⼤数据采集和可视化系统实现 |
您所在的位置:网站首页 › 数据采集的四个过程 › ⼤数据采集和可视化系统实现 |
⼤数据采集和可视化系统实现
|
前言 本篇博客用来记录 2022年春季大数据课程结课大作业(大三下,前8周,小组作业) 非常感谢小组同学的付出和积极配合! 文章目录 1. 实验目的2. 实验环境3. 实验要求4. 实验内容4.1 准备工作4.2 数据的采集和发送4.2.1 流程介绍4.2.2 实验过程4.2.3 源码解析 4.3 数据的消费和处理4.3.1 流程介绍4.3.2 实验过程4.3.3 源码解析4.3.4 程序集成 4.4 数据的存储4.4.1 Hbase存储4.4.2 Hive存储4.4.3 Hdfs存储4.4.4 Mysql存储 4.5 可视化展示4.5.1 后端实现4.5.2 前端实现4.5.3 网站部署 5. 踩坑记录6. 心得体会7. 团队协作 1. 实验目的了解Kafka、HDFS、MapReduce、Spark、HBase、Hive等组件在大数据体系结构中的角色,并通过本次综合实验对大数据技术在实际应用中的主要流程有初步的认识; 2. 实验环境实验平台:基于实验一搭建的虚拟机Hadoop大数据实验平台上的Kafka、HDFS、MapReduce、Spark、HBase、Hive等集群; 编程语言:JAVA(推荐使用)、Python、C++等; 3. 实验要求 编程实现Kafka生产者,模拟数据采集的过程,向指定topic发送数据。编写MapReduce或Spark程序,消费上述topic中的数据,并对数据进行一定的 处理,如求和、排序等。(鼓励使用流计算框架消费kafka上的数据,可以获得额外加分)上述程序将处理结果存储到HDFS文件系统中。(如果选用Hbase或Hive代替 HDFS,需要分别设计Hbase表或Hive表,会得到额外加分)将聚合后的结果通过简单的前端网页进行展示,这里可以考虑将聚合结果存储 到Mysql数据库再进行简单的展示。对以上实验内容编写实验报告,并提交实验相关代码。 4. 实验内容 4.1 准备工作同步cluster1、cluster2、cluster3的时间 // 重启时间同步服务(cluster1 上) service ntpd restart //同步时间(cluster2和cluster3) ntpdate cluster1
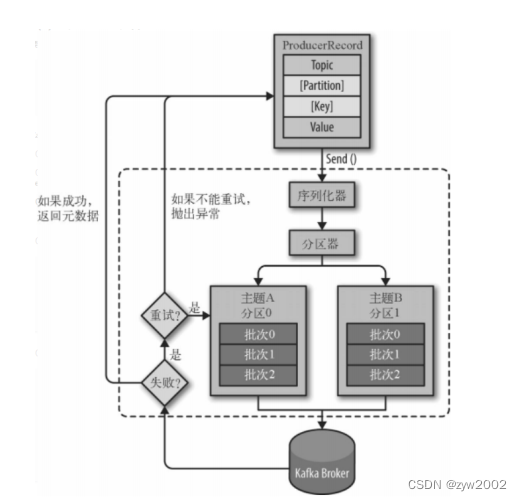
考虑到实际待处理的数据非常大,但是在测试的过程中并不需要处理全部的数据量,因此将代码设置成用户可以自定义发送数据的条数。生产者首先从txt文件中读取数据,然后每读取一行数据就发送一条,直到发送完指定数目的条数或者到达文件末尾。kafka生产者的发送流程主要如下图所示:
具体来说,一个kafka的生产者逻辑主要包括如下4个步骤 配置生产者客户端参数及创建相应的生产者实例。构建待发送的消息。发送消息关闭生产者实例 4.2.2 实验过程编写java代码实现Kafka生产者,模拟数据采集过程,向指定的topic发送数据。 在/home/hadoop目录下创建目录lab4用来存放实验数据和代码。(kafka采集数据实验.txt重命名为kafkadata.txt,内容不变)
由于直接上传的代码xftp默认是root用户,因此需要修改用户的权限。 //改变所有者为hadoop su root chown -R hadoop:hadoop /home/hadoop/
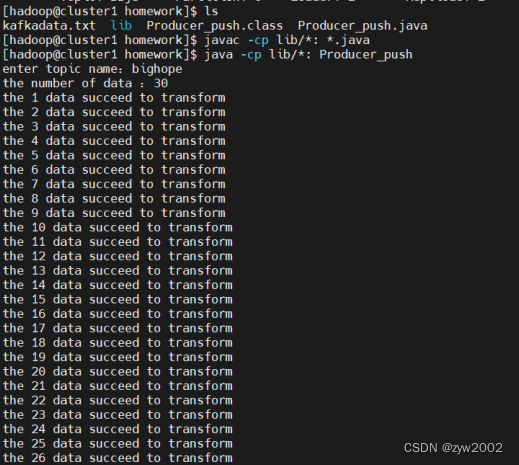
创建名称为dsj3 的topic,并先设置发送数据的行数是30条。 然后运行代码,成功的发送了前30条数据。
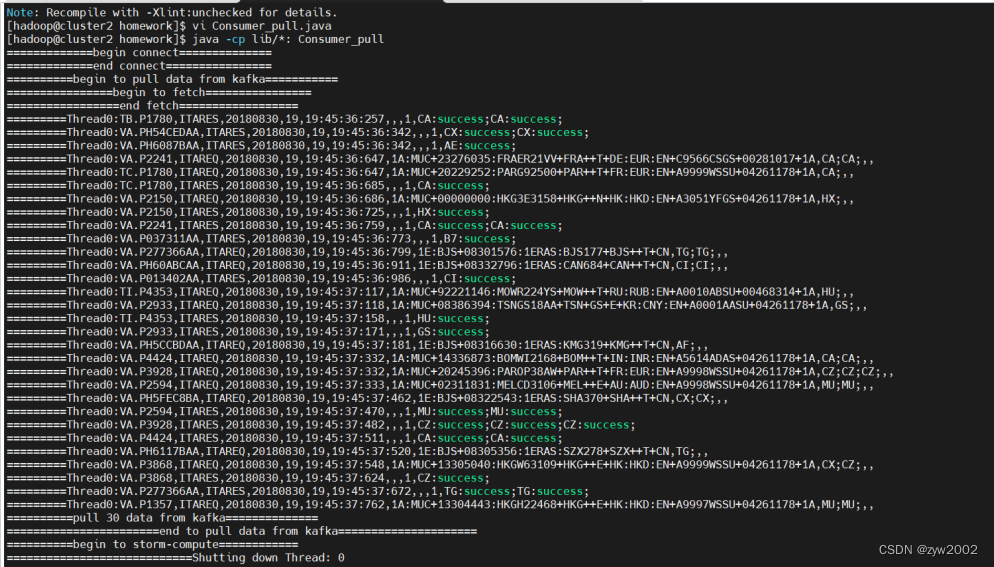
props.put("metadata.broker.list", "cluster1:9092")用来指定生产者客户端连接Kafka集群所需的broker地址清单,具体的内容格式为host1:port1,host2:port2,可以设置一个或多个地址,中间以逗号隔开,此参数的默认值为“”。注意这里并非需要所有的broker地址,因为生产者会从给定的broker里查找到其他broker的信息。在此,我们设置生产者为cluster1。 