Numpy中统计函数的讲解:平均值、中位数、标准差、方差、最大最小值、求和、加权平均数 |
您所在的位置:网站首页 › 数组的常用统计函数有哪些特点 › Numpy中统计函数的讲解:平均值、中位数、标准差、方差、最大最小值、求和、加权平均数 |
Numpy中统计函数的讲解:平均值、中位数、标准差、方差、最大最小值、求和、加权平均数
|
目录 统计函数: Numpy 能方便地求出统计学常见的描述性统计量 一:Numpy中统计函数--平均值 求平均值 二:Numpy中统计函数--中位数 中位数 np.median 平均数和中位数的区别 三:Numpy中统计函数--标准差 求标准差ndarray.std() 四:Numpy中统计函数--方差 求方差ndarray.var() 标准差和方差的区别 五:Numpy中统计函数--最大最小值 求最大值: ndarray.max() 求最小值: ndarray.min() 六:Numpy中统计函数--求和 求和: ndarray.sum() 七:Numpy中统计函数--加权平均数 加权平均值numpy.average() 统计函数: Numpy 能方便地求出统计学常见的描述性统计量 一:Numpy中统计函数--平均值 求平均值 import numpy as np p=np.arange(20).reshape(4,5) print(p) #默认求出数组中所有元素的平均值 p.mean()
