深度学习的特征与标签的维度(keras) |
您所在的位置:网站首页 › 数据标签形状设置 › 深度学习的特征与标签的维度(keras) |
深度学习的特征与标签的维度(keras)
|
keras的特征与标签的维度
一、结论二、实验源码1、文本分类1.1 源码1.2 数据集说明1.2.1 原始的是csv文件1.2.2 转txt:
1.3 特征与标签维度1.3.1 特征二维与标签一维1.3.2 特征二维与标签二维
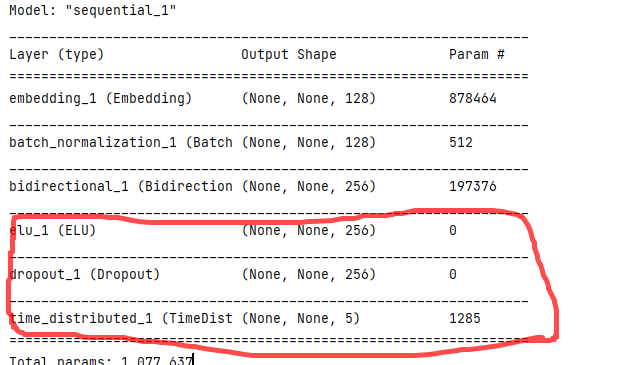
2、中文分词2.1 源码2.2 特征与标签维度2.2.1 特征二维标签三维正常dense测试dense_1层测试dense_2层
2.2.2 特征二维标签二维测试dense_1层测试dense_2层TimeDistributed(Dense)层
3、 启示:
一、结论
Dense层维度要与标签维度一致,根据需要的一致;[1,2,3]对应0与[1,2,3]对应[5,6,8]即可。 如文本分类,则标签不需要one-hot,dense层不需要TimeDistributed 因为文本分类 train_x(16656, 22) ,使得22个字的评论与标签0或者1,进行匹配,所以标签不需要one-hot,dense层不需要TimeDistributed 如中文分词,需要字与标签一一对应,标签one-hot,使得标签与dense分类后softmax的特征进行loss计算,为0,则为负;TimeDistributed使得x与y维度对应。 二、实验源码 1、文本分类 1.1 源码 import random import jieba import numpy as np from keras.preprocessing import text,sequence from keras.layers import * from keras.utils.np_utils import to_categorical from keras.models import Sequential import pandas as pd pos_file= r"J:\Conda\pythonProject\temp\pos.txt" neg_file = r"J:\Conda\pythonProject\temp\neg.txt" def txt_concat(): with open(pos_file,"r",encoding="utf-8")as f: pos = f.readlines() with open(neg_file,"r",encoding="utf-8")as f: neg = f.readlines() all = {} for pos_ in pos: pos_ = pos_.strip() all[pos_] = 1 for neg_ in neg: if neg_ in pos: neg_ = neg_.strip() all[neg_+"$"] = 0 else: neg_ = neg_.strip() all[neg_] = 0 return all def preprocessing_data(): all = txt_concat().keys() #print(text.text_to_word_sequence(pos))#转为单词序列['质量不错', '安装', '东西很好', '妈妈很喜欢', '大天客服', # '喜欢', '宝贝很好很喜欢', '卖家有多努力哦', '好', '好评', '好评', '好评', '好评'] token = text.Tokenizer(filters='#') pos = jieba.lcut(str(list(all)).replace("[","").replace("]",""),HMM=True) token.fit_on_texts(pos)#建立词典 print("词典:",token.index_word) """按照词典转squences,前面全部建立词典,后面每句话建立索引,必须遵照英文格式词 词""" txt2seq=[] for conment in list(all): conment = conment.split("##")[-1] conment = " ".join(jieba.lcut(conment,cut_all=True,HMM=True)) txt2seq.append(conment) sequences = token.texts_to_sequences(txt2seq)#转序列 #print("序列:",sequences) counts = np.bincount([len(z) for z in sequences]) maxlen =np.argmax(counts) print(maxlen) sequences1=sequence.pad_sequences(np.array(sequences),maxlen=maxlen)#对必须是列表列表,为一个文本;保障序列长度一致!! data= {} for key,value in zip(sequences1,txt_concat().values()): data[str(key.tolist())]=np.array(to_categorical(value,2)) return data data = preprocessing_data() dict_key_ls = list(data.keys()) random.shuffle(dict_key_ls) new_dic = {} for key in dict_key_ls: new_dic[key] = data.get(key) train_x,train_y = np.array([eval(i) for i in new_dic.keys()]),np.array(list(new_dic.values())) print(train_x.shape,train_y.shape,train_x[0],train_y[0]) """变为(16682, 35)""" def build_model(): model = Sequential() model.add(Embedding(50470,128,mask_zero=True)) model.add(Bidirectional(LSTM(128,recurrent_dropout=0.4))) model.add(Dropout(0.5)) model.add(Dense(2,activation="sigmoid"))#有两类,但是只匹配一类 model.summary() return model def train(): model= build_model() model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) """train_x,train_y形如[1,2,2,4,5,6,7,8,9] 1""" model.fit(train_x, train_y, batch_size=256, nb_epoch=20,validation_split=0.1) # 训练时间为若干个小时 model.save(r"J:\Conda\pythonProject\自己做项目\文本分类\苏建林的天猫评论\model\文本情感分类.h5") train() """softmax,可以运行,在于dense是二维的""" 1.2 数据集说明此处用的是苏建林大神的评论数据集,转为了txt文本。 1.2.1 原始的是csv文件
格式就是txt文本为标签,里面为内容 其中的##前面的内容,是使用tfidf提取的关键词 (原本以为这一关键词对于分类可能有用,所以试图通过tfidf等手段去提取一些特征,形成多维的特征,使得分类更加精确————结果并没有什么用!!!) 1.3 特征与标签维度 1.3.1 特征二维与标签一维
前面的16656也叫batch_size 正常运行
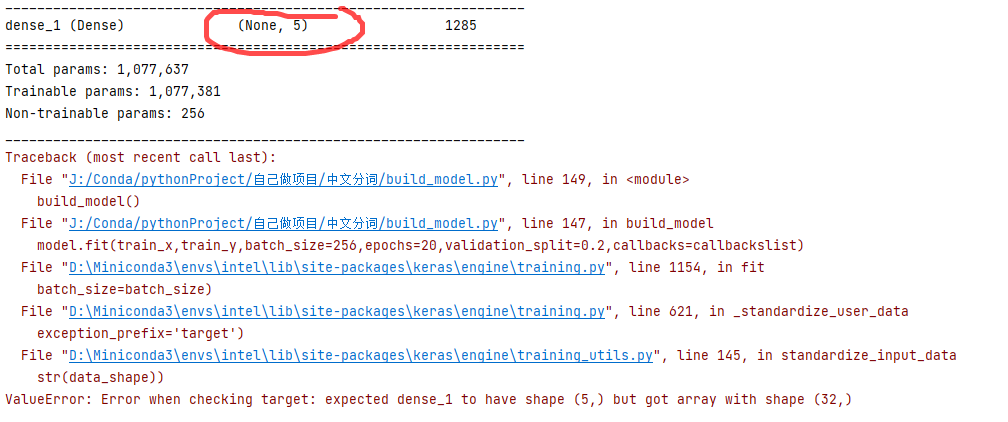
这里的差距在于模型结构体现的 结论暂定 因为标签数量为2,仅为二分类;当问题在于序列标注如中文分词时,词语与BEMS的标注体系为一一对应,此时分类自然是多分类,但是这个多分类Dense层该如何压缩、如何设定维度??? ps:顺便说一句,在情感分类上,尝试了增加tfidf关键词与不增加、使用字向量与词向量,但是这都对提升精确率没有任何作用!!! 有大神知道原因的,欢迎私聊!!! 2、中文分词 2.1 源码 # -*- coding: utf-8 -*- from keras.preprocessing.text import Tokenizer from keras.preprocessing.sequence import pad_sequences from keras.models import * from keras.layers import * from keras.optimizers import * import numpy as np from keras.utils.np_utils import to_categorical from keras.callbacks import ModelCheckpoint,TerminateOnNaN def data_laber(): # 读取语料 with open(r"J:\PyCharm项目\学习进行中\NLP教程\NLP教程\数据集\词性标注\people_fenci.txt", encoding="utf-8")as f: text = f.read().replace("\n", "&&@@") words = ["。" + i for i in text.split("。")] a, b = [], [] for i in words: word,label="","" for z in i.split("&&@@"): if len(z) > 3: z = z.replace("。", "") elif len(z)==0: z = "。 