Producer3.java代码具体实现如下: import java.io.BufferedReader; import java.io.File; import java.io.FileReader; import java.io.IOException; import java.util.Properties; import java.util.Scanner; import kafka.javaapi.producer.Producer; import kafka.producer.KeyedMessage; import kafka.producer.ProducerConfig; public class Producer3 { public static void main(String[] args) { // 1.配置生产者客户端参数及创建相应的生产者实例。 Scanner in = new Scanner(System.in); Properties props = new Properties(); props.put("serializer.class", "kafka.serializer.StringEncoder"); // 序列化 props.put("metadata.broker.list", "cluster1:9092"); // broker 地址清单 Producer producer = new Producer(new ProducerConfig(props)); // 构建生产者 // 2. 构建待发送的消息 String topic; System.out.print("请输入topic名称:"); // 创建topic topic = in.next(); File file = new File("/home/hadoop/lab4/kafkadata.txt"); //文件读取路径 BufferedReader reader = null; System.out.print("请输入发送数据行数:"); int num = in.nextInt(); // 用户自定义数据发送的行数 // 3. 生产者发动消息 try { reader = new BufferedReader(new FileReader(file)); String tempString = null; int line = 1; while ((tempString = reader.readLine()) != null) { // 当没有达到文件末尾时,继续读取 producer.send(new KeyedMessage(topic, tempString)); // 生产者发送数据 System.out.println("成功发送第 " + line + " 行数据..."); if (line == num) // 当发送指定条数的数据后,停止发送 break; line++; } reader.close(); } catch (Exception e) { // 文件读取失败 e.printStackTrace(); } finally { if (reader != null) { try { reader.close(); } catch (IOException e1) { } } } // 4. 关闭生产者实例 producer.close(); } } 4.3 数据的消费和处理 4.3.1 流程介绍这一部分处理数据的逻辑就是kafka消费者接受来自生产者数据,然后在消费者端提交storm的topology,利用storm进行数据处理后将生成结果存储入库,再可视化展示。我们的消费者拉取数据类是Consumer_pull.java,拉取topic中的数据,支持多线程处理多个topic的分区,这里测试只采用了一个线程然后对应topic只建立了一个分区,对应消费实例是Consumer_storm,测试数据条数也只有30条。storm部分书写四个类,Topology类,Spout类,Split_Bolt类和Sum_Bolt类。Topology是提交的拓朴文件,描述storm数据流的拓朴结构,Spout是数据源,发送数据的源头,Split_Bolt和Sum_Bolt是两个数据处理类,分别用于分割数据和聚合数据。我们的结构非常简单,Spout — Split_Bolt — Sum_Bolt的线形结构,实验流程就是将消费者启动,再将生产者启动,输入topic名和数据条数,然后程序就启动成功。实现的功能是将航空公司日志聚合,统计出以一小时为时间间隔的时间段内各航空公司预定成功的数量。 4.3.2 实验过程首先在生产者端(cluster1)要部属我的自己混合的lib文件夹以及producer_push.java和kafka.txt,三个文件;在消费者端(cluster2)要部署lib和Consumer_pull.java Consumer_storm.java Topology.java Spout.java Split_Bolt.java 和Sum_Bolt.java 七个文件。