大数据平台Hadoop |
您所在的位置:网站首页 › 数据分析师笔试题 › 大数据平台Hadoop |
大数据平台Hadoop
|
闭卷笔试100分钟 题型单选(30)、多选(20)、问答(30)、应用(20) 一 概论 1、大数据5V特点Volume(大量)、Velocity(高速)、Variety(多样)、Value(低密度价值)、Veracity(真实性) *2、Google三驾马车GFS(分布式文件系统)、MapReduce(超大集群的简单数据处理)、BigTable(结构化数据的分布式存储系统) 3、Hadoop的特点扩容能力:可靠的存储和处理PB级数据 低成本:普通计算机组成集群来处理数据,可达上千个节点 高效率:节点上并行处理数据使得速度快 可靠性:自动维护数据的多份复制,任务失败后自动重新部署计算任务 4、Hadoop生态系统HDFS:分布式存储,数据存储功能 MapReduce:分布式计算框架 HBase:分布式数据库,基于HDFS的NOSQL数据库 Zookeeper:,分布式协调服务框架,hadoop组件管理端 Pig:数据流处理,对MapReduce的抽象 Hive:数据仓库,将结构化的数据文件映射为数据表,将SQL翻译为MapReduce语句进行查询 5、Hadoop的主要版本p7 1.3.4 最新的3.*,出现了YARN的版本2.0 6、NoSQL有哪些关系型数据库产品很多,如 MySQL、Oracle、Microsoft SQL Sever 等,但它们的基本模型都是关系型数据模型。 非关系型数据库又称为:NoSQL ,没有统一的模型,而且是非关系型的。 NoSQL 数据库并没有一个统一的架构,两种不同的 NoSQL 数据库之间的差异程度,远远超过两种关系型数据库之间的不同。可以说,NoSQL 数据库各有所长,一个优秀的 NoSQL 数据库必然特别适用于某些场合或者某些应用,在这些场合中会远远胜过关系型数据库和其他的 NoSQL 数据库。 常见的 NoSQL 数据库包括键值数据库、列族数据库、文档数据库和图形数据库,其具体分类和特点如表所示: 分类相关产品应用场景数据模型优点缺点键值数据库Redis、Memcached、Riak内容缓存,如会话、配置文件、参数等; 频繁读写、拥有简单数据模型的应用 键值对,通过散列表来实现扩展性好,灵活性好,大量操作时性能高数据无结构化,通常只被当做字符串或者二进制数据,只能通过键来查询值列族数据库Bigtable、HBase、Cassandra分布式数据存储与管理以列族式存储,将同一列数据存在一起可扩展性强,查找速度快,复杂性低功能局限,不支持事务的强一致性文档数据库MongoDB、ES、CouchDBWeb 