S" else: z = z x,y = z.split(" ") word +=x label+=y a.append(word) b.append(label) return a,b def preprocessing_data(): """数据准备""" x,y = data_laber() """建立词典""" token1 = Tokenizer(filters='',char_level=True) token1.fit_on_texts(x) print(token1.word_index) """转sequences""" sequence_x = token1.texts_to_sequences(x) maxlen = 256 print("最长为:",maxlen) sequence_x = pad_sequences(sequence_x,maxlen=maxlen) print(sequence_x.shape) """y""" token2 = Tokenizer(filters='', char_level=True) token2.fit_on_texts(y) sequence_y = token2.texts_to_sequences(y)#to_categorical(y,4)只是one-hot化 sequence_y = pad_sequences(sequence_y, maxlen=maxlen) sequence_y = np.array([to_categorical(i,5) for i in sequence_y]) print(sequence_y.shape,sequence_y[0]) return sequence_x,sequence_y def build_model(): train_x ,train_y = preprocessing_data() model = Sequential() model.add(Embedding(6863,128,mask_zero=True)) model.add(Bidirectional(GRU(128,return_sequences=True,recurrent_dropout=0.4))) model.add(Dropout(0.5)) model.add(TimeDistributed(Dense(5,activation="softmax",))) model.summary() checkpoint = ModelCheckpoint(r'fenci.h5', monitor='val_loss',verbose=1, save_best_only=True, period=1) callbackslist = [checkpoint] model.compile(optimizer=Adam(), loss='categorical_crossentropy', metrics=['accuracy',"categorical_accuracy"]) model.fit(train_x,train_y,batch_size=256,epochs=20,validation_split=0.2,callbacks=callbackslist) model.save("fenci.h5") build_model() 2.2 特征与标签维度 2.2.1 特征二维标签三维 正常dense
dense层为 报错:
可以正常运行,但是loss爆炸了 dense层最后要分类的,只有5类,没有32类 2.2.2 特征二维标签二维数据集
同样炸了 区别在于
之前的模型结构压缩到了二维,使用了TimeDistributed后认为三维; 3、 启示:Dense层维度要与标签维度一致,这样才能完成特征对标签的分类 即
需要与 一致 因为 特征集X: (696526, 32) 经过embedding后 变成(None, None, 128) 即每个字符映射了128个维度,那么针对每个字分类,就有让dense后softmax的值与标签进行loss计算,不one-hot,就是五个[0,1]区间的值与一个标签求loss,则无法计算。 而在文本分类(情感分类)中,不是每个字的映射,而是每句话的分类。 此外,中文分词中的LSTM使用了return_sequences=True,而文本分类(情感分类)中的LSTM没有使用return_sequences=True,使得文本分类(情感分类)为二维在文本分类中,若是使用return_sequences=True,则需要展平 model.add(Embedding(50470,128,input_length=22))#此处必须有input_length,否者无法降维进行全连接 model.add(Bidirectional(LSTM(128,return_sequences=True,recurrent_dropout=0.4))) model.add(Dropout(0.5)) model.add(Flatten()) model.add(Dense(2,activation="sigmoid")) |



 特征即x的shape为(16656,22),y标签shape为(16656,) 即
特征即x的shape为(16656,22),y标签shape为(16656,) 即
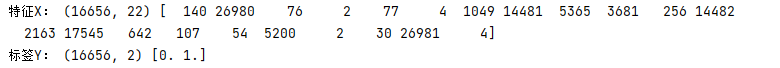 同样成功训练
同样成功训练 
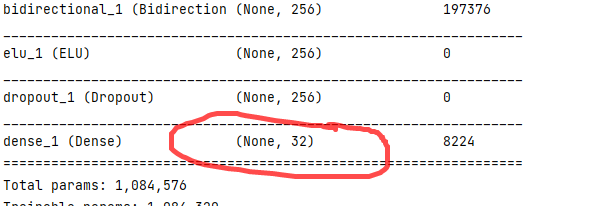
 二维的时候,dense也必须是2 若为1:
二维的时候,dense也必须是2 若为1:  报错:
报错:  由此可见,最后的dense压缩维度与标签维度有关!!!
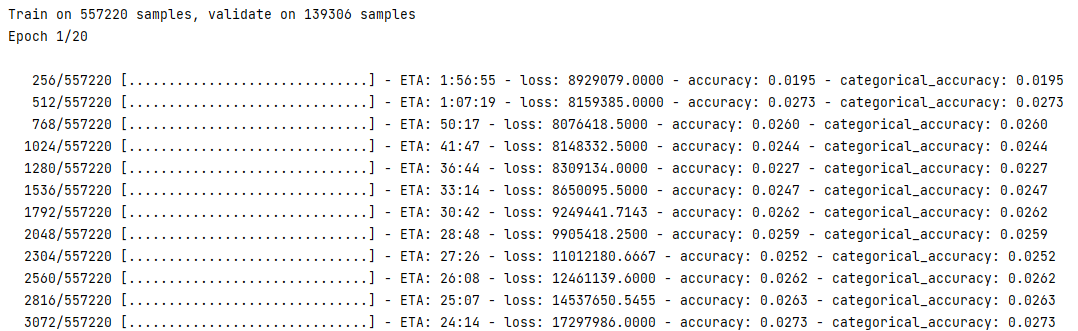
由此可见,最后的dense压缩维度与标签维度有关!!! dense层为TimeDistributed时正常运行
dense层为TimeDistributed时正常运行

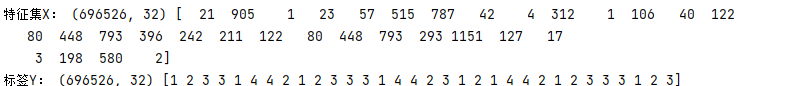

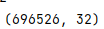

【本文地址】
今日新闻 |
推荐新闻 |