谈谈web树形目录结构的原理和操作 |
您所在的位置:网站首页 › 文件夹是树形结构 › 谈谈web树形目录结构的原理和操作 |
谈谈web树形目录结构的原理和操作
|
拨号项目中,虽然自己也鼓捣个树形结构,但思路却不是很清晰,而且是利用树形结构信息是存在xml文件中的。看完drp,并不难,但感触最深的是王勇老师分析问题,把解决问题的思路清晰化。
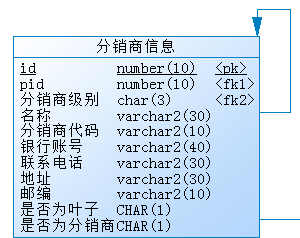
对树形结构,从数据表、web前端div生成树原理,再到对树形信息的增删改查,由两边向中间逐层分析。 数据库设计 树的几种设计方式 不带冗余字段,id,pid。效率低,查找相对繁琐。 带冗余字段,id,pid,isleaf,childrencount。多冗余字段,但方便查找。 采用固定字符串,00010010001。不易理解,编程复杂。 00,所有分销商 01,华北区001,北京市 0001,北京医药股份有限公司
这里采用第二种,带冗余字段id,pid。 自关联,id为主键,pid(parent id)为外键
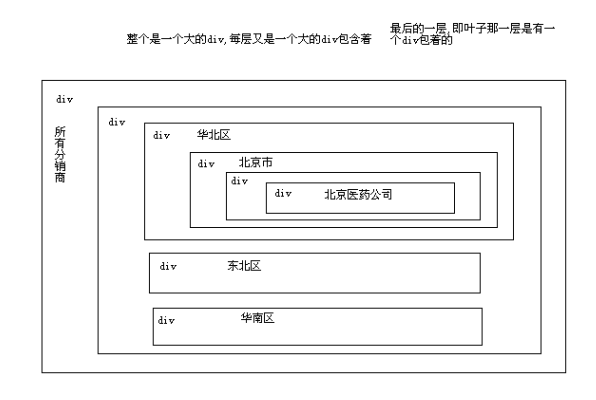
div生成树的原理
原理图:
html  所有分销商
华北区
北京市
北京医药股份有限公司
东北区
华南区
所有分销商
华北区
北京市
北京医药股份有限公司
东北区
华南区
js控制 functiondisplay(id) { eval("var div=div"+id); eval("var img=img"+id); eval("var im=im"+id); div.style.display=div.style.display=="block"?"none":"block"; img.src=div.style.display=="block"?"../images/minus.gif":"../images/plus.gif"; im.src=div.style.display=="block"?"../images/openfold.gif":"../images/closedfold.gif"; img.alt=div.style.display=="block"?"关闭":"展开"; } 树的读取 id,pid递归读取 ClientTreeReader.java /** * 完成分销商树的递归读取 * @author Administrator * */ publicclass ClientTreeReader { privateStringBuffer sbTreeHTML = new StringBuffer(); /** * 返回HTML字符串 * @return */ publicString getClientTreeHTMLString() { Connectionconn = null; try { conn= DbUtil.getConnection(); readClientTree(conn,0, 0); }catch(Exceptione) { e.printStackTrace(); }finally{ DbUtil.close(conn); } returnsbTreeHTML.toString(); } /** * 递归读取分销商树 * *第四步: 采用div生成树形结构 * @param conn * @param id * @param level 控制层次 */ privatevoid readClientTree(Connection conn, int id, int level) throwsSQLException { Stringsql = "select * from t_client where pid=?"; PreparedStatementpstmt = null; ResultSetrs = null; try { pstmt= conn.prepareStatement(sql); pstmt.setInt(1,id); rs =pstmt.executeQuery(); while(rs.next()) { sbTreeHTML.append(""); sbTreeHTML.append("\n");// \n html代码换行显示 布局换行显示 for(int i=0; i |

【本文地址】
今日新闻 |
推荐新闻 |