IPMI 2023 港科大陈浩团队新作 |
您所在的位置:网站首页 › 最先进的医学成像技术 › IPMI 2023 港科大陈浩团队新作 |
IPMI 2023 港科大陈浩团队新作
|
本文首发于微信公众号 CVHub,严禁私自转载或售卖到其他平台,违者必究。
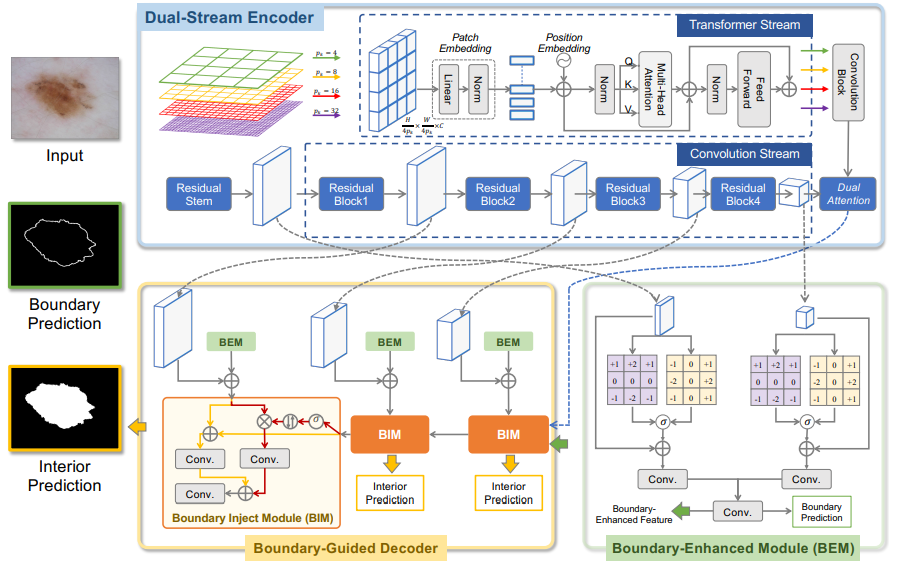
Title: Rethinking Boundary Detection in Deep Learning Models for Medical Image Segmentation Paper: https://arxiv.org/pdf/2305.00678.pdf Code: https://github.com/xiaofang007/CTO 导读本文提出了一种新颖的网络架构CTO,即Convolution, Transformer 和 Operator,通过结合卷积神经网络、视觉 Transformer 和显式边界检测操作,实现高精度的图像分割,并在准确性和效率之间保持最佳平衡。 CTO 遵循标准的编码器-解码器分割范式,其中编码器网络采用流行的 CNN 骨干结构来捕捉局部语义信息,并使用轻量级的 ViT 辅助网络来整合远距离依赖关系。为了增强边界的学习能力,本文进一步提出了一种基于边界引导的解码器网络,利用专用边界检测操作得到的边界掩模作为显式监督,引导解码学习过程。 该方法在六个具有挑战性的医学图像分割数据集上进行了评估,结果表明 CTO 在模型复杂度竞争力的同时实现了最先进的准确性。 背景运算符是传统数字图像处理中的基本组成部分,其中边界检测运算符是最核心的元素,也是本文核心要点。常用的边界检测运算符可以分为两类: 一阶导数运算符(例如Roberts、Prewitt和Sobel)二阶导数运算符(例如Laplacian)近年来,边界检测运算符在像素级计算机视觉任务中也被广泛应用,例如manipulation detection和伪装对象检测领域。在本文中,边界检测运算符被用作显式的掩模提取器,以指导隐式特征学习模型进行医学图像分割,其贡献在于利用中间层的特征图来合成高质量的边界预测,而无需额外的信息。 方法 Framework
如上图所示,CTO 遵循编码器-解码器范式,并采用跳跃连接将来自编码器的低级特征聚合到解码器中。其中编码器网络由主流的 CNN 和辅助 ViT 组成。解码器网络则采用边界检测运算符来指导其学习过程。 对于编码器,作者设计了一个双流编码器,它结合了卷积神经网络和轻量级视觉 Transformer,分别捕捉图像局部特征依赖和图像块之间的远程特征依赖。这种组合不会带来太多的计算开销。 对于解码器,采用了一个运算符引导的解码器,它使用边界检测运算符(例如Sobel)通过生成的边界掩模来指导学习过程,整个模型以端到端的方式进行训练。 Dual-Stream Encoder The Mainstream Convolution Stream为了捕捉局部特征依赖关系,CTO 首先构建了一个卷积流。本文选择了强大而高效的Res2Net作为骨干网络,它由一个卷积干部和四个残差块组成。