应用,存储面向文档或类似半结构化的数据 value 是 JSON 结构的文档数据结构灵活,可以根据 value 构建索引缺乏统一查询语法图形数据库Neo4j、InfoGrid社交网络、推荐系统,专注构建关系图谱图结构支持复杂的图形算法复杂性高,只能支持一定的数据规模
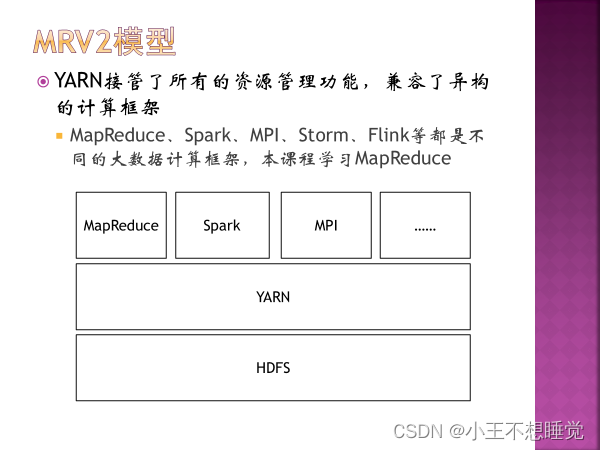
7、Hadoop/HBase/Zookeeper属于什么开源项目? Apache基金会 8、Hadoop的开发语言(Hadoop是用什么语言编写的)Java 二 HDFS HDFS:分布式文件系统,数据存储 YARN:统一资源管理和调度系统,支持多种框架 MapReduce:分布式计算框架,运行于YARN上
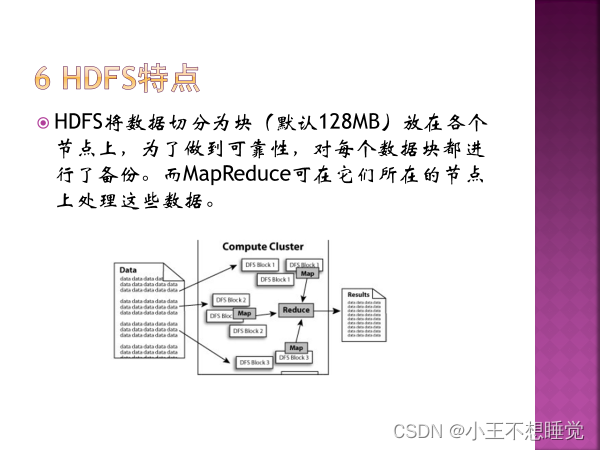
能保存PB级数据量,数据散布在大量节点上,支持更大文件 可靠性、高容错性,多节点数据备份 与MapReduce集成,允许数据在本地计算,减少计算时数据交互 局限性:不适合低延迟数据访问 不适合大量小文件存储 不支持多用户并发写入及任意修改文件,一次写入多次读取 不支持缓存,每次从硬盘重新读取
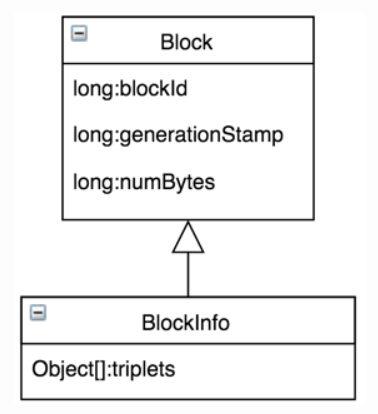
在HDFS的实现中,数据块被抽象成类org.apache.hadoop.hdfs.protocol.Block(我们以下简称Block)。在Block类中有如下几个属性字段: 1 2 3 4 5 public class Block implements Writable, Comparable { private long blockId; // 标识一个Block的唯一Id private long numBytes; // Block的大小(单位是字节) private long generationStamp; // Block的生成时间戳 } 我们从WEB UI上的数据块信息也可以看到:
一个Block除了存储上面的3个字段信息,还需要知道这个Block含有多少个备份,每一个备份分别存储在哪一个DataNode上,为了存储这些信息,HDFS中有一个名为org.apache.hadoop.hdfs.server.blockmanagement.BlockInfoContiguous(下面我们简称为BlockInfo)的类来存储这些信息,这个BlockInfo类继承Block类,如下:
