mysql查询语句中使用星号真的慢的要死? |
您所在的位置:网站首页 › 数据库查询中星号什么意思 › mysql查询语句中使用星号真的慢的要死? |
mysql查询语句中使用星号真的慢的要死?
|
前言
之所以写这篇文章,是源于以前看过的关于sql语句优化的帖子,里面明确提到了在sql语句中不要使用 * 来做查询,就像下面的规则中说的 2、尽量避免使用select *,返回无用的字段会降低查询效率。如下: SELECT * FROM t 优化方式:使用具体的字段代替*,只返回使用到的字段。
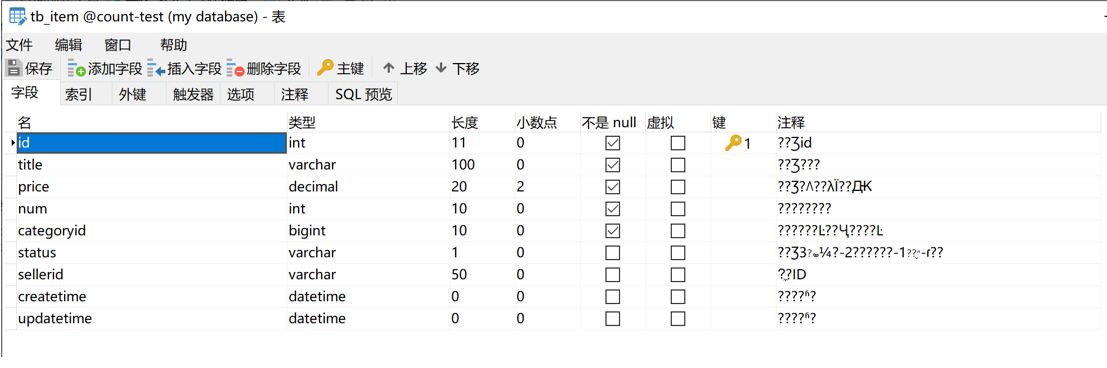
但是中国有句姥话叫“尽信书不如无书”,难道在sql查询语句中使用星号就真的慢的要死,难道加索引也不行?带着这些个疑问,我进行了一些测试。结果发现,江湖传说未必真的靠得住。那具体测试情况是咋样的呢?下面且听我给各位看官慢慢分解。 事先声明,本文是抛砖文,只进行测试,不做原理分析(要不然篇幅太长,各位看官估计要看睡着了)。本文的一切测试均以实际测试数据为准,拒绝假大空。 测试环境准备 我这次测试的系统环境如下: Win10系统 Mysql5.7.26 64位版本,使用默认的InnoDB存储引擎然后我准备了一张tb_item表,用来存放测试数据,数据是我跟朋友要的一些商品信息数据。 下图是tb_item表的结构
