【数据处理包Pandas】数据透视表 |
您所在的位置:网站首页 › 数据透视表函数有哪些种类 › 【数据处理包Pandas】数据透视表 |
【数据处理包Pandas】数据透视表
|
目录
一、通过多级索引创建数据透视表二、数据透视表三、交叉表
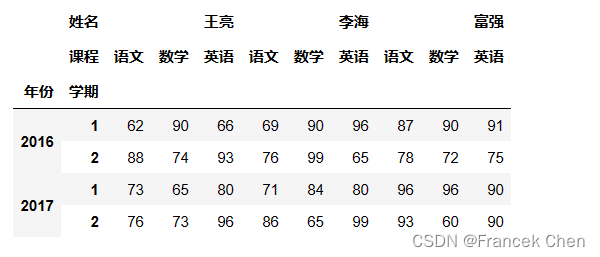
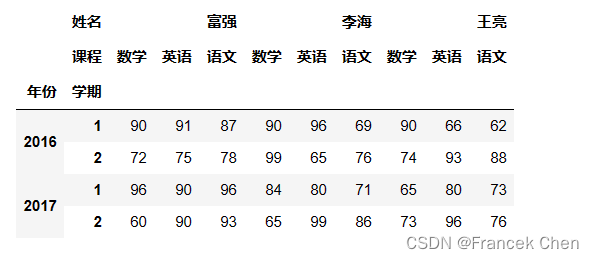
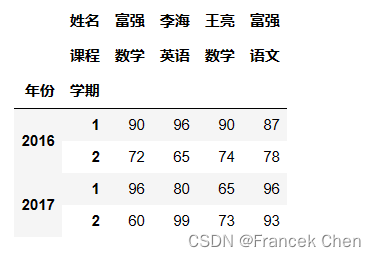
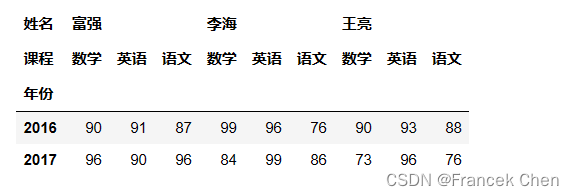
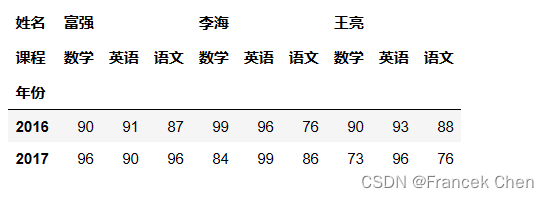
首先,导入 NumPy 和 Pandas 库。 import numpy as np import pandas as pd 一、通过多级索引创建数据透视表利用多级索引产生学生成绩表: r_index = pd.MultiIndex.from_product([[2016,2017],[1,2]],names=['年份','学期']) c_index = pd.MultiIndex.from_product([['王亮','李海','富强'],['语文','数学','英语']],names=['姓名','课程']) np.random.seed(666) scores = pd.DataFrame(np.random.randint(60,100,(4,9)),index=r_index,columns=c_index) scores
查看多级行索引: scores.index MultiIndex(levels=[[2016, 2017], [1, 2]], labels=[[0, 0, 1, 1], [0, 1, 0, 1]], names=['年份', '学期'])查看多级列索引: scores.columns MultiIndex(levels=[['富强', '李海', '王亮'], ['数学', '英语', '语文']], labels=[[2, 2, 2, 1, 1, 1, 0, 0, 0], [2, 0, 1, 2, 0, 1, 2, 0, 1]], names=['姓名', '课程'])使用stack方法把列索引变成行索引(默认是把最低级列索引变成最低级行索引),此时行索引有3级。 df = scores.stack() df
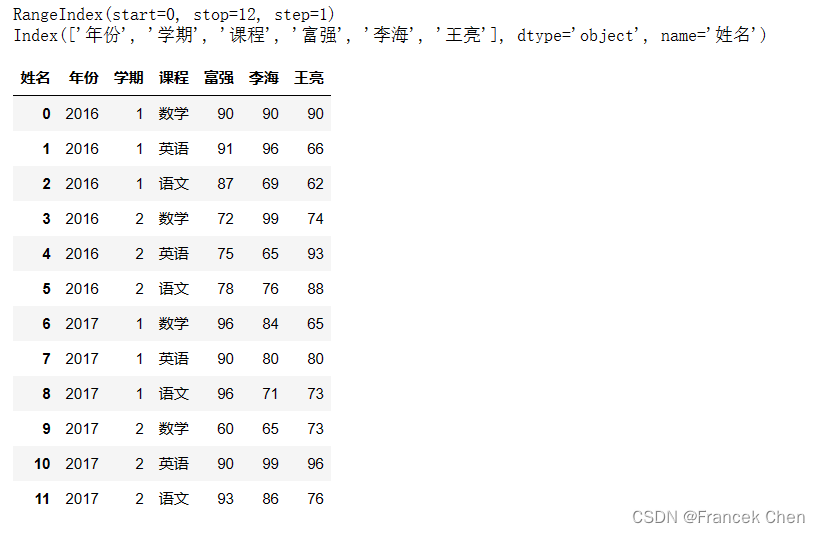
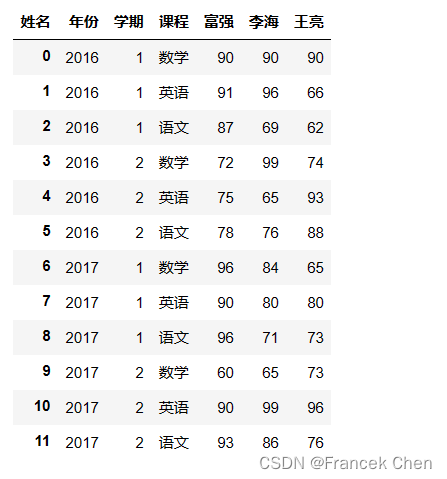
