数据集格式相互转换 |
您所在的位置:网站首页 › 数据格式转化带来的作用 › 数据集格式相互转换 |
数据集格式相互转换
|
已实现数据集转换
一、CoCo1.1 CoCo2VOC1.2 CoCo2YOLO
二、VOC2.1 VOC2CoCo2.2 VOC2YOLO
三、YOLO3.1 YOLO2CoCo3.2 YOLO2VOC
四、TT100K4.1 TT100K2YOLO
一、CoCo
1.1 CoCo2VOC
from pycocotools.coco import COCO
import os
from lxml import etree, objectify
import shutil
from tqdm import tqdm
import sys
import argparse
# 将类别名字和id建立索引
def catid2name(coco):
classes = dict()
for cat in coco.dataset['categories']:
classes[cat['id']] = cat['name']
return classes
# 将标签信息写入xml
def save_anno_to_xml(filename, size, objs, save_path):
E = objectify.ElementMaker(annotate=False)
anno_tree = E.annotation(
E.folder("DATA"),
E.filename(filename),
E.source(
E.database("The VOC Database"),
E.annotation("PASCAL VOC"),
E.image("flickr")
),
E.size(
E.width(size['width']),
E.height(size['height']),
E.depth(size['depth'])
),
E.segmented(0)
)
for obj in objs:
E2 = objectify.ElementMaker(annotate=False)
anno_tree2 = E2.object(
E.name(obj[0]),
E.pose("Unspecified"),
E.truncated(0),
E.difficult(0),
E.bndbox(
E.xmin(obj[1]),
E.ymin(obj[2]),
E.xmax(obj[3]),
E.ymax(obj[4])
)
)
anno_tree.append(anno_tree2)
anno_path = os.path.join(save_path, filename[:-3] + "xml")
etree.ElementTree(anno_tree).write(anno_path, pretty_print=True)
# 利用cocoAPI从json中加载信息
def load_coco(anno_file, xml_save_path):
if os.path.exists(xml_save_path):
shutil.rmtree(xml_save_path)
os.makedirs(xml_save_path)
coco = COCO(anno_file)
classes = catid2name(coco)
imgIds = coco.getImgIds()
classesIds = coco.getCatIds()
for imgId in tqdm(imgIds):
size = {}
img = coco.loadImgs(imgId)[0]
filename = img['file_name']
width = img['width']
height = img['height']
size['width'] = width
size['height'] = height
size['depth'] = 3
annIds = coco.getAnnIds(imgIds=img['id'], iscrowd=None)
anns = coco.loadAnns(annIds)
objs = []
for ann in anns:
object_name = classes[ann['category_id']]
# bbox:[x,y,w,h]
bbox = list(map(int, ann['bbox']))
xmin = bbox[0]
ymin = bbox[1]
xmax = bbox[0] + bbox[2]
ymax = bbox[1] + bbox[3]
obj = [object_name, xmin, ymin, xmax, ymax]
objs.append(obj)
save_anno_to_xml(filename, size, objs, xml_save_path)
def parseJsonFile(data_dir, xmls_save_path):
assert os.path.exists(data_dir), "data dir:{} does not exits".format(data_dir)
if os.path.isdir(data_dir):
data_types = ['train2017', 'val2017']
for data_type in data_types:
ann_file = 'instances_{}.json'.format(data_type)
xmls_save_path = os.path.join(xmls_save_path, data_type)
load_coco(ann_file, xmls_save_path)
elif os.path.isfile(data_dir):
anno_file = data_dir
load_coco(anno_file, xmls_save_path)
if __name__ == '__main__':
"""
脚本说明:
该脚本用于将coco格式的json文件转换为voc格式的xml文件
参数说明:
data_dir:json文件的路径
xml_save_path:xml输出路径
"""
parser = argparse.ArgumentParser()
parser.add_argument('-d', '--data-dir', type=str, default='./data/labels/coco/train.json', help='json path')
parser.add_argument('-s', '--save-path', type=str, default='./data/convert/voc', help='xml save path')
opt = parser.parse_args()
print(opt)
if len(sys.argv) > 1:
parseJsonFile(opt.data_dir, opt.save_path)
else:
data_dir = './data/labels/coco/train.json'
xml_save_path = './data/convert/voc'
parseJsonFile(data_dir=data_dir, xmls_save_path=xml_save_path)
1.2 CoCo2YOLO
from pycocotools.coco import COCO
import os
import shutil
from tqdm import tqdm
import sys
import argparse
images_nums = 0
category_nums = 0
bbox_nums = 0
# 将类别名字和id建立索引
def catid2name(coco):
classes = dict()
for cat in coco.dataset['categories']:
classes[cat['id']] = cat['name']
return classes
# 将[xmin,ymin,xmax,ymax]转换为yolo格式[x_center, y_center, w, h](做归一化)
def xyxy2xywhn(object, width, height):
