旅行足迹分析与可视化 |
您所在的位置:网站首页 › 旅游可视化信息图表 › 旅行足迹分析与可视化 |
旅行足迹分析与可视化
|
要求:对原始数据进行处理;对每个省/直辖市的旅游者进行聚类,聚类算法自选;设计可视化展示方式,在地图上展示每个省/直辖市的典型旅行者的信息及旅行者数量等,实现可视化过程; 目录 一.数据分析 二.数据处理 1.性别数字化 2.足迹计数 3.根据省/直辖市筛选数据 三.数据聚类 1.K-means聚类 2.将聚类好的数据保存到execl中 3.找到离聚类中心最近的样本 四.可视化 主要难点 最后效果 一.数据分析
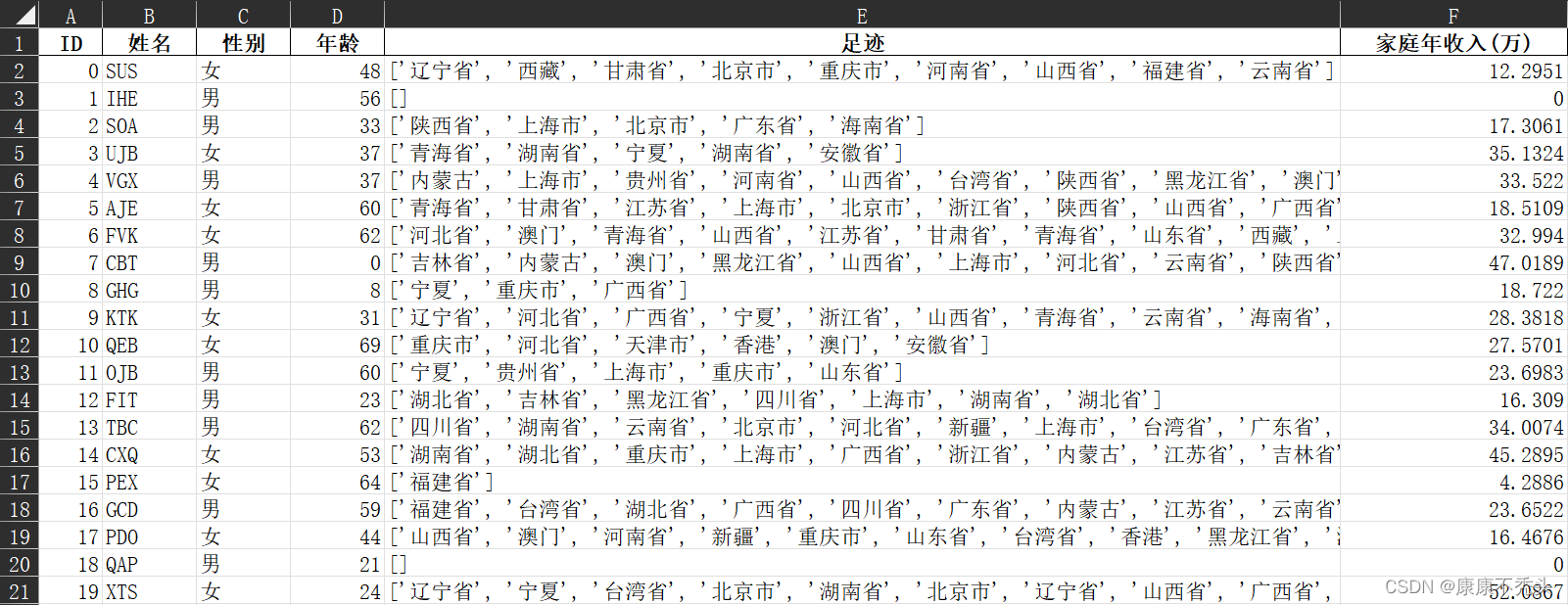
原始数据包括ID、姓名、性别、年龄、足迹和家庭年收入一共6列数据,首先需要读取excel文件的数据。 inputfile = 'dataset.xlsx' # 旅行者信息 data = pd.read_excel(inputfile, index_col = 'ID') # 读取数据 print(data.head()) # 打印前五行数据将数据文件放在PyCharm的当前工作目录下,就可以直接读取文件信息,以ID为列索引读取文件。其中足迹中包含每个旅行者去过的地方,而题目要求对每个省/直辖市的旅游者进行聚类,所以需要将每个省/直辖市的旅游者给筛选出来。
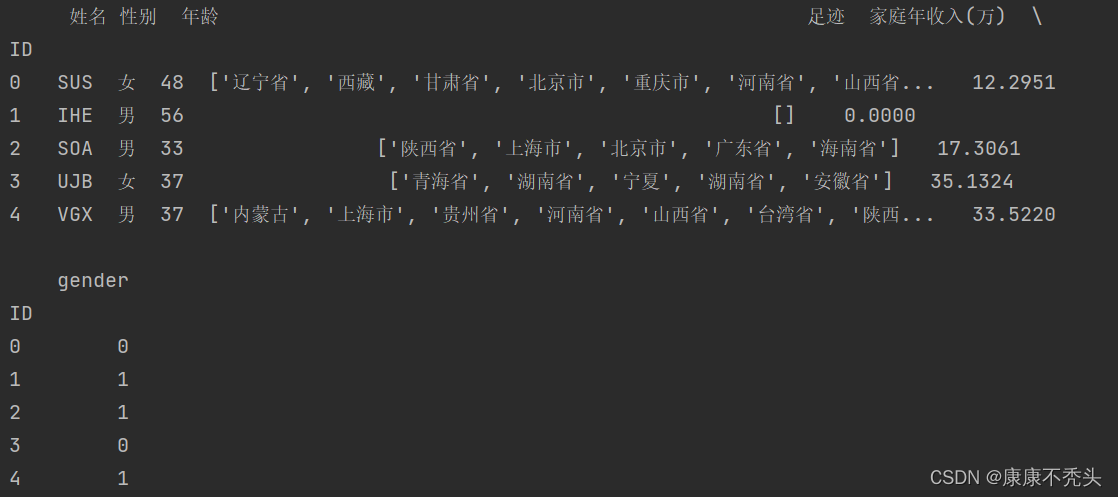
文本信息并不能直接聚类,如果要把性别作为聚类标准之一的话,需要先将性别数字化。 def get_gender_type(x): if x["性别"] == '男': return 1 if x["性别"] == '女': return 0 # 注意需要设置axis==1,表示series的index是columns data.loc[:, "gender"] = data.apply(get_gender_type, axis=1)编写函数,性别为男设置为数字1,性别为女设置为数据0,通过在数据后面添加新的一列gender表示。
如果数据量太少的话可以挖掘数据来提高聚类的可靠性,这里编写函数对足迹中去过的省/直辖市进行计数,并生成新的列。 def get_number_type(x): if x.loc['足迹'].count(',') > 0: return x.loc['足迹'].count(',') + 1 elif x.loc['足迹'].count(',') == 0: if len(x.loc['足迹'])>2: return 1 else: return 0 data.loc[:, "visit numbers"] = data.apply(get_number_type, axis=1)这里通过逗号的个数进行计数,有个小缺陷,足迹中省/直辖市是可以重复的,表示多次去过这个地方,这个函数并不能统计去过省/直辖市的个数,只能统计足迹中省/直辖市的个数。
