【GPU结构与CUDA系列4】GPU存储资源:寄存器,本地内存,共享内存,缓存,显存等存储器细节 |
您所在的位置:网站首页 › 显存与内存速度 › 【GPU结构与CUDA系列4】GPU存储资源:寄存器,本地内存,共享内存,缓存,显存等存储器细节 |
【GPU结构与CUDA系列4】GPU存储资源:寄存器,本地内存,共享内存,缓存,显存等存储器细节
|
0 软件抽象和硬件结构对应关系的例子
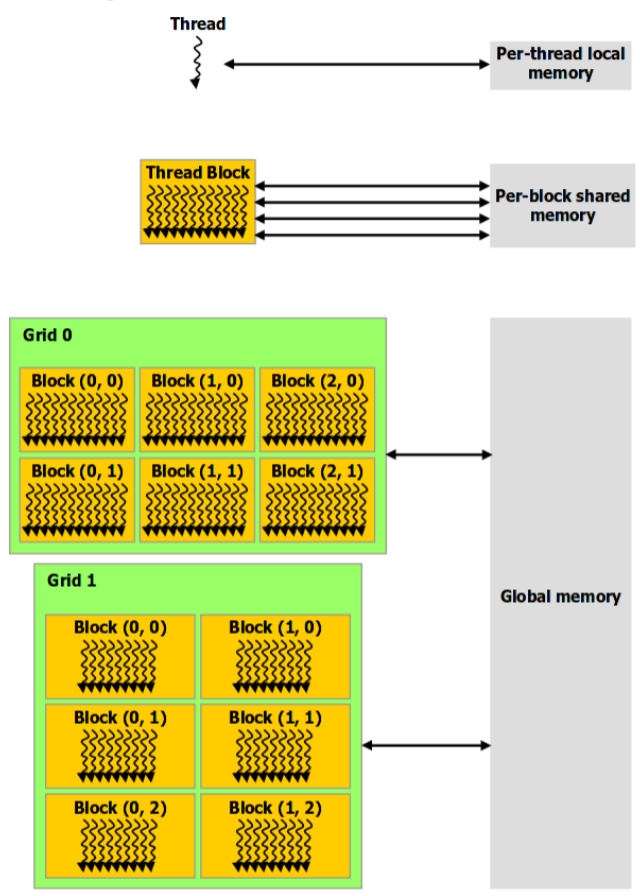
把GPU跟一个学校对应起来,学校里有教学楼、操场、食堂,还有老师和学生们;很快有领导(CPU)来检查卫生(需要执行的任务Host程序),因此这个学校的学生们要完成打扫除的工作(Device程序)。 软件抽象资源包括Thread、Warp、Block和Grid 硬件资源包括SP和SM 0.1 软件抽象Grid对应的是年级 是抽象的划分组织方式 根据年级划分任务,Grid可以分为多个不同的班级 Block对应的是班级 是抽象的划分组织方式 每个班级有若干的同学(线程),可能一个两个不同的年级会出现在同一层楼(SM),或者一层楼只有一个班级,或者没有班级,但是每一层楼的班级最大数量是固定的 Warp对应的是兴趣小组 每个小组有32个学生;(同一时间他们一定是一个班级下的小组) 并且数量固定,即使凑不满这么多学生需要加进来不干活的学生,凑够一个小组 只要求他们有着一样的兴趣爱好(能执行相同的任务) Thread对应的是学生 一个Thread对应一个SP 每个学生都有个课桌 ,放自己的物品,不能让别人用,表示每个Thread在软件上都有自己的空间(寄存器等) 0.2 硬件资源SM对应的是教学楼的一个楼层 是实际存在的资源 一个楼层上可以有多个班级,年级和楼层并没有确定的对应关系,一个楼层中可以有很多来自不同的年级的Block SM中的SP会被分成兴趣小组,承接不同的任务 SP对应的是学生 一个SP对应一个Thread 是实际存在的资源 每个学生都有个课桌 ,放自己的物品,不能让别人用,表示每个SP在硬件上都有自己的空间(local memory + registers); 在楼层中,有公共的空间(走廊、厕所等),这一层楼的所有同学都可以停留,表示一个SM中有shared memory,这个SM上的Block都可以访问;(shared memory是不是所有的block都可以访问) 学校里的公共区域,比如操场、食堂等,所有同学都可以去运动、吃饭,表示GPU中有一些公共的存储空间供所有的Grid访问。 0.3 执行任务虽然GPU是并行运行,但也并不是我们理想中所有的Thread一起工作,在打扫卫生时,并不是所有学生一起干活,学生经过老师(这里我们理解为Wrap Scheduler)安排后,分为一组一组的小组,每一个小组都只会做一件一样的事情,如果有人先做完了或者不需要做,那么他也会在旁边等他的组员,处于等待状态idle。 1 GPU不同存储的辨析
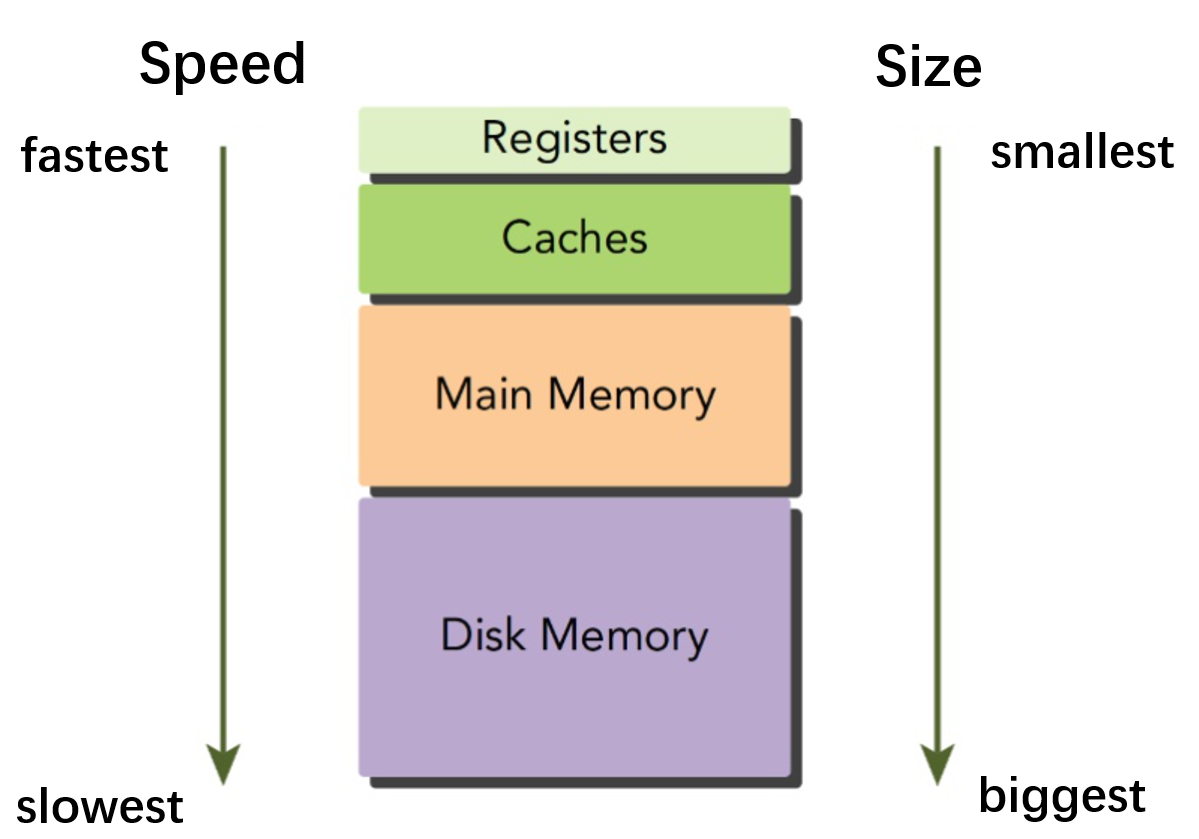
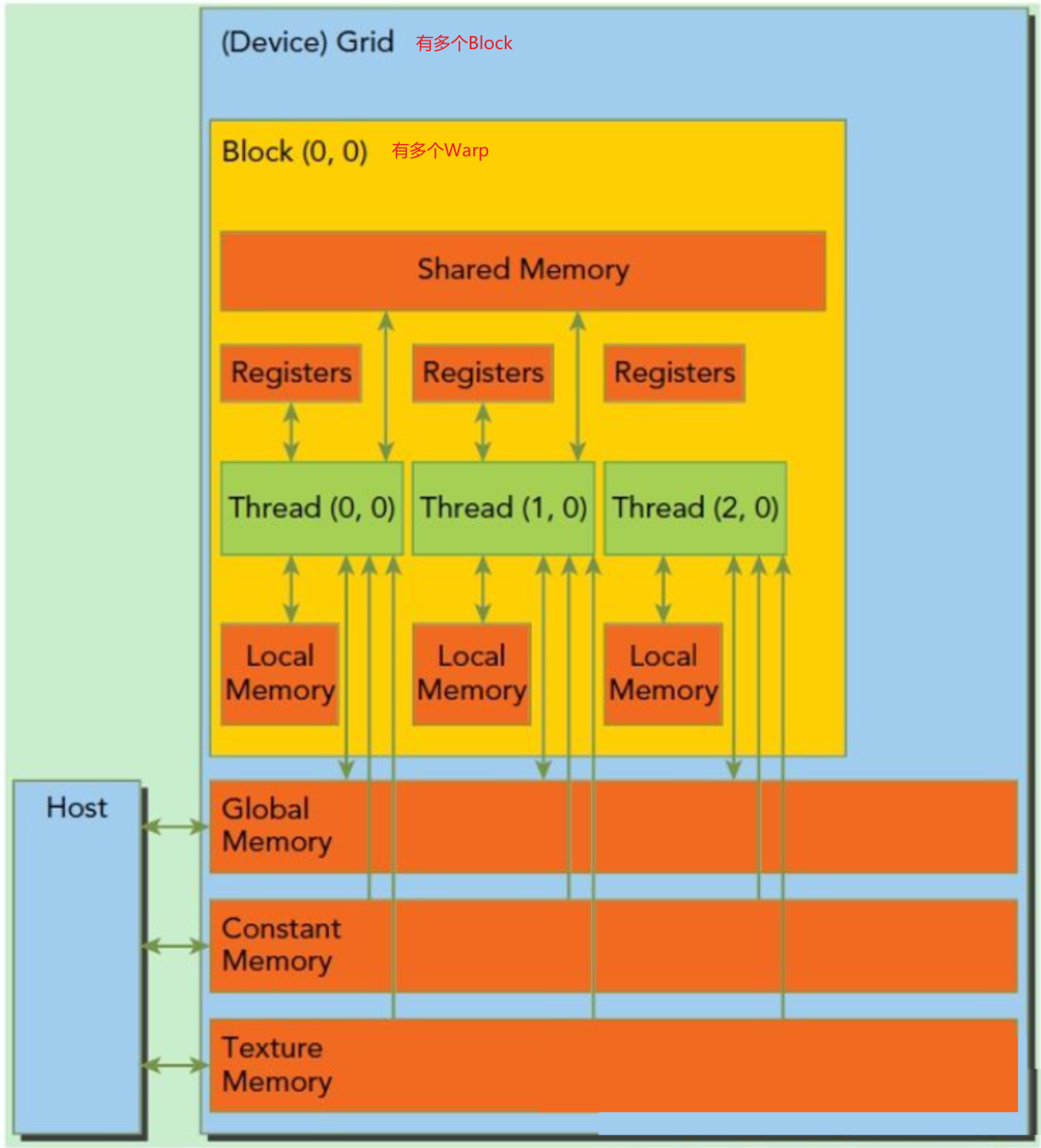
这一点跟CPU比较像,就是存储空间越大,访问速度越慢。 GPU越靠近SM的内存就越快。内存的访问速度从快到慢依次为: Registers->Caches->Shared Memory->Gloabl Memory(Local Memory)。
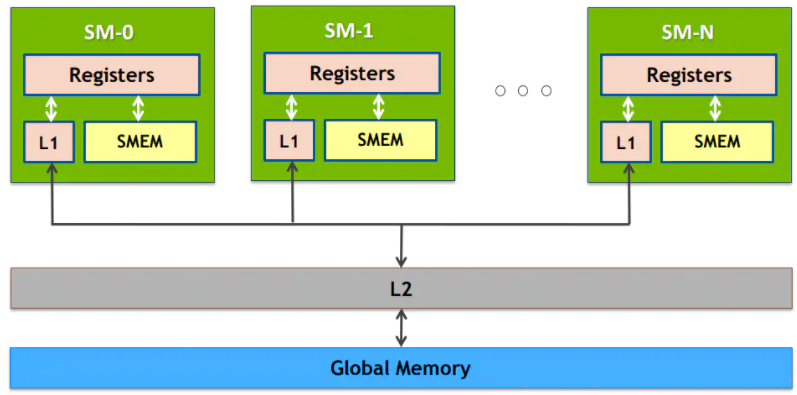
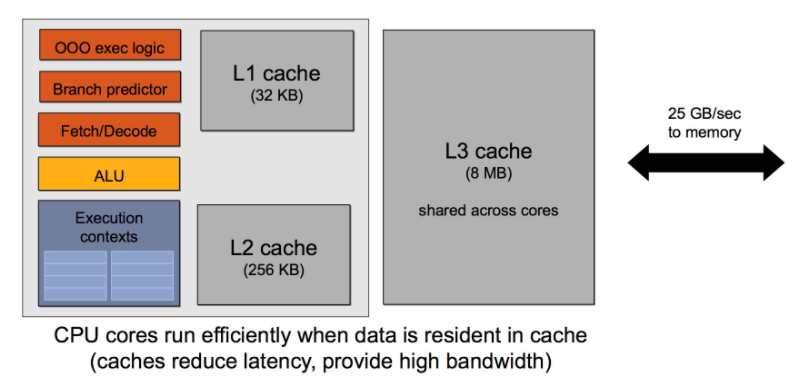
一般来说,CPU和内存之间的带宽只有数十GB/s。比如对于Intel Xeon E5-2699 v3,内存带宽达到68GB/s((2133 * 64 / 8)*4 MB/s): 内存规格最大内存大小(取决于内存类型)768 GB内存类型DDR4 1600/1866/2133最大内存通道数4最大内存带宽68 GB/s GPU的存储结构一般如下:
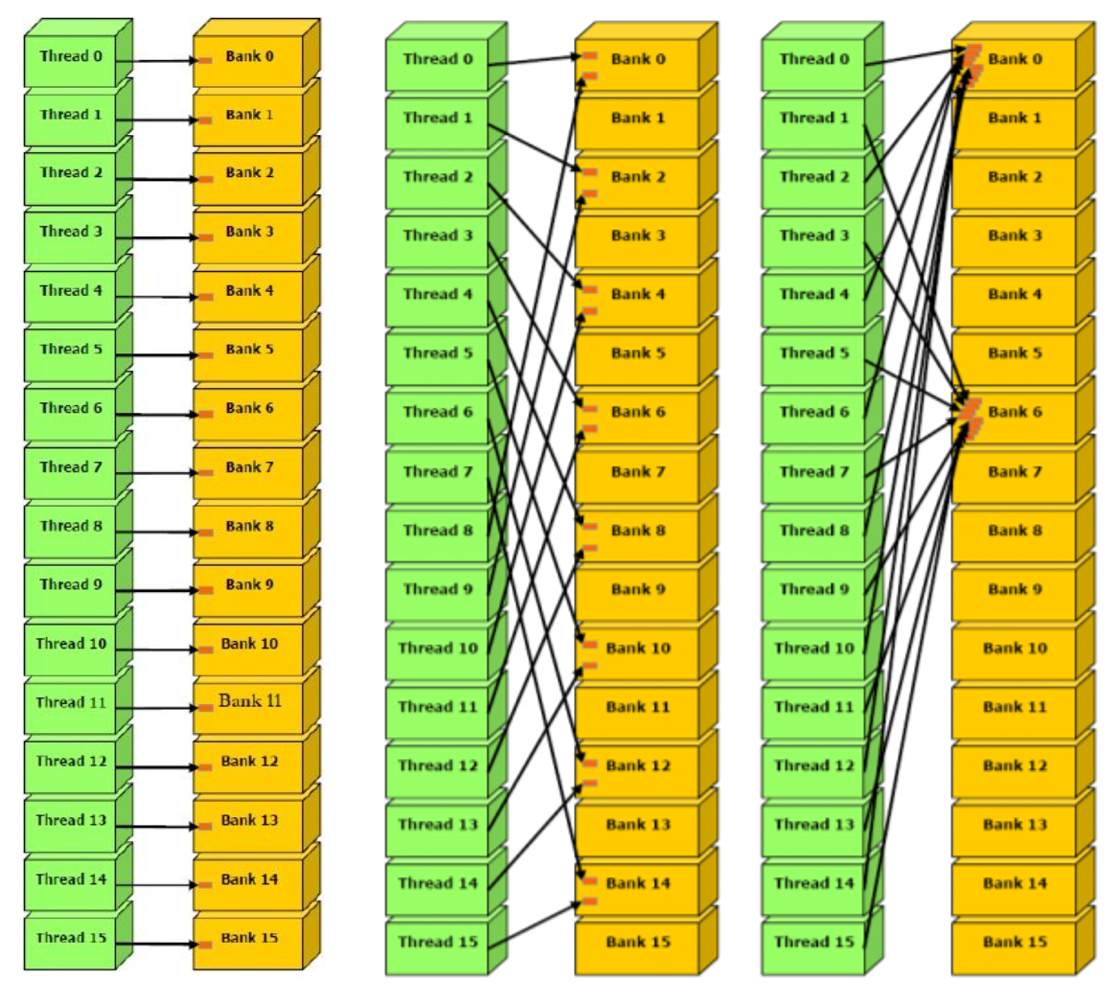