cat_id = object[0]
xn = object[1] / width
yn = object[2] / height
wn = object[3] / width
hn = object[4] / height
out = "{} {:.5f} {:.5f} {:.5f} {:.5f}".format(cat_id, xn, yn, wn, hn)
return out
def save_anno_to_txt(images_info, save_path):
filename = images_info['filename']
txt_name = filename[:-3] + "txt"
with open(os.path.join(save_path, txt_name), "w") as f:
for obj in images_info['objects']:
line = xyxy2xywhn(obj, images_info['width'], images_info['height'])
f.write("{}\n".format(line))
# 利用cocoAPI从json中加载信息
def load_coco(anno_file, xml_save_path):
if os.path.exists(xml_save_path):
shutil.rmtree(xml_save_path)
os.makedirs(xml_save_path)
coco = COCO(anno_file)
classes = catid2name(coco)
imgIds = coco.getImgIds()
classesIds = coco.getCatIds()
with open(os.path.join(xml_save_path, "classes.txt"), 'w') as f:
for id in classesIds:
f.write("{}\n".format(classes[id]))
for imgId in tqdm(imgIds):
info = {}
img = coco.loadImgs(imgId)[0]
filename = img['file_name']
width = img['width']
height = img['height']
info['filename'] = filename
info['width'] = width
info['height'] = height
annIds = coco.getAnnIds(imgIds=img['id'], iscrowd=None)
anns = coco.loadAnns(annIds)
objs = []
for ann in anns:
object_name = classes[ann['category_id']]
# bbox:[x,y,w,h]
bbox = list(map(float, ann['bbox']))
xc = bbox[0] + bbox[2] / 2.
yc = bbox[1] + bbox[3] / 2.
w = bbox[2]
h = bbox[3]
obj = [ann['category_id'], xc, yc, w, h]
objs.append(obj)
info['objects'] = objs
save_anno_to_txt(info, xml_save_path)
def parseJsonFile(json_path, txt_save_path):
assert os.path.exists(json_path), "json path:{} does not exists".format(json_path)
if os.path.exists(txt_save_path):
shutil.rmtree(txt_save_path)
os.makedirs(txt_save_path)
assert json_path.endswith('json'), "json file:{} It is not json file!".format(json_path)
load_coco(json_path, txt_save_path)
if __name__ == '__main__':
"""
脚本说明:
该脚本用于将coco格式的json文件转换为yolo格式的txt文件
参数说明:
json_path:json文件的路径
txt_save_path:txt保存的路径
"""
parser = argparse.ArgumentParser()
parser.add_argument('-jp', '--json-path', type=str, default='./data/labels/coco/train.json', help='json path')
parser.add_argument('-s', '--save-path', type=str, default='./data/convert/yolo', help='txt save path')
opt = parser.parse_args()
if len(sys.argv) > 1:
print(opt)
parseJsonFile(opt.json_path, opt.save_path)
# print("image nums: {}".format(images_nums))
# print("category nums: {}".format(category_nums))
# print("bbox nums: {}".format(bbox_nums))
else:
json_path = './data/labels/coco/train.json' # r'D:\practice\compete\goodsDec\data\train\train.json'
txt_save_path = './data/convert/yolo'
parseJsonFile(json_path, txt_save_path)
# print("image nums: {}".format(images_nums))
# print("category nums: {}".format(category_nums))
# print("bbox nums: {}".format(bbox_nums))
二、VOC
2.1 VOC2CoCo
import xml.etree.ElementTree as ET
import os
import json
from datetime import datetime
import sys
import argparse
coco = dict()
coco['images'] = []
coco['type'] = 'instances'
coco['annotations'] = []
coco['categories'] = []
category_set = dict()
image_set = set()
category_item_id = -1
image_id = 000000
annotation_id = 0
def addCatItem(name):
global category_item_id
category_item = dict()
category_item['supercategory'] = 'none'
category_item_id += 1
category_item['id'] = category_item_id
category_item['name'] = name
coco['categories'].append(category_item)
category_set[name] = category_item_id
return category_item_id
def addImgItem(file_name, size):
global image_id
if file_name is None:
raise Exception('Could not find filename tag in xml file.')