BlockInfo类中只有一个非常核心的属性,就是名为triplets的数组,这个数组的长度是3*replication,replication表示数据块的备份数。这个数组中存储了该数据块所有的备份数据块对应的DataNode信息,我们现在假设备份数是3,那么这个数组的长度是3*3=9,这个数组存储的数据如下:
也就是说,triplets包含的信息: triplets[i]:Block所在的DataNode;triplets[i+1]:该DataNode上前一个Block;triplets[i+2]:该DataNode上后一个Block;其中i表示的是Block的第i个副本,i取值[0,replication)。 我们在HDFS的NameNode中的Namespace管理中讲到了,一个HDFS文件包含一个BlockInfo数组,表示这个文件分成的若干个数据块,这个BlockInfo数组实际上就是我们这里说的BlockInfoContiguous数组。以下是INodeFile的属性: 1 2 3 4 public class INodeFile { private long header = 0L; // 用于标识存储策略ID、副本数和数据块大小的信息 private BlockInfoContiguous[] blocks; // 该文件包含的数据块数组 } 4、HDFS守护进程
5、主从结构 主节点是什么?从节点是什么? 基本的名词:NameNode SecondaryNameNode DataNode各个节点的功能 基本的名词:数据划分为Block(大小、备份数量……)、元数据、client…… NameNode:主节点(Master),管理元数据SecondaryNameNode:辅助NameNode完成某些功能,解放Name Node性能,无法替代NameNodeDataNode:从节点(Slave),存储文件的Block。文件的块(Block),默认大小128MB 同一个块备份到多个(默认三个)DataNode中存储 读写文件时,所有节点参与工作,负载均衡更好
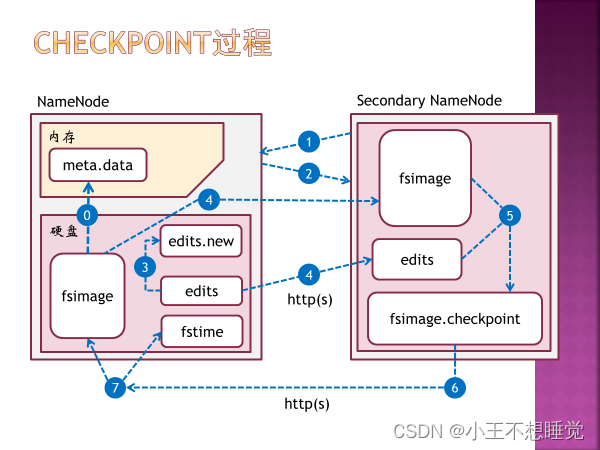