使用reset_index可以把多级索引降级成1级索引。 df = df.reset_index() print(df.index) print(df.columns) df
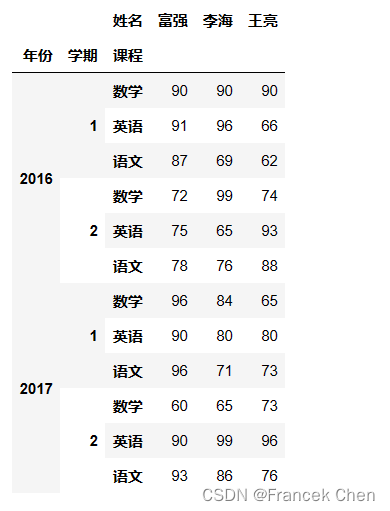
为了说明set_index和unstack方法的用法,复制df对象为df2,并用df2做演示。set_index把行索引重新设置为3级,可见set_index与reset_index互为逆操作。 df2 = df.copy() df2 = df2.set_index(['年份', '学期', '课程']) df2
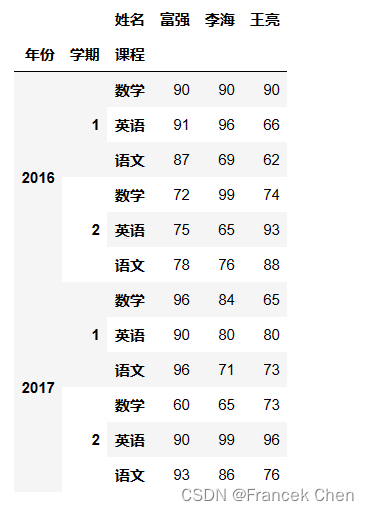
unstack方法把第3级行索引(level=2)变成列索引(默认变成最低级列索引),此时行索引和列索引分别有2级。 df2 = df2.unstack(level=2) df2
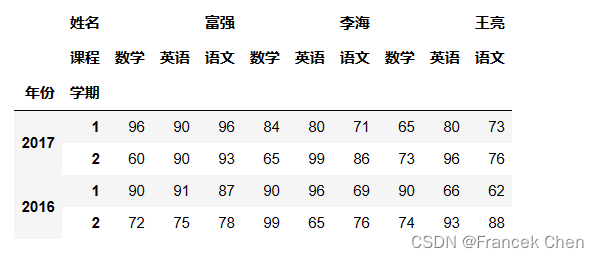
小结: (1)stack是把列索引变成行索引,unstack是把行索引变成列索引,默认都是改变最低级的索引;如果需要要修改其他级别的索引,需要用level参数指定; (2)set_index可以把普通的列变成索引(如果是多个普通的列就会变成多级索引),而reset_index可以索引还原成普通的列,并用0开始的整数序列作为新索引; (3)上述4个方法都不会直接修改原对象,需要赋值后才能修改原对象。 补充:reindex用法 reindex的作用是创建一个符合新索引的新对象(默认不会修改原对象df2),它的一个用途是按新索引重新排序。 df2.reindex([(2017,1),(2017,2),(2016,1),(2016,2)])
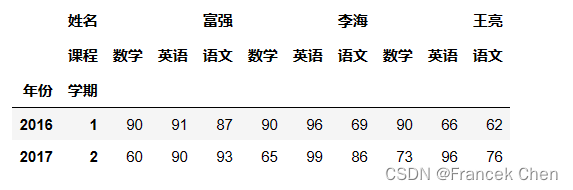
reindex的另一个用途是取部分子集,可以起到切片的效果。 df2.reindex([(2016,1),(2017,2)])
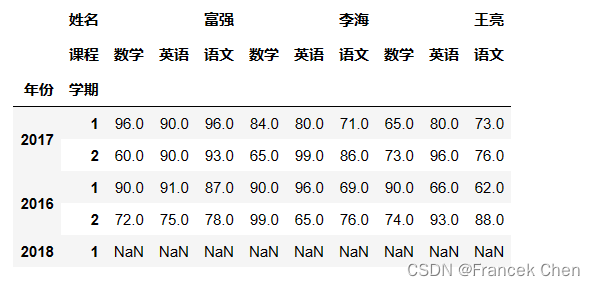
当现有数据无法匹配新的索引时,reindex将使用NaN填充。 df2.reindex([(2017,1),(2017,2),(2016,1),(2016,2),(2018,1)])
通过columns关键字,reindex也同样适用于列索引。 df2.reindex(columns=[('富强','数学'),('李海','英语'),('王亮','数学'),('富强','语文')])
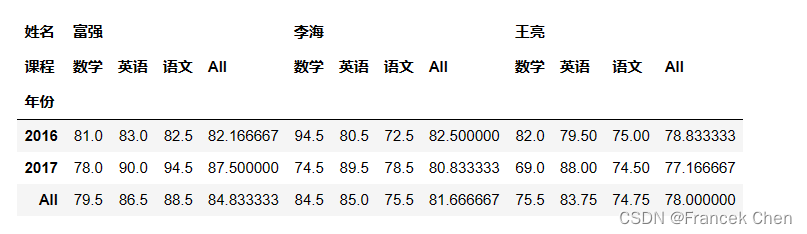
