对抗学习 |
您所在的位置:网站首页 › 数字防御 › 对抗学习 |
对抗学习
|
Adversarial Attacks and Defences: A Survey2022年的综述 Adversarial Attack and Defense: A Survey简介 近年来,深度神经网络(DNN)已广泛应用于计算机视觉[1,2,3],语音识别[4,5,6],NLP[7,8]]等诸多领域,并在工业界和学术界掀起了以深度神经网络为代表的人工智能浪潮。同时,深度学习技术与边缘计算的结合为智慧城市的发展提供了强劲动力。然而,深度神经网络的安全性尚未得到科学解释和处理。深度神经网络通过自身的结构和算法机制获得结果,在训练过程中依赖大量的外部数据。数据的特征决定了深度神经网络。判断结果。因此,攻击者可以通过修改数据来攻击深度神经网络。如图1所示对原始图像添加细微的扰动后,人眼无法察觉图像的变化,但一旦输入到神经网络模型中,就会严重影响其识别性能。  图1. 对抗性样本生成过程,通过对( a )原始样本添加( b )扰动,可以获得 ( c )对抗性样本。 图1. 对抗性样本生成过程,通过对( a )原始样本添加( b )扰动,可以获得 ( c )对抗性样本。塞格迪等人。[9]首次提出深度神经网络模型在图像分类任务中的脆弱性。对原始图像添加扰动后生成的对抗样本肉眼无法区分,但深度神经网络可以高置信度地输出错误结果。网络的识别性能受到严重影响。如图2所示,在原始示例中添加对抗性扰动形成对抗性示例后,目标模型将“猫”错误地识别为“狗”,而人眼无法检测到原始示例与对抗性示例之间的差异。白盒攻击可以获得模型的结构信息,而黑盒攻击只能通过将原始数据输入到目标模型来获得目标模型的输出。攻击策略将与实际的攻击方法一起介绍。随着对抗样本的引入,研究人员开始关注对抗样本的生成和防御方法,并取得了突破性的成果。本文将讨论近年来计算机视觉中的对抗性示例生成和防御方法。现在,已经有一些关于图像领域对策实例的评论。与之前的调查相比,我们对对策攻击进行了总结和分析,并重点关注其生成原理。同时,本文从模型优化、数据优化和附加网络三个方面对防御技术进行了分析,以期为该领域的研究人员提供相关参考。  图 2. 对抗性示例生成和对抗性攻击过程。对抗攻击 图 2. 对抗性示例生成和对抗性攻击过程。对抗攻击在本节中,我们首先介绍对抗性攻击的特征和分类,然后根据汇总结果分析典型的对抗性攻击方法。 2.1. 常用术语对抗性攻击就是通过对抗性例子来攻击神经网络。根据对抗性攻击的特点和攻击效果,对抗性攻击可分为黑盒攻击和白盒攻击、单步攻击和迭代攻击、目标攻击和非目标攻击、特定扰动和通用扰动等。等,术语介绍如下: 黑盒攻击:攻击者无法访问深度神经网络模型,从而无法获取模型结构和参数,只能通过将原始数据输入到目标模型中来获取目标模型的输出结果,并根据结果来想方设法进行攻击。 白盒攻击:攻击者可以获得目标模型的完整结构和参数,包括训练数据、梯度信息和激活函数等。 单步攻击:对抗性攻击算法只需进行一次计算即可获得攻击成功率较高的对抗性样本。 迭代攻击:对抗性攻击算法需要运行多次才能生成对抗性示例。与一次性攻击相比,迭代攻击需要更长的运行时间,但攻击效果更好。 目标攻击:攻击者设计的对抗样本输入目标模型后,目标分类器可能误判指定的分类结果,例如希望模型必须将类别3误判为类别5,则为典型的目标攻击。 非针对性攻击:对抗性例子只需要目标分类器的误判,不限制分类结果,即类别3无论误判为类别几都可以,只要不是正确预测就可以了。 特定扰动:对每个输入的原始数据添加不同的扰动,形成不同的扰动模式。 通用扰动:对每个输入的原始数据添加相同的扰动,其扰动模式相同。 2.2. 对抗性攻击目前,学术界对于对抗性例子的生成原理尚未达成统一的结论。塞格迪等人。[ 9 ]认为真实数据中存在对抗性例子,但出现的概率较低,这使得模型很难学习对抗性例子。因此,当测试集中出现对抗性样本后,分类器很难正确识别对抗性样本。虽然古德费洛等人。[ 10】认为神经网络的脆弱性是由于模型的高维线性特征,当模型使用Relu或Maxout等线性激活函数时,更容易受到对抗性例子的影响。尽管对抗性实例的生成原理尚未得到科学解释,但近年来,研究人员通过探索对抗性实例生成算法,为提高深度神经网络的安全性提供了理论和实践基础。如表1所示,本文从攻击类型、攻击目标、攻击频率、扰动类型、扰动范数、攻击策略等方面对当前典型的对抗样本生成方法进行了总结和分析。  对抗攻击的方法 对抗攻击的方法通过对抗攻击,我们产生的使得模型发生误判的样本叫做对抗样本,对抗样本一般是原始数据集的小幅度扰动产生的. L-BFGS塞格迪等人。[9]提出,在探索深度学习的可解释工作时,对对特定扰动的脆弱性会导致模型识别结果的严重偏差。他们提出了第一个深度学习的抗攻击算法L-BFGS:  其中 表示大于 0 的常数, ′表示通过添加扰动形成的对抗性样本, 表示当前样本,J 表示损失函数。算法受到参数选择的限制,所以需要选择合适的 来解决约束优化问题。L-BFGS 凭借其可迁移性,可以用于在不同数据集上训练的模型。该方法的提出掀起了学者们对对抗性例子的研究热潮。 FGSM古德费洛等人。[10]提出了快速梯度符号法(FGSM)算法来证明对抗样本的存在是由深度神经网络的高维线性引起的。算法原理是根据深度学习模型梯度变化的最大方向生成对抗扰动,并将扰动添加到图像中生成对抗样本。FGSM产生扰动的公式如下:  其中 代表产生的扰动; 和 分别是模型的参数和模型的输入; 表示对应的标签,J 是模型训练时的损失函数。 表示一个常数,用于控制扰动幅度,当 为 0.25,FGSM 对于浅层 softmax 分类器在 MNIST 数据集上的分类可以导致错误率为 99.9%,平均置信率为 79.3%。 FGSM算法的优点是攻击速度快,因为该算法属于单步攻击,但有时单步攻击生成的对抗样本的攻击成功率较低。因此,Kurakin 等人。[25]提出了一种基于迭代的FGSM(I-FGSM)。I-FGSM的主要创新点是通过在多个小step中增加损失函数来产生扰动,从而可以获得更多的对抗性样本。 JSMA帕佩诺特等人。[11]提出了基于雅可比的显着图攻击(JSMA)。JSMA没有利用模型输出的损失函数的梯度信息,而是利用模型输出类别的概率信息进行反向传播来获取梯度信息,然后构建对抗性显着性图来达到攻击的目的。深度学习模型对输入样本的x的前向梯度计算为:  通过前向梯度可以得到每个像素点对模型分类的影响程度。然后,为了量化像素值的变化对目标分类器的影响,JSMA提出了基于雅可比矩阵的对抗显着性图的构建,如下所示:  C&W C&W针对学者提出的攻击方法,Papernot等人。[26]提出了防御性蒸馏,它利用蒸馏算法[27]将复杂网络的知识转移到简单网络,使攻击者无法直接联系原始模型进行攻击,防御性蒸馏有效地防御了一些对抗性示例。对于防御性蒸馏,Carlini 等人提出了通过l0,l2,l无穷大 约束进行C&W攻击,防御蒸馏无法防御C&W攻击,C&W攻击的一般扰动约束如下:  其中 D 代表约束范式,例如 0, 2, ∞ 约束生成过程中改变的干净示例点的数量,l2约束整体扰动程度,l无穷大约束每个像素允许的最大扰动, 表示超参数,并且F采用多种目标函数。通过在 MINIST 和 CIFAR 数据集上进行实验,C&W 实现了对蒸馏网络的攻击,成功率为 100%,并且 C&W 可以通过调整参数生成高置信度的对抗样本。 one pixel attack苏等人。[13]提出了一种攻击方法单像素攻击(OPA),只需要改变一个像素就可以生成对抗性例子。该方法利用差分进化算法寻找对抗性扰动,然后改变一个或少量像素导致模型误分类,OPA攻击公式如下:  其中 d= 1,表示网络只改变模型的一个像素。作者利用差分进化算法来获得攻击效果的最优对抗性扰动。对于n维图像 =( ,⋯, ),改变一个像素引起的扰动实际上是沿着平行于n维的方向。数据点的干扰是在一个方向上进行的。每个扰动都是一个5元组,包括x坐标、y坐标和RGB值。