精准度分析:如何衡量机器学习模型的准确性 |
您所在的位置:网站首页 › 数据准确性的重要性 › 精准度分析:如何衡量机器学习模型的准确性 |
精准度分析:如何衡量机器学习模型的准确性
|
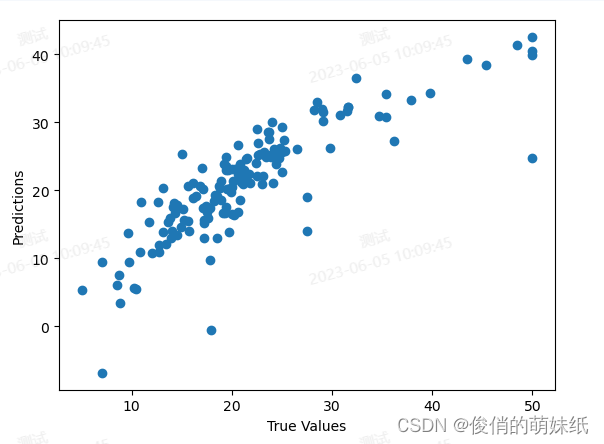
模型评估是机器学习中非常重要的一步,它是对训练好的模型进行性能评估和验证的过程。在机器学习中,模型的准确性和泛化能力是非常关键的因素,模型评估可以帮助我们了解模型在新数据上的泛化性能如何,以及为进一步调整和优化模型提供指导。 在模型的评估中,通常会使用一些统计指标来衡量模型的表现,如均方误差(MSE)、平均绝对误差(MAE)、均方根误差(RMSE)、R平方等。这些指标能够反映出模型预测结果与实际结果的差异程度,我们可以通过这些指标来评估模型的准确性、稳定性和预测能力等方面的表现,同时也可以用于比较不同模型之间的性能差异。此外,还可以通过可视化工具来展示模型的评估结果,例如条形图、曲线图、散点图、热力图等等。 回归模型评估简介:基于预测结果和原始结果,评价回归算法模型的优劣,包含指标。 其中指标包括R2、RMSE。 常用的回归模型评估指标:均方误差(Mean Squared Error, MSE):MSE是预测值与真实值之间距离的平方和除以样本数量的平均值。MSE可以评估模型在预测连续数值时的精度。如果MSE越小,则说明模型的预测结果越接近真实值。均方根误差(Root Mean Squared Error, RMSE):RMSE是MSE的平方根,因此它反映了预测值与真实值之间的平均距离,并且通常比MSE更易于解释。平均绝对误差(Mean Absolute Error, MAE):MAE是预测值与真实值的绝对值之和除以样本数量的平均值。MAE可以评估模型在连续变量上的表现,但是它不像MSE一样强调较大的误差值。决定系数(Coefficient of Determination, R^2):R^2度量模型在解释目标变量方差方面的表现。它的取值范围在0和1之间,其中1表示完美拟合,而0表示模型无法解释目标变量的差异。 举例说明:烘焙师做蛋糕,根据已知的烘焙时间和相关特征(蛋糕尺寸、温度等)数据集作为基准、将数据分为训练集和测试集。随后,烘焙师根据经验和模型来预测测试集中的每个蛋糕的烤制世界,然后将预测值和测试集中的真实烘焙时间进行比较。如果烤制时间的预测值与真实值非常接近,那么差的平方将会很小,MSE也会很小。相反,如果预测值与真实值相差较大,那么MSE将会增大。还有另一个常用的评估指标是均方根误差(Root Mean Squared Error,RMSE)。与MSE不同的是,RMSE是将MSE的结果开根号,这样我们可以获得更直观的数值,表示预测值与真实值之间的平均差距。 通过计算MSE和RMSE,我们可以对回归模型的表现有一个直观的认识。如果MSE和RMSE的值较小,那么说明模型的预测能力较好,烘焙师的技能水平高。反之,如果MSE和RMSE较大,就意味着模型的预测与真实值之间存在较大偏差,需要对模型进行改进。 举例说明:天气预报员的准确性,根据过去的天气情况数据,包括实际的最高气温和其他相关特征(如湿度、风速等)。将数据分为训练集和测试集。 MSE和RMSE越小,R²越接近1,代表模型的性能越好。 # 导入需要的库 import matplotlib.pyplot as plt from sklearn.datasets import load_boston from sklearn.linear_model import LinearRegression from sklearn.model_selection import train_test_split from sklearn.metrics import mean_squared_error, r2_score # 加载波士顿房价数据集 boston = load_boston() # 分割数据集 X_train, X_test, y_train, y_test = train_test_split(boston.data, boston.target, test_size=0.3, random_state=42) # 