GPU的高速缓存较小,上图的Memory实际上是指GPU卡内部的显存。但是与显存之间的带宽可以达到数百GB/s,比如P40的显存带宽为346GB/s,远远大于CPU的内存带宽,但是,相对于GPU的计算能力,显存仍然是瓶颈所在。 1.1.3 CPU与GPU交互在现代的异构计算系统中,GPU是以PCIe卡作为CPU的外部设备存在,两者之间通过PCIe总线通信: ---------- ------------ |___DRAM___| |___GDRAM____| | | ---------- ------------ | CPU | | GPU | |__________| |____________| | | --------- -------- |___IO____|---PCIe---|___IO___|对于PCIe Gen3 x1理论带宽约为1000MB/s,所以对于Gen3 x32的最大带宽为32GB/s,而受限于本身的实现机制,有效带宽往往只有理论值的2/3还低。所以,CPU与GPU之间的通信开销是比较大的。 1.2 Registers 寄存器是访问速度最快的空间。当我们在核函数中不加修饰的声明一个变量,那该变量就是寄存器变量,如果在核函数中定义了常数长度的数组,那也会被分配到Registers中;寄存器变量是每个线程私有的,当这个线程的核函数执行完成后,寄存器变量也就不能访问了。寄存器是比较稀缺的资源,空间很小,Fermi架构中每个线程最多63个寄存器,Kepler架构每个线程最多255个寄存器;一个线程中如果使用了比较少的寄存器,那么SM中就会有更多的线程块,GPU并行计算速度也就越快。如果一个线程中变量太多,超出了Registers的空间,这时寄存器就会发生溢出,就需要其他内存(Local Memory)来存储,当然程序的运行速度也会降低。因此,在程序中,对于那种循环操作的变量,我们可以放到寄存器中;同时要尽量减少寄存器的使用数量,这样线程块的数量才能增多,整个程序的运行速度才能更快。 