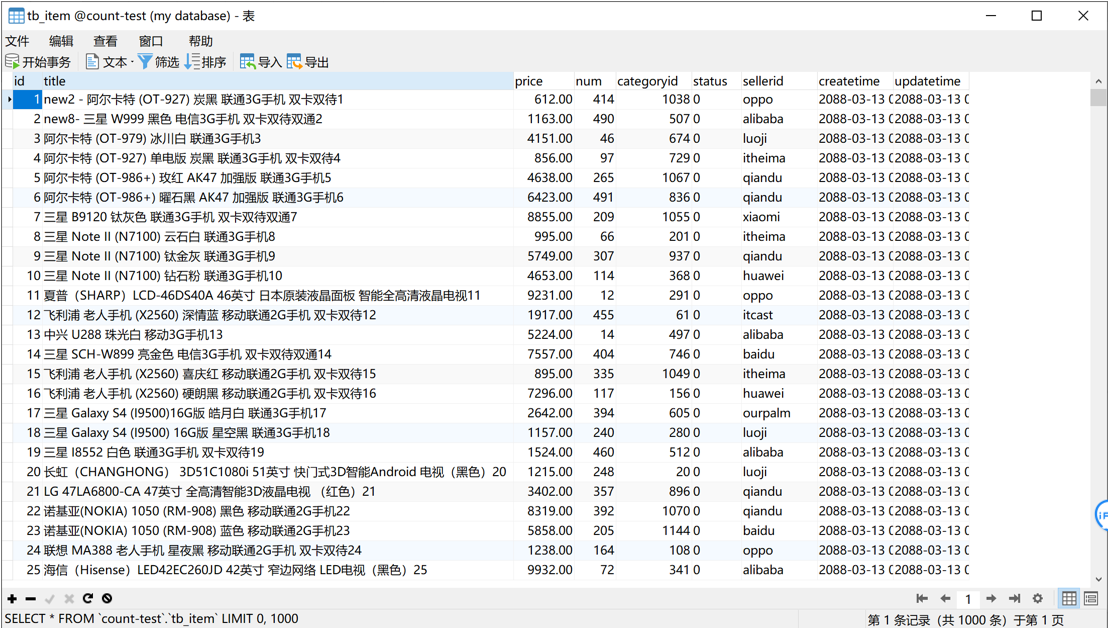
tb_item表中的部分数据
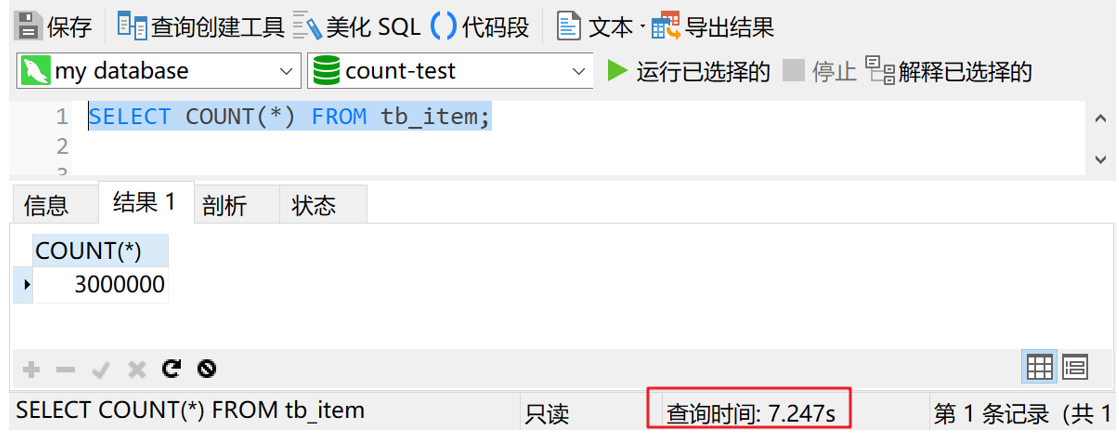
我将从以下几个方面去进行测试: count查询 联表查询 分页查询好,闲话不多说,马上开整。 一.count查询 在count查询操作中,又分为两种情况,不带where条件的count查询,和带where条件的count查询。那我们就依次来测试一下。 1. 不带where条件的count查询 我们先来测试一下统计整个表的记录数。首先给大家剧透一下,tb_item表一共有300万条数据。执行 SELECT COUNT(*) FROM tb_item,结果如下图所示
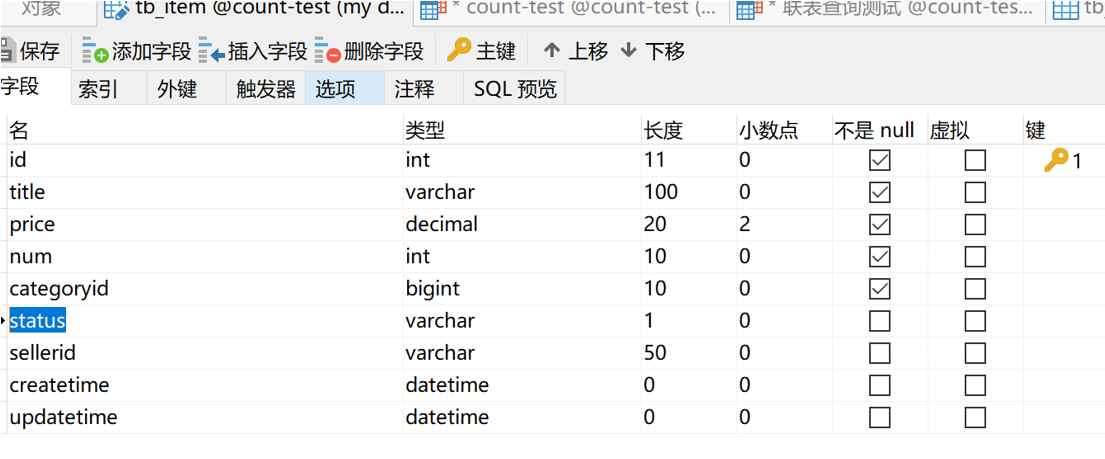
可以看到,查询时间是7秒多。如果是配置一般的机器,估计会更慢。显然,统计整张表的数据量,使用星号貌似是不行的。 那有没有办法可以优化一下呢?当然有啊,而且我都给大家测试好了。在tb_item表中有一个 status 字段,不知道大家注意到了没有