创建线性回归模型对象 lr = LinearRegression() # 训练模型 lr.fit(X_train, y_train) # 预测测试集 y_pred = lr.predict(X_test) # 评估模型 mse = mean_squared_error(y_test, y_pred) rmse = mean_squared_error(y_test, y_pred, squared=False) r2 = r2_score(y_test, y_pred) # 绘制y轴的实际值与预测值散点图 plt.scatter(y_test, y_pred) plt.xlabel("True Values") plt.ylabel("Predictions") plt.show() # 绘制x轴的预测值与误差图 plt.scatter(y_pred, y_pred - y_test, c="blue", marker="o", label="Training data") plt.hlines(y=0, xmin=y_test.min(), xmax=y_test.max(), colors="red", lw=2) plt.xlabel("Predicted values") plt.ylabel("Residuals") plt.legend(loc="upper left") plt.title("Residual plot") plt.show() # 输出评估指标 print("Mean Squared Error: ", mse) print("Root Mean Squared Error: ", rmse) print("R-squared: ", r2)
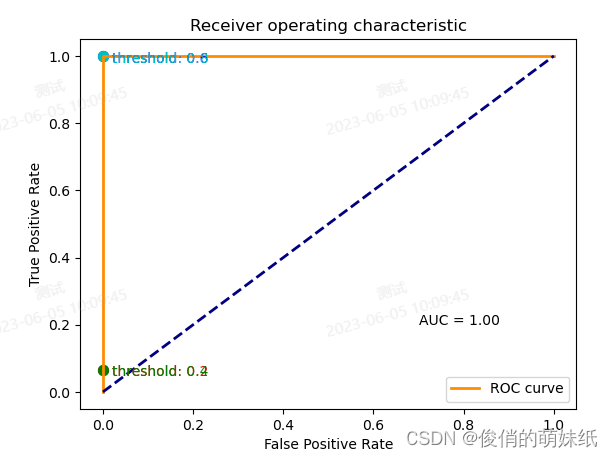
简介:评估模块支持计算准确率(accuracy),精确率(precision),召回率(recall),F1评分(F-score),confusion matrix。 准确率(Accuracy): 准确率指的是分类正确的样本数占总样本数的比例。 精确率(Precision): 精确率指的是被分类器正确分类为正例的样本数占分类器输出为正例的总样本数的比例。 召回率(Recall): 召回率指的是被分类器正确分类为正例的样本数占实际为正例的总样本数的比例。 F1分数(F1-Score): F1分数综合考虑了精确率和召回率,是精确率和召回率的调和平均数。 在ROC曲线中,AUC是一个常用的度量指标,表示模型正确分类正例的概率比负例高的程度。AUC越接近1,说明模型分类能力越强;AUC越接近0.5,说明模型对于正例和负例的判别能力差不多,相当于随机猜测;AUC小于0.5则说明模型分类错误的概率比瞎猜还要大。 举例说明:根据二分类来预测某个人是否患有某种疾病。 训练集:包含一组已知标记(即是否患病)的个体数据,以及与其相关的特征(如年龄、性别、体重等)。这些数据被用来训练模型学习患病和非患病之间的模式和特征。训练集中的每个样本都有一个已知的标签,即该人是否患病。 测试集:包含一组未标记的个体数据,同样包括与其相关的特征。这些数据被用来评估训练好的模型在新数据上的性能。测试集中的每个样本都没有标签,即我们不知道他们的真实状态(是否患病),我们的目标是使用模型对其进行预测,并与真实状态进行比较。 如果我们训练的模型具有高准确率、高精确率和高召回率,那么可以认为该模型在预测一个人是否患病方面表现良好,具有较高的准确性和能够较好地识别患病个体。相反,如果这些指标较低,那么模型的预测能力可能不够准确或者对患病个体的识别能力不强。 