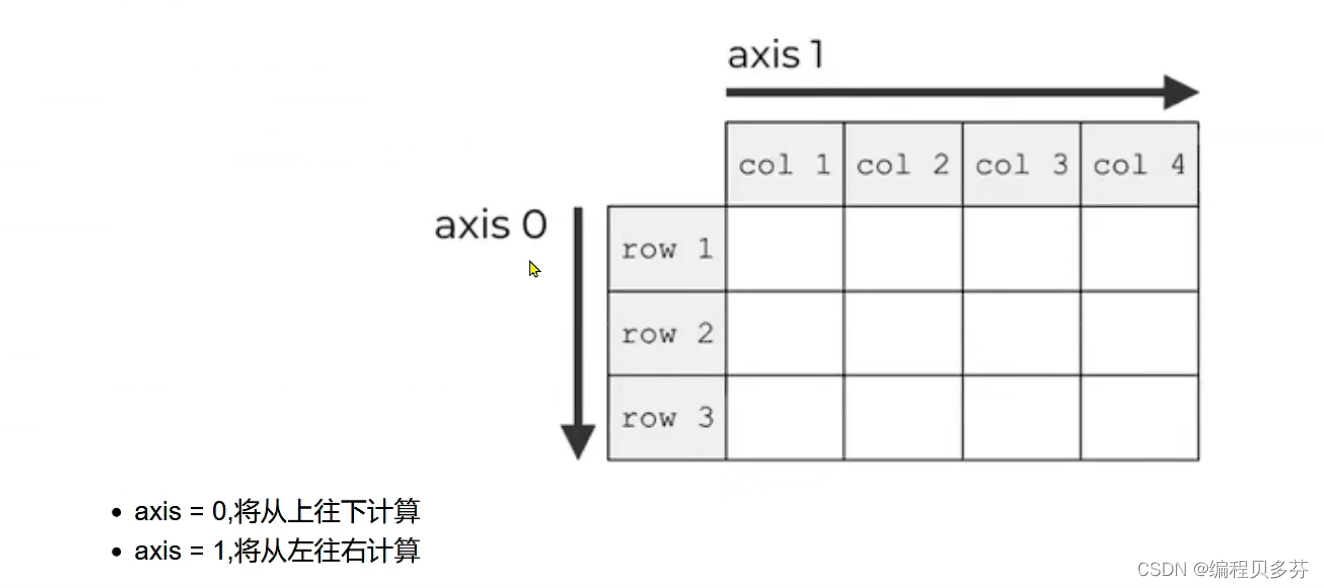
若想求某一维度的平均值,设置 axis 参数,多维数组的元素指定:
p=np.arange(20).reshape(4,5) print(p) print('-----------------') # axis=0时,求每一列的竖着的维度平均值 print(p.mean(axis=0)) #axis=1时,求每一行的横着的维度的平均值 p.mean(axis=1) 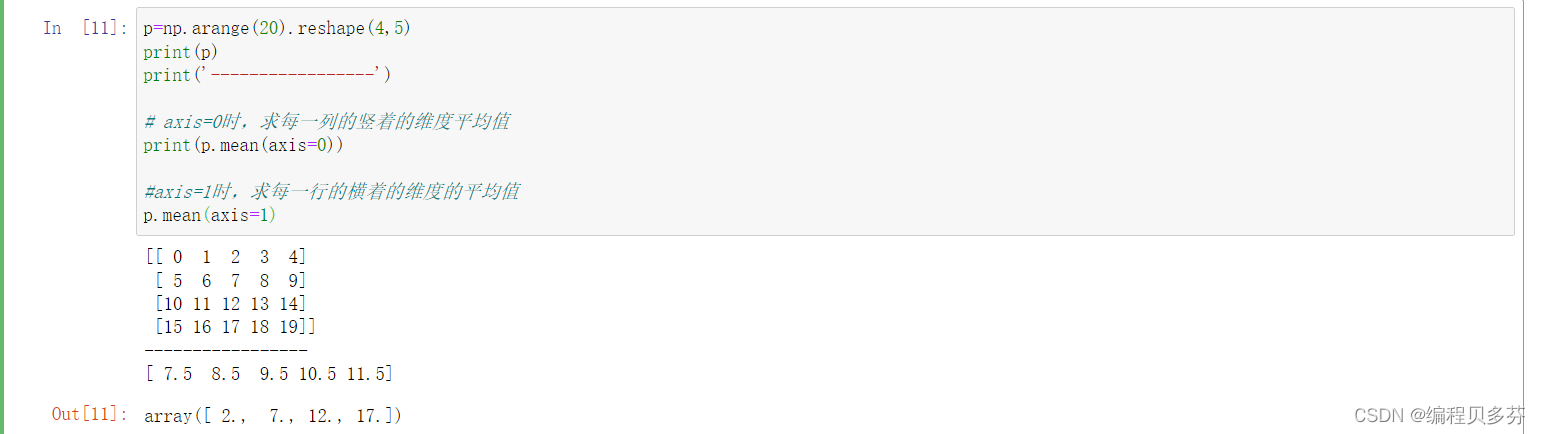
二:Numpy中统计函数--中位数 中位数 np.median 中位数又称中点数,中值 是按顺序排列的一组数据中居于中间位置的数,代表一个样本,种群或概率分布中的一个数组 平均数和中位数的区别·平均数:是一个"虚拟"的数,是通过计算得到的,它不是数据中的原始数据。 · 中位数:是一个不完全"虚拟""的数。 ·平均数:反映了一组数据的平均大小,常用来一代表数据的总体"平均水平"。 ·中位数:像一条分界线,将数据分成前半部分和后半部分,因此用来代表一组数据的"中等水平"¶ a=np.array([1,3,5,6,8]) print(a) np.median(a)
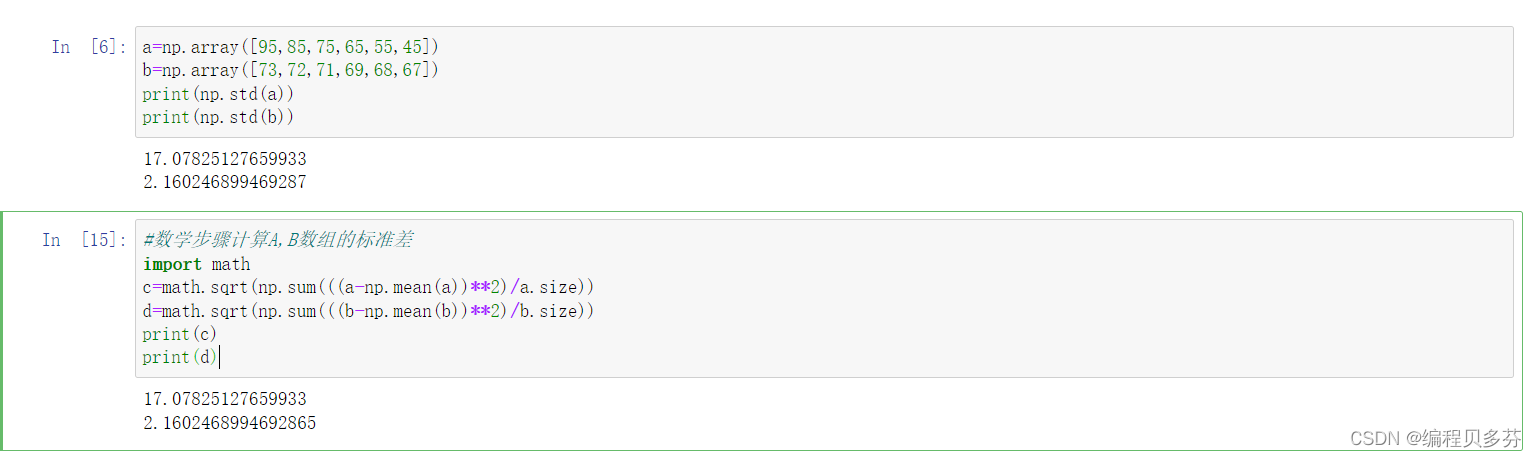
