机器学习入门(1) |
您所在的位置:网站首页 › 数据分析和程序员 › 机器学习入门(1) |
机器学习入门(1)
|
话不多说上代码,爬取一些数据进行可视化和机器学习演练 #数据分析库 import pandas as pd #科学计算库 import numpy as np from pandas import Series,DataFrame import matplotlib.pyplot as plt import seaborn as sns plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签 plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号 data_all = pd.read_excel("alldata.xlsx") #这里如果使用read—_csv会产生报错,因为d.read.csv默认分隔符是“,”,倘若文档中存在该字符,则会自动分割 #解决办法:改变默认的分隔符 ''' 在pd.read_csv中加入参数sep设置为None或者别的字符如\t 如: data = pd.read_csv(“E:/test/datas/new/11-new.txt”,encoding=“utf-8”,header=None,sep = None) ''' print(data_all.head(5))#查看前五行 print(data_all.info())#查看 基本信息 #可以看到,数据共1305条,数据类型,以及数据并无缺失,这里省略数据空值处理的过程 '''公司代号与其他关系不大,暂且忽略''' #接下来划分数据集 print('简单做图') #首先我们来看特征的基本情况 x = data_all['城市'] y =data_all['薪水'] q = data_all['职位名称'] #value_counts()pandas 的value_counts()函数可以对Series里面的每个值进行计数并且排序。 x.value_counts().plot.pie(labeldistance = 1.1,autopct = '%1.2f%%', shadow = False,startangle = 90,pctdistance = 0.6,figsize=(10,10),fontsize =20) plt.show() #labeldistance,文本的位置离远点有多远,1.1指1.1倍半径的位置 #autopct,圆里面的文本格式,%3.1f%%表示小数有三位,整数有一位的浮点数 #shadow,饼是否有阴影 #startangle,起始角度,0,表示从0开始逆时针转,为第一块。一般选择从90度开始比较好看 #pctdistance,百分比的text离圆心的距离 #patches, l_texts, p_texts,为了得到饼图的返回值,p_texts饼图内部文本的,l_texts饼图外label的文本 #figsize,图片的尺寸 #可以看到北上广深占比最大,其次为成都,杭州,武汉等新一线城市
这里绘图查看一下各个城市中程序员薪资的最大值与最小值情况
接下来 看一下不同的方向分类 train[['最小值','最大值']].groupby(train['职位名称']).mean().plot.bar(figsize=(10,10))
即可生成网页版数据报告,上图 |

 接下来按照职位名称来可视化,但是其实并没有什么意义,因为数据集原本就是按照数据分析师,python工程师和前端工程师爬取下来的
接下来按照职位名称来可视化,但是其实并没有什么意义,因为数据集原本就是按照数据分析师,python工程师和前端工程师爬取下来的 接下来大概看一下城市与薪资,薪资与工作年限等等的关系
接下来大概看一下城市与薪资,薪资与工作年限等等的关系


 可以看出来什么也不太清楚,但是显然一线城市的薪资最高值与最低值比二三线城市要高出许多,这也符合我们的日常认知。 接下来我们来看一下工作年限与薪资的关系
可以看出来什么也不太清楚,但是显然一线城市的薪资最高值与最低值比二三线城市要高出许多,这也符合我们的日常认知。 接下来我们来看一下工作年限与薪资的关系 结果基本符合我们的日常认知,值得注意的是一年以下的工作年限薪资水平普遍低于应届毕业生,随后随着工作年限的增加而升高。 接下来查看一下公司规模
结果基本符合我们的日常认知,值得注意的是一年以下的工作年限薪资水平普遍低于应届毕业生,随后随着工作年限的增加而升高。 接下来查看一下公司规模 接下来看一下薪资最小值、最大值分布
接下来看一下薪资最小值、最大值分布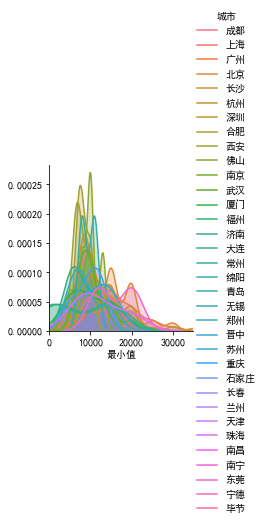
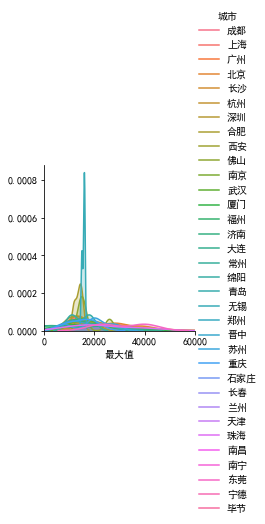 可以看出城市的最低薪资最多在1w左右,最高薪资集中在1.8w左右
可以看出城市的最低薪资最多在1w左右,最高薪资集中在1.8w左右 最后再给大家安利一个一行代码生成数据报告的强大工具 pandas_profiling 同样的pip install pandas_profiling 即可
最后再给大家安利一个一行代码生成数据报告的强大工具 pandas_profiling 同样的pip install pandas_profiling 即可





 功能性可以说是十分强悍了! (激动地搓手手)
功能性可以说是十分强悍了! (激动地搓手手)【本文地址】
今日新闻 |
推荐新闻 |