星环大数据系列(一):Inceptor VS Hive |
您所在的位置:网站首页 › 星环是什么意思 › 星环大数据系列(一):Inceptor VS Hive |
星环大数据系列(一):Inceptor VS Hive
|
前言 最近事情较多,逃了好几周的更,终于有点时间可以继续写点东西了。 话说入职新公司后,开始接触星环大数据平台。作为国产大数据平台的翘楚,借着国家信创政策的东风,可谓天时地利人和。 气氛烘托到这里了,近远期需求和目标都有了,不好好了解下就有点说不过去了,于是顺理成章的开启了星环之旅。 对比开源社区的竞品,来分析下星环的扩展点以及优化点,毕竟是站在了巨人肩膀上的更进一步,为了想入坑或者了解星环平台的XDJM们提供点参考(话说现在网上星环的资料真的少得可怜,大部分都是星环自己的宣传资料) 最后声明一下,由于资源以及时间的限制,此系列文章不会对星环平台组件的性能指标做过多测试和评论,仅仅从架构以及功能层面做相关的分析以及说明,大家可以按需阅读。
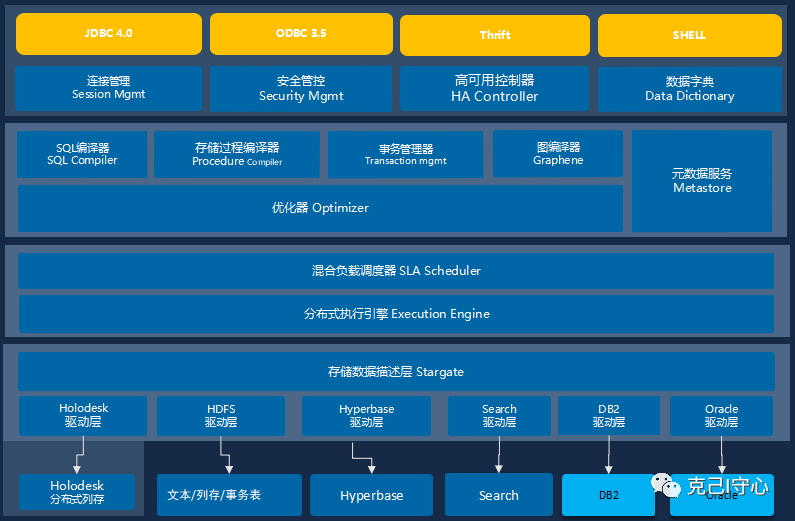
既然是大数据平台,那么数仓的实现,尤其是关系型数仓的实现自然必不可少了。 在星环这套体系中,关系型数仓的基础实现就是Inceptor,其开源界的师傅就是大名鼎鼎的HIVE,早期的大数据的玩家肯定对这个名字特别的熟悉。 下面我们就来看看Inceptor是何方神圣。 what Inceptor星环大数据平台的 Inceptor 是一种基于 Apache Hive 开发的大数据查询和分析工具,底层封装了星环版本的Spark作为计算引擎。 它提供了 SQL 查询引擎、数据仓库和数据集成等功能,能够对海量的数据进行高效的处理和分析。 Inceptor 的特点包括高性能、易用性、灵活性和可扩展性,同时还支持多租户、多用户和多任务等特性,能够满足企业级大数据应用的需求。 下面就是Inceptor的架构图:
星环大数据平台的 Inceptor 具有以下特点: 高性能Inceptor 基于 Apache Hive 开发,具备了优秀的查询和处理性能,能够快速处理海量的数据。 在原生的HIVE基础上,Inceptor在任务执行引擎与数据存储引擎上都做了部分的优化与升级,下面详细说一下: 分布式执行引擎Distributed Execution EngineInceptor基于Apache Spark深度开发的专用分布式计算引擎,由于星环定制化的Spark版本并未开源,所以只能从官网寻找答案了。 从官网可知Inceptor对Spark的优化主要体现在如下两个方面: GC问题:Inceptor引擎独立构建了分布式数据层,将计算数据从计算引擎JVM内存空间中独立出来,可以有效减少JVM GC对系统性能和稳定性的影响SQL执行计划优化:Inceptor实现了基于代价的优化器和基于规则的优化器,辅以100多种优化规则,以保证SQL应用在无需手工改动的情况下能够发挥最大的性能首先,不确认星环的定制版本的spark不知道是从哪个版本的开源代码中fork出来的,看样子应该是2.X之前的版本。 GC的问题在spark 2.X版本后spark提供了off heap模式,可以将计算数据从JVM中抽离出来放在off heap中,减少了GC对性能和稳定性的影响。 