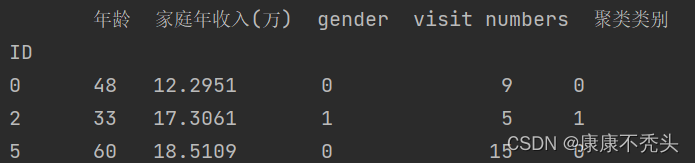
首先建立数组存放各个省/直辖市的名字,另建一个数组存放筛选好的数据,采用for循环筛选。 sheng_name = ['北京市','天津市','河北省','山西省','辽宁省','吉林省','黑龙江省','江苏省','浙江省','安徽省','福建省','江西省','山东省','河南省','湖北省','湖南省','广东省','海南省','四川省','贵州省', '云南省','陕西省','甘肃省','青海省','台湾省','内蒙古','广西','西藏','宁夏','新疆','上海 市','重庆市','香港','澳门'] sheng = [' 0',' 1',' 2',' 3',' 4',' 5',' 6',' 7',' 8',' 9',' 10',' 11',' 12',' 13',' 14',' 15',' 16',' 17',' 18',' 19', ' 20',' 21',' 22',' 23',' 24',' 25',' 26',' 27',' 28',' 29',' 30',' 31',' 32',' 33',' 34',' 35'] for num in range(0,len(sheng_name)): sheng[num] = data.loc[data["足迹"].str.contains(sheng_name[num]), :] 三.数据聚类 1.K-means聚类这里数据标准化效果并不好,故没有采用,将筛选好的数据聚成3类。 k = 3 # 聚类的类别 iteration = 500 # 聚类最大循环次数 for num in range(0,len(sheng_name)): sheng[num] = data.loc[data["足迹"].str.contains(sheng_name[num]), :] sheng[num] = sheng[num].drop(labels=['姓名', '性别', '足迹'], axis=1) # 将无关数据剔除 sheng_zs[num] = sheng[num] #sheng_zs[num] = 1.0 * (sheng[num] - sheng[num].mean()) / sheng[num].std() # 数据标准化 model = KMeans(n_clusters=k, max_iter=iteration, random_state=1234) # 分为k类,并发数4 model.fit(sheng_zs[num]) # 开始聚类 # 简单打印结果 r1 = pd.Series(model.labels_).value_counts() # 