R语言 |
您所在的位置:网站首页 › 数据分析报告r语言 › R语言 |
R语言
|
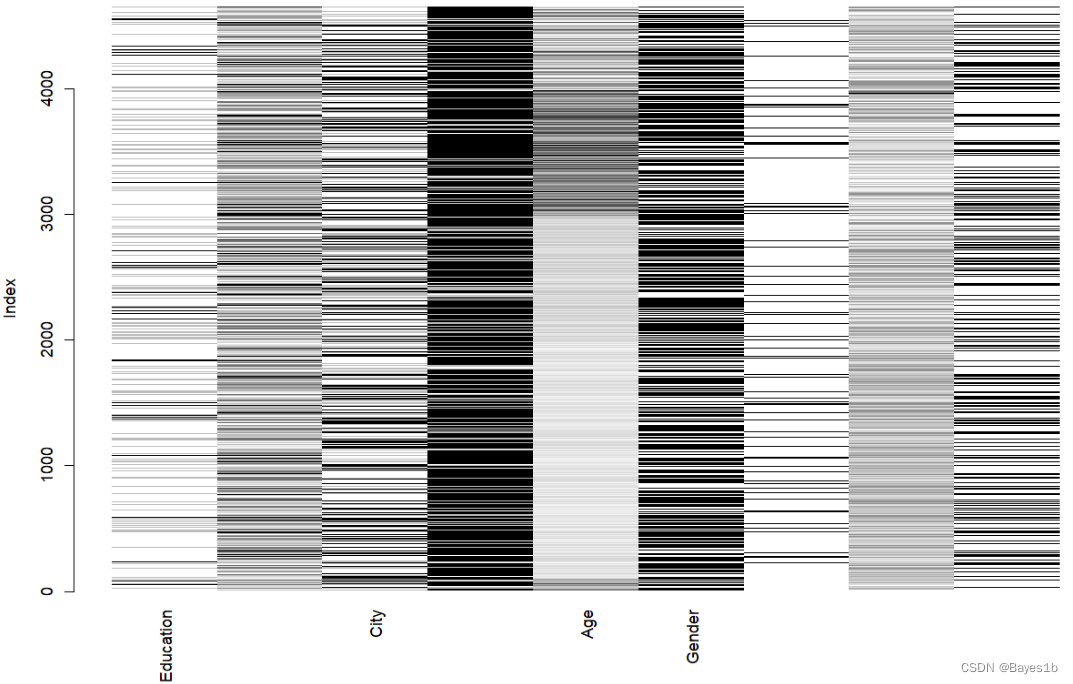
下面在此分享一下一次课程作业的答题思路及个人答题结果。如有错误欢迎指正。 *本文参考了很多文章。如有雷同纯属纯属巧合。 1引言 1.1研究背景及意义 随着知识经济的到来,高科技迅速发展,人力资源配置日益社会化全球化。企业的组织发展的战略资源已不单单是生产资料等物质成本,也包括了以知识、技能和智力为特征的人力资源。人们越来越意识到,拥有和创造知识与智力资本的人是企业拥有核心竞争力的源泉,人力资源管理的地位和重要性也达到前所未有的水平。然而,各个企业人员的大量流动与流失,使得企业的人力资源成本日益上升,成为亟待解决的一大问题。 对此,通过对员工数据进行分析,挖掘出什么因素对离职率有贡献,并及时安抚员工情绪才能减少人员流失以及可能的经济损失。 1.2研究目的 根据该公司人力资源部门提供的数据,预测该员工未来2年内是否离职。 2数据说明 2.1数据查看 本文数据来自Kaggle,由TEJASHVI提供。主要包含了员工的基本信息和其未来2年内是否离职,其中离职与否就是需要预测的变量。 经统计,共计4653条样本,1个因变量,8个自变量。具体变量名及含义如下表所示。 变量名 含义 类型 Education 受教育程度 有序类别型 自变量 Joining Year 入职时间 数值型 自变量 City 城市 无序类别型 自变量 PaymentTier 收入等级 有序类别型 自变量 Age 年龄 数值型 自变量 Gender 性别 无序类别型 自变量 EverBenched 曾经被排除在项目之外 1 个月或更长时间 无序类别型 自变量 ExperienceInCurrentDomain 当前领域的经验 数值型 自变量 LeaveOrNot 未来是否离职 无序类别型 因变量 2.2数据处理 对数据的缺失情况可视化,图中,灰度表示值的大小,浅色表示值小,深色表示值大,默认缺失值为红色。
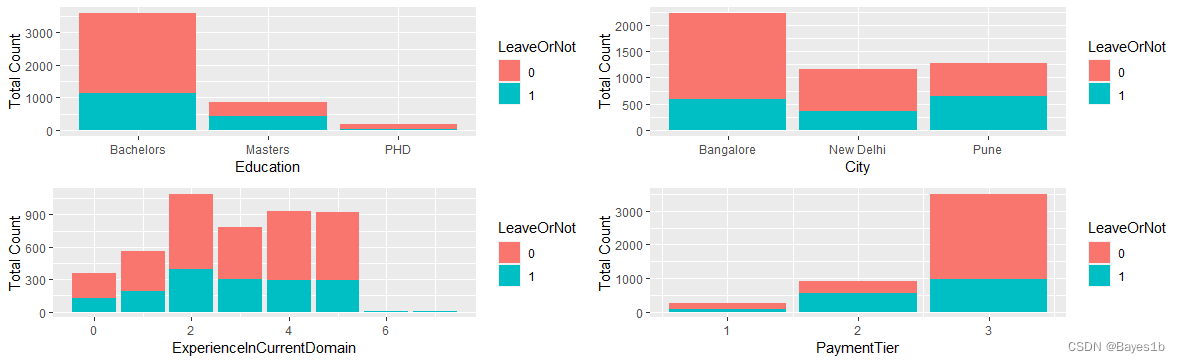