而SQL执行计划优化方面在spark 3.X版本后spark提供了AQE机制(相关知识可以参考Spark3中千呼万唤始出来的AQE到底有哪些提升,是否值得一用?),使得SQL执行计划的优化阶段从执行前变成了执行中。 AQE 是 Spark SQL 的一种动态优化机制,在运行时,每当 Shuffle Map 阶段执行完毕,AQE 都会结合这个阶段的统计信息,基于既定的规则动态地调整、修正尚未执行的逻辑计划和物理计划,来完成对原始查询语句的运行时优化。 这种质的飞越,非对称打击就好比冷兵器时代的战争突然出现了飞机坦克大炮,碾压效果可想而知。 综上,在不确定星环定制版的spark的版本以及和开源功能融合机制的前提下,我对Inceptor的Distributed Execution Engine优于最新版本的spark的结论持怀疑态度。 分布式内存列式存储 Holodesk为了加速交互式分析的速度,Inceptor推出了基于内存或者SSD的列式存储引擎Holodesk。 Holodesk把数据在内存或者SSD中做列式存储,辅以基于内存的执行引擎,可以完全避免IO带来的延时,极大的提高数据扫描速度。 相对于Distributed Execution Engine带来的提升,Holodesk的提升更显而易见: 存储形式:众所周知,列式存储是OLAP类型业务的Mr Right,十分适合实时的聚合和统计。而针对数据仓库的聚合以及统计场景同样很友好,效率提升效果明显存储介质:Holodesk可以将数据存储在内存或者SSD等闪存介质,比起硬盘存储的HDFS同样效率提升效果明显。另外Holodesk基于SSD存储做了定制的优化,使得结合使用低成本的内存、闪存混合存储方案,可接近全内存存储的分析性能,保证解决方案的高性价比综上,如果Inceptor启用Holodesk存储,在性能上还是能够碾压使用HDFS存储的HIVE的
Inceptor 支持 SQL 查询语言,用户可以直接使用熟悉的 SQL 语句进行数据查询和分析,不需要进行复杂的编程。 这个无需多言,毕竟数仓的概念就是从RDS中产生的,早期的数据仓库人员基本上都是SQL专家,如果可以使用SQL操作Inceptor会大大降低使用成本。 另外Inceptor开发了SQL编译器 SQL 2003 Compiler,支持ANSI SQL 92和SQL 99标准, 支持ANSI SQL 2003 OLAP核心扩展,可以满足绝大部分现有的数据仓库业务对SQL的要求,方便应用平滑迁移。 灵活性Inceptor 支持多种数据源和数据格式,可以方便地集成各种数据源,并且支持多种数据格式的查询和分析。 这个就不多说了,直接截个图,再加上上面的那个输出格式的图。如果需要了解详细的信息直接去官网吧。
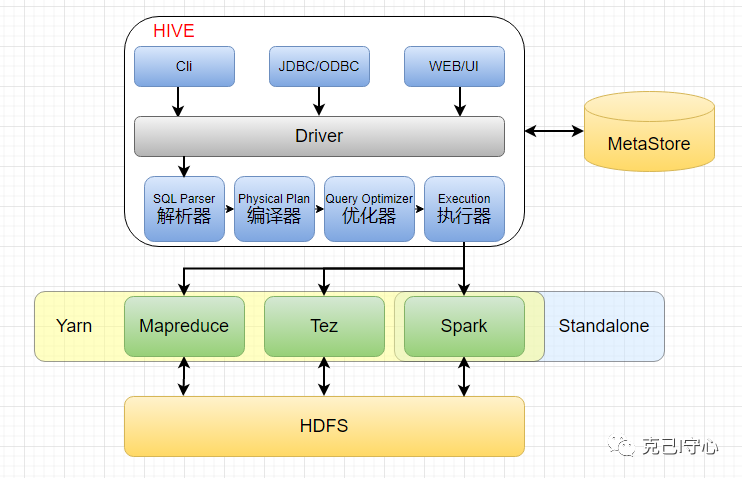
Inceptor 支持分布式部署,可以随着数据量的增长而进行横向扩展,同时还支持自定义扩展,能够满足不同场景的需求。 建议的常规操作是TDFS(星环版的HDFS)上的ORC格式文件存储;高性能操作就是Holodesk文件存储了。 两者都支持横向扩展,能满足大数据的需求。 多租户、多用户和多任务支持Inceptor 支持多租户和多用户,可以对数据进行权限控制和隔离,同时还支持多任务执行,能够满足企业级大数据应用的需求。 Inceptor的不足作为一种大数据查询和分析工具,星环大数据平台的 Inceptor 具备较高的性能和灵活性,但也存在一些缺点: 学习成本较高:虽然 Inceptor 支持 SQL 查询语言,但是其使用和配置仍需要一定的学习成本,特别是对于初学者来说。 