数据透视表相当于在行和列两个维度上进行分组,它可以根据一个或多个键对数据进行聚合,并根据行和列上的分组键将数据分配到各个矩形区域中。数据透视表的效果可以通过groupby来实现,但有时候直接使用pivot_table方法建立数据透视表可能更方便些,而且额外提供了汇总功能。 pd.pivot_table()方法原型: DataFrame.pivot_table(values=None, index=None, columns=None, aggfunc='mean', fill_value=None, margins=False, margins_name='All', dropna=True, margins_name: str = 'All') values:指定要聚合的列。index:指定行索引。columns:指定列索引。aggfunc:指定聚合函数,默认为均值(‘mean’),也可以是 ‘sum’、‘count’、‘min’、‘max’ 等。fill_value:用于替换缺失值的值。margins:是否在结果中包含边际汇总,默认为 False。margins_name:如果 margins 为 True,则指定边际汇总列的名称,默认为 ‘All’。dropna:是否删除缺失值,默认为 True。第1个参数是data参数,提供了绘制数据透视表的数据来源,可以是整个 DataFrame,也可以是 DataFrame 的子集;index和columns参数指定了行分组键和列分组键;values指定想要聚合的数据字段名(相当于sql里的聚合函数操作的列),默认使用data参数指定的数据;aggfunc参数指明进行聚合运算的函数,默认是mean;margins=True参数提供了数据汇总功能。 df.pivot_table(['富强','李海','王亮'],index='年份',columns='课程',aggfunc='mean',margins=True)
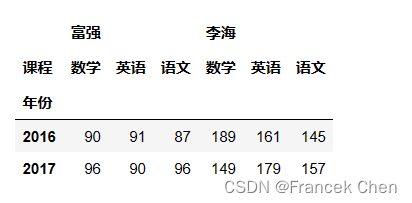
aggfunc参数允许使用字典,可以对不同的列数据实现不同的聚合操作。 df.pivot_table(index='年份',columns='课程',aggfunc={'富强':'max','李海':sum})
上面的语句也可以写成等价的groupby形式: df.groupby(['年份','课程']).agg({'富强':'max','李海':sum}).unstack()
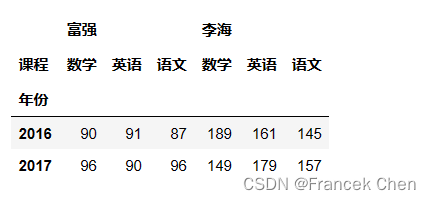
注意:当来源的数据和聚合的数据不同时,需要使用values参数,下面两个语句等价。 # df.pivot_table(index='年份',columns='课程',values=['富强','李海','王亮'],aggfunc='max') # 来源数据是df pd.pivot_table(df,index='年份',columns='课程',values=['富强','李海','王亮'],aggfunc='max')