6、元数据、Block、DataNode、NameNode、心跳 元数据: 存储文件路径、文件副本数量、文件块所处的服务器位置等。 元数据保存在NameNode中 内存元数据:meta data,用于查询 硬盘元数据镜像文件:fsimage,持久元数据化存储元数据 数据操作日志:edits,将更改记录进去,可以此运算出元数据 元数据管理过程: 系统启动,读取fsimage和edis至内存,形成内存元数据meta data, client向NameNode发起数据增删查请求,NameNode在接受请求后在内存元数据中执行操作,并返回结果给client,如果是增删操作,则同时记录数据操作日志edits。Secondary NameNode在合适的时间将操作日志合并到fsimage中。
在HDFS系统中,为了便于文件的管理和备份,引入分块概念(block)。这里的 块 是HDFS存储系统当中的最小单位,HDFS默认定义一个块的大小为64MB。当有文件上传到HDFS上时,若文件大小大于设置的块大小,则该文件会被切分存储为多个块,多个块可以存放在不同的DataNode上,整个过程中 HDFS系统会保证一个块存储在一个datanode上 。但值得注意的是 如果某文件大小没有到达64MB,该文件并不会占据整个块空间 。 hadoop计算的分片大小不小于blockSize,并且不小于mapred.min.split.size。默认情况下,以HDFS的一个块的大小(HDFS也是采用块管理的,但是比较大,在Hadoop1.x中默认大小是64M,Hadoop2.x中大小默认为128M)为一个分片,即分片大小等于分块大小。当某个分块分成均等的若干分片时,会有最后一个分片大小小于定义的分片大小,则该分片独立成为一个分片。 DataNode故障恢复:每个DataNode定期(默认3秒)向NameNode发送心跳信息,报告自己的状态。如果DataNode发生故障没有定时向NameNode发送心跳,就会被NameNode标记为“宕机”,该节点上所有数据不可读,NameNode不会向其发送任何I\O请求。 NameNode定期检查数据块的副本数量,小于冗余因子(即设定的副本数)时启动冗余复制,在其他正常数据节点生成副本。
NameNode故障恢复: 如果进行了高可用性配置,发生NameNode故障时,由zookeeper通过选举机制选取一个备用名称节点切换为激活状态,保证hadoop正常运行。 如果没有进行高可用性配置,系统把NameNode的核心文件同步复制到SecondaryNameNode(备份名称节点)中,当发生NameNode故障时,通过SecondaryNameNode中的FsImage和EditLog文件恢复NameNode。