lib文件夹中是程序运行所需要的包,解决了storm和kafka运行包冲突的问题,所以在编译和运行时只需要导入lib文件中的包即可。 在编译程序之前要先启动kafka以及storm,实验流程在实验一的手册中,流程不再赘述,有一点区别是storm的nimbus端是cluster2,也就是要将cluster2和cluster1的实验一storm操作流程对换。 编译程序,在程序根文件夹下键入命令 javac -cp lib/*: *.java编译成功 生产者端和消费者端都做如上编译处理,编译成功后,要先在生产者端利用kafka的console创建一个topic,键入命令如下,创建bighope主题名 kafka-topics.sh --create --zookeeper cluster1:2181,cluster2:2181,cluster3:2181 --replication-factor 3 --partitions 1 --topic bighope然后先启动消费者程序,键入命令, java -cp lib/*: Consumer_pull bighope再启动生产者程序,键入命令, java -cp lib/*: Producer_push然后根据提示输入topic名以及数据条数,这里测试我们采取30条数据,topic名就是在之前创建的topic名,我们这里是bighope,结果如下
生产者端接收数据成功
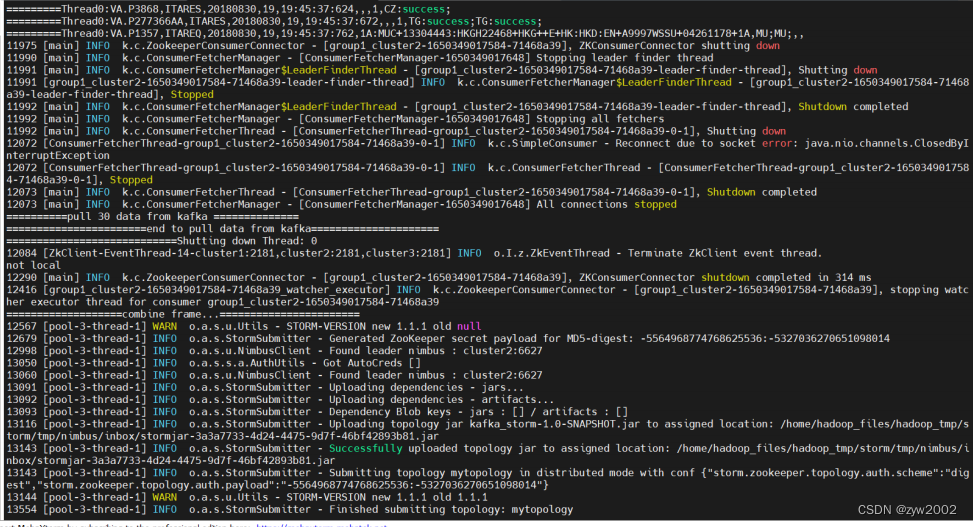
在接收数据后,kafka会进行一个消费实例,此实例可以实现不同线程处理方式不同,这里我们是单线程,使用Consumer_storm实例来利用storm消费数据,流程首先是成功提交Topology
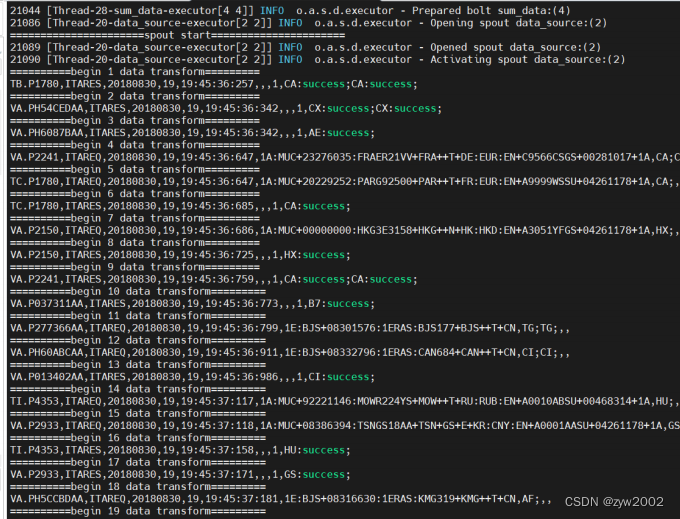
spout开始传输数据
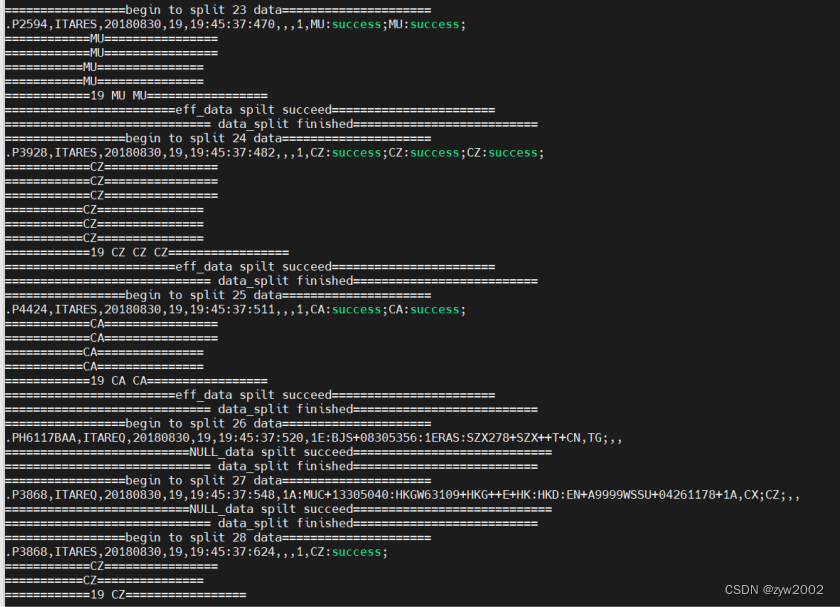
split_Bolt分割数据文件
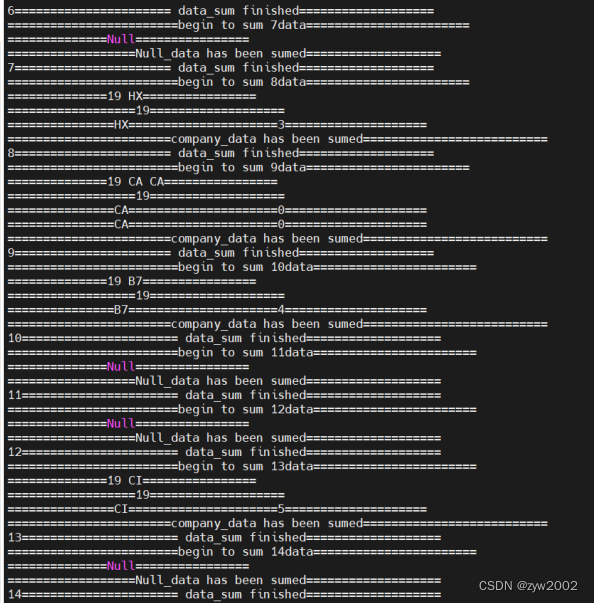
sum_Bolt聚合分割数据
sum_Bolt写入文件
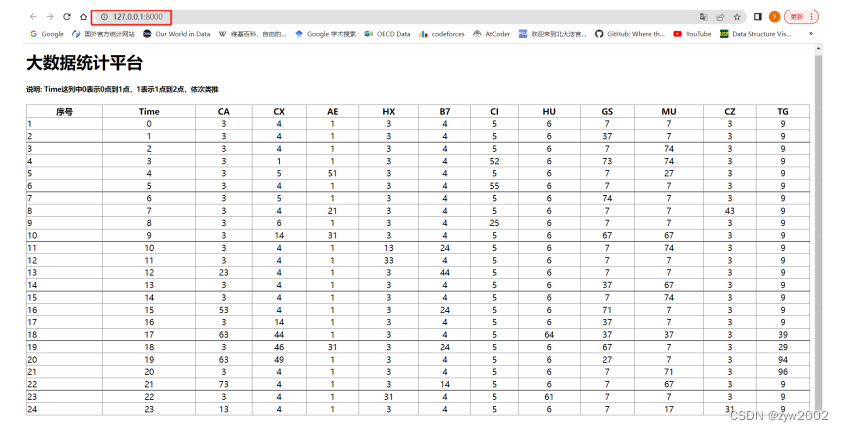
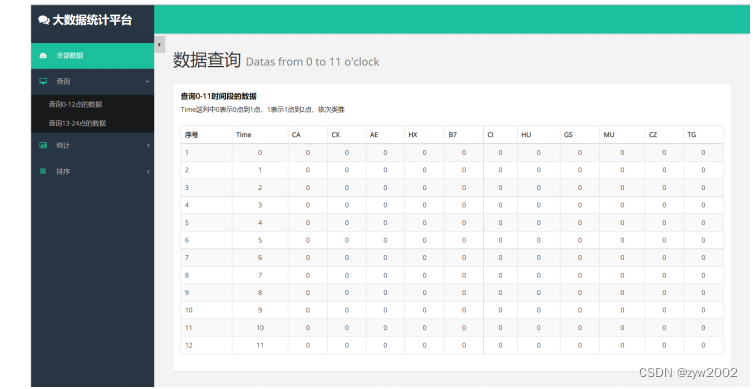
统计结果先写入fly-company_sum.txt,这里只处理了30条,数据量很少,后续会将数据写入数据存储设备 接下来这部分,我会介绍消费者端以及storm的源码解析 Consumer_pull.javaComsumer_pull类,包含执行消费者拉取数据的主类 私有属性定义,消费者连接,topic名,线程执行对象 private final ConsumerConnector consumer;//consumer对象 private final String topic;//订阅的topic private ExecutorService executor;//线程执行对象初始化方法,Consumer_pull方法,连接kafka配置程序段,以及接收topic名 /** *初始化消费者对象 *@parama_topic订阅的topic */ public Consumer_pull(String a_zookeeper,String a_groupId,String a_topic){ System.out.println("=============begin connect=============="); consumer= Consumer.createJavaConsumerConnector(createConsumerConfig(a_zookeeper,a_groupId)); System.out.println("=============end connect================"); this.topic=a_topic; }kafka消费者关闭方法,关闭线程执行以及消费者连接 /** * kafka消费者关闭方法 */ public void shutdown(){ if (consumer != null) consumer.shutdown(); if (executor != null) executor.shutdown(); try { if (!executor.awaitTermination(60000, TimeUnit.MILLISECONDS)) { System.out.println("Timed