【梯度下降法】详解优化算法之梯度下降法(原理、实现) |
您所在的位置:网站首页 › 最大方向导数求解 › 【梯度下降法】详解优化算法之梯度下降法(原理、实现) |
【梯度下降法】详解优化算法之梯度下降法(原理、实现)
|
梯度下降法(Gradient descent,简称GD)是一阶最优化算法。 要使用梯度下降法找到一个函数的局部极小值,必须向函数上当前点对应梯度(或者是近似梯度)的反方向的规定步长距离点进行迭代搜索。如果相反地向梯度正方向迭代进行搜索,则会接近函数的局部极大值点,这个过程则被称为梯度上升法。 梯度下降法是迭代法的一种,可以用于求解最小二乘问题(线性和非线性都可以)。在求解机器学习算法的模型参数,即无约束优化问题时,梯度下降法和最小二乘法是最常采用的方法。在求解损失函数的最小值时,可以通过梯度下降法来迭代求解,得到最小化的损失函数和模型参数值。反过来,如果我们需要求解损失函数的最大值,这时就需要用梯度上升法来迭代了。在机器学习中,基于基本的梯度下降法发展了两种常用梯度下降方法,分别为随机梯度下降法和批量梯度下降法。
举例说明,将下山的人看作
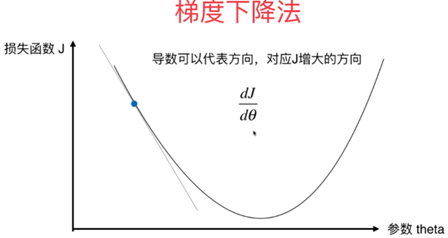
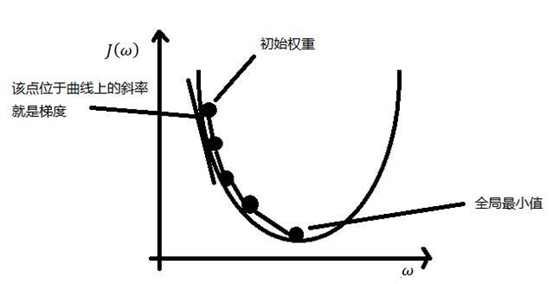
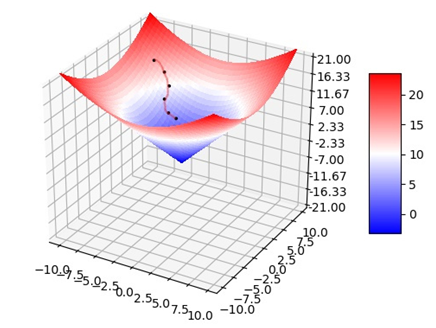
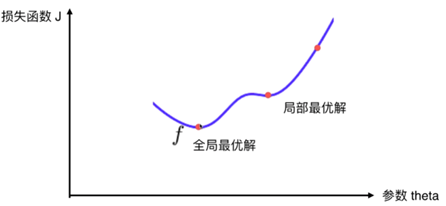
在当前位置求偏导,即梯度,正常的梯度方向类似于上山的方向,是使值函数增大的,下山最快需使 可以看出梯度下降有时得到的是局部最优解,如果损失函数是凸函数,梯度下降法得到的解就是全局最优解。
如果函数为一元函数,梯度就是该函数的导数: 如果为二元函数,梯度定义为: 梯度下降法公式: 求解步骤: (1)确定当前位置的损失函数的梯度,对于 (2)用步长乘以损失函数的梯度,得到当前位置下降的距离,即 (3)确定是否所有的 即为最终结果。否则进入第(4)步。 (4)更新所有的
计算训练集所有样本误差,对其求和再取平均值作为目标函数。权重向量沿其梯度相反的方向移动,从而使当前目标函数减少得最多。因为在执行每次更新时,需要在整个数据集上计算所有的梯度,所以速度会很慢,同时,其在整个训练数据集上计算损失函数关于参数θ的梯度: 由于FG每迭代更新一次权重都需要计算所有样本误差,而实际问题中经常有上亿的训练样本,故效率偏低,且容易陷入局部最优解,因此提出了随机梯度下降算法。其每轮计算的目标函数不再是全体样本误差,而仅是单个样本误差,即每次只代入计算一个样本目标函数的梯度来更新权重,再取下一个样本重复此过程,直到损失函数值停止下降或损失函数值小于某个设定的阈值。此过程简单,高效,通常可以较好地避免更新迭代收敛到局部最优解。其迭代形式为: 其中, 但是由于,SG每次只使用一个样本迭代,若遇上噪声则容易陷入局部最优解。 (3)小批量梯度下降法小批量梯度下降算法是FG和SG的折中方案,在一定程度上兼顾了以上两种方法的优点。每次从训练样本集上随机抽取一个小样本集,在抽出来的小样本集上采用FG迭代更新权重。被抽出的小样本集所含样本点的个数称为batch_size,通常设置为2的幂次方,更有利于GPU加速处理。特别的,若batch_size=1,则变成了SG;若batch_size=n,则变成了FG。其迭代形式为: 关注微信公众号【有梦想的程序星空】,了解软件系统和人工智能算法领域的前沿知识,让我们一起学习、一起进步吧! |
【本文地址】