计算公式如下:  其中 表示候选解,r1,r2,r3是随机数,F表示尺度参数,设置为0.5, 是当前的迭代次数。每次迭代后,如果候选解得到的结果超过父结果,则候选解继续下一次迭代,否则父结果继续下一次迭代,直到获得最佳攻击结果或达到最大迭代次数. DeepFool穆萨维-德兹富利等人。提出了一种基于梯度迭代的DeepFool方法来生成对抗性扰动。DeepFool首先通过计算得到扰动,然后通过不断迭代的像素调整将正常样本推向决策边界,直到跨越决策边界后得到对抗样本。以二元分类为例,假设分类函数为  对应的仿射平面为  最小扰动 影响原样本的分类结果 0由分类函数等于正交投影 0到 ,计算公式为 如下:  上述目标函数解决了最小对抗扰动 迭代计算,计算公式如下:  DeepFool通过计算正常示例和对抗性示例的决策边界之间的最小距离来衡量示例的鲁棒性。同时,与对FGSM的单步攻击相比,DeepFool可以在更短的时间内产生更准确的扰动,但Deepfool只能实现无针对性的攻击。 ZOO与现有的一些基于代理模型的黑盒攻击方法不同,Chen等人。[15]提出了零阶优化(ZOO),它没有利用代理模型的攻击可传递性,而是估计一阶梯度和二阶梯度的值,然后使用 Adma 或 Newton 方法迭代以获得最佳对抗性示例,并向给定输入添加扰动  其中h是一个常数,ei表示第i个位置为1、其余为0的向量。一阶估计梯度值计算如下  二阶估计梯度计算如下:  陈等人。通过在MNIST和CIFAR10数据集上的实验验证,ZOO攻击可以获得较高的攻击成功率,但与白盒攻击C&W相比,ZOO攻击需要更多的时间。 UAP穆萨维-德兹富利等人。[16]基于DeepFool提出了一种通用对抗性扰动攻击(UAP),同样利用对抗性扰动将正常样本推向决策边界,形成对抗性样本。它的定义如下:  一般对抗性扰动满足 以下限制:  其中k(x)表示分类函数, 参数用于控制对抗性扰动的强度 , 用于控制对原始示例的攻击成功率。在UAP的迭代过程中,通过DeepFool算法获得每个实例的最小扰动并不断更新。直到生成最佳对抗样本。UAP攻击达到将本地产生的对抗性扰动移植到目标网络进行攻击的目的。尽管 Moosavi-Dezfooli 等人仅在ResNet上进行了实验来验证一般扰动的有效性,但UAP攻击已成功推广到其他神经网络。 advGAN肖等人。文献[17]提出了一种基于生成对抗网络的对抗攻击方法advGAN,主要由生成器组成G, 判别器D,和目标网络模型C 。AdvGAN 首先输入原始示例 进入生成器以生成对抗性扰动g( )然后输入 +g( )分别给判别器和目标模型。一方面,判别器D用于识别示例的类别。AdvGAN的目标函数如下所示:  目标函数分为三部分,其中Ladv是判别损失,目的是引导生成器生成最好的对抗性扰动,公式如下  AdvGAN 生成的对抗性扰动可能会引导模型将其错误分类为类别t L 表示对抗性损失,即GoodFellow提出的原始损失函数。公式如下:  该损失函数的目标是优化生成器G和判别器D。经过训练和优化后,生成器G可以产生最好的对抗性扰动g(x)和判别器D还可以有效地识别对抗性示例,对于稳定GAN的训练,公式如下:  超参数 表示优化距离,advGAN在MNIST数据集上进行黑盒攻击实验,取得了92.76%的成功率。 ATNs巴卢贾等人提出了基于生成模型的对抗性转换网络(ATN)。ATNs 输入是原始示例,对抗性示例是通过训练前馈神经网络生成的。一方面满足最小扰动并保持对抗性例子与原始例子的相似性,另一方面满足对抗性攻击的成功率。因此,目标函数如下:  其中 G function代表需要训练的生成模型。输入原始样本后,输出对抗样本,F(xi)表示被攻击的目标模型,其中Lx和Ly分别表示输入空间和输出空间的损失函数。前者用于约束对抗性示例与原始示例之间的差异。类似,后者是用来约束对抗性攻击的成功率的。 UPSET and ANGRI萨卡等人。[19]提出了两种黑盒攻击方法,UPSET和ANGRI,前者生成目标类的通用扰动,后者生成图像特定的扰动。UPSET 产生对抗性扰动 by residual generation network,假如说 是选定的目标类别,扰动表示为 =R( )对抗样本生成公式如下:  其中R代表 UPSET 网络,并且s是用于调整扰动的大小。UPSET网络的损失函数由两部分组成,如下:  其中Lc惩罚无法生成目标攻击类别,并且Lf用于确保对抗性示例与原始示例之间的相似性。与UPSRT相比,ANGRI联合At和Ax获得Ac,然后生成对抗性例子X',由于ANGRI可以获得输入图像,因此它可以生成更好的对抗性图像,即使当分类器用噪声图像进行训练时,ANGRI仍然可以生成更好的对抗性示例。 Houdini西塞等人。[20]提出了Houdini算法,该算法可以为模型执行的任务的最终性能测量生成对抗示例,用于解决一些无法通过梯度下降生成对抗示例的组合和不可分解的问题,例如语音识别和语义分割。Houdini网络的损失函数如下:  其中gtheta 表示带有参数的目标神经网络,  表示实际得分与预测得分之间的差异,并且L是原始损失函数。此外,西塞等人。将Houdini网络应用于语音识别、语言分割和姿态估计,取得了良好的性能。 BPDA为了验证基于梯度混淆的防御是否存在缺陷,Athalye 等人]提出了后向传递可微近似(BPDA)。当给定预训练分类器时,预处理器g(x)被构建出来,满足g(x)约等于x,导数可近似为  BPDA通过上述方程可以有效克服基于梯度混淆的防御,并获取梯度的近似值,然后通过多次迭代的平均值生成反例。作者基于 ICLR2018 上提出的混杂梯度,对 7 种防御模型进行了 BPDA 攻击。BPDA完全避开了6次防守,部分避开了1次防守。BPDA算法证明基于梯度混淆的防御方法具有特定且明显的缺陷。 DaST在现实世界的任务中,预训练的模型很难获得。在本文中,周等人提出了无数据替代训练方法(DaST),无需任何真实数据即可获得对抗性黑盒攻击的替代模型。为了实现这一目标,DaST 利用专门设计的生成对抗网络 (GAN) 来训练替代模型。特别是,我们为生成模型设计了多分支架构和标签控制损失,以处理合成示例的不均匀分布。然后使用生成模型生成的合成示例来训练替代模型,然后用受攻击模型进行标记。替代模型的任务是模仿目标模型的输出。这是一场二人游戏,目标模型可以被视为裁判。这个游戏的损失函数可以写成:  表示衡量替代模型之间输出距离的度量D和目标模型T。更新生成模型  其中L L代表标签控制损失, 用于控制L L的权重。 DaST 是第一个无需任何真实数据即可训练对抗性攻击的替代模型。攻击者可以使用这种方法来训练对抗性攻击的替代模型,而无需收集任何真实数据。周等人。攻击了 Microsoft Azure 上的在线机器学习模型。使用他们的方法,远程模型错误分类了 98.35% 的对抗样本。 GAP++与仅依赖输入图像来生成对抗性扰动的算法相比,Mao 等人。[23]受之前工作[28]的启发,提出了一种基于GAP的新颖的通用框架GAP++[29]],它可以根据输入图像和目标标签条件扰动来推断目标。与以往的单目标攻击模型不同,该模型通过学习攻击目标与图像语义之间的关系来进行目标条件攻击。GAP++ 仅使用一种经过训练的模型即可生成所有类型的目标扰动。在GAP++的架构中,每个输入图像都需要相应的目标标签作为条件信息。然而,在非目标的情况下,没有条件目标标签。因此,使用零向量进行脱靶训练,因为它不会通过在模型中连接零张量来影响内部表示的学习。在 MNIST 和 CIFAR10 数据集上的大量实验表明,该方法在单目标攻击模型下取得了更好的性能,在小扰动范数下取得了更高的欺骗率。虽然GAP++借用了原始GAP的网络架构和归一化技巧,但它的性能比GAP轻,因此可以用于许多攻击任务。 CG-ES标准进化策略(ES)算法可以执行黑盒攻击,其中广泛采用高斯分布作为搜索分布。然而,它可能不够灵活,无法捕获不同良性示例周围的对抗性扰动的不同分布。冯等人。