MS:如何衡量企业创新?基于文本分析的新度量办法 |
您所在的位置:网站首页 › 文本分析能力 › MS:如何衡量企业创新?基于文本分析的新度量办法 |
MS:如何衡量企业创新?基于文本分析的新度量办法
|
研究采用隐狄利克雷分配(latent Dirichlet allocation,LDA)模型。 LDA作为基于贝叶斯学习的话题模型,是潜在语义分析、概率潜在语义分析的扩展,于2003年由Blei等人提出,本质上是一种基于概率分布的文本挖掘手段,首先它将每篇文章看做话题的组合,而每个话题则是一组词汇的集合,在这个集合中可以统计各个词汇的分布。目前在文本数据挖掘、图像处理、生物信息处理等领域被广泛使用。 训练数据来自标普数据库,涵盖了1990-2010之间703家企业共6200条观测,收集了企业创新的一些基本属性。特别是相比传统的专利和R&D支出度量,该度量模型囊括了企业创新所具备的时间序列和横截面特征。
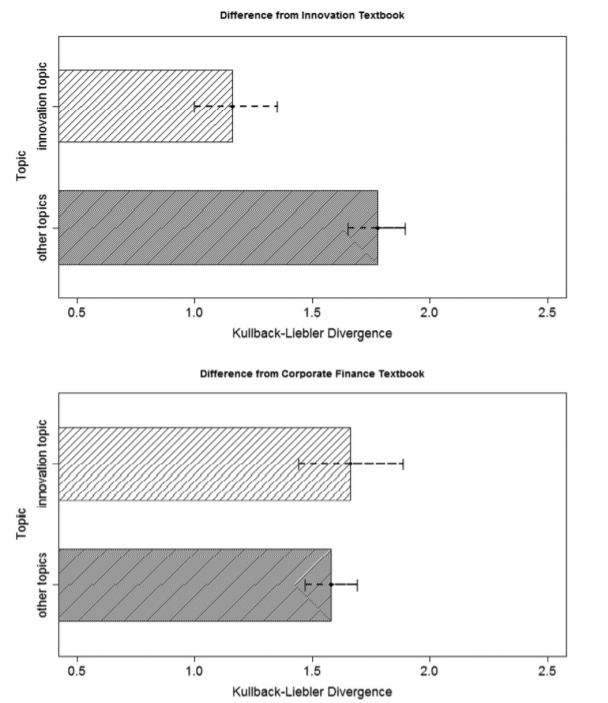
图1
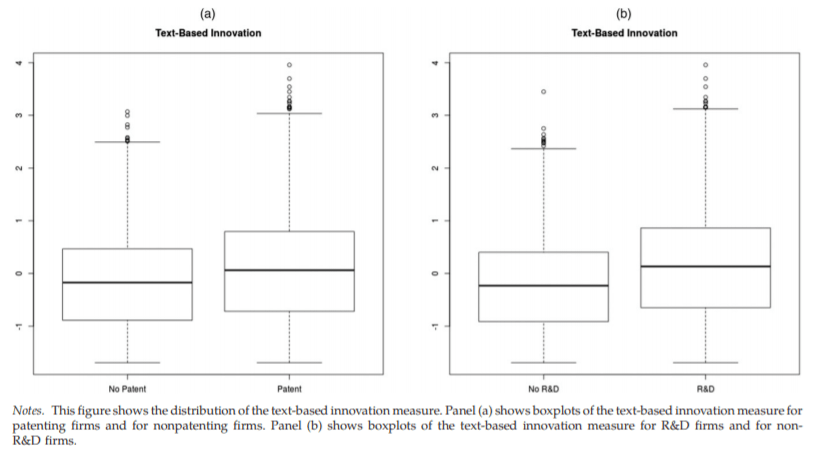
图2 04 实证结果 01 一致性 文章采用基于文本的创新度量对企业的专利申请和R&D花费进行了描述性统计,发现新的创新度量方法可以反映传统的专利度量方法和R&D度量方法所捕获的创新行为。
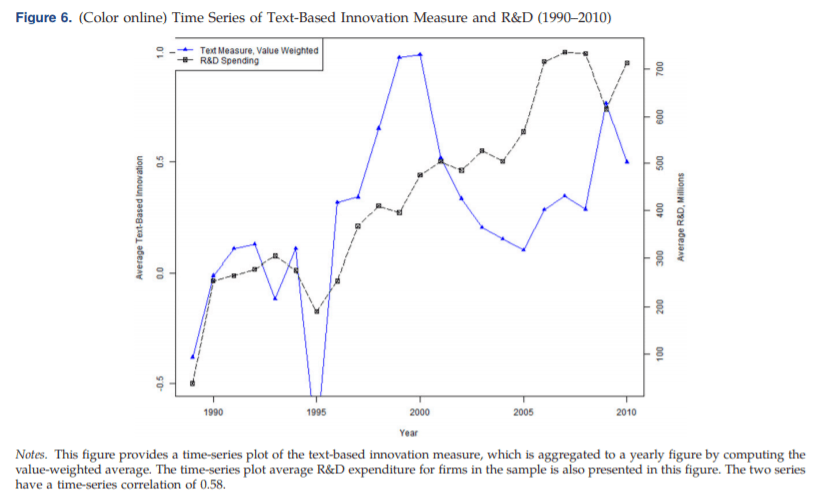
图3
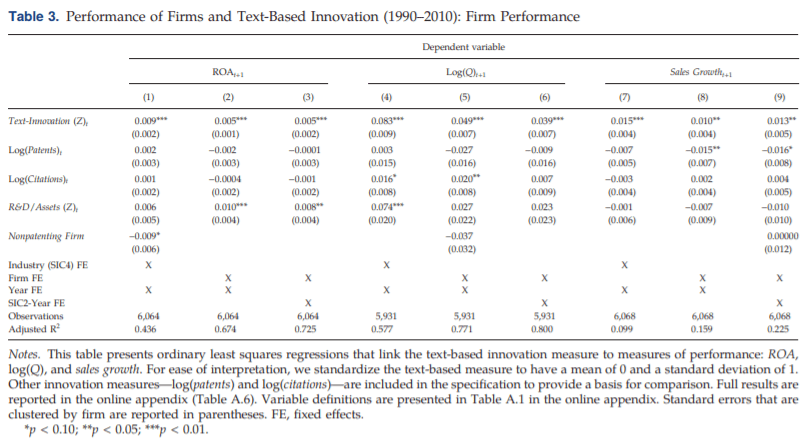
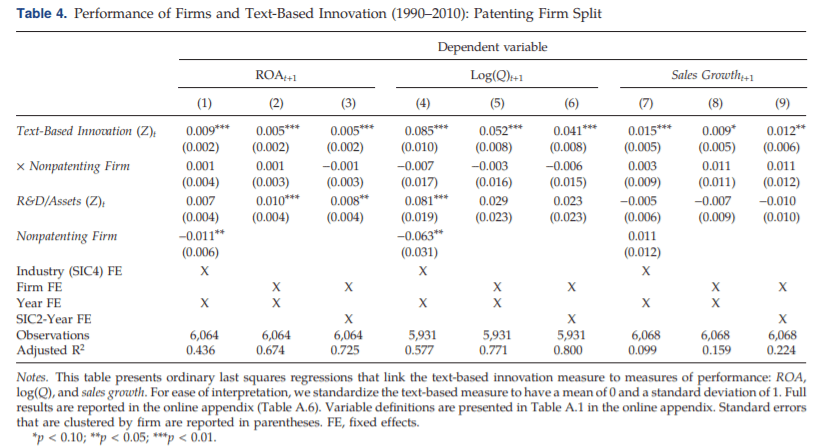
