深入理解注意力机制(加权求和) |
您所在的位置:网站首页 › 数据加权的本质 › 深入理解注意力机制(加权求和) |
深入理解注意力机制(加权求和)
|
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
本文链接:
https://blog.csdn.net/BVL10101111/article/details/78470716
最近刷了一些attention相关的paper(照着here的列表+自己搜的paper),网上相关的资料也有很多,在此只讲一讲自己对于attention的理解,力求做到简洁明了。 一.attention 的本质attention其实就是一个加权求和。 attention处理的问题,往往面临的是这样一个场景: 你有kk维)。 solution: 1.一个最简单粗暴的办法就是这kk,显然不够合理。 2.较为合理的办法就是,加权平均,即(αiαi 而attention所做的事情就是如何将αiαi合理的算出来。 二.attention 的设计如何计算得到αiαi,一般分两个步骤: step 1: 设计一个打分函数ff值越大。 step 2:对所得到的kk 那么如何设计step 1中的打分函数ff呢,在论文”Dynamic Attention Deep Model for Article Recommendation by Learning Human Editors’Demonstration”中的Attention Mechanism章节给了较为全面的概括。大体分为三类: 1.Location-based Attention 2.General Attention 3.Concatenation-based Attention 其中General Attention并不常见,(可能笔者读的paper不够多,目前还没有遇到过)因此在这里不做介绍。接下来详细介绍下Location-based Attention和Concatenation-based Attention的设计。 2.1 Location-based Attention应用场景, 比如 对于一个问题‘Where is the football?’, ‘where’ 和‘football’ 在句子中起着总结性的作用。而这种attention只和句子中每个词自身相关。 Location-based的意思就是,这里的attention没有其他额外所关注的对象,即attention的向量就是hihi,这里的激活函数activation,常见的有三种:1)tahn,2)relu,3)y=x(即没有激活函数) 具体我们来举几个例子,可能具体实现上,有略微区别,不过都大同小异: Example 1:A Context-aware Attention Network for Interactive Interactive Question Answering_KDD2017 这篇文章涉及多个attention,这里只举相关的几个例子: 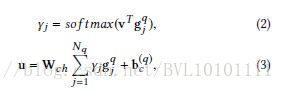 可以看到,
gqjgjq再进行下一步操作。
可以看到,
gqjgjq再进行下一步操作。
Example 2:Dynamic Attention Deep Model for Article Recommendation by Learning Human Editors’ Demonstration_KDD2017 这里用了两种不同的attention,通过权重αα) 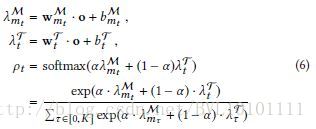 2.1 Concatenation-based Attention
2.1 Concatenation-based Attention
Concatenation-based意思就是,这里的attention是指要关注其他对象。 我们用htht可以是用cnn提取得到的图片信息,用rnn提取得到的句子信息等等)。 需要注意的是这里的htht可以是恒定不变的一个向量(比如整个句子的向量表达),也可以是随着时序不断变化的向量(比如句子中的单词的向量表达,不同时刻,面对的是句子中不同的单词),具体问题,具体设计 而ff。 函数的描述的意思就是,希望通过W1,W2W1,W2计算score。 具体我们来举几个例子,可能具体实现上,有略微区别,不过都大同小异: Example 1:Attentive Collaborative Filtering Multimedia Recommendation with Item- and Component-Level Attention_sigir17 这篇论文讲了多层的attention 其中一层是: 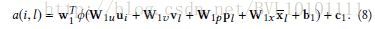
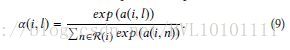 这里
uiui 。可以说是,想加什么attention,就直接把对应向量往公式里一加,即可。
另一层是:
这里
uiui 。可以说是,想加什么attention,就直接把对应向量往公式里一加,即可。
另一层是:
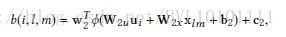
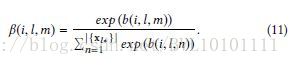 与第一层的attention类似,不多讲。
与第一层的attention类似,不多讲。
Example 3:Dipole Diagnosis Prediction in Healthcare via Attention-based Bidirectional Recurrent Neural Network_2017KDD 在这篇论文中,将上下文的文本信息作为attention,即公式(7)中的cici。 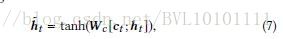