[24]基于条件发光模型和高斯分布,提出了一种新的分布搜索进化策略方法(CG-ES)来解决分数黑盒攻击问题。CG-ES通过基于条件流的模型将高斯分布变量转换到另一个空间,以增强捕获良性示例上对抗性扰动的固有分布的能力和灵活性。此外,冯等人。建议预训练 c-Glow [30] 模型通过将基于能量的模型近似为替代模型的扰动分布。然后在ES中将预训练的c-Glow模型初始化为攻击目标模型。因此,所提出的CG-ES方法同时利用了基于查询和基于传输的攻击方法,并实现了更高的攻击成功率和更高的攻击效率。 对抗性攻击比较L-BFGS是一种早期的对抗性攻击算法,它启发了其他攻击算法。L-BFGS生成的对抗样本具有良好的可迁移性,可以应用于多种不同类型的神经网络结构。 JSMA虽然具有较高的攻击成功率,但由于其攻击依赖于输入样本的雅可比矩阵,而不同样本的雅可比矩阵差异较大,因此JSMA不具备可迁移性。 FGSM仅需一次迭代即可获得对抗性扰动,因此攻击效率较高,但攻击成功率不如PGD等迭代攻击算法。 与FGSM、JSMA等攻击相比,DeepFool攻击产生的对抗性扰动相对较小,但DeepFool不具备定向攻击的能力。UAP基于DeepFool的思想,实现了更好的泛化能力,实现了跨模型、跨数据集的通用攻击能力,为真实场景的攻击需求提供技术支撑。 One-Pixel通过修改单个像素来达到攻击的目的。与其他算法相比,生成的对抗样本更具欺骗性,但需要多轮迭代才能找到最优解,因此攻击效率较低。 C&W攻击具有很强的攻击性。与L-BFGS、FGSM、DeepFool等攻击方式相比,C&W可以成功攻破防御蒸馏的防御,但牺牲了攻击效率。 UPSET和ANGRI是同时提出的,但UPSET不依赖于输入数据的属性,可以实现通用攻击。后者无法实现一般攻击,因为它依赖于训练时输入数据的属性。 AdvGAN、DaST和GAP++在攻击过程中都使用了生成对抗网络。,形成的对抗样本具有很强的攻击效果,因为生成器和判别器的博弈过程生成的对抗样本与原始样本高度相似。 对抗防御我们从模型优化、数据优化和附加网络三个方向分析对抗性示例防御。如下图所示,每个研究方向都有几种具体技术。本节通过一些典型算法介绍不同方向的防御技术。  模型优化difensive distillation 模型优化difensive distillation蒸馏法最早由 Hiton 等人提出。[27],它基于知识迁移的思想,将复杂网络迁移到简单网络。为了防御对抗性攻击,Papernot 等人。[26]提出了一种防御性蒸馏技术。首先,使用蒸馏算法为原始模型训练蒸馏模型。此时的输入是原来的输入样例和标签得到概率分布,然后利用输入样例和概率分布训练一个架构相同的蒸馏模型得到新的概率分布。此时,概率分布是新标签,温度T是超参数。当使用整个蒸馏网络进行分类任务时,可以有效防御对抗性攻击。 gradient regularization阿德帕利等人。[ 31 ]提出了一种新颖的位平面特征一致性(BPFC)正则化器,它通过使用正常的训练机制来提高模型的对抗鲁棒性。根据较高位平面中的信息形成粗略印象,并仅使用较低位平面来完善其预测。实验表明,通过对不同量化图像中学习到的表示施加一致性,与正常训练的模型相比,深度神经网络的对抗鲁棒性得到了显着提高。该方法并不是由于梯度掩蔽实现的鲁棒性,而是由于 BPFC 正则器改进的局部特性,从而产生更好的对抗鲁棒性。 对抗性训练需要额外的足够数据以确保模型足够稳健。马等人。[ 32 ]提出二阶对抗性正则化器(SOAR)来代替对抗性训练。为了导出正则化器,Ma 等人。给出了鲁棒优化框架下的对抗鲁棒性问题,用损失函数wrt的二阶泰勒级数逼近SOAR输入,并近似求解了鲁棒优化公式的内部最大化。对 CIFAR-10 和 SVHN 数据集的大量实验表明,SOAR 显着提高了网络的鲁棒性基于交叉熵的 PGD 生成的有界扰动。 gradient masking为了防止攻击者通过梯度信息攻击模型,Folz 等人。[34]提出了一种S2SNet屏蔽模型梯度的防御方法。S2SNet首先将类别相关信息转换为结构信息以影响梯度中的信息,然后对分类任务所需的结构部分进行编码,丢弃其他部分以消除对抗性扰动。S2SNet 通过编码器和解码器的无监督训练来保留结构信息。因此,得到的解码器将注意力转向与分类任务高度相关的特征信息,然后使用目标模型的梯度来微调解码器。在整个训练过程中,梯度中不涉及类相关信息,因此基于梯度的对抗样本无法攻击模型。 image denoising对抗性实例的生成是通过在原始实例中添加特定噪声来生成的,可以通过图像去噪来抵抗对抗性实例的攻击,但普通去噪器存在残差放大效应问题,导致模型输出错误结果。因此,廖等人。[35]提出了一种高层表示引导降噪器(HGD),它使用U-Net网络作为去噪网络,并在高层网络的特征中加入损失函数,从而抑制误差的放大, HGD损失函数如下:  什么时候 我 我 为-2,为FGD,表示倒数第二层的卷积特征图之间的差异;什么时候 我 我 -1是LGD,表示最后一层的卷积特征图之间的差异。由于FGD和LGD不需要样本的标签信息,因此属于无监督学习。与前两者不同的是,CGD需要示例标签信息,并要求CNN模型预测结果并与标签进行比较。HGD模型通过去噪可以显着防御针对实例的攻击,并荣获NIPS2017攻防大赛防御项目冠军。 随机网络王等人。[ 36 ]提供了一种新的解决方案,通过防御性dropout来强化对抗性攻击下的DNN。Dropout是一种常见的调优方法,用于处理训练数据有限引起的过拟合问题。作为一种调整方法,除了在训练期间使用 dropout 以获得最佳测试精度之外,Wang 等人。测试时也使用dropout来获得较强的防御效果。防御性丢失算法根据神经网络模型和攻击者生成对抗性示例的策略确定最佳测试丢失率。 王等人。[ 37]提出了防御效率评分(DES)来评估不同防御系统的鲁棒性-准确性权衡。为了实现 DES,Wang 等人。提出了分层随机切换(HRS),它通过一种新颖的随机化方案来保护神经网络。HRS保护网络由随机切换块链组成。每个块包含一组具有不同权重的并行通道,以及一个随机开关,用于控制在接收到块的输入时激活哪个通道。在运行时,输入仅通过每个块的激活通道传播,并且激活通道不断切换。HRS-protect 模型中的每个激活路径都具有分散随机化的特点,以提高鲁棒性,此外,与使用多个不同网络的集成防御相比,HRS只需要单一的底层网络架构来进行防御。与防御性dropout相比,在MNIST和CIFAR-10上的实验表明,HRS以最小的测试精度为代价取得了更好的防御效果。 刘等人。[ 38]提出了通过在神经网络中添加随机噪声层的随机自集成(RSE)防御方法。将输入向量与随机噪声融合得到的噪声层插入到神经网络的卷积层之前。因此,在训练过程中,梯度在反向传播计算时会受到噪声层的干扰。在推理阶段,每次前向传播,由于噪声层的存在,都会得到不同的预测结果,然后将结果集成可以有效抵抗对抗性攻击。以CIFAR-10数据和VGG网络为例,以往最好的防御技术使得模型在受到C&W攻击时的分类准确率达到48%。然而,在 RSE 防御的情况下,模型的预测准确率为 86.1%。此外, 数据优化对抗性训练大名鼎鼎的对抗性训练原来在这里。 对抗训练就是在训练集中添加对抗样本,模型训练时可以学习到对抗样本的特征分布,从而增加模型的鲁棒性。目前,对抗训练作为对抗样本的主要防御方法之一,缺乏大规模数据集上的研究成果,ImageNet上的各种防御措施都会被特定的白盒攻击所攻破。因此,Kannan 等人。[ 39 ]介绍了一种基于PGD对抗训练的logit配对策略[ 33]]提出混合小批量PGD(M-PGD)对抗训练方法。M-PGD在对抗训练中加入了干净的例子,logit配对策略包括两种配对方法,一种是将干净的例子与对抗性的例子配对,另一种是将干净的例子与另一个干净的例子配对。作者在ImageNet数据集上验证了对抗性logit配对策略具有一定的抵抗白盒和黑盒攻击的能力。此时,综合对抗训练的防御几乎失败,其准确率仅为1.3%,而M-PGD在白盒攻击和黑盒攻击下的准确率分别为27.9%和47.1%。 