经初步查看,并无缺失值。 为方便后续分析,我们对Education、Gender、EverBenched进行重编码,对City进行One-Hot编码。 经处理,剩余11个变量。 2.3描述性统计 对数据进行描述性统计。 对数值型变量,计算其最小值、最大值、平均数、中位数、25%分位数、75%分位数。 Name Min 1st Qu Median Mean 3rd Qu Max JoiningYear 2012 2013 2015 2015 2017 2018 Age 22.00 26.00 28.00 29.39 32.00 41.00 ExperienceInCurrentDomain 0.00 2.00 3.00 2.91 4.00 7.00 对类别型变量,计算各类别数目多少。 Name Type1 Type2 Type3 Education 3601(Bachelors) 873(Masters) 179(PHD) PaymentTier 243 918 3492 Gender 2778(男) 1875(女) EverBenched 4175(否) 478(是) City 2228(Bangalore) 1157(New Delhi) 1268(Pune) LeaveOrNot 3503(否) 1600(是) 由上,数据相差并不是很大,因此此处数据不进行标准化。 2.4数据划分 将数据按7:3的比例划分为训练集和测试集,以便后续分析。经划分,训练集共有3249条数据,测试集共有1404条数据。 3数据分析 我们先初步观察一下各自变量与是否离职之间的关系。按从左到右,从上到下的顺序,依次是Age、Gender与LeaveOrNot关系图、JoiningYear、EverBenched与LeaveOrNot关系图、Education与LeaveOrNot关系图、ExperienceInCurrentDomain与LeaveOrNot关系图、City与LeaveOrNot关系图:PaymentTier与LeaveOrNot关系图。
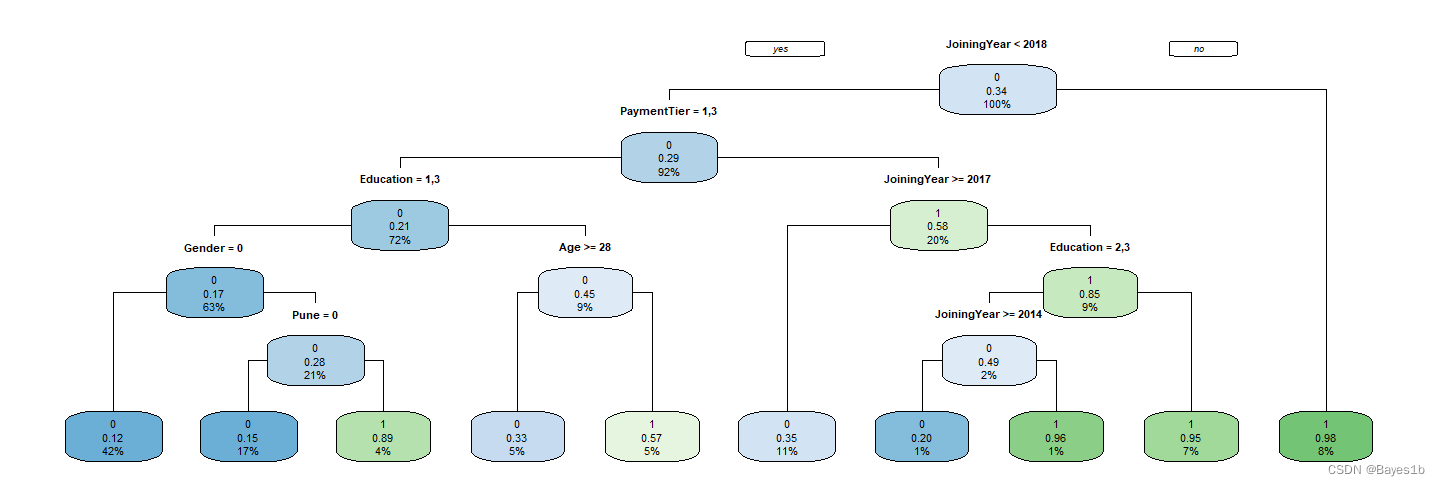
由上图知,离职人员特征偏年轻化,性别差异、地区差异不明显。经常参加项目、教育水平为学士学位、经验丰富、收入水平为第三等级的更容易离职。 3.1决策树算法 ①模型求解 可视化训练集决策树图:
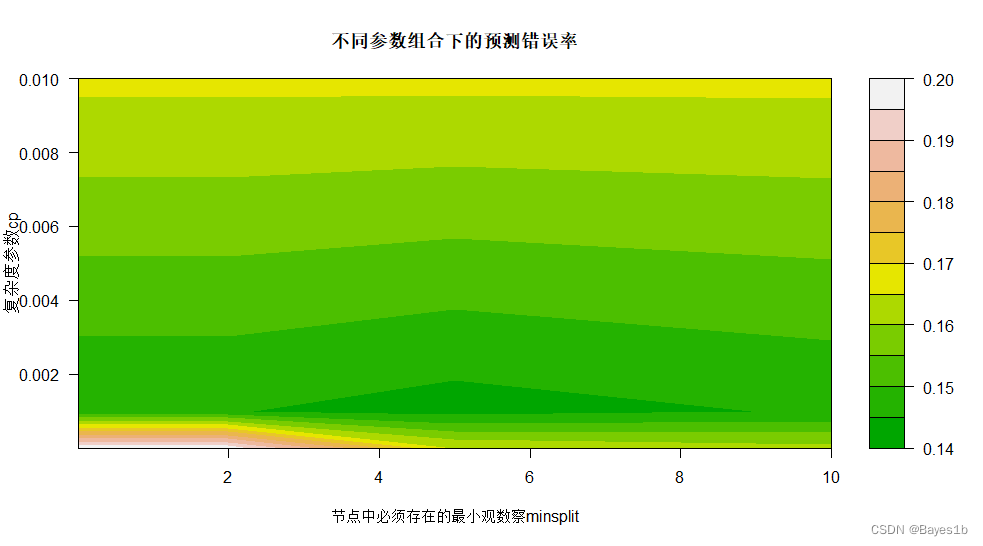
对于rpart函数而言,除了自变量、因变量、使用的数据集以外,它的重要参数还有:minsplit(节点中必须存在的最小观察数)、cp(复杂度参数, 用于惩罚过大 (过于复杂) 的树)等。 考虑到样本量适中,在我们给定minsplit与cp的值后,利用10折交叉验证找到预测误差最小时的损失惩罚参数。