out waiting for consumer threads to shut down, exiting uncleanly"); } } catch (InterruptedException e) { System.out.println("Interrupted during shutdown, exiting uncleanly"); } }kafka消费者配置文件,这里的参数设置都是参考官网给的解释 /** * 消费者配置文件 * @return ConsumerConfig */ private static ConsumerConfig createConsumerConfig(String a_zookeeper,String a_groupId) { Properties props = new Properties(); props.put("group.id",a_groupId);//"group1" props.put("zookeeper.connect",a_zookeeper);//"cluster1:2181,cluster2:2181,cluster3:2181" props.put("zookeeper.session.timeout.ms", "400"); props.put("zookeeper.sync.time.ms", "200"); props.put("auto.commit.interval.ms", "1000"); props.put("consumer.timeout.ms","10000"); // props.put("auto.offset.reset","smallest"); // props.put(org.apache.kafka.clients.consumer.ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG,"range"); return new ConsumerConfig(props); }消费者run方法取出kafkastream这一数据流对象,然后我们进行处理将其传输到消费者实例中,使用excutor提交线程 /** * 消费者kafkastream处理方式 * @param a_numThreads 线程总数 */ public void run(int a_numThreads) { System.out.println("==========begin to pull data from kafka==========="); Map topicCountMap=new HashMap(); topicCountMap.put(topic,new Integer(a_numThreads)); //System.out.println("================begin to fetch================"); Map consumerMap=consumer.createMessageStreams(topicCountMap); //System.out.println("=================end fetch=================="); //取出后的数据流存放在容器中,每个流对应一个线程 List streams=consumerMap.get(topic); //部署所有线程 executor= Executors.newFixedThreadPool(a_numThreads); //创建消费者对象, int threadNumber=0; for(final KafkaStream stream:streams){ executor.submit(new Consumer_storm(stream,threadNumber));//提交线程 threadNumber++; } }消费者运行主函数,获取参数,传入方法中,并执行方法,这里只采用了单线程处理一个topic的一个分区,后续可以实现多分区处理,通过控制台控制线程数。 /** *运行消费者端 *@paramargs控制台参数,会获取topic名 */ public static void main(String[] args) { /** *执行kafka消费者端的进程,读取Consumer_pull拉取的数据 */ String zookeeper="cluster1:2181,cluster2:2181,cluster3:2181";//zookeeper集群地址 String groupId="group1";//消费者群组名 String topic=args[0];//topic名 int threads=Integer.parseInt("1");//线程数 Consumer_pull pull=new Consumer_pull(zookeeper,groupId,topic); pull.run(threads);//运行进程 try{ Thread.sleep(10000); }catch (InterruptedException ie){ System.out.println("=======something interrupt========="); } pull.shutdown(); } Consumer_storm.java在Consumer_pull里面的run方法中我们利用excutor提交了一个Consumer_storm对象,在这里会解析这一运行实例 属性定义,kafka数据流以及线程编号 private KafkaStream m_stream;//kafka数据流 private int m_threadNumber;//线程号初始化对象 /** * 消费类初始化 * @param a_stream kafka数据流 * @param a_threadNumber 线程号 */ public Consumer_storm(KafkaStream a_stream,int a_threadNumber){ m_stream=a_stream; m_threadNumber=a_threadNumber; }重写run函数,Consumer_storm实现Runnable接口方法,遍历kafka流,然后进行topology应用 public void run() { ConsumerIterator it = m_stream.iterator(); int count = 0; String[] str = new String[30];//存储30个数据大小 while (it.hasNext()) { String data = new String(it.next().message()); System.out.println("=========Thread" + m_threadNumber + ":" + data); str[count] = data; count++; }//数据遍历循环 System.out.println("==========pull " + count + " data from kafka =============="); System.out.println("=======================end to pull data from kafka====================="); System.out.println("============================Shutting down Thread: " + m_threadNumber); Topology.Topology_arrage(new Spout(str)); } Topology.javatopology定义,配置topology,这里会画出你的topology结构,例如我的拓朴是split_bolt接收名为data_source的spout数据流源头的数据,sum_bolt接收名为split_data数据流源头的数据,一个简单的线形结构,后续若做出改进可以实现更复杂的topology。 public static void Topology_arrage(Spout spout){ Split_Bolt split_bolt=new Split_Bolt(); Sum_Bolt sum_bolt=new Sum_Bolt(); TopologyBuilder builder=new TopologyBuilder();//定义拓扑 builder.setSpout("data_source",spout,1);//设置spout线程 builder.setBolt("split_data",split_bolt,1).shuffleGrouping("data_source");//设置split_bolt线程 builder.setBolt("sum_data",sum_bolt,1).shuffleGrouping("split_data");//设置sum_bolt线程利用本地提交topology,这里未向集群提交,在测试环节先实现本地处理,后续会努力实现向集群提交打包的jar包 Config conf=new