对于小规模数据的处理不够高效:Inceptor 适合于海量数据的处理和分析,但对于小规模数据的处理可能不够高效。因为其底层数据处理基于spark实现,在默认情况下,处理每个文件都需要启动一个任务,任务维护以及调度的开销比较大。 安装和配置相对复杂:在安装和配置 Inceptor 时需要涉及到多个组件和服务的配置,需要一定的技术能力和经验。这也是整个星环平台面临的问题,需要整个的星环体系的加持,上手成本天然很高,不太适合中小企业或者数据场景。 对于实时查询的支持有限:Inceptor 基于 Hive 实现,虽然底层使用了定制版的spark,且有Holodesk这种性能利器的加持,但是对于实时查询的支持相对有限,需要结合其他工具和技术(如ArgoDB)进行处理。 开源社区相对较小:Inceptor 是星环科技自主开发的产品,相对于开源社区产品,其开源社区相对较小,生态相对不够完善。 与Hive对比:青出于蓝而胜于蓝星环大数据平台的 Inceptor 和 Apache Hive 都是基于 Hadoop 生态系统的大数据查询和分析工具,它们有一些共同点,也存在一些差异。 HIVE架构图:
共同点: SQL 查询语言支持:Inceptor 和 Hive 都支持 SQL 查询语言,可以使用熟悉的 SQL 语句进行数据查询和分析。 类似的生态系统:Inceptor 和 Hive 都是基于 Hadoop 生态系统或者类Hadoop生态系统的大数据查询和分析工具,可以处理海量的数据。 支持分布式部署:Inceptor 和 Hive 都支持分布式部署,可以随着数据量的增长进行横向扩展。 差异点: 性能:Inceptor 在性能方面相对于 Hive 有一定优势,因为 Inceptor 基于 Hive 进行了优化,并且使用了一些新的技术。 功能:Inceptor 在功能方面相对于 Hive 更加强大,它不仅支持数据仓库和数据集成,还支持多租户和多用户等特性,可以满足更多的大数据应用场景。 学习成本:Inceptor 在学习成本方面相对于 Hive 更高,因为 Inceptor 使用的是一些新的技术和架构,需要更多的学习和理解。 社区支持:Hive 作为 Apache 的开源项目,拥有庞大的社区支持和生态系统,而 Inceptor 的开源社区相对较小,生态相对不够完善。 综上所述,Inceptor 在性能和功能方面相对于 Hive 更加优秀,但在学习成本和社区支持方面存在一定差距。 总结由于Inceptor是在HIVE的基础上进行了部分优化和定制化而产生的组件,所以刨除其他条件来看,显然Inceptor比HIVE更优秀。 但是刨除其他条件显然是耍流氓的行为,Inceptor的优秀是基于很多先决条件的,比如说星环的整套体系的加成以及某些组件硬件的加成。还有就是整个星环体系的学习和上手成本也同样让很多人望而却步。 好在星环是商业的大数据平台,理论上能用钱解决所有的问题。所以到底是自力更生艰苦奋斗奋战开源,还是能用钱解决的问题都不是问题,这个球又踢回给各位使用者自己了! 文章到这里就结束了,最后路漫漫其修远兮,技术之路还很漫长。如果想一起学习各种技术的小伙伴,欢迎点赞转发加关注,下次学习不迷路,我们在技术的路上共同前进!
|




【本文地址】
今日新闻 |
推荐新闻 |