针对深度神经网络容易受到物理攻击的问题,Wu等人。[ 40 ]基于人脸识别上的眼镜框攻击和停车标志上的贴纸攻击,验证了PGD对抗训练[ 33 ]和随机平滑在两种场景中的鲁棒性有限。因此,他们设计了一种新颖的遮挡攻击防御(DOA)对抗训练防御方法。首先,提出了一种抽象的对抗模型,矩形遮挡攻击(ROA)。与传统相比 基于模型,ROA可以更好地实施物理攻击。ROA用于在图像上放置矩形贴纸来实现攻击。最后,使用对抗性例子进行对抗性训练。人脸识别中的对抗性眼镜和停车标志上的对抗性贴纸实验证明,DOA对抗训练模型对深度神经网络的物理攻击具有很强的鲁棒性。 特征压缩对抗样本与原始图像之间的扰动非常小,但在图像分类模型的高维空间中被放大。贾等人。[ 41]提出了一种基于图像压缩的对抗性实例防御方法ComDefend,以消除图像的冗余扰动。ComDefend由压缩卷积神经网络(ComCNN)和重建卷积神经网络(RecCNN)组成,其中ComCNN将输入图像的24位像素压缩为12位,以获得原始图像的压缩表示,该表示可以保留原始图像的主要信息足够多。然后将压缩后的表示输入到ResCNN,ResCNN重建干净的原始图像,并且ResCNN在重建过程中添加高斯噪声以提高抵抗对抗样本的能力。与HGD等方法相比,ComDefend不需要对抗性样本,从而降低了计算成本 输入重建为了抵御对抗性例子的攻击,Guo等人提出通过使用五种图像变化来消除图像扰动,包括图像裁剪和重新缩放、图像深度降低、JPEG压缩、总方差最小化和图像绗缝,并最大限度地保留有效图像信息。普拉卡什等人。文献[ 43 ]提出了一种基于像素偏转的像素值重新分配方法来局部破坏图像,并利用小波去噪技术来减少像素偏移带来的破坏和对抗性扰动,干净样本的分类结果不受影响,而对抗性样本的分类结果不受影响。样例经过像素偏转后能够正确分类,达到消除扰动的目的。 萨曼古埃等人。[ 44 ]在WGAN[ 45 ]的基础上提出了一种对抗性示例防御方法Defense-GAN。首先,使用随机噪声生成器生成多个随机噪声向量,然后将随机噪声向量与原始样本一起输入到生成器。当随机噪声拟合干净样本的分布时,对抗网络中的训练结束,以噪声数量作为循环变量重复上述训练过程,然后选择性能最好的图像进行分类任务。金等人。[ 46]提出了一种APE-GAN防御策略,同样使用生成器来重建样本,但APE-GAN将对抗样本和干净样本分别输入到生成器和判别器进行训练,从而消除对抗扰动。 附加网络对抗性样本检测科恩等人。[ 47]提出了一种将影响函数与基于 KNN 的度量相结合的对抗性攻击检测方法。该方法可以应用于任何预训练的神经网络,通过使用影响函数测量每个训练示例对验证集数据的影响,确定训练集中的数据点如何影响给定测试示例的网络决策。影响函数衡量模型损失函数中特定训练点的小权重对测试点损失的影响,提供了每个训练示例对测试示例的分类影响程度的度量。同时,使用KNN来搜索这些支持训练样例在DNN嵌入空间中的排名。可以看出,这些例子与正常输入的最近邻高度相关, 孟等人。[ 48]认为对抗性例子的属性不应该从特定的生成过程中发现,而是通过寻找所有对抗性例子的生成过程中内在的共同属性来增强防御方法的泛化能力。因此,孟等人。提出了一种独立于攻击的防御框架 MagNet,该框架既不依赖于对抗性示例及其生成过程,也不修改原始模型,而仅利用输入数据的特征。MagNet由探测器和重组器组成。基于深度学习的流行假设,对抗样本位于远离流行边界或流行边界的位置。检测器的作用是检测远离流行边界的对抗性例子,并拒绝对它们进行分类,然后通过重构来重构它们。分类器将接近流行边界的样本重构为原始样本进行分类。 先前的对抗性示例检测研究表明,输入示例及其邻居在特征空间中表现出显着的一致性。基于此,Abusnaina 等人。[ 49]提出了潜在邻域图(LNG)来表征输入的邻域。在本文中,对抗性示例检测问题转化为图分类问题。首先,为每个输入示例生成潜在邻域图,然后使用图神经网络(GNN)通过邻域图中节点之间的关系来区分良性示例和对抗性示例。给定输入示例,选择的参考对抗性示例和良性示例用于捕获输入示例附近的局部流形。LNG节点连接参数和图注网络参数以端到端的方式联合优化,以确定对抗性示例检测的最佳图拓扑。 崔等人。[ 50 ]通过实验验证,GAN生成的恶意PowerShell文件很难被传统的人工智能算法检测到,因此他们提出了一种基于注意力的过滤方法来检测恶意PowerShell。该方法首先使用注意力机制从PowerShell训练数据生成恶意令牌列表,然后通过恶意令牌列表从假PowerShell数据生成真实的PowerShell数据。实验验证基于注意力过滤恢复的PowerShell数据检测率为96.5% 综合防御为了验证是否可以通过整合多个弱防御来构建强大的对抗防御能力,He等人。[ 51 ]研究了三种集成防御方法,包括特征压缩、专家+1和集成检测机制。为了增加实验的可信度,He 等人。假设攻击者完全了解模型的架构、参数和防御策略,通过在 MNIST 和 CIFAR-10 两个数据集上进行验证,当使用自适应攻击来评估这些防御时,攻击者能够击败上述 3 种综合防御低失真。因此,他等人。提出在进行对抗性防御研究时,应该使用稳健的攻击来评估防御能力。 余等人。[ 52]提出了一种新颖的AuxBlocks模型防御方法,通过引入多个类似于自集成模型的AuxBlocks模型来扩展原始模型。于等人。将模型分为两部分:公共模型和私有模型,其中公共模型代表原始模型,私有模型是引入的几个辅助模型。公共模型可以暴露给攻击者,而私有模型对于攻击者来说是私有的,使得攻击者无法生成有效的对抗性示例。AuxBlocks 被设置为微型神经网络,也可以是任何其他结构。于等人。通过实验验证,在神经网络中引入AuxBlocks可以有效提高模型的鲁棒性。即使响应自适应白盒攻击, 模型的鲁棒性和泛化性能的关系模型上线之后,常常面临线上的表现比线下训练的时候表现差的情况,在提高模型的泛化性能的时候,我们常常问自己,模型在给定的数据/任务上的表现如何?为什么表现变差了? 这类问题也是比较常见研究的更多的,我们一般会分析模型是否过拟合到训练数据上,线上的数据是否发生了data shift问题, 而在对抗鲁棒性中,我们则是问“如果数据集或模型可以经历不同的可量化级别的变化,模型的表现是否会发生显著的变化 ”,这个过程通常涉及到我们需要预先定义一些“变化”从而对模型以进行稳健性评估和改进,这是对抗性机器学习的关键要素。 在对抗学习中,“变化”的定义是非常谨慎的,即认为变化应该是很小幅度,不易察觉的,因为一旦数据的变化很大,则本身已经超越了对抗学习的初衷和目的了,例如数据分布的偏移本身带来的例如特征分布的变化是很显著的,这不属于对抗学习研究和想要解决的问题。 模型的泛化性能的评估,主要考察的是模型对未知数据的预测能力,而模型的鲁棒性能的评估,主要考察的是模型对于输入的小幅扰动是否敏感,这个问题和过拟合的问题的一些解决方案是类似,我个人是一直把对抗训练当作一种特殊的数据增强的方式来看待的,对抗样本的产生可以看作一种fake hard sample mining的方法,之所以说是fake的,是因为按照目前看过的paper来说,通过各种攻击方法产生的对抗样本大概率都不是真实存在于原始数据集中的样本,之所以是hard的,是因为对抗训练被定义为一个min-max问题,即生成能够让model产生最大loss的hard sample的同时又让model最小化在这些对抗样本上的loss: 具体的,给定原始样本x,对抗攻击旨在找到一个对抗性样本x_adv = x+delta,delta应该尽量“小而致命”,小,即对抗样本和原始样本之间的差异很小,这样不容易改变原始样本x的语义,致命则指能够给模型产生相对大的loss。 