可以看到,颜色越深误差越小,即当minsplit取5,cp取0.001时模型有最优。根据混淆矩阵,此时的训练集精度为87.17%。 ③预测 利用最优模型对测试集样本数据进行预测。根据混淆矩阵,测试集的测试精度为84.40%。 ④交叉验证 将上述最优模型作用于全部数据集,并进行10-折交叉验证。 10折后得到的混淆矩阵如图: 0 1 0 293+282+291+298+292+ 295+298+290+275+281=2895 47+56+54+39+49+ 59+53+54+62+57=530 1 13+16+10+17+16+ 11+19+17+17+22=158 113+112+111+111+108+ 100+95+104+111+105=1070 模型的交叉验证精度为:85.21% 3.2随机森林算法 ①模型求解 对于randomForest函数而言,除了自变量、因变量、使用的数据集以外,它的重要参数还有:ntree(在森林中树的个数)、mtry(每棵树使用的特征个数)等。 在随机森林中计算变量的重要性时,通过将相应变量替换为一列随机的数后,计算模型的准确率或者GINI系数的降低。0表示变量替换后对分类为0数据的影响;1表示变量替换后对分类为1的数据的影响。MeanDecreaseAccuracy表示变量替换后平均减少的准确率;MeanDecreaseGini表示变量替换后平均减少的GINI系数。数值越大表示变量越重要。为更直观展示变量的重要性,绘制变量的重要性曲线如下:
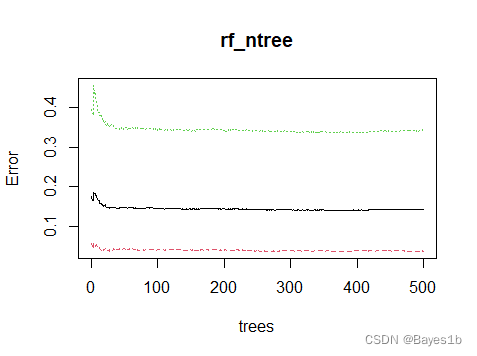
由图知,移除JoiningYear(入职时间)后,平均减少的准确率最高;移除JoiningYear(入职时间)后,平均减少的GINI系数最多。说明该变量较为重要。 为了测试出ntree为多少时模型是最优的,我们先采用500棵树,然后画出错误率与决策树的数量的关系曲线。在这里,我们考虑了所有自变量的平方根即3作为mtry(每棵树使用的特征个数)。
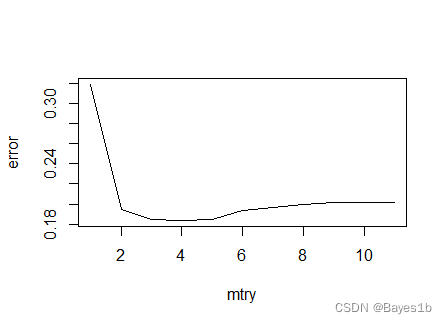
可以看出,在树的数量大于100时模型就基本上较为稳定,因此在保证效能的情况下,我们可以减少改变决策树的数量,减少运行时间。由于500棵树时模型较为稳定,所以我们这里的ntree值就取100棵树。 下面给定不同的mtrt值进行比较,看看该参数对错误率的影响情况,从而确定最佳的那个参数。