1.3 Local MemoryLocal Memory也是每个线程私有的,但却是存储在于Global Memory中的。在核函数中符合存储在寄存器中但不能进入核函数分配的寄存器空间中的变量将被存储在Local Memory中,Local Memory中可能存放的变量有以下几种: 使用未知索引的本地数组较大的本地数组或结构体任何不满足核函数寄存器限定条件的变量 1.4 Shared Memory每个SM中都有共享内存,使用__shared__关键字(CUDA关键字的下划线一般都是两个)定义,共享内存在核函数中声明,生命周期和线程块一致。 同样需要注意的是,SM中共享内存使用太多,会导致SM上活跃的线程数量减少,也会影响程序的运行效率。 数据的共享肯定会导致线程间的竞争,可以通过同步语句来避免内存竞争,同步语句为: void __syncthreads();当所有线程都执行到这一步时,才能继续向下执行;频繁调用__syncthreads()也会影响核函数的执行效率。 共享内存因为需要分配给不同的线程所以被分成了不同个Bank,一个Warp中有32个线程,在比较老的GPU中,16个Bank可以同时互相访问,即一条指令就可以让半个Warp同时访问16个Bank,这种并行访问的效率可以极大的提高GPU的效率。比较新的GPU中,一个Warp即32个SP可以同时访问32个Bank,效率又提升了一倍。 下面这个图中: 左边的图每个线程访问一个Bank,不存在内存冲突,通过一个指令即可完成访问所有的访问操作; 中间的图虽然看起来有些乱,但还是一个线程对应一个Bank,也不存在冲突,一个指令即可完成。 右边的图中,存在多个Thread访问一个Bank的情况,如果是读操作,那么GPU底层可以通过广播的方式将数据传给各个Thread,延迟不会很大,但如果是写操作,就必须要等上一个线程写完成后才能进行下一个线程的写操作,延时会比较大。