心跳过程: 数据节点主动发送请求及要报告的信息(register:自身信息,block report:block的信息,使NameNode可以维护block和DataNode之间的映射关系),名称节点被动回复需要传达的信息或指令。NameNode没有收到周期性send heartbeat,则认为该数据节点失效,将失效节点中的bolock重新备份到其他数据节点。
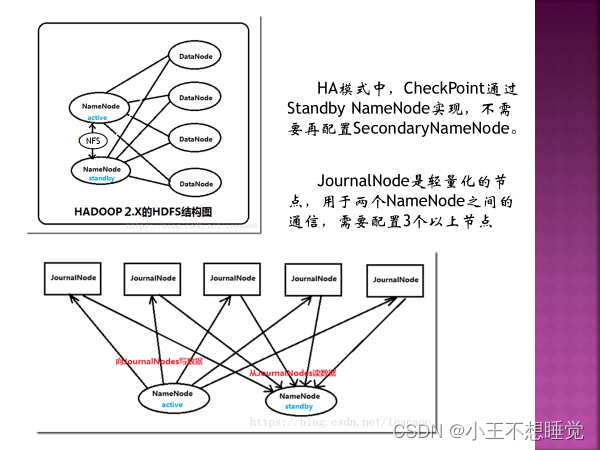
hadoop2.x中引用HDFS名称节点高可用框架。 配置两个相同的NameNode,一个为active mode活跃模式,另一个为standby mode待机模式,两个node数据保持一致,活动节点失效,则待机节点切换为活动节点,保证hadoop正常运行。 HA模式(高可用名节点)(High Availability NameNode),不需要再配置SecondaryNameNode,CheckPoint通过Standby NameNode实现。 JournalNode是轻量化节点,用于两个NameNode之间通信,需要配置3个以上节点。
8、DataNode容错机制
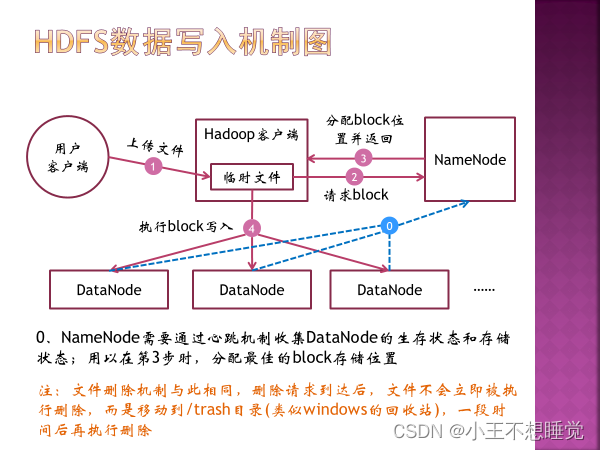
*9、HDFS读写流程 写入机制: 用户客户端请求Hadoop客户端,执行文件上传,上传的文件写入hadoop客户端的临时目录,当文件写入数据量超过block(Hadoop1.x缺省64MB,2.x缺省128MB)大小时,请求NameNode申请数据块。NameNode返回数据块ID及存储数据块的DataNode地址列表,hadoop客户端根据地址列表向DataNode写入数据块。客户端写入一个数据块后,在DataNode之间异步进行数据块复制,最后一个DataNode上数据块写入完成后,发送一个确认信息给前一个DataNode,第一个DataNode返回确认信息给客户端,数据写入完毕。客户端向NameNode发送最终确认信息。 删除机制与此相同,删除请求到达后,文件不会立即被执行删除,而是移动到/trash目录(回收站),一段时9间后再执行删除。
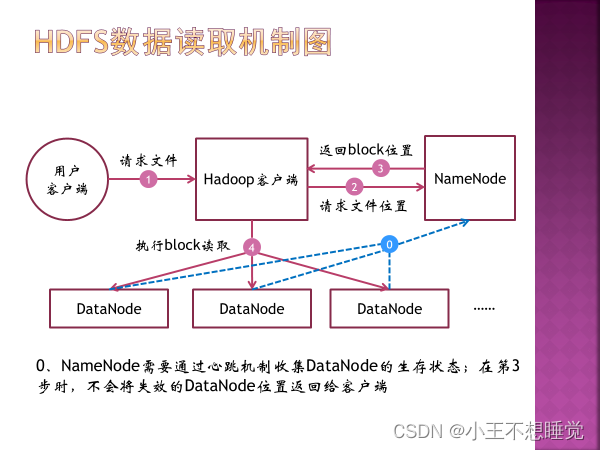
用户客户端请求Hadoop客户端,请求返回指定文件,hadoop客户端向NameNode发送读文件请求。NameNode查询meta data并返回文件数据对应的数据块ID及存储数据块的DataNode地址列表,该列表按照DataNode与客户端的距离进行排序。客户端在距离最近的数据节点上读取数据,如果读取失败,则从另一个副本所在数据节点读取数据。读取到所有block后合并成文件。 NameNode需要通过心跳机制收集DataNode生存状态,不会将失效的DataNode位置返回给客户端。 客户端:Client。代表用户通过与NameNode和DataNode交互来访问整个HDFS,整个HDFS运行在内网,与外界隔离,只有Client可以接受外界命令,确保系统安全。