这是个很有意思的问题,尤其对于高对抗强度的反欺诈场景而言是很适合的,fraudster 一旦被新模型catch,则会想方设法绕过模型的检测,即evation attack(下文有详细描述),从model的角度而言,fraudster的检测绕过带来的结果就是fraudster的features的变化,考虑到fraudster要做evastion attack也是有成本的,例如某些特定品牌的手机的牌子一旦作为model比较focus的信息,那么fraudster要躲避检测则意味着需要更换新的手机品牌,这样成本就比较高了,更多时候,fraudster会通过一些成本比较低的方法来进行大量的尝试从而绕过模型的检测,具体表现就是features的微小变动导致model的预测结果发生相对显著的变化。 (这里的基础假设是,fraudster要大幅度改变自己的features则需要比较高的成本来绕过检测,而通过小成本来小幅度变化自己的features如果就能够绕过检测显然是prefer的,当然实际的业务场景不一定符合这样的假设,例如fraudster可能花很少的effort就能让features产生很大的变化,那么对抗学习可能就派不上用场,或者fraudster需要花费很高昂的成本才能在features上发生很小的变化,那么对抗学习可能也不太需要使用) 为什么我们需要了解对抗学习?1.对抗学习,提供了一个新的视角来对模型的有效性进行评估,我们以往评估一个模型能否上线投入使用,往往关注于过拟合问题,即模型在训练和预测阶段的模型表现是否会产生较大的差异,而对抗学习提出来模型的robustness的概念,即输入的微小变化(人为or自然的变化,对抗学习主要关注的是人为对输入的扰动)是否会导致模型输出结果的巨大变化; 2.数据增强/对抗过拟合,对抗学习中的防御方法,对抗训练,在文本领域中常常也被作为一种样本增强的方法,也有一些research直接将对抗训练作为一种特殊的数据增强手段,相对于图像和文本有许多自己独立的数据增强方法,通过对抗训练来进行样本增强的方法可以扩展到任何领域的应用。包括了时间序列数据,静态表格数据等等,除了我们比较熟悉的FGSM,PGD之类的攻击+防御的方法,早期label smooth也作为一种防御手段存在,而label smooth本身也是一种对抗过拟合的方法,因此实际上对抗学习中的许多防御手段是可以直接用于帮助缓解过拟合问题的; 3.反欺诈:对抗学习领域和反欺诈的应用是非常相契合的,在各类的反欺诈应用中,安全人员和欺诈者之间的博弈与对抗学习领域的许多research是类似的,即研究者发明各种先进的攻击手段来攻破先进的防御手段,随着前者由于涉及到具体的业务场景往往要复杂的多而后者的许多实验设定都较为理想,但思想是通用的。 常见的攻击手段分类(1)数据投毒攻击(Data Poisoning Attacks):数据攻击的目标是通过在训练数据中注入恶意样本来影响模型的准确性。  攻击者将更改现有数据或引入错误标记的数据。然后,基于此数据训练的模型将对正确标记的数据做出错误的预测。例如,攻击者可以将欺诈案例重新标记为非欺诈。 这方面的一个典型的例子就是早期淘宝店铺刷好评,皇冠,提升信誉,从而为推荐系统造成虚假的training data。对于许多应用程序,如果模型只训练一次。数据和模型都将被彻底检查,那么遭遇此类攻击的机会可能很小。但是就目前大部分常见的ai应用而言,模型常常是动态refresh的,例如,可能每天/每周/每个月一次让老模型在新数据上retraining,或直接构造一个新的模型,则更加容易受到数据投毒攻击。显然,在海量的数据面前,要对模型的训练产生足够的影响,是需要大量的数据投毒的,相对少量的投毒基本很难影响模型本身的拟合效果。 (2)模型规避攻击(Model Evasion Attacks):这个我比较熟悉点,电商领域的像地址,备注这类的常规的基于规则的敏感词屏蔽的检测系统经常被这么攻击,汉字太博大精深了hhhhh。 在这种类型的攻击中,重点是精心制作既执行特定任务又逃避检测的输入样本(通过强制模型将其标记为良性,即错误分类)[4]  这类攻击和我们熟悉的对抗样本的概念比较相关,例如垃圾邮件和恶意软件检测,也是最为常见的一种攻击手段。 (3)模型提取攻击(Model Extraction Attacks): 如今,由于云计算的普及,这种攻击越来越受到关注。许多不同的供应商提供机器学习即服务(MLaaS),该服务的安全性仍在争论中。 这些MLaaS服务为用户提供了一个预测平台,用户可以通过上传训练数据来训练分类器。然后,供应商决定哪种学习模型和算法最适合用户,并为用户提供一个预测API来查询和获取模型响应。这些查询是收费的,用户按查询收费。此类攻击的主要目标是构建能够和云服务提供的模型产生大致相同计算逻辑的本地模型,从而绕过付费,。这通常很有用,因为用户没有资源来“训练”云的强大机器。换句话说,这种复制可以看作是一种模型蒸馏方法。 (这种思路其实很多地方都有用到,例如简单的模型蒸馏方法,例如可解释机器学习中使用简单可解释模型去拟合复杂模型的input和output) 云服务的模型提供的响应通常包括: 特征,预测结果,这些值可用于确定模型的工作方式并复制其决策边界。最成功的攻击依赖于攻击者从API接收到的信息丰富的输出。然而,即使攻击者拥有的唯一信息是查询的答案,即预测结果,他仍然可以非常准确地模拟系统功能。 根据所使用的模型和攻击者可以访问的信息,模型提取攻击分为以下三个主要类别: a 方程求解模型提取攻击(Equation-solving model extraction attacks): 许多机器学习算法,如逻辑回归,模型可以是一个简单的方程。例如,在Logistic回归中,模型是一个LR函数,攻击者只知道权重和偏差。通过相应地调整输入数据(甚至使用随机输入),攻击者可以构建一个由n+1个变量组成的线性系统,并求解“w”s和“b”。当然,在神经网络等复杂模型中进行这一尝试要困难得多,但[5]已经表明,可以100%准确地重建模型。(我去,这么强,看来有必要学一学攻击技术哈哈哈) b 路径查找攻击(Path finding attacks): 举了一个决策树的例子,此方法假定决策树中的每个叶都有唯一的分布,因此我们可以跟踪查询中的数据属于哪个叶。通过一次更改一个特征的输入数据,我们可以计算出树的所有不同分支,这基本上意味着我们可以从查询中重建树。 c 成员资格查询攻击(Membership queries attacks): 这可以通过假设一个模型并以自适应学习方式对其进行训练来实现,从一些标记数据开始,重新训练模型,然后查询我们的局部置信度较低的点。[7],[6] 简单来说,就是local training model 直到到达和云服务模型相近的精度。 (4) 其它Reconstruction Attack 和 Inference Attack ,联邦学习里还有一些其它的attck方式,不过主要和数据的隐私安全有关,和robustness关系不是很大,就不赘述了。 可以看到,致力于增强模型鲁棒性的对抗性训练,大都和Model Evasion Attacks即逃避检测攻击有关,因为许多对抗训练的方法就是在训练的过程中动态加入对抗样本,而用于产生对抗样本几乎绝大多数的算法都是为了让模型产生误判而达到evation的目的而开发的. Model Evasion Attack实际上针对于不同的恶意攻击手段是有许多对应的防御措施的,这部分内容可以查阅前面推荐的书或其它的一些paper,而对抗训练是防御手段中比较出名的一种,最初接触对抗训练是在bert里做finetune的时候使用fgm来提升模型的泛化性能的,效果还是相当不错的。  图片来源 https://zhuanlan.zhihu.com/p/91269728 图片来源 https://zhuanlan.zhihu.com/p/91269728这里首先大概介绍一下,对抗训练中涉及到的evasion attack的几种划分方法:(from ahttp://blog.csdn.net/weixin_45521594/article/details/105004259) 攻击方法分类标准假正性攻击(false positive)与伪负性攻击(false negative):假正性攻击:原本是错误的但被被攻击模型识别为正例的攻击(eg: 一张人类不可识别的图像,被NN以高置信度分类为某一类); 伪负性攻击:原本应该被正常识别但被被攻击模型识别错误的攻击(eg: 原本能够被正确的样本,在遭到对抗攻击后,被攻击模型无法对其正确分类)。