图4 文章基于分析报告中披露情感和企业披露创新行为的顺序进行了详实的稳健性检验,详见论文。 02 有效性 表1验证了三种不同的创新度量和企业绩效之间的关系。在基于文本的度量中,企业内部的创新变化是未来经营绩效的一个有用的预测指标,并且这种关系不能被行业水平上的不可观测因素所解释。 基于文本的创新度量相比基于专利数量、专利引用和R&D的度量与经营绩效的关系更为密切。(尽管R&D与未来经营绩效正相关,但R&D的统计显著性是边际的,且在的企业绩效指标之间不具有稳健性)
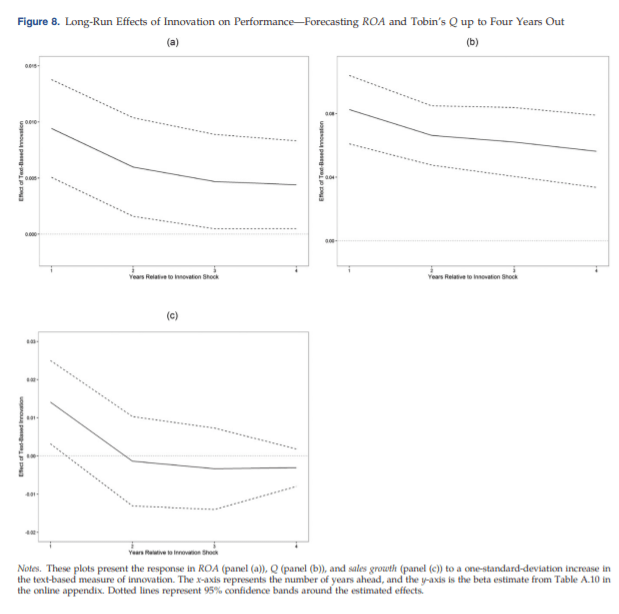
表1 文章进一步验证了基于文本分析的创新度量可以在评价企业创新对企业绩效的长期影响(1-4年)中发挥作用,随着时间的推移创新的效果可能会减弱。
图5 03 普适性
表2 04 高效性 此外,基于文本分析的创新度量可以通过实时分析报告来计算,而传统基于专利的创新度量耗时更长 (例如,即使最终批准的专利申请数量也必须等待专利被批准或被拒绝)。因此,基于文本分析的方法是更高效的。 05 结论与展望 Schumpeter (1934)提出了五种类型的企业创新:新产品、新生产方法、新供应来源、新市场的开发和企业组织的新方式。传统专利和R&D创新度量方式具有较大的局限性。本文通过扩大研究样本,形成语料库并使用LDA文本分析提供了可靠的基于文本分析的创新度量手段。 最后,虽然我们的分析应用于分析报告的文本,但我们的文本方法可以应用于除了分析报告的其他材料,以更精准定位创新行为(e.g., see the analysis of product innovation in Mukherjee et al. 2017 using press releases),未来这种度量方法将会获得更长足的进步。 此外文章还发现在拥有多面手CEO的公司中,基于文本分析测度的创新水平普遍较低,在我们已经得知创新与企业绩效的关系后,这个问题值得深思。 编辑 | 段蒙汉、邓皓文 排版 | 王琳
END
|


 返回搜狐,查看更多
返回搜狐,查看更多【本文地址】
今日新闻 |
推荐新闻 |