统计各类别数目 r2 = pd.DataFrame(model.cluster_centers_) # 找出聚类中心 r = pd.concat([r2, r1], axis=1) r.columns = list(sheng_zs[num].columns) + ['类别数目'] # 重命名表头 print(r) # 详细输出原始数据及其类别 r = pd.concat([sheng[num], pd.Series(model.labels_, index=sheng[num].index)], axis=1) # 详细输出每个样本对应的类别 r.columns = list(sheng[num].columns) + ['聚类类别'] # 重命名表头 print(r)第一个r打印出来的是聚类中心以及类别数目,可以看出性别数据在0~1之间的0.5,说明性别对聚类的影响并不大,同时可以观察到visit numbers和家庭年收入相关性比较大,数据有点冗余。
第二个r则是数据后面加上了类别这一列。
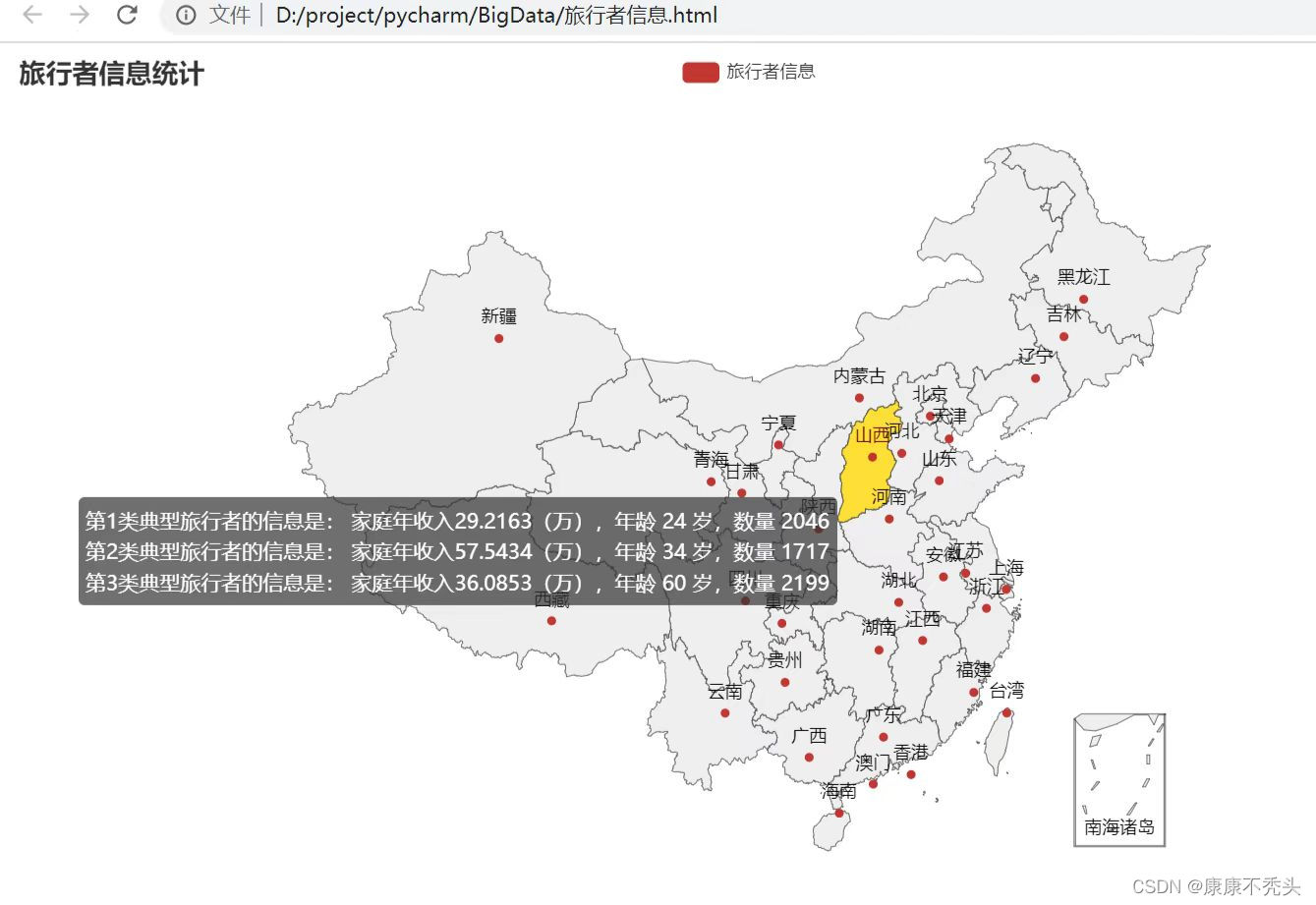
如果想要仔细查看聚类的效果,可以将数据保存为.xlsx文件,这里提供一个方法。 outputfile = 'traveler.xlsx' # 保存结果的文件名 df = pd.DataFrame() df.to_excel(outputfile) # 保存结果 excel_writer = pd.ExcelWriter(outputfile) for num in range(0,len(sheng_name)): r.to_excel(excel_writer, sheet_name=sheng_name[num]) excel_writer.save() excel_writer.close()生成的xlsx文件里有多个sheet,sheet名是对应的省名称。 3.找到离聚类中心最近的样本 display = '' for iclust in range(model.n_clusters): # get all points assigned to each cluster: cluster_pts = sheng[num][model.labels_ == iclust] # get all indices of points assigned to this cluster: cluster_pts_indices = np.where(model.labels_ == iclust)[0] cluster_cen = model.cluster_centers_[iclust] min_idx = np.argmin([euclidean(sheng[num].iloc[idx], cluster_cen) for