ps: 我现在做的遇到的大部分攻击算法都是伪负性攻击算法。 白盒攻击(white box)与黑盒攻击(black box):被攻击模型的模型参数可以被获取的被称为白盒攻击,对抗训练使用的大部分都是白盒攻击; 白盒攻击是构建对抗性样本的最简单方法,并且成功率最高,扰动最小。在实践中,白盒攻击的假设往往过于强大,因为生产中使用的底层模型通常对攻击者是隐藏的,白盒攻击是评估模型robustness的最可靠方法,因为它们通常会导致最强的攻击,可用于评估系统在最坏情况下的性能。因此,模型开发人员可以使用白盒攻击来提供内部性能评估。 白盒攻击也是我比较感兴趣的(因为研究对抗学习的主要目的是想要尝试通过对抗学习的一些idea来提升模型的performance。。),整体可以用下面的公式表达  g(x)表示对抗攻击引发的模型的误判程度的衡量,比较常用的就是模型训练使用的loss function,例如常见的交叉熵,CW攻击中引入了hinge loss,认为hinge loss作为误判程度的衡量更容易产生成功的攻击。 后面的正则项则表示对攻击的约束,即原始样本和用于攻击的对抗样本之间的某种距离衡量(衡量对抗性扰动的程度),比较常用的就是Lp范数。 对抗性扰动常用的 ℓp 范数包括 ℓ\infty 、ℓ2、ℓ1 和 ℓ0 范数。 在制作对抗性样本时,ℓp 范数系列具有物理意义。 ℓ\infty 范数限制所有维度的最大变化,ℓ2 范数测量 x 和 x0 之间的欧氏距离,ℓ1 范数测量 x 和 x0 之间的总变化(绝对值)之和,ℓ0 范数测量修改过的元素(例如,修改过的图像像素)个数,所谓的LP范数攻击的意思就是对抗性扰动的衡量方式,例如我们用L2范数来衡量对抗性扰动的程度则称这种攻击为L2范数攻击。 根据上下文,我们可以在优化公式中以约束或惩罚函数的形式使用混合规范进行对抗性攻击。例如,陈等人。 (2018b) 提出了对深度神经网络的弹性网络攻击(EAD 攻击),它使用 ℓ1 和 ℓ2 范数的混合来寻找稀疏的对抗样本,并被证明可以提高 C&W 攻击的攻击性能。苏等。 (2019) 提出了一种基于 ℓ0 范数的攻击,该攻击仅修改少量像素即可引起预测变化。我们还可以利用卷积过滤器并使用群体规范来设计 Xu 等人提出的结构化对抗攻击。 (2019b)。 早期,在研究界,关于防御如何有效对抗攻击的讨论非常活跃,因为根据攻击者和防御者的行动顺序不同,结论会大相径庭,这是攻击者的重要规范。威胁模型。如果攻击者首先通过创建对抗性示例采取行动,随后防御者开始识别那些生成的对抗性示例,例如在数据推理之前使用基于输入过滤或数据重建的技术,那么可以减轻或减轻许多攻击。另一方面,如果防御者首先采取行动,而攻击者知道防御到位,那么在后一种情况下,许多防御被证明是无效的或“被破坏的”(Carlini 和 Wagner,2017a;Athalye 等人., 2018 年;Carlini 等人,2019a)。 后一种设置称为自适应白盒攻击设置,它基本上假设在进行对抗性攻击时防御对攻击者是完全透明的(除了一些不可控的随机性)。此设置对于实施实际攻击可能不切实际,但它提供了关于机器学习 24 对抗鲁棒性的真实鲁棒性的诚实(最坏情况)评估 保护模型免受对抗性攻击,超出攻击者和防御者之间信息不对称的优势。否则,有人认为,如果在第一个设置中稳健的模型对自适应攻击不稳健,它们可能会给人一种错误的安全感或稳健感(Carlini 和 Wagner,2017a;Athalye 等,2018;Carlini 等, 2019a).正如 Athalye 等人所讨论的,一个典型的例子是防御带来的所谓“梯度混淆”效应,这种效应由于信息混淆(例如,输入空间中损失景观上的梯度过度平滑或噪声过大)而混淆了基于梯度的攻击。 (2018)。然而,了解防御机制的攻击者可以提出高级方法或采用基于非梯度的攻击来使这些防御失效。卡里尼等人。 (2019a) 提供了许多基于自适应攻击评估对抗性鲁棒性的原则。 • 超出 ℓp 规范的对抗性攻击包括语义相似的示例,例如颜色空间移动(Hosseini 和 Poovendran,2018 年)和空间变换(例如旋转)(Xiao 等人,2018 年;Engstrom 等人,2019b)。蔡等人。 (2022) 提出了考虑多种攻击类型及其攻击顺序的复合对抗攻击。 • 超出 ℓp 规范的对抗性攻击包括语义相似的示例,例如颜色空间移动(Hosseini 和 Poovendran,2018 年)和空间变换(例如旋转)(Xiao 等人,2018 年;Engstrom 等人,2019b)。蔡等人。 (2022) 提出了考虑多种攻击类型及其攻击顺序的复合对抗攻击。    模型参数不可见的被称为黑盒攻击。 黑盒攻击可以进一步细分为 有限的黑盒攻击,这类方法基于从模型的输出来产生对抗样本, 以及基于score的黑盒攻击,这类方法基于从NN返回的原始预测(分数)来改进对抗输入。基于分数的方法可以访问所有分数或仅访问最高(例如,前10名)分数。基于分数的方法介于白盒和有限黑盒方法之间;他们需要访问比有限的黑盒攻击更详细的模型响应,但不需要像白盒攻击那样访问模型算法。 在软标签黑盒攻击设置中,攻击者可以观察(部分)类预测及其相关的置信度分数。在硬标签黑盒攻击(基于决策)设置中,攻击者只能观察到 top-1 标签预测,这是保持模型效用所需返回的最少信息。除了攻击成功率,查询效率也是黑盒攻击性能评估的重要指标。 转移攻击是黑盒攻击的一个分支,它使用从白盒代理模型生成的对抗样本来攻击目标黑盒模型。代理模型可以是预训练的(Liu 等人, 2017b) 或从一组数据样本中提取,这些样本具有目标模型给出的软标签作为训练标签 (Papernot et al., 2016, 2017)。 在白盒和黑盒攻击的范围之间,变化威胁模型和攻击者的能力会导致不同的灰盒攻击。 还有其它的一些划分方法可见下: 有目标攻击(target attack)和无目标攻击(non-target attack): 有目标攻击:期望对抗样本被定向误识别为某一特定类别; 无目标攻击:仅仅希望对抗样本不能被识别的而没有指定目标类别。 单步攻击(One-time attack)和迭代攻击(Iteration attack): 最典型的就是之前实现过的FGSM([2]) I-FGSM([3]),前者是单步攻击,后者为迭代攻击; 个体攻击(Individual attack)和普适性攻击(Universal attack): 个体攻击向每个样本添加不同的扰动,大多数攻击方法都属于个体攻击(典型算法可见[4],[5]); 普适性攻击训练一个整个数据集通用的扰动。 优化扰动(optimized perturbation)和约束扰动(constrained perturbation): 优化扰动表示扰动大小作为优化过程中的优化目标(典型算法算法可参考[6]),C&W攻击(白盒攻击)算法是一种基于迭代优化的低扰动对抗样本生成算法。该算法设计了一个损失函数,它在对抗样本中有较小的值,但在原始样本中有较大的值,因此通过最小化该损失函数即可搜寻到对抗样本; 约束扰动表示所添加扰动仅需满足约束即可。 目前该领域最常用的数据集为MNIST, CIFAR 和ImageNet; 最常用的被攻击模型为LeNet, VGG, AlexNet,GoogLeNet, CaffeNet, and ResNet等 对抗训练和数据增强的关系?对抗训练是用于提高深度学习模型抗攻击性的一种最有效的防御策略。与其他防御策略不同,对抗性训练旨在从本质上增强模型的鲁棒性。 在各种现有防御策略中,对抗训练(AT=Adversial Training)[Goodfellow等人,2015;Madry等人,2018]被证明是对抗对抗性攻击最有效的方法[Pang等人,2020a;Maini等人,2020;Schott等人,2019],受到了研究界的广泛关注。