Res2Net 是由南开程明明教授团队早年发表的一种卷积神经网络变体,旨在增强网络的感受野和特征表示能力。它通过重新设计残差模块中的连接方式,引入了多尺度感受野的概念,以提升网络的性能。在传统的残差模块中,特征从一个模块传递到下一个模块时,通常采用相同的尺度。然而,Res2Net 引入了一个新的结构单元,称为"Res2Block",它在模块内部引入了多个分支,每个分支具有不同的感受野。这种多分支结构可以捕捉不同尺度的特征,从而增强网络对不同尺度信息的表示能力。这种设计使得网络可以更好地捕捉图像中的细节和全局上下文信息,从而提升了图像分析和计算机视觉任务的性能。 The Assistant Transformer Stream其次,作者设计了一个基于轻量级视觉 Transformer 的辅助流。LightViT旨在捕捉不同尺度图像块之间的远程特征依赖关系。具体而言,它由多个并行的轻量级 Transformer 块组成,这些块接收不同尺度的特征块作为输入。所有的 Transformer 块共享相似的结构,包括块嵌入层和 Transformer 编码层。 LightViT 的块嵌入层用于将输入的特征块转换为嵌入向量,将空间维度转换为序列维度。这样,每个特征块都可以被视为一个序列,并在 Transformer 模块中进行处理。接下来,Transformer 编码层用于对特征块进行自注意力机制的建模,以捕捉不同特征块之间的长程依赖关系。通过在 Transformer 模块中引入自注意力机制,LightViT 可以有效地对特征块之间的相互作用进行建模,从而提取图像的全局上下文信息。 LightViT 的设计使得网络可以在不同尺度上捕捉图像块之间的远程特征依赖,从而提升了图像分析任务的性能。由于采用了轻量级的 Transformer 块,LightViT 在保持高效性能的同时,减少了模型的计算和存储开销。这使得 LightViT 成为一种适用于医学图像分析等领域的有效工具。 Boundary-Guided Decoder边界引导的解码器使用梯度运算符模块来提取前景对象的边界信息。然后,通过边界优化模块,将边界增强特征与多级编码器的特征进行整合,旨在同时在特征空间中表征类内和类间的一致性,丰富特征的表征能力。这种方法能够使解码器在生成分割结果时更好地利用边界信息,从而产生更准确的分割结果。 Boundary Enhanced Module (BEM)边界优化模块使用高级特征和低级特征作为输入,提取边界信息并过滤掉与边界无关的信息。为了实现这个目标,作者在水平方向 G x G_{x} Gx 和垂直方向 G y G_{y} Gy 上应用Sobel算子来获得梯度图。具体而言,本文采用两个 3 × 3 3\times 3 3×3 的参数固定卷积,并应用步长为1的卷积操作。这两个卷积定义为:
然后,我们将这两个卷积应用于输入特征图,得到梯度图 M x M_{x} Mx 和 M y M_{y} My。接下来,梯度图通过 sigmoid 函数进行归一化,然后与输入特征图融合,得到增强边缘特征图 F e F_{e} Fe:
其中,圈号表示逐元素相乘, σ \sigma σ 表示 sigmoid 函数, M x y M_{xy} Mxy 是将 M x M_{x} Mx 和 M y M_{y} My 沿通道维度进行拼接。然后,我们便可以直接使用简单的堆叠卷积层将边缘增强特征图进行融合。最后,输出特征图受到GT 边界图的监督,从而消除了物体内部的边缘特征,产生边界增强特征。 Boundary Inject Module (BIM)上一步我们通过 BEM 得到的边界增强特征可以作为先验知识,改善编码器生成的特征的图像表示能力。紧接着,本文提出了 BIM,引入了双路径边界融合方案,促进前景和背景特征的表示能力。具体而言,BIM 接收两个输入:边界增强特征与来自编码器网络的对应特征的通道级连接,以及前一解码器层的特征。然后,这两个输入被馈送到 BIM 中,其中包含两个独立的路径,分别用于促进前景和背景的特征表示。对于前景路径,我们直接沿通道维度将这两个输入进行拼接,然后应用一系列的 Conv-BN-ReLU(卷积、批归一化、ReLU激活)层,得到前景特征。对于背景路径,则设计了背景注意力组件,选择性地关注背景信息。 Loss FunctionCTO是一个多任务模型,包含内部和边界分割,本文定义了一个总体损失函数来共同优化这两个任务:
