python中文短文本的预处理及聚类分析(NLP) |
您所在的位置:网站首页 › 文本聚类分析软件 › python中文短文本的预处理及聚类分析(NLP) |
python中文短文本的预处理及聚类分析(NLP)
|
python中文短文本的预处理及聚类分析(NLP)
对于中文短文本而言,其有着单个文本词量少,文本多等特点,并且在不同的领域中中文短文本有着不同的特点。本文以已获取的微博语料出发,使用DBSCAN密度聚类,并对其进行简单可视化。 #说明: 1-本文所有程序都已实现跑通,可直接复制调试,输入的文档为文本文档.txt,编码格式为utf-8(可以在另存为之中修改编码格式,默认为ANSI),注意每一行为一个短文本样本即可。 2-本文以python3.7为语言环境,使用到的jieba,sklearn等扩展包需要提前安装好。 1 原始文本的预处理 1.1 去除文本噪音对于原始文本,总会有很多东西是我们不需要的,比如标点、网址来源、表情转换符([西瓜]、[大笑])等,如下图所示。 接着,我们就可以对于储存到列表corpus中的每个预料字符串进行去噪了,在这里使用的是re库中的sub函数,为了方便阅读和修改,所以以罗列的方式展现,代码如下所示: stripcorpus = corpus.copy() for i in range(len(corpus)): stripcorpus[i] = re.sub("@([\s\S]*?):","",corpus[i]) # 去除@ ...: stripcorpus[i] = re.sub("\[([\S\s]*?)\]","",stripcorpus[i]) # [...]: stripcorpus[i] = re.sub("@([\s\S]*?)","",stripcorpus[i]) # 去除@... stripcorpus[i] = re.sub("[\s+\.\!\/_,$%^*(+\"\']+|[+——!,。?、~@#¥%……&*()]+","",stripcorpus[i]) # 去除标点及特殊符号 stripcorpus[i] = re.sub("[^\u4e00-\u9fa5]","",stripcorpus[i]) # 去除所有非汉字内容(英文数字) stripcorpus[i] = re.sub("客户端","",stripcorpus[i]) stripcorpus[i] = re.sub("回复","",stripcorpus[i]) 1.2 jieba分词接着,我们在只剩下汉语的stripcorpus列表中,将字符串长度小于5的去除,并使用jieba进行分词,代码如下所示: import jieba.posseg as pseg onlycorpus = [] for string in stripcorpus: if(string == ''): continue else: if(len(string) |
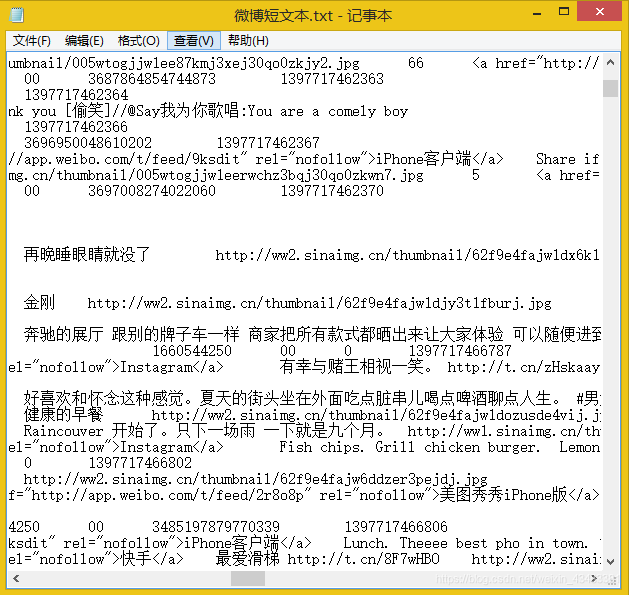 因此我们首先读取记事本中的内容,并按照每行的格式保存到python列表list中,代码如下所示:
因此我们首先读取记事本中的内容,并按照每行的格式保存到python列表list中,代码如下所示:【本文地址】
今日新闻 |
推荐新闻 |