对抗性训练的概念很简单:它在每个训练循环中用对抗性样本来增加训练数据。 从数学上讲,对抗训练是作为一个最小-最大问题来表述的(对抗样本根据使得模型产生最大loss的方式来优化和产生,最小化则是希望模型能够在对抗样本上的loss最小化),它寻找最坏情况下的最佳解决方案。对抗性训练的主要挑战是解决研究人员正在积极研究的内部最大化问题(最小化问题就是常规的nn的根据loss function的梯度下降没啥可研究的)。 基础概念介绍 对抗性攻击(Adversarial Attacks): 对抗性攻击是指为训练有素的模型寻找对抗性样本的过程。在本文中,我们只考虑训练/测试数据最初来自同一分布的情况。 (这其实是一个非常有意思的地方,对抗样本和分布偏移样本之间的关系是什么?二者对于模型来说,都是一种能够让模型分类错误的存在,不同之处在于,对抗样本本身的基本假设是独立同分布,即对抗样本本身仍旧是处于全局的训练数据的分布之下的,而分布偏移样本则相反,其实可以理解为一个尺度的问题,  原图来源于Towards Deep Learning Models Resistant to AdversarialAttacks) 以分类为例,我们使用  表示将输入图像x,size为(h,w,c),映射到具有k类的离散标签集的图像分类器,其中θ表示f的参数,即神经网络的trainable parameters,h、w、C分别表示图像高度、宽度和通道。考虑到某种扰动δ,我们试图找到某种扰动δ可以最大化损失函数(最大化损失函数意味着让模型的性能变得最差),例如交叉熵损失Lce,因为这种扰动是直接针对原始样本x的,并且一般认为扰动相对于原始的数据是非常细微的,并不会改变原始数据的内在含义,因此 f(x+δ)=f(x)。所以我们将扰动 δ估计为  其中y是x的标签,p可以是0、1、2和∞, 在大多数情况下,δ很小,所以是属于肉眼无法察觉的扰动。注意,在本文中,我们只考虑基于lp的攻击进行对抗训练的分类。 那么原始样本x的对抗样本x′表示为  该公式可以用来笼统地表示 如快速梯度符号法(FGSM)[Goodfellow等人,2015]、迭代FGSM[Kurakin等人,2016]和投影梯度下降(PGD)攻击[Madry等人,2018]等。 这里补充一下  实际上这里的扰动的p代表的是Lp范数,比如我们常见的L2范数  编辑切换为居中 https://www.jianshu.com/p/60adcd0f6787 可以理解为对抗样本和原始样本之间的某种距离度量要小于某个阈值的意思。比如l1是曼哈顿距离,l2是欧几里得距离。 下面这个图应该会比较清晰一点了  高维空间的一个奇怪特征是空间中的所有点都具有相似的欧氏距离。虽然 L2 范数是我们理解的低二维或三维空间中最直观的距离度量,但事实证明它是高维空间中距离的糟糕度量。L2 范数常用于生成对抗样本,但它不一定是衡量扰动的最佳方法。 另一种距离测量是 L1 范数,它只是所有像素差异的绝对值的总和。 (以图片为例) 另一种方法可能是根据具有不同值的像素总数来衡量两幅图像之间的差异。在输入空间术语中,这只是两个图像之间具有不同值的维数。这种测量在数学上被称为 L0-“范数”。 直觉上,这是一种合理的方法,因为我们可能期望更少的像素变化会比更多的像素变化更不易察觉,但 L0-范数不限制像素变化的绝对大小而只是统计变化像素的数量这也是不合理的,因为部分像素极大的变化也违背了对抗样本的基本特点“小而致命”。(对抗性样本的基本要求生成导致网络错误解释的输入,但不会被人类检测为攻击。这意味着这种变化对人类来说是察觉不到的,或者微不足道到足以让人类有意识或无意识地忽视它,否则如果生成对抗样本的过程中,对原始数据的变化太大,可能会使得原始数据的语义也发生巨大的变化,这样对抗样本的标签就是noise的了) 最后介绍最为流行的方法, L∞ 范数(“无穷大”范数)l无穷大范数计算的是原始样本和对抗样本各个像素的差异的最大值,因此它可以对图像进行许多无穷小和难以察觉的变化,这些变化组合起来会对图像的分类产生重大影响。 (一些生成对抗样本的工具介绍:CleverHans、Foolbox 和 IBM 的 Adversarial Robustness Toolbox) 对抗健壮性的对抗训练 目前,对抗训练被广泛认为是实践中提高深度学习模型对抗鲁棒性的最有效方法【Athalye和Carlini,2018年】。然而,对抗训练要想完美地应对对抗性攻击,还有很长的路要走。流行的对抗训练方法[Madry等人,2018年]可以在MNIST上生成一个稳健的模型,最坏情况下的准确率约为90%。对于稍具挑战性的数据集,例如CIFAR10,对抗训练在SVHN上仅达到约45%和40%【Buckman等人,2018年】,这远远不能令人满意。此外,对抗训练导致深度学习模型泛化能力下降(在nlp里确相反,对抗训练被用于增强模型的泛化能力)。在本节中,我们首先回顾了对抗性训练的发展,用一种新的分类法总结了最近的进展,并讨论了对抗性训练的泛化问题。 对抗训练的起源 对抗训练可能是增强神经网络对抗 对抗性样本的最直观方法。毕竟,可以训练网络来区分复杂的特征和模式,那么肯定有一些对抗样本的特征可以让它们被模型发现? 对抗性样本表明 NN 存在缺陷,表明 NN 无法泛化所有输入。因此,提前产生对抗性样本并引入他们将会提高算法的鲁棒性。 一种思路是通过引入一个对抗性样本的检测工具,用于作为trained model的input前的detect tools,即detect tools检测某个样本属于对抗性样本,则后续做出适当相应,例如通过强制降低模型的预测置信度。 更常见的思路是直接将预先定义好的对抗性样本加入模型训练的过程中,从而让模型不仅能够完成正常样本的下游任务,附加的,还能够完成对抗性样本的下游任务。 大多数对抗性样本被认为位于对抗性子空间内——输入空间内连续的错误分类区域。那么,我们当然可以用许多带标签的对抗样本来训练(或重新训练)模型,以便它学会在这些子空间上正确泛化  这种使用对抗性样本例训练模型的概念已经从多个角度进行了探索。不幸的是,尽管这种技术看起来是一种很好的防御,但经过训练的模型仅对通过与对抗性相同或相似的方法生成的对抗性样本具有鲁棒性训练数据。 对抗训练的最初想法是由[Szegedy et al.,2014]首次提出的,其中神经网络是基于对抗样本和干净样本的混合进行训练的。Goodfellow等人(2015)更进一步,建议FGSM在训练期间产生对抗性样本。然而,他们训练的模型仍然容易受到迭代攻击[Tram`er等人,2018年],因为这些方法使用线性函数来近似损失函数,导致相应深度模型决策面上的数据点附近出现尖锐曲率。尖锐曲率的存在也称为梯度遮蔽【Papernot等人,2017年】。 与先前的工作不同,模型是基于干净数据和对抗数据的混合进行训练的,一系列研究仅使用对抗数据训练模型。Huang et al.(2015)首次定义了一个最小-最大问题,即以分类问题为例,训练过程产生的对抗样本要能够最大化loss,但同时模型又能够最小化loss。他们还指出,解决这个min-max问题的关键是找到强有力的对抗性样本。Shaham等人(2018)从稳健优化的角度考虑了这个最小-最大问题,并提出了对抗训练的框架。公式如下所示:  其中(x,y)∼ D表示从分布D中取的训练数据,B(x,ε)是允许的扰动集,表示为  Madry等人(2018)对此公式给出了合理的解释:内部最大化问题是为给定模型找到导致最坏情况的对抗样本,外部最小化问题是训练一个对 对抗性样本鲁棒的模型。 基于这种联系,Madry等人(2018)采用了一种称为PGD攻击的多步骤梯度攻击来解决内部最大化问题,如下所示:  其中t是当前步长,α是步长。此外,他们从对抗性样本的角度研究了内部最大化问题,并给出了局部极大值对PGD的可处理性的理论和经验证明。通过大量实验,他们的方法(PGD)显著提高了深度学习模型对各种攻击的对抗鲁棒性,这是对抗训练方法的一个里程碑。