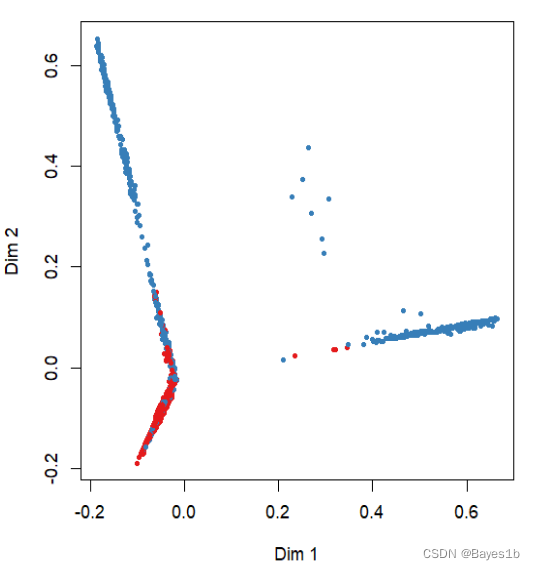
由上图可知,mtry为4时错误率最少。 因此,当ntree=100,mtry=4时模型有最优。根据混淆矩阵,此时的训练集精度为90.03%。 可视化训练集随机森林图:
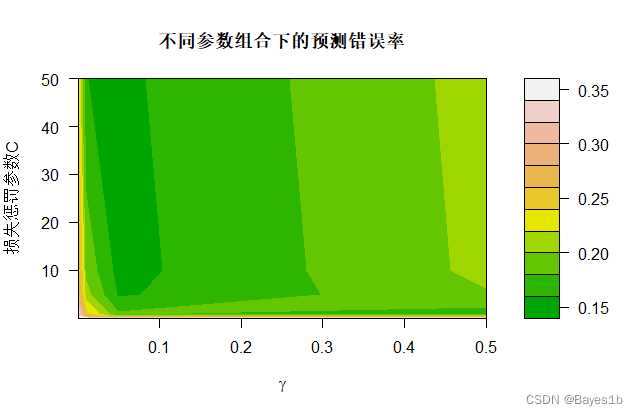
③预测 利用最优模型对测试集样本数据进行预测。根据混淆矩阵,测试集的测试精度为84.90%。 ④交叉验证 将上述最优模型作用于全部数据集,并进行10-折交叉验证。 10折后得到的混淆矩阵如图: 0 1 0 296+290+295+307+301+ 299+307+300+282+293=2970 37+47+42+34+42+ 50+47+50+55+54=458 1 10+8+6+8+7+ 7+10+7+10+10=83 123+121+123+116+115+ 109+101+108+118+108=1142 模型的交叉验证精度为:88.37%。 3.3 SVM算法 ①模型求解 对于SVM函数而言,除了自变量、因变量、使用的数据集以外,它的重要参数还有:gamma(指定多项式核以及径向基核中的参数γ)、cost(损失惩罚函数参数C)等。 考虑到样本量适中,在我们给定Gamma与cost的值后,利用10折交叉验证找到预测误差最小时的损失惩罚参数。
可以看到,颜色越深误差越小,即当gamma取0.05,cost取10时模型有最优。根据混淆矩阵,此时的训练集精度为86.67%。 ③预测 利用最优模型对测试集样本数据进行预测。根据混淆矩阵,测试集的测试精度为83.33%。 ④交叉验证 将上述最优模型作用于全部数据集,并进行10-折交叉验证。 10折后得到的混淆矩阵如图: 0 1 0 287+283+287+294+294+ 287+294+283+269+281=2859 54+57+59+44+61+ 70+66+68+74+67=620 1 19+15+14+21+14+ 19+23+24+23+22=194 106+111+106+106+96+ 89+82+90+99+95=980 模型的交叉验证精度为:82.51%。 3.4 算法比较 将各算法得到的精度进行比较。 