Config(); //提交topology try { LocalCluster cluster = new LocalCluster(); System.out.println("=====================Topology local run begin====================="); cluster.submitTopology("mytopology", conf, builder.createTopology());//提交topology Utils.sleep(40000); cluster.killTopology("mytopology"); cluster.shutdown(); // System.out.println("not local"); // StormSubmitter.submitTopology("mytopology",conf,builder.createTopology()); }catch (Exception e){ e.printStackTrace(); System.out.println("=============something wrong=============="); } Spout.java继承BaseRichSpout,以及要重写其主要函数方法 属性定义,接收数据对象,存储数据的数组,以及定义自己发送tuple的名字 private SpoutOutputCollector collector;//定义发射tuple的对象 private int count=1;//发射数据的次数 private String[] str=new String[30];//存放数据的数组(30代表能处理数据的最大值) private static final String field="string";//形成的tuple命名为string初始化对象,将数据写入属性 /** *初始化,获取数据 *@paramstr应用端输入的数据 */ public Spout(String[] str){ this.str=str; }open方法,在spout开始执行时,首先进入该方法,将发射数据的collector类型写入属性 /** * open 方法 * @param map storm的配置 * @param topologyContext topology组件信息 * @param spoutOutputCollector 发射tuple的方法 */ @Override public void open(Map map, TopologyContext topologyContext, SpoutOutputCollector spoutOutputCollector) { System.out.println("======================spout start======================"); collector=spoutOutputCollector; }nextTuple 主要的执行方法,将数据打包成一个一个tuple发送出去,collector的emit方法就是发送数据的方法,将数据转换成tuple的value值写入tuple /** * nextTuple 方法 * 主要的执行方法,用于输出数据,是Spout实现的核心 */ @Override public void nextTuple() { //遍历数据,进行发送 if (count 第二步:工具类 package com.liangjiajia.mybatis.utils; import org.apache.ibatis.io.Resources; import org.apache.ibatis.session.SqlSession; import org.apache.ibatis.session.SqlSessionFactory; import org.apache.ibatis.session.SqlSessionFactoryBuilder; import java.io.IOException; import java.io.Reader; public class MyBatisUtils { private static SqlSessionFactory sqlSessionFactory = null; static { Reader reader = null; try { reader = Resources.getResourceAsReader("mybatis-config.xml"); sqlSessionFactory = new SqlSessionFactoryBuilder().build(reader); } catch (IOException e) { e.printStackTrace(); throw new ExceptionInInitializerError(e); } } public static SqlSession openSession() { return sqlSessionFactory.openSession(); } public static void closeSession(SqlSession session) { if (session != null) { session.close(); } } } package utils; import java.io.IOException; import java.io.RandomAccessFile; import java.util.ArrayList; import java.util.HashMap; import java.util.List; import java.util.Map; public class IOUtils { public static void main(String[] args) { IOData(); } public static List IOData() { List entries = new ArrayList(); try { RandomAccessFile file = new RandomAccessFile("src/main/java/fly-company_sum.txt", "r"); String str; while ((str = file.readLine()) != null) { Map temp = new HashMap(); int index = str.indexOf(":"); int time = Integer.parseInt(str.substring(0, index)); temp.put("time", time); String ss = str.substring(index + 2); String[] sss = ss.split(" "); for (int i = 1, j = 0; j DOCTYPE html> 数据汇总 大数据统计平台 说明: Time这列中0表示0点到1点,1表示1点到2点,依次类推 序号 Time CA CX AE HX B7 CI HU GS MU CZ TG {% for item in items %} {{ forloop.counter }} {{ item.time }} {{ item.ca }} {{ item.cx }} {{ item.ae }} {{ item.hx }} {{ item.b7 }} {{ item.ci }} {{ item.hu }} {{ item.gs }} {{ item.mu }} {{ item.cz }} {{ item.tg }} {% endfor %} 配置urls.py, 建立URL和视图函数的对应关系首先在myapp文件夹下新建一个urls.py文件,在urlpatterns中添加列表项,声明views中编写的逻辑代码与网页地址之间的映射关系,代码内容如下 from django.conf.urls import url from . import views urlpatterns = [ url(r'^$', views.index), ]然后还需要修改bigdata/urls.py 文件,使其包括所有在myapp/urls.py中定义的路径,修改代码如下: from django.contrib import admin from django.urls import path,include from myapp import views urlpatterns = [ path('admin/', admin.site.urls), path('', include('myapp.urls')), ] 运行代码,测试结果直接在pycharm中点击运行,然后在浏览器中访问127.0.0.1:8000 , 效果示意如下图,说明成功的实现了代码逻辑部分。
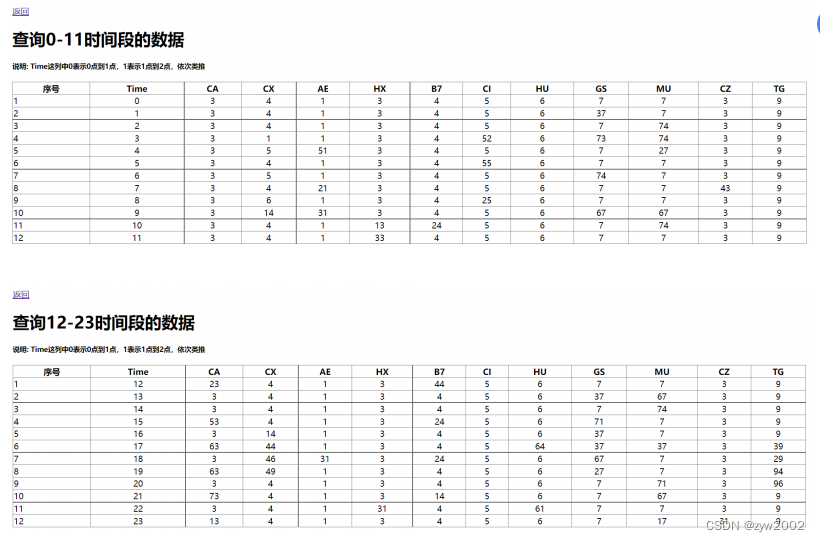
同理,按照上述的方法还实现了查询13-24点的航班预定信息。测试效果如下
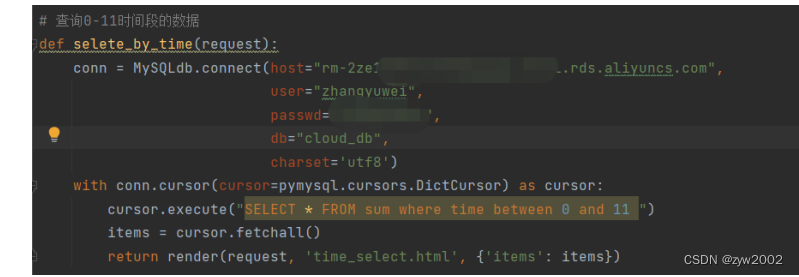