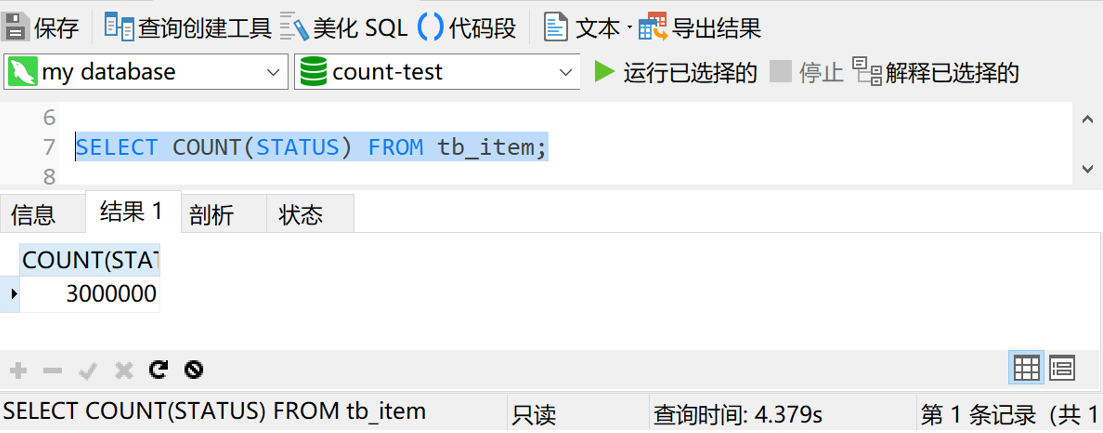
我们发现,这个字段的长度才占一个varchar。那如果我们修改一下刚才的sql,改成 SELECT COUNT(STATUS) FROM tb_item 又会如何呢?我们执行一下这条sql,看一下结果
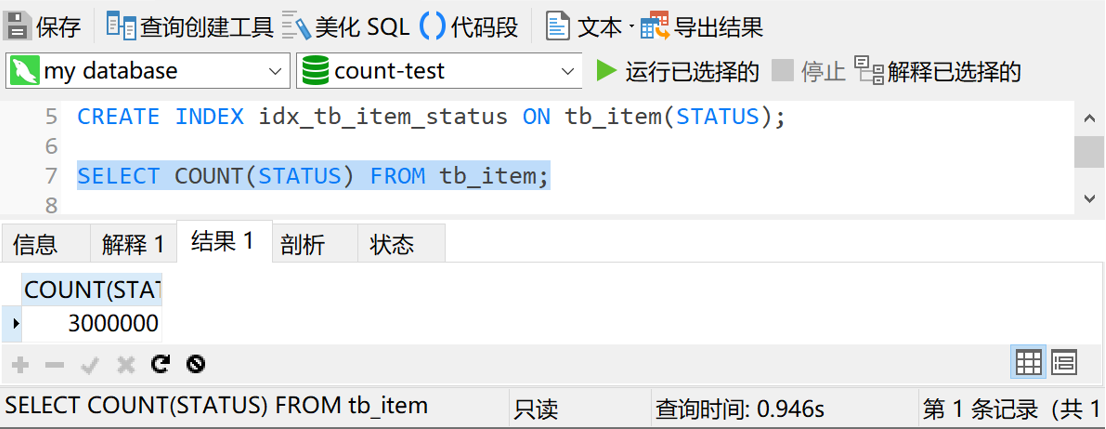
可以看到,这次的查询时间是4秒多,快了将近一半。 如果我们给 status 字段加个索引,结果又会怎样呢?那我们就加个索引试试。执行 CREATE INDEX idx_tb_item_status ON tb_item(STATUS) 然后我们再执行一下 SELECT COUNT(STATUS) FROM tb_item,结果如下图
这次的查询时间是0.9秒,不到1秒。 从一开始的7秒多到现在的不到1秒,查询时间缩短了85%。这个优化结果真是爽的一批啊。 2. 带where条件的count查询 现在我们再试一下使用星号执行带where条件的查询操作会是个什么情况。我们简单一些,就查询价格小于1000块钱的商品数据。 执行 SELECT COUNT(*) FROM tb_item t WHERE t.price |
【本文地址】
今日新闻 |
推荐新闻 |