算法 训练集精度 测试集精度 交叉验证精度 决策树 87.17 84.40 85.21 随机森林 90.03 84.90 88.37 SVM 86.67 83.33 82.51 由上表可以发现,各类模型拟合效果均较为良好,随机森林算法最优。在运行时我们还发现,SVM运行速度较慢,决策树算法运行速度较快。 4总结 在建模过程中,考虑到数据相差并不是很大,因此我们没有对数据进行标准化,后续可以进行标准化然后再观察拟合效果。 总的来说,在参数选择环节,每个模型我们都只设置了两个在我们看来最重要的参数的值,然后进行了一番选择。但是有些模型的其他参数可能还是非常重要,但是却被我们忽视,可能会造成建模上的误差,导致最后结果的错误。 在使用决策树算法时,虽然该算法较为简单便捷,但是可能出现过拟合的情况。而且对于各类别样本数量不一致的数据,在决策树当中,信息增益的结果偏向于那些具有更多数值的特征。 在使用随机森林算法时,虽然它可以处理高维度的数据,且不用作特征选择,但是它对随机种子的依赖性较大。我们无法控制内部运行,只能通过给定随机种子和参数来不断尝试。这也可能导致我们给出的模型并不是最佳模型。而自己不断细致调参可能会消耗大量时间,最后也得不到那个最好的结果,随机性过强。 在使用SVM算法时,只考虑了radial核函数,导致拟合效果不佳。这很可能是该数据并不适合这样划分,后续可以采取polynomial核函数、线性核函数、sigmoid核函数进行建模。同时我们建模时没有进行特征选择,有些变量对拟合效果可能是副作用或者无作用的,且过多变量影响运算效率,可以运用caret包的rfe函数执行递归的特征选择过程,进而得到最好的结果。 虽然我们在这里并没有完成启发式参数选择的办法,但与交叉验证选参数的方法相比,启发式参数选择的办法应该较为高效率。因为交叉验证循环次数肯定要超过启发式选择。根据查找的资料和个人的理解,我们就拿SMO为例。SMO的思想类似于坐标上升算法,我们需要优化一系列的参数值,但是每次都会选择尽量少的参数来优化,再不断迭代直到函数收敛到最优值,相当于如果算法判断某个参数不合理,那么根本就不会取运行那个选择进而增大计算量。那这样看来,循环次数肯定会小于交叉验证的次数。准确率大致来看可能差不多,因为都会先给定参数的范围值,那么最后选出的结果应该大差不差。 附录 # 导入数据 set.seed(11) epl |


【本文地址】
今日新闻 |
推荐新闻 |