整体损失由主要的内部分割损失 L s e g L_{seg} Lseg 和边界损失 L b n d L_{bnd} Lbnd 组成。需要注意的是,在边界检测损失中,仅考虑来自 BEM 的预测结果,该模块将编码器的高层特征图和低层特征图作为输入。至于主要图像分割损失,作者采用了深监督策略,以获得来自解码器不同层级特征的预测结果。 Interior Segmentation LossL s e g L_{seg} Lseg 是交叉熵损失 L C E L_{CE} LCE 和平均交并比 mIoU 损失 L m I o U L_{mIoU} LmIoU 的加权和:
边界损失 L b n d L_{bnd} Lbnd 考虑到边界检测中前景和背景像素之间的类别不平衡问题,因此采用Dice损失:
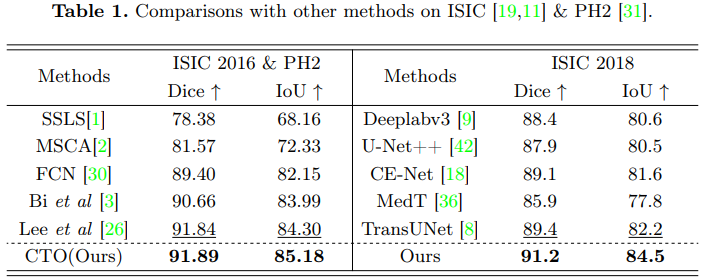
本文将 CTO 与包括 U-Net、ResUNet、VNet、ViT、TransUNet和Swin-Unet在内的多个 SOTA 方法在以下几个主流的基准数据集上进行实验比对。 ISIC 2016 & PH2CTO 在 Dice 系数上达到了 91.89%,在 IoU 上达到了 85.18%,分别比最先进方法高出 0.05% 和 0.88%。
通过 5 倍交叉验证,CTO 在 Dice 系数上达到了 91.2%,在 IoU 指标上达到了 84.5%,分别比最先进方法高出 1.8% 和 2.3%。此外,CTO 在 LiTS17 数据集上在Dice和IoU上分别达到了91.50%和84.59%,分别比最先进方法高出0.26%和0.45%。 CoNIC
可以看出,在 BTCV 数据集上,CTO 在 Dice 上达到了 81.10%,在 HD 上达到了 18.75%,超过了最先进方法。尤其是在模糊边界的器官上,如“胰腺”和“胃”,该模型在 Dice 上取得了显著的增益,分别为4.70%和3.60%。值得注意的是,CTO 在模型效率方面表现出色,具有可比较的 FLOPs 和参数,同时取得了竞争性的性能改进。 总结本研究提出了一种名为CTO的新型网络架构,用于医学图像分割。与先进的医学图像分割架构相比,CTO 在识别准确性和计算效率之间取得了更好的平衡。本文的贡献在于利用中间特征图合成高质量的边界监督掩模,而无需额外信息。通过在六个公开数据集上进行的实验,CTO 在性能上超越了最先进的方法,并验证了其各个组件的有效性。 CVHub是一家专注于计算机视觉领域的高质量知识分享平台,全站技术文章原创率达99%,每日为您呈献全方位、多领域、有深度的前沿AI论文解决及配套的行业级应用解决方案,提供科研 | 技术 | 就业一站式服务,涵盖有监督/半监督/无监督/自监督的各类2D/3D的检测/分类/分割/跟踪/姿态/超分/重建等全栈领域以及最新的AIGC等生成式模型。关注微信公众号,欢迎参与实时的学术&技术互动交流,领取CV学习大礼包,及时订阅最新的国内外大厂校招&社招资讯! |


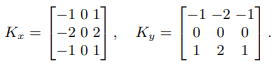

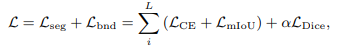
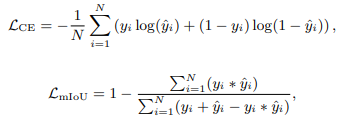
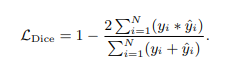



【本文地址】
今日新闻 |
推荐新闻 |