博弈论基础读书笔记三 完全信息动态博弈和逆向归纳法 |
您所在的位置:网站首页 › 斯坦伯格博弈模型求解 › 博弈论基础读书笔记三 完全信息动态博弈和逆向归纳法 |
博弈论基础读书笔记三 完全信息动态博弈和逆向归纳法
|
第二章完全信息动态博弈 先来说明两个概念: 1、静态博弈是指在博弈中,参与人同时选择或虽非同时选择但后行动者并不知道先行动者采取了什么具体行动。 2、动态博弈是指在博弈中,参与人的行动有先后顺序,且后行动者能够观察到先行动者所选择的行动。 这一章,我们来讨论关于完全信息(即参与者的收益函数是共同知识的博弈)动态博弈的问题。 在这里我们还将博弈分为两种: 完美信息博弈:即要选择行动的参与者完全知道这一步之前所有的博弈过程。 完全但不完美信息博弈:即要选择行动的参与者不知道这一步之前的博弈过程。 进行这章之前先简要的解释一些东西: 所有的动态博弈的中心问题都是可信任性。下面给一个经典的手雷博弈的例子: 第一, 参与者1可以选择支付1000美元给参与者2或者是一分不给。 第二, 参与者2观察参与者1的选择,然后决定是否引爆一颗手雷将两个人同 炸死。 如果参与者2威胁参与者1如果他不付1000美元就引爆手雷,如果参与者1相信这个威胁,则最优选择是支付1000美元。但参与者1却不会对这一威胁信以为真,因为它不可置信(参与者2不会蠢到因为1000美元而同归于尽,至于参与者1考虑参与者2是不是疯子的情况在第三章讨论)。 这个例子就是典型的完全且完美信息博弈。 在2.1节我们将在后面使用逆向归纳解,来求解这个问题。 在2.2节我们会丰富前一节的博弈模型使之成为完全但不完美博弈,我们会定义这种博弈的子博弈精炼解,它是逆向归纳法的延申。 在2.3节研究重复博弈,即多次重复一个给定博弈。这里分析问题的中心使(可信的)威胁和对以后做出的承诺对当前行为的影响。 在2.4节中我们介绍分析一般的完全信息动态博弈所需要的工具。不再区别信息是否是完美的。 本节和本章的重点都在语言,一个完全信息动态博弈可能会有多个纳什均衡,但其中一些均衡或许包含了不可置信的威胁和承诺,子博弈精炼纳什均衡则是通过了可信检验的均衡。 看到这里你可能还是一头雾水,但是无所谓,让我们一节一节的来讲,看到最后你在回头看前面的总结可能会更有利于你对本章的理解。
1.1. 逆向归纳法 完美且完全信息博弈有以下特点: 行动是顺序发生的 下一步行动选择之前,所有以前的行动都可以被观察到 每一可能的行动组合的收益函数都是共同知识我们通过逆向归纳法对这类问题进行求解: 当博弈的第二阶段参与者2行动时,由于参考参与者1的行动a1,他面临的决策问题可以以以下式子表示: 假定对A1中,每一个参与者2的优化问题只有唯一解,用R2(a1)表示,这是参与者2的最优反应。在这个问题中,参与者1、2都是理性的,并且这都是两者共同知道的知识,所以对于参与者1,他可以预测出R2(a1),那么对于参与者1,他在这个博弈中的决策问题为: 假定对于参与者1,这个问题依旧有唯一解,表示为a1*,那么称(a1*,R2(a1*))为这一博弈的逆向归纳解。在这个博弈中,我们排除了所有的不可置信威胁(比如手雷博弈中参与者2 的同归于尽),因为我们考虑的时候都是在考虑双方的最优解,并且双方都为理性人。当然也有多个解的情况,这就类似于纳什均衡中的多解 到这里可能看起来很容易(其实真的很容易),那么我们需要一个例子让我们对这个理论有更深刻的理解: 斯塔克尔贝里双头垄断模型 和上一章的古诺双头垄断模型类似,不过这里我们对参与者进行了修改:参与者1为支配企业,参与者2为从属企业。也就是说,在这个博弈中,市场规则和收益函数和古诺模型相同,区别是参与者1可以先选择产量,参与者2得到了参与者1的产量信息之后再选择自己的产量(古诺模型中两者产量是同时决定的,并且互相不知道对方要决定的产量)。 博弈顺序如下 企业1选择产量q1>=0 企业2观测到然后选择产量 收益由以下函数给出ui(qi,qj)=qi(a-qi-qj-c) 为了得到这个逆向解,我们首先计算出企业2对企业1的最优反应函数R2(q1): max u2(q1,q2)=q2(a-q1-q2-c) subject to q2>=0
由上式得: R2(q1)=(a-q1-c)/2 那么对于企业1当他计算出后,那么对于企业1来说,问题就变成了: max u1(q1,R2(q1)) subject to q1>=0 =max q1(a-q1-c)/2 subject to q1>=0 又上式可得, q1*=(a-c)/2 q2*=(a-c)/4 这就是斯塔克尔贝里双头垄断模型的逆向归纳解 之后我们来讨论从这个解中看到的东西,这也是为什么举这个例子的重要原因。 从结果我们可以计算出来,斯塔克尔贝里博弈中市场的出清价格要低于古诺博弈中的价格,但是在这个模型中,企业1完全可以选择古诺模型中的产量,从而和企业2达到古诺博弈中的平衡,而他没有这么做,证明他的利润水平提高了。同样,我们对比前后企业2 的收益情况,可以看出斯塔克尔贝里博弈中,企业2的利润有了明显降低。这就揭示了一个道理,在博弈论中,了解更多的信息(准确来说是作为一个参与者被别人了解更多信息),如参与者1知道参与者2能看到自己的产量,对于参与者2反而是不利的。 再来举个例子来理解这句话: 依旧是斯塔克尔贝里模型,不过这次参与者2无法得知参与者1第一阶段向市场投放的产量。那么会出现下面的情况: 如果企业1相信企业2选择它的斯塔克尔贝里产量,那么企业1会改变自己的策略,使其倾向于对 的反应,但是企业2也会推断到企业1这么想,从而改变自己的策略,同样,企业1也会预测到企业2预测到了企业1预测到了企业2会选择斯塔克尔贝里产量从而改变自己的策略…… 这样不断循环就会回到古诺博弈的平衡,所以对于企业2不知道企业1产量这一信息所得的利润要大于得知时的利润。 得知信息越多,利润反而可能会下降,这一结论违背我们的常识,但却是我们证明出的结果。在想想举例子前说的容易,是不是有了一些反差感,这就是数学美丽的地方,把一些看似简单易懂、看似无用的理论变成令人惊奇的东西。 |
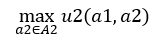
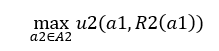
【本文地址】
今日新闻 |
推荐新闻 |