常量内存驻留在设备内存中,每个SM都有专用的常量内存空间,使用__constant__关键字来声明,可以用来声明一些滤波系数等常量。 常量内存存在于核函数之外,在kernel函数外声明,即常量内存存在于内存中,并不在片上,常量内容的访问速度也是很快的,这是因为每个SM都有专用的常量内存缓存,会把片外的常量读取到缓存中;对所有的核函数都可见,在Host端进行初始化后,核函数不能再修改。 1.6 Texture Memory纹理内存的使用并不多,它是为了GPU的显示而设计的,这里不多讲了。纹理内存也是存在于片外。 1.7 Global Memory全局内存,就是我们常说的显存,就是GDDR的空间,全局内存中的变量,只要不销毁,生命周期和应用程序是一样的。 在访问全局内存时,要求是对齐的,也就是一次要读取指定大小(32、64、128)整数倍字节的内存,数据对齐就意味着传输效率降低,比如我们想读33个字节,但实际操作中,需要读取64字节的空间。 对于Global和Constant,Host可以通过下面的函数访问: cudaGetSymbolAddress() cudaGetSymbolSize() cudaMemcpyToSymbol() cudaMemcpyFromSymbol() 1.8 GPU缓存每个SM都有一个一级缓存,所有SM公用一个二级缓存,GPU读操作是可以使用缓存的,但写操作不能被缓存。 L1 Cache:Pascal架构上,L1 Cache和Texture已经合为一体(Unified L1/Texture Cache),作为一个连续缓存供给warp使用。 L2 Cache:用来做Global Memory的缓存,容量大,给整个GPU使用。
每个SM有一个只读常量缓存,只读纹理缓存,它们用于设备内存中提高来自于各个内存空间内的读取性能。 讲到缓存,我们就必须要提一点,CPU和GPU在缓存上的一个重要差别就是“缓存一致性”(cache coherency) 问题。缓存一致是指一个内存的写操作需要通知所有核的各个级别的缓存,因此,无论何时,所有处理器核看到的内存视图是完全一样的。随着处理器中核数量的增多,这个“通知”的开销迅速增大,使得“缓存一致性”成为限制一个处理器中核数不能太多的一个重要因素。