11、常见虚拟机Virtual Box、VMWare
12、安装Hadoop之前的步骤:配置SSH免密、安装JDK
13、常见的配置文件: 环境变量配置在/etc/profile,配置完后source /etc/profile /etc/hosts /etc/hostname 同14: core-site.xml(配置项)、hdfs-site.xml、yarn-site.xml workers 14、*常见Linux命令:cd、ls、mkdir、cat、jps等,vi编辑器的常用命令 常见错误:command not found,file or directory no exists 启动/停止Hadoop的命令 start-all.sh/stop-all.sh 15、Hadoop常见配置文件core-site.xml(配置项)、hdfs-site.xml、yarn-site.xml workers
16、HDFS守护进程、YARN守护进程 (主节点的守护进程和从节点的守护进程分别是什么)
*17、HDFS命令 -ls -mkdir -get(-copyToLocal) -put(-copyFromLocal)
*18、异常分析 无DataNode的情况下,能否 -ls?可以,原因:目录结构存储在namenode中的,不需要访问datanode There are 0 datanode(s) running and 0 node(s) are excluded in this operation. 能否-get/-put?不能,原因,上传下载文件需要访问datanode 19、HDFS Java API用途HDFS REST API
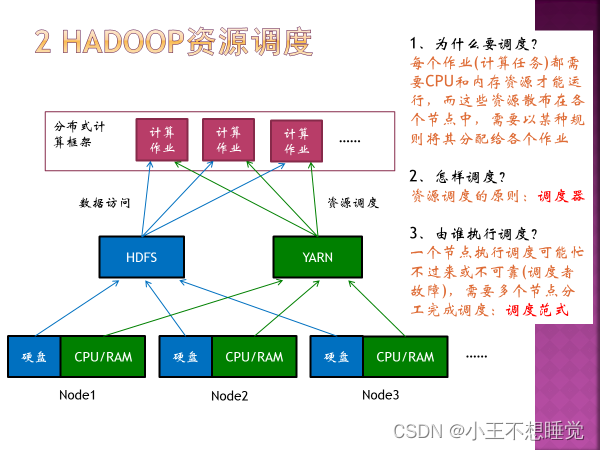
不管分步执行启动过程还是通过脚本自动启动,模块的启动顺序都是一致的即先启动HDFS模块然后再启动YARN模块,停止的过程则是先停止YARN模块再停HDFS模块。 在 Hadoop 中,HDFS 和 YARN 是两个不同的服务,它们可以同时启动,也可以分别启动。一般情况下,需要先启动 HDFS,因为其他服务如 MapReduce、Spark 等需要依赖 HDFS 存储和读取数据。