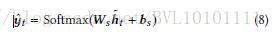
Example 4:Enhancing Recurrent Neural Networks with Positional Attention for Question Answering_SIGIR2017 通过题目 Positional Attention也大致可以猜到,作者应该通过其他方式得到了一个position的表达向量pjpj,将其作为attention,具体公式如下: 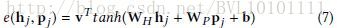
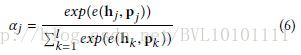
Example 5:Learning to Generate Rock Descriptions from Multivariate Well Logs with Hierarchical Attention_2017KDD 和前面类似,不多讲,直接上公式: 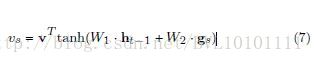
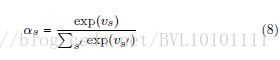
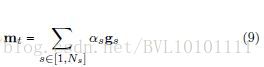
Example 6:Reasoning about entailment with neural attention_ICLR2016 也不多讲,直接上公式 看到这里相信大家对于attention有了较为直观的感觉,其实套路都差不太多,看各家paper给出的公式也都差不多,具体是结合问题,怎么去设计这个attention向量,怎么去说故事罢了。 三.attention 的扩展 (多层attention,常见的是2层)举个简单的例子,一个文档由k2k2大小不一)个word组成。 第一层:word-level的attention 对于每个sentence有k1k1,然后,得到这些,具体任务具体分析。 这里举几个例子(不具体展开讲公式),比如: Example 1:A Context-aware Attention Network for Interactive Interactive Question Answering_KDD2017 输入一篇文档和问题,输出回答 第一层attention: 先用location attention+ mlp对问题embedding成一个向量u 用Concatenation-based Attention(前一个句子和当前句子concatenation)+与u的相似度进行计算attention score建模,得到每个句子的embedding 第二层attention 以句子的embedding的粒度,对整个文档进行attention(利用与u的相似度进行计算attention score) Example 2:Leveraging Contextual Sentence Relations for Extractive Summarization Using a Neural Attention Model_SIGIR2017 输入一篇文档,输出文档的summarize 第一层attention (Location-based Attention) ,word-level,来生成每个句子的vector 第二层attention 利用第一层句子的vector,将当前句子作为中心,前n个句子和后n个句子组成的2n+1个句子的序列,作为RNN输入,将中心句子作为attention,来embedding上下文,然后通过上下文,对这个中心句子进行打分,作为句子对于整个文本的重要性的依据。 Example 3: Learning to Generate Rock Descriptions from Multivariate Well Logs with Hierarchical Attention_2017KDD 输入矿井的特征,有n个特征,每个特征是一个时间序列,表示不同深度的该特征。 第一层attention(location attention) 因为每一个特征都是一个时间序列,因此可以用rnn+attention对其进行embedding,成一个vector。生成了n个vector 第二层attention 和其他attention不同的是,世界对这n个向量进行(location attention)算score,因此这里的attention和rnn没有什么关系。 Example 4:Attentive Collaborative Filtering Multimedia Recommendation with Item- and Component-Level Attention_sigir17 用了两层attention。 第一层attention 每个item有多种feature,在feature-level的attention上,用user vector去做。然后得到每个item的vector。 第二层attention 结合了好几个feature进行打分,最后得到一个user feature的vector。与最原始的user vector结合起来得到了最后的user vector,然后与item做内积,判断相似性与喜好。 四.总结目前来看,attention的套路还是很固定的,主要的关键点是如何结合具体问题,设计出你所要关心的attention,即htht 加入到model中去,作为计算score的依据。 |

【本文地址】
今日新闻 |
推荐新闻 |