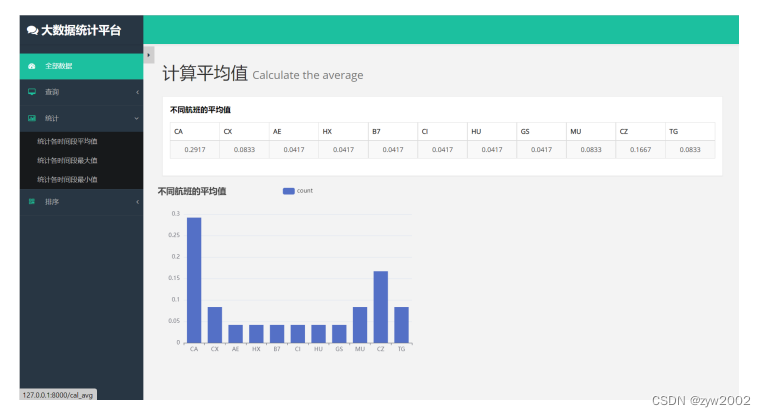
按照功能模块2的实现方法,同样可以编写逻辑函数,通过对游标执行不同的sql语句实现数据的统计功能。例如 cursor.execute("SELECT AVG(ca) as avg_ca,AVG(cx) as avg_cx, AVG(ae) as avg_ae, AVG(hx) as avg_hx, AVG(b7) as avg_b7, AVG(ci) as avg_ci, AVG(hu) as avg_hu,AVG(gs) as avg_gs,AVG(mu) as avg_mu, AVG(cz) as avg_cz,AVG(tg) as avg_tg from sum") 语句实现平均值,然后还可以将AVG函数变为MAX,MIN函数来求解最大值和最小值。具体实现不再赘述,功能展示如下:
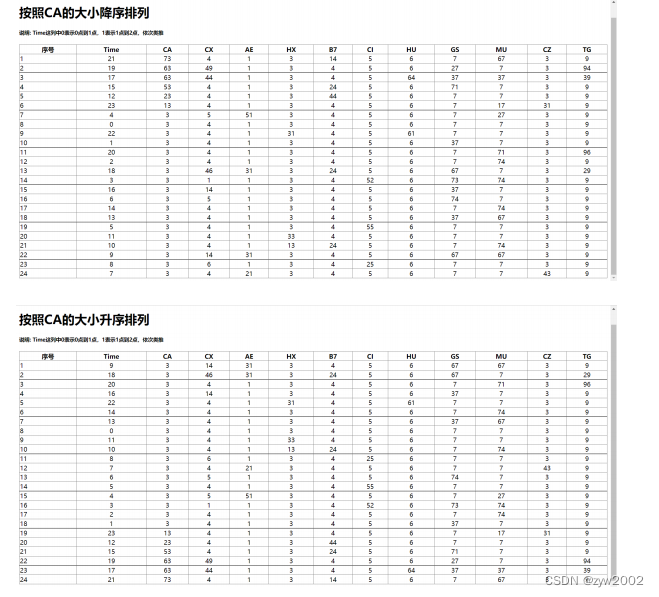
按照功能模块2的实现方法,同样可以编写逻辑函数,通过对游标执行不同的sql语句实现数据的排序功能。例如 SELECT * FROM sum order by ca 语句实现按照ca的数量进行升序排序,然后还可以在其后添加关键字 DESC实现 降序排序。 具体实现不再赘述,功能展示如下: 由于Django在默认情况下不能实现CSS、FONT等界面前端效果,因此我们需要对Django进行进一步配置。 在项目中manage.py同级目录下新建static文件夹,在static文件夹下新建css、js等文件夹,并在相应的文件下放入我们需要的文件。
在调用了.css文件的html文件(templates\index.html)中加入custom-style.css的路径,注意此处路径为/static/css/custom-style.css 在terminal下运行python [manage.py](http://manage.py) runserver,在浏览器中输入http://127.0.0.1:8000/即可看见可视化界面(下图为index.html文件的示例)
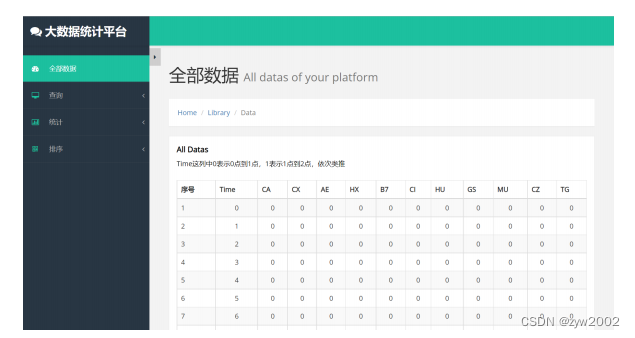
基于4.5.1中提到的后端基本功能,我们进行了界面的进一步细化与展示。 我们将现有功能分为四部分(全部数据展示、数据查询、数据统计、数据排序),并由index.html作为主界面完成数据的全部展示,并在界面左侧提供数据查询、统计与排序的选项,点击左侧栏相应按钮进行功能界面跳转。各界面展示如下 首页:index.html此部分主要采取表格的形式展示,如上图 数据查询(0-11):time_select.html数据查询(12-23):time_select2.html
在此界面除了利用表格展示信息外,我们额外增加了柱状图便于观察。 首先引入echarts用以柱状图的显示,需要在中加入 然后在中加入柱状图的具体实现部分,用dd存取从数据库中获取的数据,由于获取的数据为一个字符串,且存在一定的干扰项,因此我们通过正则语法对其进行拆分,再将拆分后的数据进行显示。 var dd = '{{ items }}'; console.log(typeof dd); var ss = dd.match(/\d+\.\d+/g); ss = ss.map(Number); var myChart = echarts.init(document.getElementById('main')); var option = { title: { text: '不同航班的平均值' }, tooltip: {}, legend: { data: ['count'] }, xAxis: { data: ['CA', 'CX', 'AE', 'HX', 'B7', 'CI', 'HU', 'GS', 'MU', 'CZ', 'TG'] }, yAxis: {}, series: [ { name: 'count', type: 'bar', data: ss } ] }; myChart.setOption(option);界面运行展示如下:
同cal_avg.html一样,我们采用了echarts用以显示折线图,除了增加必要的echarts引用外,我们还需要在部分增加的代码部分如下 var dd = '{{ items }}'; console.log(dd); console.log(typeof dd); var dd = dd.split("'"); console.log(dd); var ss = [] for (var i = 1; i |






【本文地址】
今日新闻 |
推荐新闻 |