线性回归 |
您所在的位置:网站首页 › 最小二乘法公式线性回归方程 › 线性回归 |
线性回归
|
接上一篇文章【线性回归——二维线性回归方程(证明和代码实现)】 前言: 博主前面一篇文章讲述了二维线性回归问题的求解原理和推导过程,以及使用python自己实现算法,但是那种方法只能适用于普通的二维平面问题,今天博主来讲一下线性回归问题中更为通用的方法,也是我们实际开发中会经常用到的一个数学模型,常用的解法就是最小二次乘法和梯度下降法.博主今天对最小二乘法进行推导并使用Python代码自定义实现,废话不多说,开始吧: 一、公式推导 假如现在有一堆这样的数据 ( x 1 , y 1 ) , ( x 2 , y 2 ) , … , ( x n , y n ) (x_1,y_1),(x_2,y_2),\dots,(x_n,y_n) (x1,y1),(x2,y2),…,(xn,yn),然后我们已经通过某种方式得到了数据所对应的模型 y ^ = θ 0 + θ 1 x \hat{y}=\theta_0+\theta_1x y^=θ0+θ1x,但是因为 y ^ \hat{y} y^ 毕竟是通过训练模型所得到的预测值,所以 y ^ \hat{y} y^ 与 y y y 之间必定存在误差如图所示: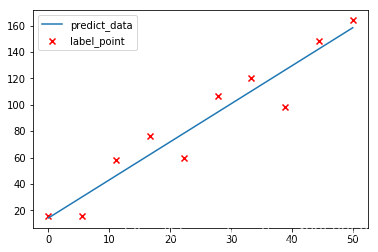
也就是说存在一个这样的等式
ω
=
y
^
−
y
\omega=\hat{y}-y
ω=y^−y 其中
ω
\omega
ω 的值代表误差值.现在不妨我们再来将训练数据换一下变成
(
x
11
,
x
12
,
…
,
x
1
m
,
y
1
)
,
(
x
21
,
x
22
,
,
…
,
x
2
m
,
y
1
)
,
…
,
(
x
n
1
,
x
n
2
,
…
,
x
n
m
,
y
n
)
(x_{11},x_{12},\dots,x_{1m},y_1),(x_{21},x_{22},,\dots,x_{2m},y_1),\dots,(x_{n1},x_{n2},\dots,x_{nm},y_n)
(x11,x12,…,x1m,y1),(x21,x22,,…,x2m,y1),…,(xn1,xn2,…,xnm,yn)这里有n项数据,其中每项数据的前 m 个数据代表特征值,最后的一个数据代表标签值(也就是真实的 y 值),对这个数据我们通过线性模型也可以将数据对应的模型写出来:
y
^
=
θ
0
+
θ
1
x
1
+
θ
2
x
2
+
⋯
+
θ
m
x
m
\hat{y}=\theta_0+\theta_1x_1+\theta_2x_2+\cdots+\theta_mx_m
y^=θ0+θ1x1+θ2x2+⋯+θmxm不妨简化一下换成矩阵的形式表示:
y
^
=
∑
i
=
0
n
θ
i
x
i
=
θ
T
x
\displaystyle \hat{y}=\sum_{i=0}^n{\theta_ix_i}=\theta^Tx
y^=i=0∑nθixi=θTx 其中
θ
=
[
θ
0
θ
1
⋮
θ
m
]
,
x
i
=
[
x
i
0
x
i
1
⋮
x
i
m
]
,
x
i
0
=
1
\theta=\begin{bmatrix}\theta_0 \\ \theta_1 \\ \vdots \\ \theta_m \end{bmatrix},x_i=\begin{bmatrix}x_{i0}\\x_{i1}\\ \vdots\\x_{im}\end{bmatrix},x_{i0}=1