与上面数据透视表等价的groupby写法: df.groupby(['年份','课程'])['富强','李海','王亮'].max().unstack()
交叉表是一种用于计算分组频率的特殊透视表,可以pivot_table实现同样的功能,因此更建议掌握好pivot_table的使用。 pd.crosstab()方法原型: pd.crosstab(index, columns, values=None, rownames=None, colnames=None, aggfunc=None, margins=False, margins_name='All', dropna=True, normalize=False) index:要在行上进行分组的序列、数组或DataFrame列。columns:要在列上进行分组的序列、数组或DataFrame列。values:可选参数,要聚合的值列。如果未指定,则将计算所有剩余列的计数/频率。rownames:可选参数,用于设置结果中行的名称。colnames:可选参数,用于设置结果中列的名称。aggfunc:可选参数,用于聚合值的函数,默认为计数。常见的值包括sum、mean、median、min、max等。margins:可选参数,布尔值,默认为False,如果为True,则添加行/列总计。margins_name:可选参数,用于设置边际总计的名称。dropna:可选参数,布尔值,默认为True,表示是否删除任何具有缺失值的行。normalize:可选参数,布尔值或’all’,默认为False。如果为True,则返回相对频率(百分比形式)。如果为’all’,则在每个索引/列组中返回全局相对频率。 df
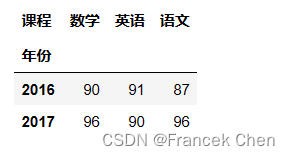
注意: (1)交叉表只能以pd而不能以 DataFrame 对象作为crosstab方法的前缀 (2)crosstab方法没有data参数,index和columns参数不能用列名字符串,而需要用 Series 或数组对象赋值 (3)aggfunc参数默认是统计频数(aggfunc='count');当统计其他聚合信息时,需要同时指定values和aggfunc参数 下面的示例是查看富强同学在不同年份各门课程的最高分: pd.crosstab(index=df['年份'],columns=df['课程'],values=df['富强'],aggfunc='max')
|
【本文地址】
今日新闻 |
推荐新闻 |