而 YARN 则是用于资源调度和任务管理的服务,它可以在 HDFS 启动后启动。 具体来说,Hadoop 集群的启动流程如下: 启动 HDFS:包括 NameNode 和 DataNode 服务,用于存储和管理数据。启动 YARN:包括 ResourceManager 和 NodeManager 服务,用于资源调度和任务管理。启动其他服务:如 MapReduce、Spark 等。 三 YARN 1、YARN是什么
2、YARN主从架构(守护进程)



4、Yarn调度器(三种) 
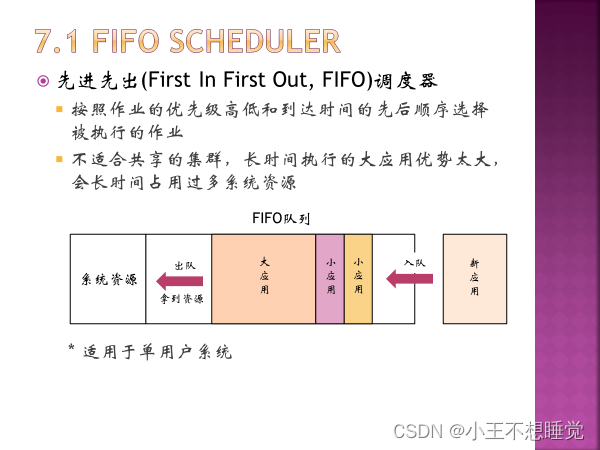 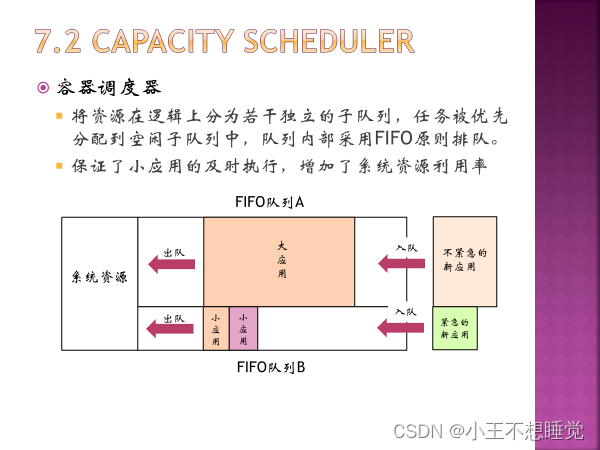
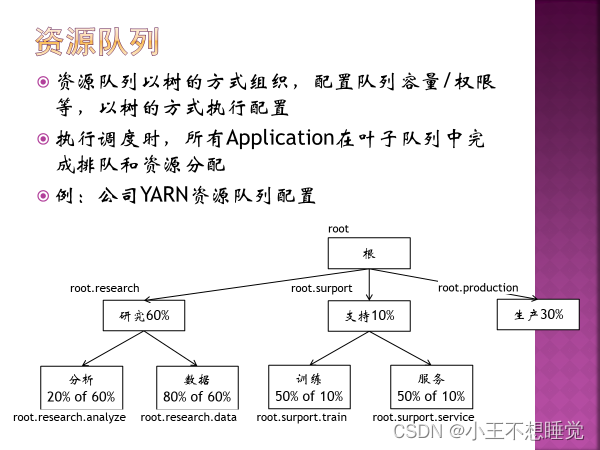
 5、一级调度RM,二级调度AM 5、一级调度RM,二级调度AM
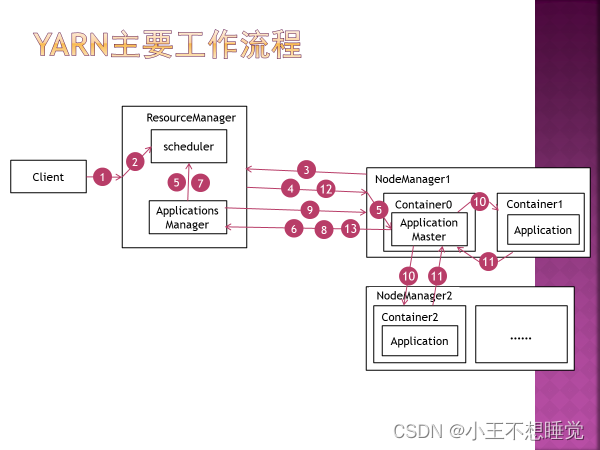
YARN工作流程:
四 MapReduce
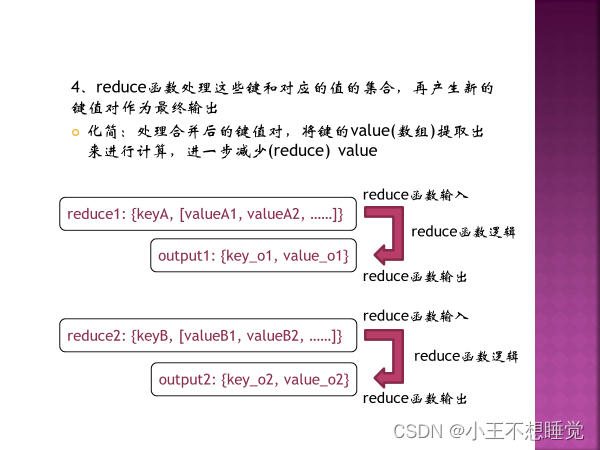
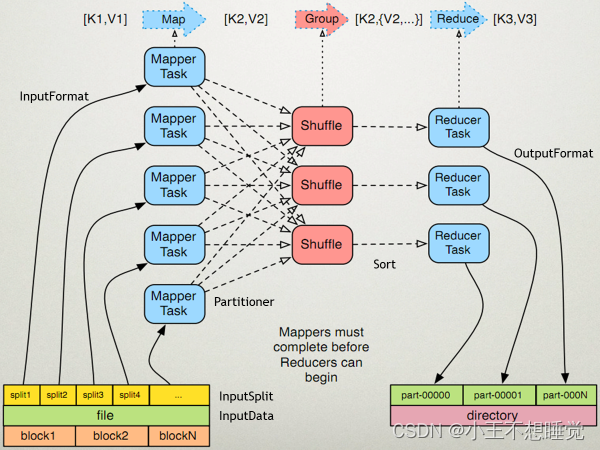
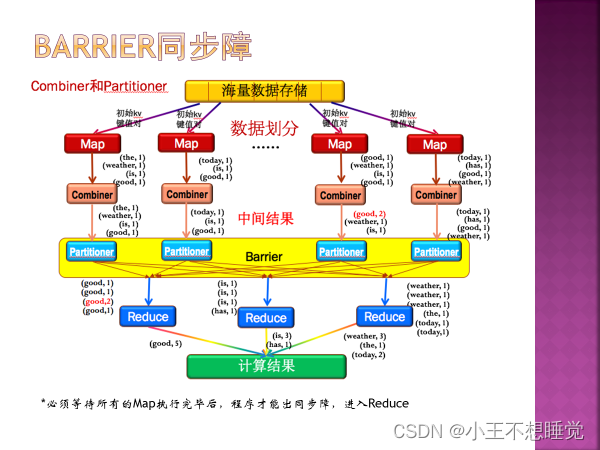
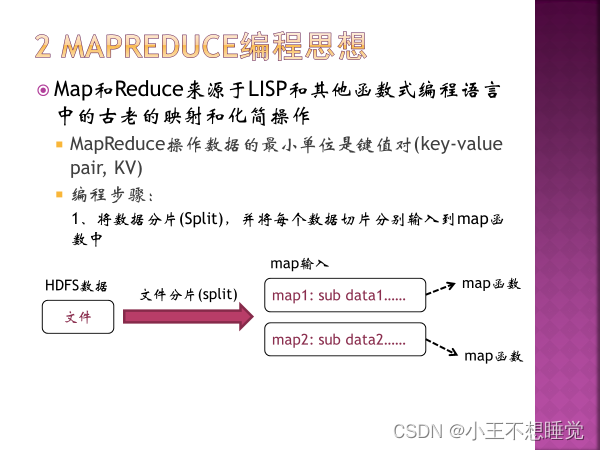
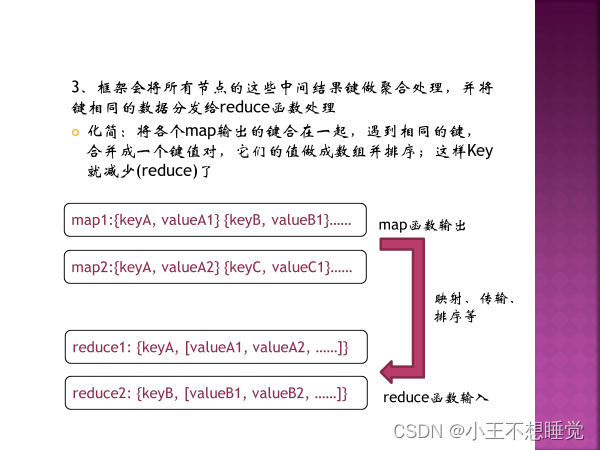
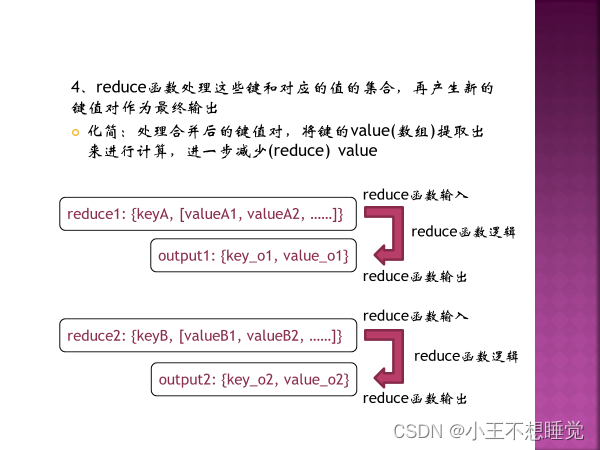
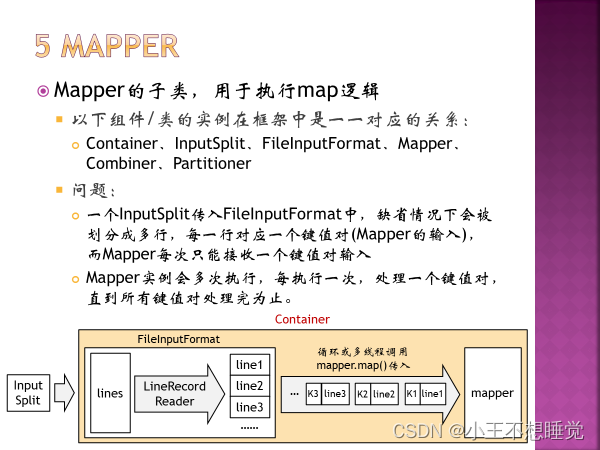
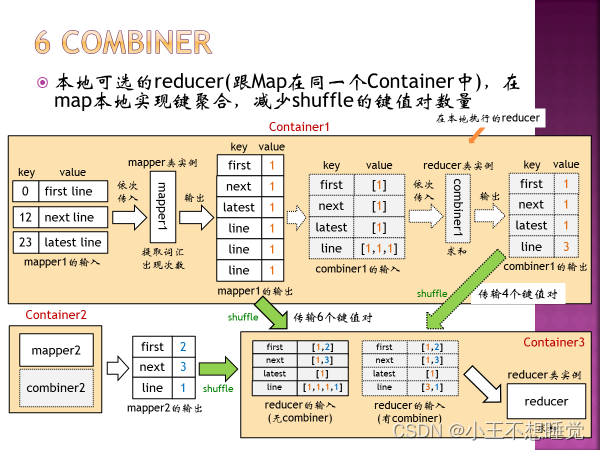
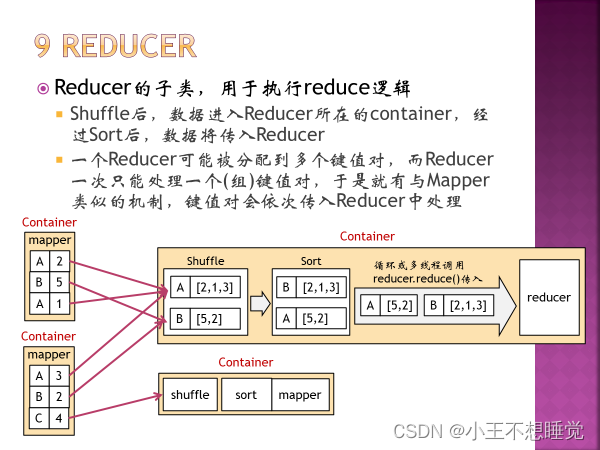
 *2、MapReduce过程 *2、MapReduce过程
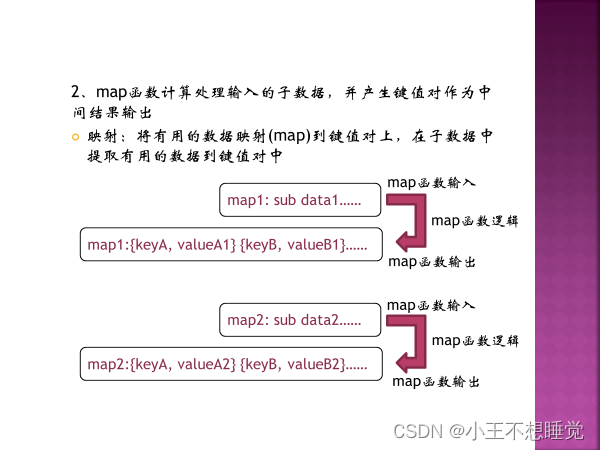
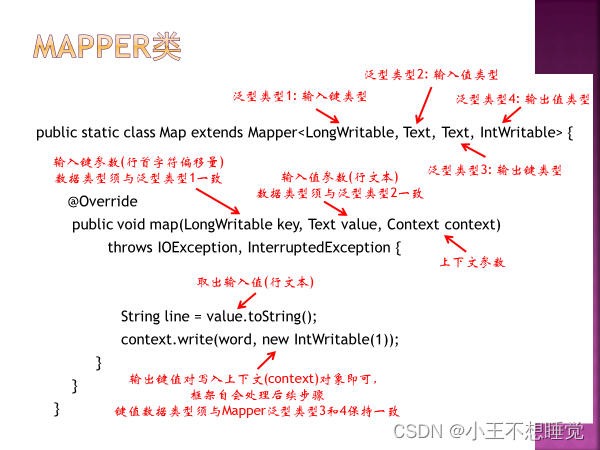
context它是mapper的一个内部类,简单的说顶级接口是为了在map或是reduce任务中跟踪task的状态,很自然的MapContext就是记录了map执行的上下文,在mapper类中,这个context可以存储一些job conf的信息,比如job运行时参数等,我们可以在map函数中处理这个信息,这也是hadoop中参数传递中一个很经典的例子,同时context作为了map和reduce执行中各个函数的一个桥梁,这个设计和java web中的session对象、application对象很相似 