“缓存一致”系统中最坏的情况是,一个内存写操作会强迫每个核的缓存都进行更新,进而每个核都要对相邻的内存单元进行写操作。 CPU遵循“缓存一致”原则,而GPU不是。在GPU中系统不会自动的更新其他核的缓存。所以GPU能扩展到一个芯片内具有大数量的核心。它需要由程序员写清楚每个处理器核输出的各自不同的目标区域。从程序的视角看,这支持一个核仅负责一个输出或者一个小的输出集。 1.9 总结如下: 存储器作用域声明期RegisterThreadKernelLocal MemoryThreadKernelShared MemoryBlockKernelGlobal MemoryGridApplicationConstantGridApplication 2 内存与软件硬件的一一对应 2.1 Thread 每一个Thread都有自己的local memory和Registers即每个同学都可以把自己的东西放到自己的课桌上,别的同学不可以使用; Local Memory,它是每个线程专有的线程,但却是存在于Global Memory中的,结合我们在第0节例子中拿学校和学生举的例子,可以理解为:学生的课桌都放满了,只能在操场里给他再找个地方放东西,所以访问速度是很慢的,但是这部分还是属于他的local memory,别的线程应该是访问不了的。 2.2 Block 每一个Block有自己的shared memory,构成Block的所有Thread都可以访问。可以被线程中所有的线程共享,其生命周期与线程块一致即每个班所在的教室里的走道、讲台等,是这个班里同学们的公共区域,别的班级的同学不能进入; 2.3 Grid Grid之间会有Global memory和Cache所有的Grid都可以访问,即学校里的操场、餐厅等,是全校同学的公共区域,所有年级的同学都可以共享。 所有的thread(包括不同block的thread)都共享一份 global memory、constant memory、和texture memory。所有的线程都可以访问全局内存(Global Memory)