三:Numpy中统计函数--标准差 求标准差ndarray.std() 在概率统计中最常使用作为统计分布程度上的测量,是反映一组数据离散程度最常用的一种量化形式 标准差定义是总体各单位标准值与其平均数离差平方的算术平均数的平方根。 简单来说,标准差是一组数据平均值分散程度的一种度量。 --------------------------------- 一个较大的标准差,代表大部分数值和其平均值之间差异较大; --------------------------------- 一个较小的标准差,代表这些数值较接近平均值 例:A、B两组各有6位学生参加同一次语文测验,A组的分数为95、85、75、65、55、45, B组的分数为73、72、71、69、68、67。 分析那组学生之间的差距大?
a=np.array([95,85,75,65,55,45]) b=np.array([73,72,71,69,68,67]) print(np.std(a)) print(np.std(b)) #数学步骤计算A,B数组的标准差 import math c=math.sqrt(np.sum(((a-np.mean(a))**2)/a.size)) d=math.sqrt(np.sum(((b-np.mean(b))**2)/b.size)) print(c) print(d)
标准差的应用: 标准差应用于投资上,可作为量度回报稳定性的指标。标准差数值越大,代表回报远离过去平均数值,回报较不稳定故风险越高。相反,标准差数值越小,代表回报较为稳定,风险亦较小 四:Numpy中统计函数--方差 求方差ndarray.var()-----衡量随机变量或一组数据时离散程度的度量---与标准差类似作用 a=np.array([95,85,75,65,55,45]) b=np.array([73,72,71,69,68,67]) print('A的方差为:',np.var(a)) print('B的方差为:',np.var(b))
标准差和方差的区别 标准差有计量单位,而方差无计量单位,但两者的作用一样,虽然能很好的描述数据与均值的偏离程度,但是处理结果是不符合我们的直观思维的。 五:Numpy中统计函数--最大最小值 求最大值: ndarray.max()axis=0时,从上往下查找最大值; axis=1时,从左往右查找最大值 a=np.arange(30).reshape(5,6) print(a) print(a.max()) print('---------------------------------------------') print(a.max(axis=0)) print(a.max(axis=1))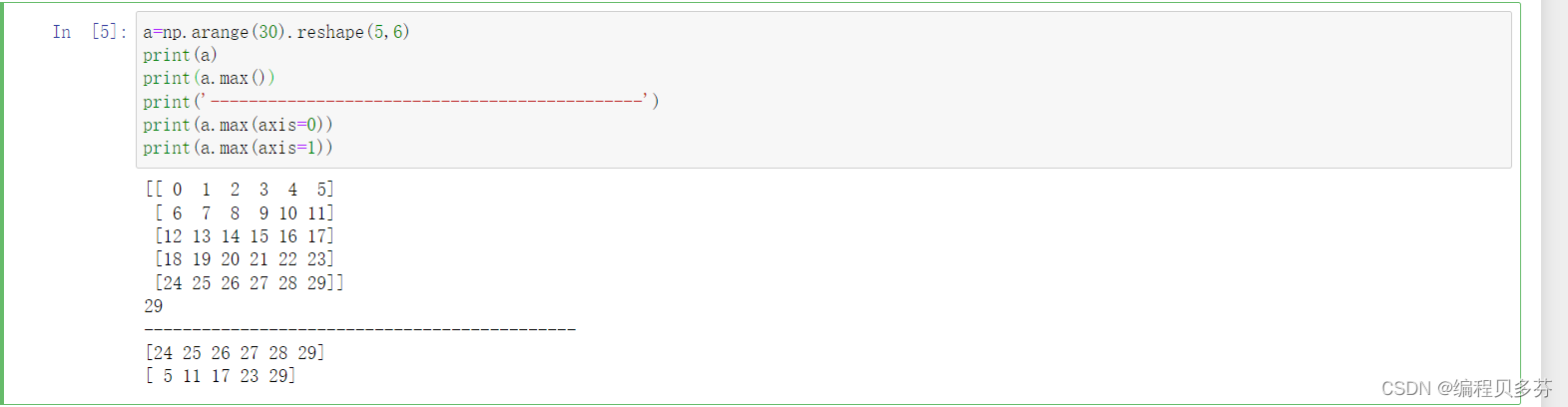
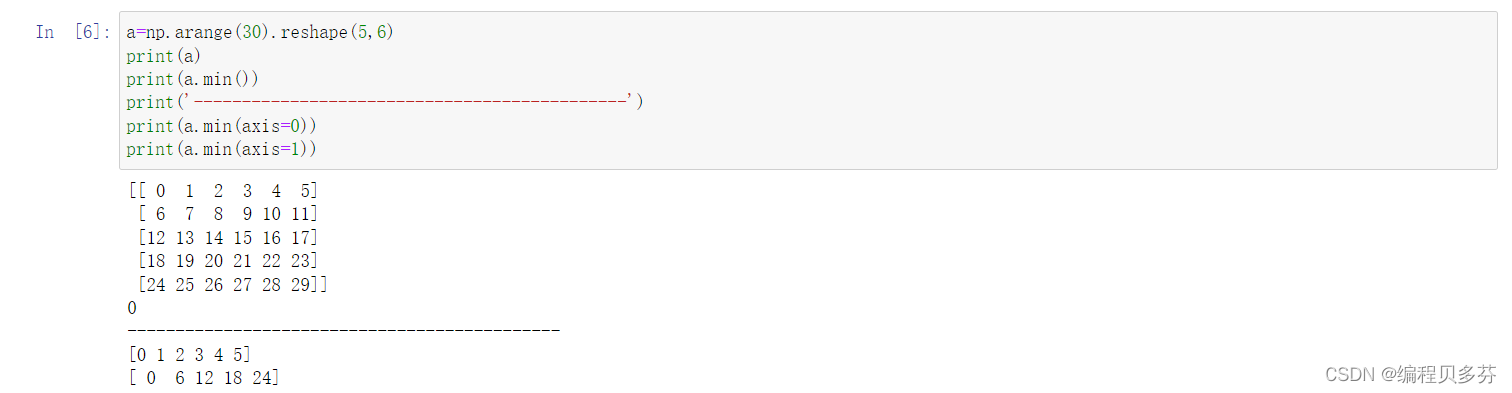