import matplotlib.pyplot as plt from sklearn.datasets import make_classification from sklearn.linear_model import LogisticRegression from sklearn.metrics import roc_curve, roc_auc_score from sklearn.model_selection import train_test_split # 生成二分类数据集 X, y = make_classification(n_samples=100, n_features=2, n_redundant=0, n_clusters_per_class=1, random_state=42) # 划分数据集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42) # 训练逻辑回归模型 model = LogisticRegression() model.fit(X_train, y_train) # 预测测试集 y_pred = model.predict(X_test) # 计算fpr和tpr y_score = model.decision_function(X_test) fpr, tpr, _ = roc_curve(y_test, y_score) # 绘制ROC曲线和散点图 plt.figure() plt.plot(fpr, tpr, color='darkorange', lw=2, label='ROC curve') plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--') plt.xlabel('False Positive Rate') plt.ylabel('True Positive Rate') plt.title('Receiver operating characteristic') plt.legend(loc="lower right") # 添加阈值散点图 thresholds = [0.2, 0.4, 0.6, 0.8] colors = ['r', 'g', 'b', 'c'] for i, color in zip(range(len(thresholds)), colors): # 找到最靠近threshold的fpr和tpr,并绘制散点图 closest_index = (abs(thresholds[i]-tpr)).argmin() closest_fpr = fpr[closest_index] closest_tpr = tpr[closest_index] plt.scatter(closest_fpr, closest_tpr, s=50, color=color) plt.annotate('threshold: {}'.format(thresholds[i]), xy=(closest_fpr+0.02, closest_tpr-0.02), color=color) # 显示AUC值 auc_score = roc_auc_score(y_test, y_score) plt.text(0.7, 0.2, 'AUC = {:.2f}'.format(auc_score)) plt.show()
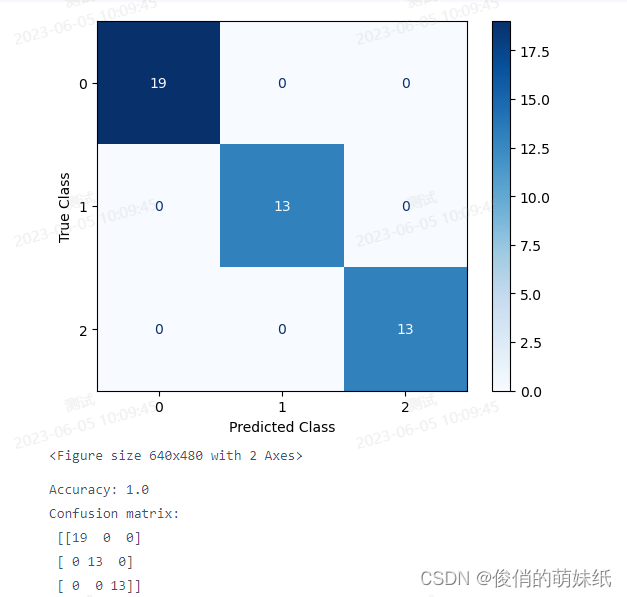
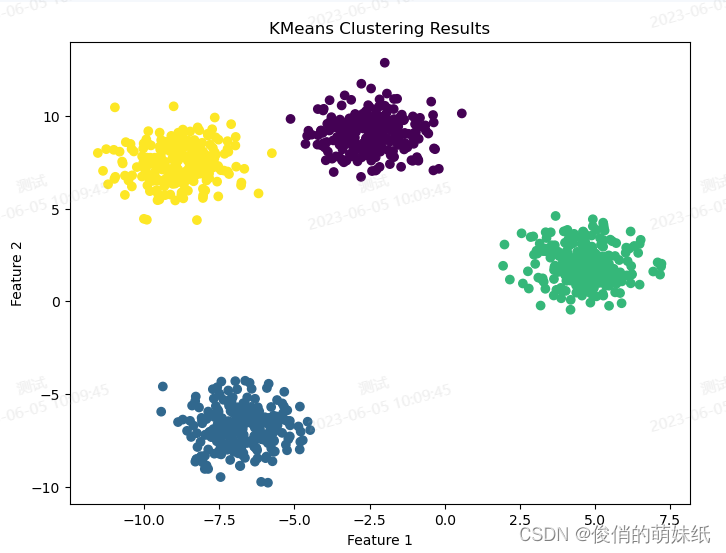
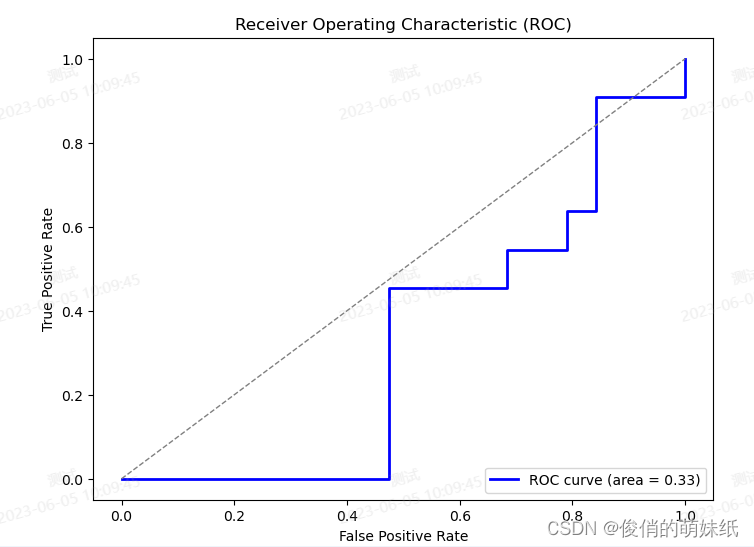
简介:评估模块支持计算准确率(accuracy),精确率(precision),召回率(recall),F1评分(F-score),confusion matrix。 举例说明:正在构建一个模型来识别图像中的动物种类,包括猫、狗和鸟。我们有一个训练集,其中包含标记为猫、狗或鸟的图像,并具有与每个图像相关联的特征。我们希望通过这些训练数据让模型学会区分不同的动物种类。接下来,我们使用这个训练集来训练多分类模型。模型会学习在给定图像的情况下,如何根据特征来预测图像所属的动物种类。训练完成后,我们将使用一个测试集来评估模型的性能。 测试集包含一组未标记的图像样本,我们不知道它们的真实类别是猫、狗还是鸟。我们的目标是使用模型对这些图像进行分类,并与它们的真实类别进行比较。通过评估上述指标,我们可以获得关于多分类模型性能的详细信息。