if size['width'] is None:
raise Exception('Could not find width tag in xml file.')
if size['height'] is None:
raise Exception('Could not find height tag in xml file.')
image_id += 1
image_item = dict()
image_item['id'] = image_id
image_item['file_name'] = file_name
image_item['width'] = size['width']
image_item['height'] = size['height']
image_item['license'] = None
image_item['flickr_url'] = None
image_item['coco_url'] = None
image_item['date_captured'] = str(datetime.today())
coco['images'].append(image_item)
image_set.add(file_name)
return image_id
def addAnnoItem(object_name, image_id, category_id, bbox):
global annotation_id
annotation_item = dict()
annotation_item['segmentation'] = []
seg = []
# bbox[] is x,y,w,h
# left_top
seg.append(bbox[0])
seg.append(bbox[1])
# left_bottom
seg.append(bbox[0])
seg.append(bbox[1] + bbox[3])
# right_bottom
seg.append(bbox[0] + bbox[2])
seg.append(bbox[1] + bbox[3])
# right_top
seg.append(bbox[0] + bbox[2])
seg.append(bbox[1])
annotation_item['segmentation'].append(seg)
annotation_item['area'] = bbox[2] * bbox[3]
annotation_item['iscrowd'] = 0
annotation_item['ignore'] = 0
annotation_item['image_id'] = image_id
annotation_item['bbox'] = bbox
annotation_item['category_id'] = category_id
annotation_id += 1
annotation_item['id'] = annotation_id
coco['annotations'].append(annotation_item)
def read_image_ids(image_sets_file):
ids = []
with open(image_sets_file, 'r') as f:
for line in f.readlines():
ids.append(line.strip())
return ids
def parseXmlFilse(data_dir, json_save_path, split='train'):
assert os.path.exists(data_dir), "data path:{} does not exist".format(data_dir)
labelfile = split + ".txt"
image_sets_file = os.path.join(data_dir, "ImageSets", "Main", labelfile)
xml_files_list = []
if os.path.isfile(image_sets_file):
ids = read_image_ids(image_sets_file)
xml_files_list = [os.path.join(data_dir, "Annotations", f"{i}.xml") for i in ids]
elif os.path.isdir(data_dir):
# 修改此处xml的路径即可
# xml_dir = os.path.join(data_dir,"labels/voc")
xml_dir = data_dir
xml_list = os.listdir(xml_dir)
xml_files_list = [os.path.join(xml_dir, i) for i in xml_list]
for xml_file in xml_files_list:
if not xml_file.endswith('.xml'):
continue
tree = ET.parse(xml_file)
root = tree.getroot()
# 初始化
size = dict()
size['width'] = None
size['height'] = None
if root.tag != 'annotation':
raise Exception('pascal voc xml root element should be annotation, rather than {}'.format(root.tag))
# 提取图片名字
file_name = root.findtext('filename')
assert file_name is not None, "filename is not in the file"
# 提取图片 size {width,height,depth}
size_info = root.findall('size')
assert size_info is not None, "size is not in the file"
for subelem in size_info[0]:
size[subelem.tag] = int(subelem.text)
if file_name is not None and size['width'] is not None and file_name not in image_set:
# 添加coco['image'],返回当前图片ID
current_image_id = addImgItem(file_name, size)
print('add image with name: {}\tand\tsize: {}'.format(file_name, size))
elif file_name in image_set:
raise Exception('file_name duplicated')
else:
raise Exception("file name:{}\t size:{}".format(file_name, size))