idx in cluster_pts_indices]) element = str("第"+str(iclust+1)+"类典型旅行者的信息是: "+"家庭年收入"+str(sheng[num].iloc[cluster_pts_indices[min_idx]].loc["家庭年收入(万)"])+"(万),年龄 "+str(int(sheng[num].iloc[cluster_pts_indices[min_idx]].loc["年龄"])) + " 岁,数量 "+str(r1[iclust])+'') display = display + elementmodel.n_clusters是数据分类的类别数,这里是3。np.where获得对应类别样本的行索引,cluster_cen获得聚类中心,min_idx获得离聚类中心欧几里得距离最小样本的行索引,最后地图上需要显示的数据用字符串element拼接。 四.可视化在中国地图上显示信息,实现当鼠标停留在对应省/直辖市上显示对应典型旅行者的信息和数量。利用pyecharts库里面的功能。 js_code_str= ''' function(params){ var data = %(display)s; return data[params.value]; } ''' # 旅行者信息显示 def create_china_map(): ''' 作用:生成中国地图 ''' ( Map(init_opts=opts.InitOpts(width="1000px", height="600px")) # 可切换主题 .set_global_opts( title_opts=opts.TitleOpts(title="旅行者信息统计"), tooltip_opts=opts.TooltipOpts(is_show=True,trigger_on='mousemove|click',axis_pointer_type='cross',formatter=JsCode(js_code_str% dict(display=display_content))) ) .add("旅行者信息",data_sheng, maptype="china") .render("旅行者信息.html") ) create_china_map() 主要难点这里需要显示的字符串都保存在变量中,而这些变量怎么显示在地图上并可以对应到省,这里花了不少时间试错,最后采用tooltip_opts来进行提示框配置,其中js_code_str中如果要引用外部变量需要像函数一样传参,这里在js_code_str中定义变量data来接收,并通过params.value来确定省对应的数组元素。 最后效果
|



【本文地址】
今日新闻 |
推荐新闻 |