准确率告诉我们模型整体的分类准确性,混淆矩阵提供了每个类别的分类结果,而精确率、召回率和 F1 分数则帮助我们了解模型在每个类别上的表现。 import numpy as np import matplotlib.pyplot as plt from sklearn.datasets import load_iris from sklearn.ensemble import RandomForestClassifier from sklearn.metrics import accuracy_score, confusion_matrix, plot_confusion_matrix from sklearn.model_selection import train_test_split # 加载数据集 data = load_iris() X = data.data y = data.target # 划分数据集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42) # 训练随机森林模型 model = RandomForestClassifier(n_estimators=100) model.fit(X_train, y_train) # 预测测试集 y_pred = model.predict(X_test) # 计算准确率和混淆矩阵 acc = accuracy_score(y_test, y_pred) cm = confusion_matrix(y_test, y_pred) # 绘制混淆矩阵图 plot_confusion_matrix(model, X_test, y_test, cmap=plt.cm.Blues) plt.xlabel('Predicted Class') plt.ylabel('True Class') plt.show() print('Accuracy:', acc) print('Confusion matrix:\n', cm) 简介:评估模块支持固定聚类个数的预测,以及计算展示区间聚类个数的肘部法则和轮廓系数。 举例说明:假如一家电商公司,要对用户进行分群,以便更好地进行个性化推荐和定向营销。我们收集了用户的购买历史数据,包括购买的产品类别、购买金额和购买频率等信息。然后我们使用聚类算法对这些用户进行分群,目的是找出具有相似购买行为的用户组。通过肘部法则和轮廓系数来得出准确结论。 # 导入必要的库 import matplotlib.pyplot as plt from sklearn.datasets import make_blobs from sklearn.cluster import KMeans # 生成随机数据集 X, y = make_blobs(n_samples=1000, centers=4, random_state=42) # 使用KMeans算法进行聚类 kmeans = KMeans(n_clusters=4, random_state=42) y_predict = kmeans.fit_predict(X) # 绘制散点图 plt.figure(figsize=(8, 6)) plt.scatter(X[:,0], X[:,1], c=y_predict, cmap='viridis') plt.title('KMeans Clustering Results') plt.xlabel('Feature 1') plt.ylabel('Feature 2') plt.show() 简介:训练集和验证集损失变化和准确率变化。 包括:DNN(深度神经网络)、CNN(卷积深度神经网络) 举例说明:DNN(深度神经网络)假设我们正在开发一个猫狗图像分类器,它可以将给定的图像分为两类:猫和狗。我们的DNN模型已经训练好,并且我们准备好了一组测试图像来评估模型的性能。