# 提取一张图片内所有目标object标注信息
object_info = root.findall('object')
if len(object_info) == 0:
continue
# 遍历每个目标的标注信息
for object in object_info:
# 提取目标名字
object_name = object.findtext('name')
if object_name not in category_set:
# 创建类别索引
current_category_id = addCatItem(object_name)
else:
current_category_id = category_set[object_name]
# 初始化标签列表
bndbox = dict()
bndbox['xmin'] = None
bndbox['xmax'] = None
bndbox['ymin'] = None
bndbox['ymax'] = None
# 提取box:[xmin,ymin,xmax,ymax]
bndbox_info = object.findall('bndbox')
for box in bndbox_info[0]:
bndbox[box.tag] = int(box.text)
if bndbox['xmin'] is not None:
if object_name is None:
raise Exception('xml structure broken at bndbox tag')
if current_image_id is None:
raise Exception('xml structure broken at bndbox tag')
if current_category_id is None:
raise Exception('xml structure broken at bndbox tag')
bbox = []
# x
bbox.append(bndbox['xmin'])
# y
bbox.append(bndbox['ymin'])
# w
bbox.append(bndbox['xmax'] - bndbox['xmin'])
# h
bbox.append(bndbox['ymax'] - bndbox['ymin'])
print('add annotation with object_name:{}\timage_id:{}\tcat_id:{}\tbbox:{}'.format(object_name,
current_image_id,
current_category_id,
bbox))
addAnnoItem(object_name, current_image_id, current_category_id, bbox)
json_parent_dir = os.path.dirname(json_save_path)
if not os.path.exists(json_parent_dir):
os.makedirs(json_parent_dir)
json.dump(coco, open(json_save_path, 'w'))
print("class nums:{}".format(len(coco['categories'])))
print("image nums:{}".format(len(coco['images'])))
print("bbox nums:{}".format(len(coco['annotations'])))
if __name__ == '__main__':
"""
脚本说明:
本脚本用于将VOC格式的标注文件.xml转换为coco格式的标注文件.json
参数说明:
voc_data_dir:两种格式
1.voc2012文件夹的路径,会自动找到voc2012/imageSets/Main/xx.txt
2.xml标签文件存放的文件夹
json_save_path:json文件输出的文件夹
split:主要用于voc2012查找xx.txt,如train.txt.如果用格式2,则不会用到该参数
"""
voc_data_dir = 'D:/jinxData/voctest/Annotations'
json_save_path = 'D:/jinxData/voc/voc2coco/train.json'
split = 'train'
parseXmlFilse(data_dir=voc_data_dir, json_save_path=json_save_path, split=split)
train、val和test分别执行一次即可。 以上代码参考自博文数据转换。 四、TT100K 4.1 TT100K2YOLO import os import json from random import random import cv2 import shutil import json import xml.dom.minidom from tqdm import tqdm import argparse class TT100K2COCO: def __init__(self): self.original_datasets = 'tt100k' self.to_datasets = 'coco' def class_statistics(self): # os.makedirs('annotations', exist_ok=True) # 存放数据的父路径 parent_path = 'D:/jinxData/TT100K/data' # 读TT100K原始数据集标注文件 with open(os.path.join(parent_path, 'annotations.json')) as origin_json: origin_dict = json.load(origin_json) classes = origin_dict['types'] # 建立统计每个类别包含的图片的字典 sta = {} for i in classes: sta[i] = [] images_dic = origin_dict['imgs'] # 记录所有保留的图片 saved_images = [] # 遍历TT100K的imgs for image_id in images_dic: image_element = images_dic[image_id] image_path = image_element['path'] # 添加图像的信息到dataset中 image_path = image_path.split('/')[-1] obj_list = image_element['objects'] # 遍历每张图片的标注信息 for anno_dic in obj_list: label_key = anno_dic['category'] # 防止一个图片多次加入一个标签类别 if image_path not in sta[label_key]: sta[label_key].append(image_path) # 只保留包含图片数超过100的类别 result = {k: v for k, v in sta.items() if len(v) >= 100} for i in result: print("the type of {} includes {} images".format(i, len(result[i]))) saved_images.extend(result[i]) saved_images = list(set(saved_images)) print("total types is {}".format(len(result))) type_list = list(result.keys()) result = {"type": type_list, "details": result, "images": saved_images} print(type_list) # 保存结果 json_name = os.path.join(parent_path, 'statistics.json') with open(json_name, 'w', encoding="utf-8") as f: json.dump(result, f, ensure_ascii=False, indent=1) def original_datasets2object_datasets_re(self): ''' 重新划分数据集 :return: ''' # os.makedirs('annotations2', exist_ok=True) # 存放数据的父路径 parent_path = 'D:/jinxData/TT100K/data' # 读TT100K原始数据集标注文件 with open(os.path.join(parent_path, 'annotations.json')) as origin_json: origin_dict = json.load(origin_json) with open(os.path.join(parent_path, 'statistics.json')) as select_json: select_dict = json.load(select_json) classes = select_dict['type'] train_dataset = {'info': {}, 'licenses': [], 'categories': [], 'images': [], 'annotations': []} val_dataset = {'info': {}, 'licenses': [], 'categories': [], 'images': [], 'annotations': []} test_dataset = {'info': {}, 'licenses': [], 'categories': [], 'images': [], 'annotations': []} label = {} # 记录每个标志类别的id count = {} # 记录每个类别的图片数 owntype_sum = {} info = { "year": 2021, # 年份 "version": '1.0', # 版本 "description": "TT100k_to_coco", # 数据集描述 "contributor": "Tecent&Tsinghua", # 提供者 "url": 'https://cg.cs.tsinghua.edu.cn/traffic-sign/', # 下载地址 "date_created": 2021 - 1 - 15 } licenses = { "id": 1, "name": "null", "url": "null", } train_dataset['info'] = info val_dataset['info'] = info test_dataset['info'] = info train_dataset['licenses'] = licenses val_dataset['licenses'] = licenses test_dataset['licenses'] = licenses # 建立类别和id的关系 for i, cls in enumerate(classes): train_dataset['categories'].append({'id': i, 'name': cls, 'supercategory': 'traffic_sign'}) val_dataset['categories'].append({'id': i, 'name': cls, 'supercategory': 'traffic_sign'}) test_dataset['categories'].append({'id': i, 'name': cls, 'supercategory': 'traffic_sign'}) label[cls] = i count[cls] = 0 owntype_sum[cls] = 0 images_dic = origin_dict['imgs'] obj_id = 1 # 计算出每个类别共‘包含’的图片数 for image_id in images_dic: image_element = images_dic[image_id] image_path = image_element['path'] image_name = image_path.split('/')[-1] # 在所选的类别图片中 if image_name not in select_dict['images']: continue # 处理TT100K中的标注信息 obj_list = image_element['objects'] # 记录图片中包含最多的实例所属的type includes_type = {} for anno_dic in obj_list: if anno_dic["category"] not in select_dict["type"]: continue # print(anno_dic["category"]) if anno_dic["category"] in includes_type: includes_type[anno_dic["category"]] += 1 else: includes_type[anno_dic["category"]] = 1 # print(includes_type) own_type = max(includes_type, key=includes_type.get) owntype_sum[own_type] += 1 # TT100K的annotation转换成coco的 for image_id in images_dic: image_element = images_dic[image_id] image_path = image_element['path'] image_name = image_path.split('/')[-1] # 在所选的类别图片中 if image_name not in select_dict['images']: continue