θ=⎣⎢⎢⎢⎡θ0θ1⋮θm⎦⎥⎥⎥⎤,xi=⎣⎢⎢⎢⎡xi0xi1⋮xim⎦⎥⎥⎥⎤,xi0=1,我们再把
y
^
\hat{y}
y^ 换一个符号表示:
y
θ
(
x
i
)
=
∑
i
=
0
m
θ
i
x
i
=
θ
T
x
i
\displaystyle y_{\theta}(x_i)=\sum_{i=0}^m{\theta_ix_i}=\theta^Tx_i
yθ(xi)=i=0∑mθixi=θTxi 上面这个函数方程即表示我们的拟合曲线,再结合我们前面分析的误差结论可知(因为误差值可正可负,这里加减就无所谓了):
y
i
=
θ
T
x
i
+
ω
i
y_i=\theta^Tx_i+\omega_i
yi=θTxi+ωi 等式中的 右端项
y
i
y_i
yi 代表真实的标签值,等式的左端项
θ
T
x
i
+
ω
i
\theta^Tx_i+\omega_i
θTxi+ωi 就代表预测值加上误差值
写在最后的话: 感觉这篇文章写了好久,写这篇文章发现了几个自身的问题,矩阵的求导方法还不是很熟悉,矩阵的有一些基本性质有遗忘现象. 感觉线性代数和高数还是要时不时的回去复习一下,不然会越学越吃力,怎么说了写博客还是收益挺多了,凡是不能图快,要是地基都没打牢,房子搭在高也是会倒的,万丈高楼平地起.嗯. 最后如果有小伙伴发现文章有什么错误的地方,欢迎指出来,将非常感谢!!!(__) |
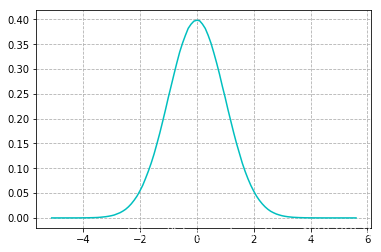 上图这个图应该很眼熟吧,没错就是表示正态分布(也称高斯分布)的统计图,其实现实生活中,误差的波动性也大多遵循这个规律.是什么意思呢?我们可以把图中的横坐标想作误差值,而纵坐标想成概率值,那么从图中我们可以发现一个很有意思的规律,误差值的绝对值越大那么它出现的概率反而会越小越趋近于0,误差值在0附近时可以看它们出现的概率是最大的,也就是说那种极大或者极小的误差值是占少数的.我们现在要引出一个函数也就是高斯分布的概率密度函数:
f
(
x
−
μ
)
=
1
2
π
σ
e
(
−
(
x
−
μ
)
2
2
σ
2
)
\displaystyle f(x-\mu)= \frac{1}{\sqrt{2\pi}\sigma}e^{\displaystyle (-\frac{(x-\mu)^2}{2\sigma^2})}
f(x−μ)=2π
σ1e(−2σ2(x−μ)2) 不懂概率密度函数的小伙伴也别急,你就把这个函数的自变量想成事件,然后函数的值想作此事件发生的概率即可;
上图这个图应该很眼熟吧,没错就是表示正态分布(也称高斯分布)的统计图,其实现实生活中,误差的波动性也大多遵循这个规律.是什么意思呢?我们可以把图中的横坐标想作误差值,而纵坐标想成概率值,那么从图中我们可以发现一个很有意思的规律,误差值的绝对值越大那么它出现的概率反而会越小越趋近于0,误差值在0附近时可以看它们出现的概率是最大的,也就是说那种极大或者极小的误差值是占少数的.我们现在要引出一个函数也就是高斯分布的概率密度函数:
f
(
x
−
μ
)
=
1
2
π
σ
e
(
−
(
x
−
μ
)
2
2
σ
2
)
\displaystyle f(x-\mu)= \frac{1}{\sqrt{2\pi}\sigma}e^{\displaystyle (-\frac{(x-\mu)^2}{2\sigma^2})}
f(x−μ)=2π
σ1e(−2σ2(x−μ)2) 不懂概率密度函数的小伙伴也别急,你就把这个函数的自变量想成事件,然后函数的值想作此事件发生的概率即可;
【本文地址】