我们使用测试数据集来评估我们的猫狗图像分类器,在测试集中有200张猫的图像和200张狗的图像,评估结果如下: 准确率:85%(分类正确的图像数量 / 总图像数量) 猫的精确率:90%(分类正确的猫的图像数量 / 预测为猫的图像数量) 猫的召回率:85%(分类正确的猫的图像数量 / 实际上是猫的图像数量) 狗的精确率:80%(分类正确的狗的图像数量 / 预测为狗的图像数量) 狗的召回率:85%(分类正确的狗的图像数量 / 实际上是狗的图像数量) F1值:87%(2 *(精确率 * 召回率)/(精确率 + 召回率)) 准确率、精确率、召回率、F1值越高,准确率越高。 举例说明:CNN(卷积深度神经网络)假如你是一个面包师傅,你想提高面包技术,收集了大量的面包图片作为数据集。图片上包含了各种类型的面包,比如法棍面包、土司面包和芝士面包等。接下来通过检测面包的特征,比如形状、边缘和纹理,进行CNN训练。一个CNN卷积层可能会检测到法棍面包的长条形状和略微弯曲的边缘,或者土司面包酥脆的外表和网状的纹理。最后通过,特征来判断面包的品质,例如,如果模型发现面包有均匀的酥皮和松软的内部,那么它可能会判断这是一款优质的面包。 CNN模型就像一个面包探测器,它通过卷积层和池化层来学习面包的特征,并通过全连接层来判断面包的品质。 # 导入必要的库 import numpy as np import pandas as pd import matplotlib.pyplot as plt from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split from sklearn.neural_network import MLPClassifier from sklearn.metrics import accuracy_score, confusion_matrix, classification_report, roc_curve, auc # 加载Iris数据集 iris = load_iris() X, y = iris.data, iris.target feature_names = iris.feature_names # 划分训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 定义MLP分类器模型 mlp = MLPClassifier(hidden_layer_sizes=(16, 16), max_iter=1000, random_state=42) # 模型训练和预测 mlp.fit(X_train, y_train) y_pred = mlp.predict(X_test) y_proba = mlp.predict_proba(X_test)[:,1] # 获取预测概率 # 计算准确率、FPR和TPR,并输出混淆矩阵和分类报告 accuracy = accuracy_score(y_test, y_pred) confusion_matrix = confusion_matrix(y_test, y_pred) classification_report = classification_report(y_test, y_pred, target_names=iris.target_names) fpr, tpr, thresholds = roc_curve(y_test, y_proba, pos_label=2) # 画出ROC曲线 roc_auc = auc(fpr, tpr) plt.figure(figsize=(8,6)) plt.plot(fpr, tpr, color='blue', lw=2, label='ROC curve (area = %0.2f)' % roc_auc) # 绘制ROC曲线 plt.plot([0, 1], [0, 1], color='grey', lw=1, linestyle='--') # 绘制随机猜测线 plt.xlabel('False Positive Rate') plt.ylabel('True Positive Rate') plt.title('Receiver Operating Characteristic (ROC)') plt.legend(loc="lower right") plt.show() # 输出混淆矩阵和分类报告 print("Accuracy:", accuracy) print("Confusion Matrix:\n", confusion_matrix) print("Classification Report:\n", classification_report)