print("dealing with {} image".format(image_path)) # shutil.copy(os.path.join(parent_path,image_path),os.path.join(parent_path,"dataset/JPEGImages")) # 处理TT100K中的标注信息 obj_list = image_element['objects'] # 记录图片中包含最多的实例所属的type includes_type = {} for anno_dic in obj_list: if anno_dic["category"] not in select_dict["type"]: continue # print(anno_dic["category"]) if anno_dic["category"] in includes_type: includes_type[anno_dic["category"]] += 1 else: includes_type[anno_dic["category"]] = 1 # print(includes_type) own_type = max(includes_type, key=includes_type.get) count[own_type] += 1 num_rate = count[own_type] / owntype_sum[own_type] # 切换dataset的引用对象,从而划分数据集根据每个类别类别的总数量按7:2:1分为了train_set,val_set,test_set。 # 其中每个图片所属类别根据该图片包含的类别的数量决定(归属为含有类别最多的类别) if num_rate 'file_name': image_name, 'id': image_id, 'width': W, 'height': H}) # 保存结果 for phase in ['train', 'val', 'test']: json_name = os.path.join(parent_path, 'dataset/annotations/{}.json'.format(phase)) json_name = json_name.replace('\\', '/') with open(json_name, 'w', encoding="utf-8") as f: if phase == 'train': json.dump(train_dataset, f, ensure_ascii=False, indent=1) if phase == 'val': json.dump(val_dataset, f, ensure_ascii=False, indent=1) if phase == 'test': json.dump(test_dataset, f, ensure_ascii=False, indent=1) def divide_TrainValTest(self, source, target): ''' 创建文件路径 :param source: 源文件位置 :param target: 目标文件位置 ''' # for i in ['train', 'val', 'test']: # path = target + '/' + i # if not os.path.exists(path): # os.makedirs(path) # 遍历目录下的文件名,复制对应的图片到指定目录 for root, dirs, files in os.walk(source): for file in files: file_name = os.path.splitext(file)[0] if file_name == 'train' or file_name == 'val' or file_name =='test' or file_name =='classes': continue image_path = os.path.join(file_name + '.jpg') # print(image_path) if 'train' in source: shutil.copyfile('D:/jinxData/TT100K/data/image_reparation/' + image_path, target + '/train/' + image_path) elif 'val' in source: shutil.copyfile('D:/jinxData/TT100K/data/image_reparation/' + image_path, target + '/val/' + image_path) elif 'test' in source: shutil.copyfile('D:/jinxData/TT100K/data/image_reparation/' + image_path, target + '/test/' + image_path) if __name__ == '__main__': tt100k = TT100K2COCO() # tt100k.class_statistics() # tt100k.original_datasets2object_datasets_re() # tt100k.coco_json2yolo_txt('train') # tt100k.coco_json2yolo_txt('val') # tt100k.coco_json2yolo_txt('test') tt100k.divide_TrainValTest('D:/jinxData/TT100K/data/dataset/annotations/train', 'D:/jinxData/TT100K/data') tt100k.divide_TrainValTest('D:/jinxData/TT100K/data/dataset/annotations/val', 'D:/jinxData/TT100K/data') tt100k.divide_TrainValTest('D:/jinxData/TT100K/data/dataset/annotations/test', 'D:/jinxData/TT100K/data') |
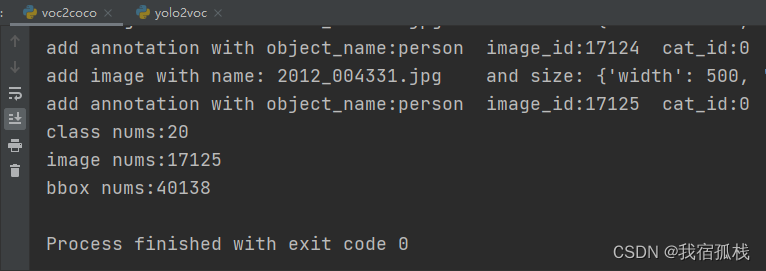
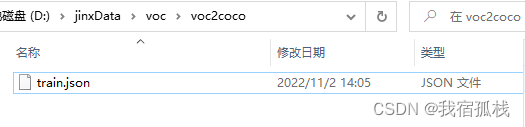 将annotations目录下的所有xml标注文件按coco格式写入了json文件中。
将annotations目录下的所有xml标注文件按coco格式写入了json文件中。
 此处得到的是全部的标签信息,可根据如下代码进行train、val和test的比例划分:
此处得到的是全部的标签信息,可根据如下代码进行train、val和test的比例划分: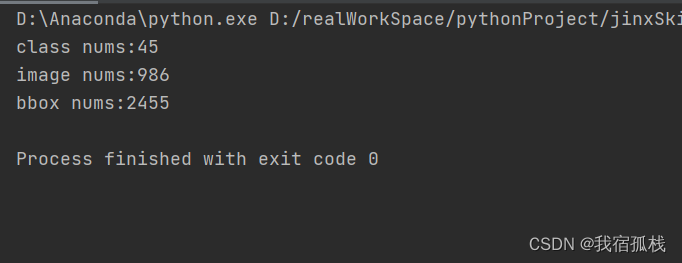
 train和val同理。
train和val同理。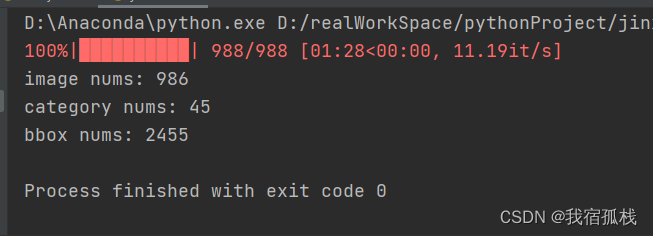
【本文地址】
今日新闻 |
推荐新闻 |