求最小值: ndarray.min() axis=0时,从上往下查找最小值; axis=1时,从左往右查找最小值 a=np.arange(30).reshape(5,6) print(a) print(a.min()) print('---------------------------------------------') print(a.min(axis=0)) print(a.min(axis=1))
六:Numpy中统计函数--求和 求和: ndarray.sum() axis=0时,从上往下求和; axis=1时,从左往右查求和 print(a) print(a.sum()) #从上往下求和 print(a.sum(axis=0)) #从左往右求和 print(a.sum(axis=1))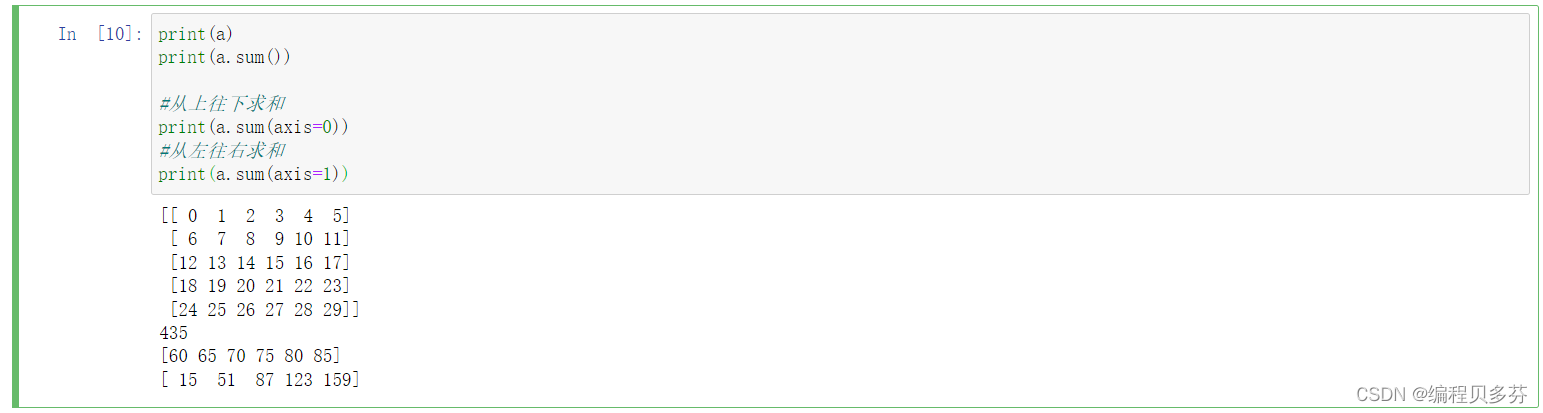 七:Numpy中统计函数--加权平均数
加权平均值numpy.average()
七:Numpy中统计函数--加权平均数
加权平均值numpy.average()
即将各数值乘以相应的权数,然后加总求和得到总体值,再除以总的单位数: numpy.average(a, axis=None, weights=None, returned=False) weights:数组,可选 与a中的值关联的权重数组。a中的每个值都根据其关联的权重对平均值做出贡献。权重数组可以是一维的(在这种情况下,它的长度必须是沿给定轴的a的大小)或与a具有相同的形状。如果weights=None,则假定a 中的所有数据的权重等于1。