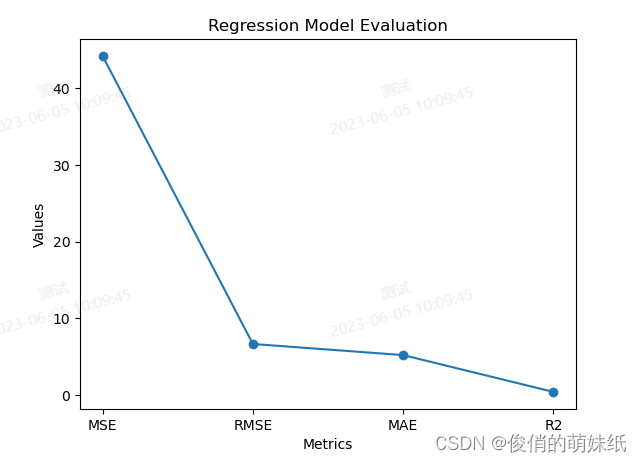
简介:训练集和验证集损失变化和准确率变化。 举例说明:设你是一名房地产经纪人,你的任务是根据房屋的大小、地理位置、卧室数量等特征来预测房屋的价格。首先,你会收集一个包含了多个房屋信息和对应价格的数据集。每个房屋都有一些特征值,比如房间数量、浴室数量、房屋面积、附近学校的评分等。而对应的价格就是你想要预测的目标值。接下来根据回归(DNN)进行训练。在训练过程中,模型将根据输入的特征值和对应的实际价格进行学习。它会不断调整神经元之间的连接权重,以使预测值越来越接近实际价格。 如果,RMSE较小,说明你的模型在预测房屋价格上表现较好,预测值与实际值之间的差异较小;如果RMSE较大,说明模型的预测不够准确,需要进一步优化。MSE/MAE的结果越接近0,说明模型的预测越准确。R2取值范围为0到1,越接近1表示模型对数据的拟合越好,接近0说明模型的拟合效果较差。 # 导入必要的库 import numpy as np import pandas as pd import matplotlib.pyplot as plt from sklearn.datasets import load_boston from sklearn.model_selection import train_test_split from sklearn.neural_network import MLPRegressor from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score # 加载Boston数据集 boston = load_boston() X, y = boston.data, boston.target feature_names = boston.feature_names # 划分训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 定义MLP回归器模型 mlp = MLPRegressor(hidden_layer_sizes=(16, 16), max_iter=1000, random_state=42) # 模型训练和预测 mlp.fit(X_train, y_train) y_pred = mlp.predict(X_test) # 计算均方误差、均方根误差、平均绝对误差和R平方 mse = mean_squared_error(y_test, y_pred) rmse = np.sqrt(mse) mae = mean_absolute_error(y_test, y_pred) r2 = r2_score(y_test, y_pred) # 生成曲线图 metrics = ['MSE', 'RMSE', 'MAE', 'R2'] values = [mse, rmse, mae, r2] plt.plot(metrics, values, marker='o') plt.title('Regression Model Evaluation') plt.xlabel('Metrics') plt.ylabel('Values') plt.show()
在机器学习中,我们需要评估模型的性能以确定其是否满足预期目标。这不仅有助于理解我们的模型在不同场景下的表现,还能指导我们对模型进行调整和优化。常用的评估指标包括准确率、精确度、召回率、F1分数等,也可以使用ROC曲线、AUC值等来评估二分类模型的性能。此外,通过混淆矩阵、误差分析、学习曲线、特征重要性分析、超参数调整等方法,我们还可以更深入地了解模型的性能和行为。综合使用这些评估方法,可以帮助我们更好地理解和优化机器学习模型的性能! |


【本文地址】
今日新闻 |
推荐新闻 |