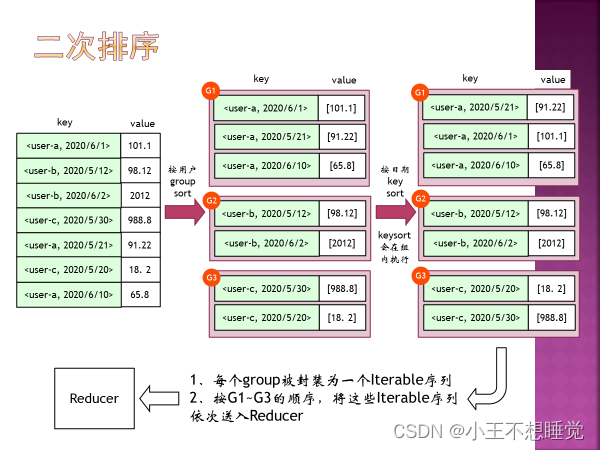
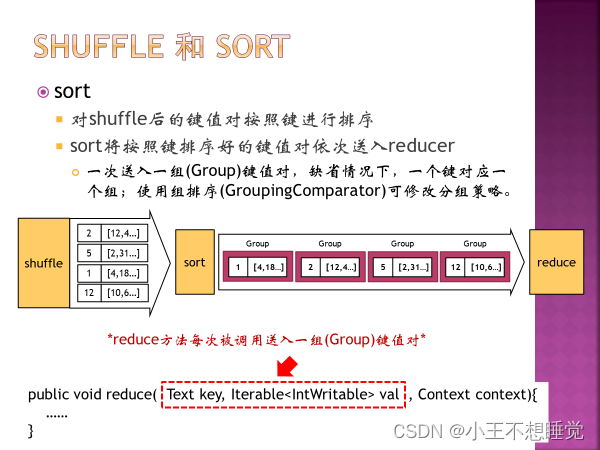
(Sort: MapReduce默认输出的key是字符类型时,默认是按照字典序排序) 5、二次排序的概念
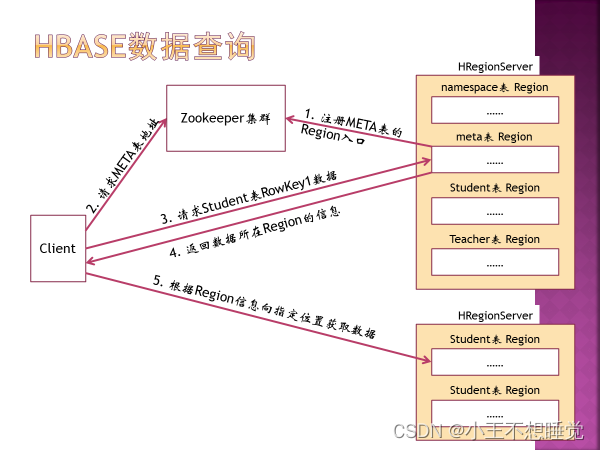
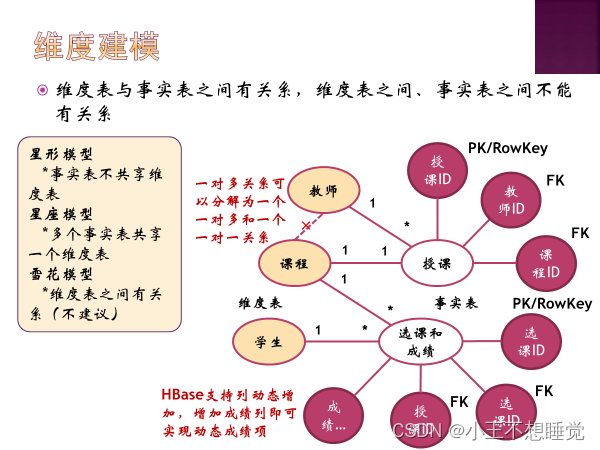
五 HBase
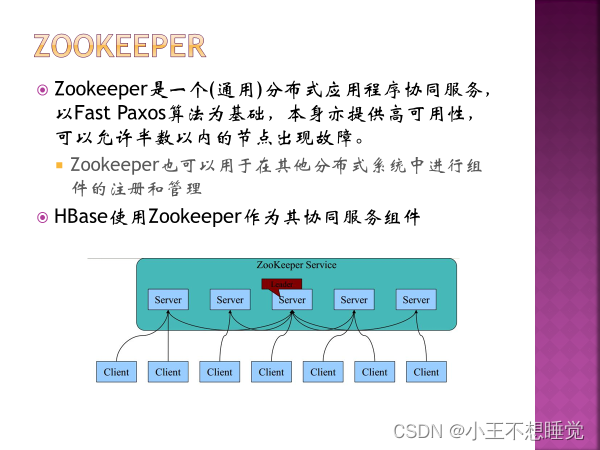
*2、Zookeeper守护进程 QuorumPeerMain 
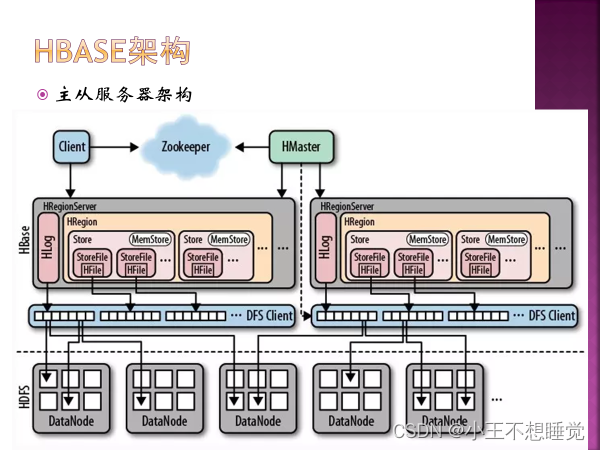
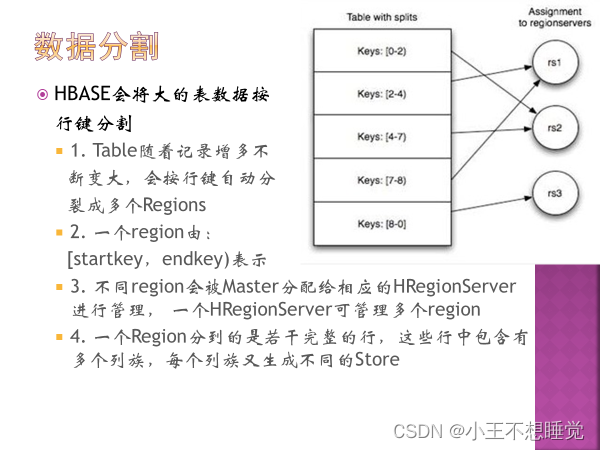
*4、如何划分Region,Region中的HFile和列族的关系 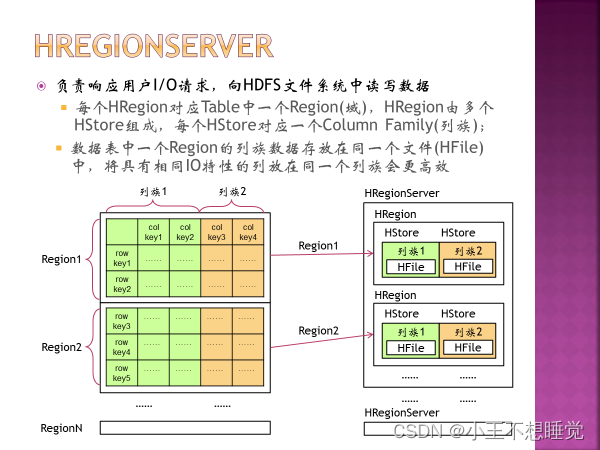

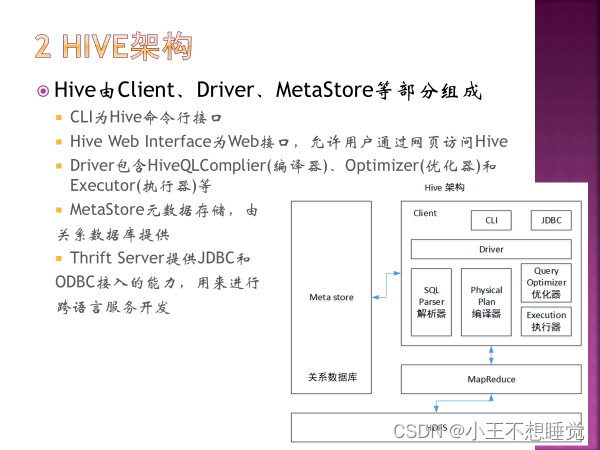
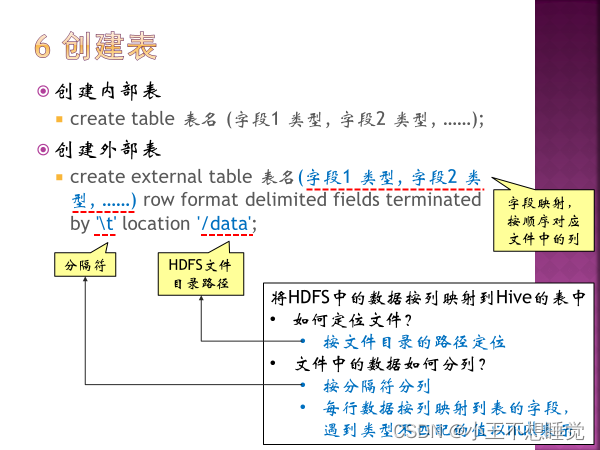
提供类SQL(HiveQL)查询,HiveQL会被编译成MapReduce,在Hadoop中执行查询 是基于HDFS和MapReduce的数据仓库软件
Hive是一个构建在Hadoop上的数据仓库框架 Hive的设计目的是让精通SQL但JAVA编程技能相对较弱的分析师能够对存放在HDFS上的大规模数据集执行查询。 数据仓库是面向主题的,普通操作性数据库主要面向事务性处理,数据仓库又称为分析型数据库。 HIVE特点: 延迟高,适合高吞吐量、批量、海量数据处理; 语法和SQL相似,学习成本低,避免去写复杂的MapReduce,缩短开发周期 支持自由的扩展集群的规模,一般不需要重启服务 Hive支持自定义函数,用户可以根据自己的需求去定义函数。 良好的容错性,部分节点出现错误,SQL仍然可以成功执行。
仅供个人复习参考 cr.Kerst |













































































【本文地址】
今日新闻 |
推荐新闻 |