每一个时钟周期内,Warp(一个block里面一起运行的thread,其中各个线程对应的数据资源不同,因为指令相同但是数据不同)现在规定的thread数量是32个。一个block中最多含有16个warp。所以一个block中最多含有512个线程。
GPU基本处理单元是流多处理器,有关处理单元介绍,之前的文章中有叙述。这篇主要讲存储结构
为了最大化执行效率动态切换执行指令策略。 3.3 显存我们经常考虑优化一些东西,包括OverDraw,贴图纹理,遮挡剔除,批次合并,不少都是为了照顾显存带宽的。显存虽然大,但是它频率不高,访问还有延时,而且这个延时往往是三位数甚至四位数的GPU核心指令周期。 通常交给GPU计算东西的时候,都是要把数据从内存拷贝到显存,GPU计算完成之后,从显存拷贝回来。当然如果这些数据用于显示,直接划分一块显存区域给帧缓存,然后让显示器读取这块显存即可,这时候不需要往回拷贝。 LAST 参考文献GPU 初理解 - 简书 GPU架构之处理模块 - 知乎 GPU中的基本概念 - 云+社区 - 腾讯云 CUDA, 软件抽象的幻影背后 之二 | 奇点视觉 CUDA, 软件抽象的幻影背后 | 奇点视觉 GPU编程1–GPU中的基本概念 - 知乎 (3条消息) gpu的单位表示_GPU中的基本概念_weixin_39717121的博客-CSDN博客 CUDA的thread,block,grid和warp - 知乎 GPU编程3–GPU内存深入了解 - 知乎 GPU架构之Hierarchy Memory多级存储 - 知乎 cuda编程(一):GPU概念与架构 - 知乎 GPU计算 – GPU体系结构及CUDA编程模型 Nvidia GPU架构 - Cuda Core,SM,SP等等傻傻分不清?_咚咚锵的博客-CSDN博客_cuda sm Fermi威力完美呈现,GeForce GTX 580全球同步评测 - 超能网 |

【本文地址】
今日新闻 |
推荐新闻 |