一维计算是: avg = sum(a*weights)/ sum(weights)----对权重的唯一限制是sum(weights)不能为0。 avarage_a=[10,20,30] print(np.mean(avarage_a)) print(np.average(avarage_a))
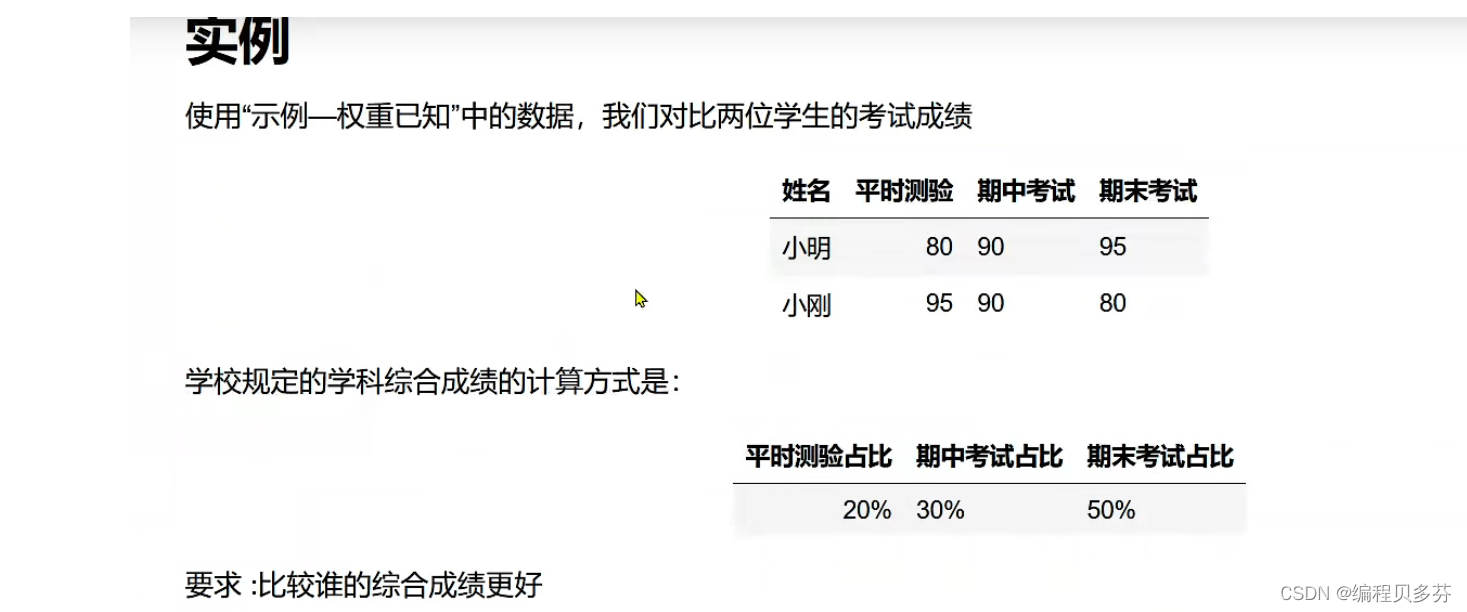
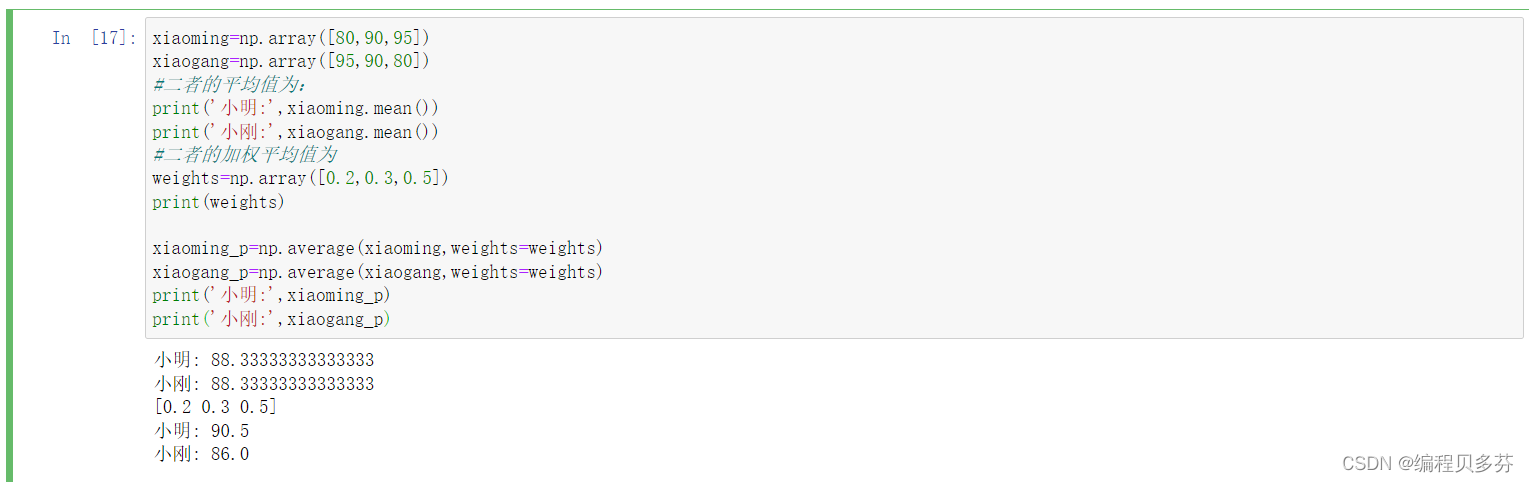
例题如下: xiaoming=np.array([80,90,95]) xiaogang=np.array([95,90,80]) #二者的平均值为: print('小明:',xiaoming.mean()) print('小刚:',xiaogang.mean()) #二者的加权平均值为 weights=np.array([0.2,0.3,0.5]) print(weights) xiaoming_p=np.average(xiaoming,weights=weights) xiaogang_p=np.average(xiaogang,weights=weights) print('小明:',xiaoming_p) print('小刚:',xiaogang_p)
|


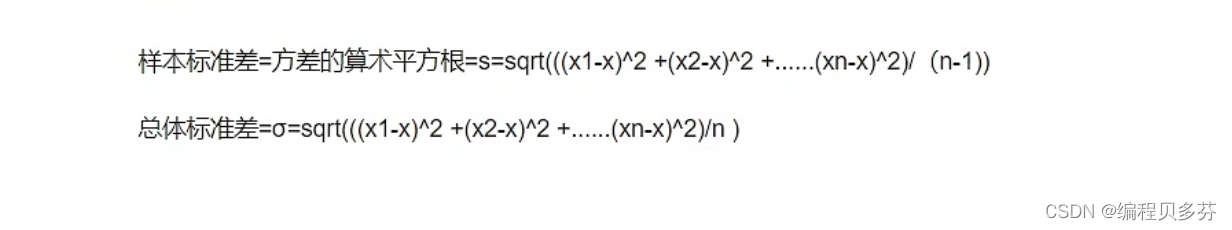

【本文地址】