由于大多数衍生作品都遵循其设计和设置,PGD成为一个重要的基准,并被视为在实践中进行对抗训练的标准方式. 防御方法 Gradient masking Gradient masking这种方法改变模型以隐藏预测场景中的梯度,从而使创建对抗性示例变得困难。 Adversarial training 这包括训练(或再训练)网络,使其学会区分对抗性输入。这是通过在训练数据中包含对抗性示例来实现的。 Out-of-distribution (OoD) detection 在这里,我们看看是否可以训练网络不仅返回预测,还可以基于数据是否位于网络能够以高精度操作的分布范围内,来返回对该预测的确信程度的置信度度量。 Randomized dropout uncertainty measurements 最后,该方法在训练后的模型中添加了一种称为随机丢弃的训练技术,从而为网络的预测引入了不确定性。这是基于一个前提,即对抗性输入会导致更大的不确定性,因此可能检测到它们。 Defensive Distillation,Thermometer Encoding,Pixel Defend。。。。。。 彼时对抗训练并不是防御对抗攻击唯一的方法,还有诸如 Defensive Distillation 、Thermometer Encoding 、Pixel Defend 、对输入进行随机化处理 等看起来也很有前景的方法。 但是接下来大部分都被证明本质是对模型的梯度进行了混淆(Gradient Masking ),这样大部分白盒的攻击方法都不能有效地利用梯度来进行攻击(回顾一下经典的FGSM是基于梯度产生对抗样本的,如果梯度被混淆则无法实施最强大的白盒攻击),但是对抗样本本身依然是客观存在的,通过重建梯度或者使用较强的黑盒攻击方法,这些模型依然可以被攻破。 from Greene:对抗训练——终极数据增强? 2018年,Anish Athalye 等人 对ICLR中展示的11种对抗防御方法进行了评估,最后他们只在基于对抗训练的两种方法上没有发现混淆梯度的迹象,自此之后,对抗训练成为对抗防御研究的主流。 对抗训练本身有两个显著的问题,一个问题是速度极慢,假设针对每个样本进行10次PGD对抗攻击来获得对抗样本,那么一个训练迭代就对梯度多进行了10次反向传播,训练用时至少是正常训练的十倍(因此最初才会使用FGSM等快速攻击方法来加快对抗训练)。 另一个问题则是精度较低(这一点和在nlp中的应用存在很大的不同),一方面是模型在正常样本上的精度降低了,原来可以达到95%以上的分类精度的模型,进行对抗训练之后,往往只能达到80%~90%(这意味着模型可能要在稳健性和精确度 之间取舍);另一方面模型在对抗攻击下的精度(Robust Accuracy)也不高,目前最好的结果依然不超过70% 。 还有一个与对抗训练本身无关,但是对于防御对抗攻击的研究来说更加重要的问题:如何衡量模型的对抗稳健性?关于对抗训练的研究往往试图使用最强的白盒攻击来证明模型的稳健性,一般使用PGD攻击和C&W攻击 。 但对抗攻击是一个存在问题——只需要针对大部分样本都能够生成一个能够欺骗模型的对抗样本,这个攻击方法就是成功的,而对抗防御则是一个任意问题——一个对抗稳健的模型,需要能够正确识别所有潜在攻击方法生成的对抗样本,使用对抗攻击来证明对抗稳健性本身就是不靠谱的,得到的只是模型对抗稳健性 的上界,因此另有一系列研究(Provable Defense)从对抗训练出发,转而追求模型对抗稳健性的下界。  编辑切换为居中 添加图片注释,不超过 140 字(可选) 对抗训练分类 一个大的分类方法 被攻击模型的模型参数可以被获取的被称为白盒攻击;模型参数不可见的被称为黑盒攻击。原文部分 在本小节中,我们回顾了近几年来对抗训练的最新进展,按对对抗训练的不同理解进行了分类。表1总结了选定的对抗训练方法。  Adversarial Regularization 对抗性正则化的概念首次出现在【Goodfellow等人,2015年】。除了交叉熵损失,他们在目标函数中添加了一个正则化项,该项基于FGSM,表示为  Kurakin等人(2017年)通过控制batch内对抗性样本的占比,扩展了基于FGSM的正则化方法,使其可以扩展到ImageNet。他们的方法的有效性在单步攻击中得到了验证,因为他们认为神经网络的线性化归因于对抗性样本的存在【Goodfellow等人,2015年】。然而,秦等人(2019)计算了对抗损失与其一阶泰勒展开之间的绝对差值,得出结论认为,更稳健的模型通常具有更小的局部线性值。相应地,他们用局部线性正则化代替了基于FGSM的正则化,以实现对抗鲁棒性。 与以前的方法不同,[Zhang等人,2019b]将鲁棒误差(robust error ) Rrob分解为自然误差Rnat和边界误差Rdb之和。当数据与决策边界之间的距离足够小(小于δ)时,就会出现边界错误,这也是对抗性样本存在的原因。因此,他们提出了TRADES通过解决以下问题来最小化Rdb:  其中λ是用于表示正则化强度的系数。这种分解被证明是有效的,TRADES在CIFAR-10上的性能优于PGD,错误率降低了10%。TRADES的一个问题是,无论自然数据是否正确分类,正则化的设计都是为了将原始样本及其对抗样本推到一起。【Wang等人,2020年】调查了错误分类样本的影响,并提出了MART,该训练强调权重为1的错误分类样本− Py(x,θ),其中Py(x,θ)是基本真值标签y的概率。 由于深度模型的放大作用,不可察觉的噪声可能会导致特征空间发生重大变化【Goodfellow等人,2015年】。一些研究从特征空间的角度分析对抗训练。Kannan等人(2018)提出了对抗逻辑配对(ALP),鼓励对抗样本和原始样本的特征空间接近。但由于对抗训练目标的制定错误,ALP最初并不有用【Engstrom等人,2018年】。为了进一步加强原始数据的特征空间与对抗数据的特征空间的一致性,Mao等人(2019年)采用了流行的triple loss进行规范化,将对抗样本用作anchor(这个思路在nueral structure learning里也有用到)。 对抗正规化是对抗训练的一个重要变体【Shaham等人,2018年】。与对抗训练的最初形式相比,对抗正规化更灵活,需要对对抗鲁棒性有深入的了解。此外,鲁棒性错误的分解确实为未标记数据铺平了道路,以增强对抗性鲁棒性。 Curriculum-based Adversarial Training 根据对抗训练的公式,内部最大化问题总是试图找到产生最坏情况的对抗样本。一个自然的问题是:这些最坏情况的样本总是适合对抗训练吗?Zhang等人(2020年)发现,强攻击产生的对抗性样本明显跨越了决策边界,并且更接近原始数据。由于PGD仅使用对抗性样本进行训练,这导致模型对对抗性样本产生overfiting[Cai等人,2018年]。 为了缓解这个问题,研究人员将课程训练的理念引入对抗训练。Cai等人(2018)提出了课程对抗训练(CA T),其假设是,采用更多步骤的PGD会产生更强的对抗性样本。从少量步骤开始,CAT逐渐增加PGD的迭代步骤,直到模型对当前攻击达到高精度。与CAT不同,友好对手训练(FAT)[Zhang等人,2020年]在执行PGD攻击时使用早停,并在决策边界附近返回对抗样本进行训练。CAT和FAT都以实际的方式调整攻击强度,但缺少定量标准。Wang等人(2019)从收敛的角度出发,设计了一阶平稳条件(FOSC)来估计内部最大化问题的收敛质量,FOSC越接近0,攻击越强。 这种基于课程的方法有助于改进干净数据的泛化,同时保持对抗性鲁棒性。他们成功的一个可能原因是早期训练阶段的弱攻击与泛化有关[Wang等人,2019]。除了消除过拟合外,基于课程的方法还由于求解内部最大化问题的PGD迭代次数不同而减少了训练时间。 Ensemble Adversarial Training Tram`er等人(2018年)首次将集成学习引入对抗训练,称为集成对抗训练(EAT),其中训练数据由不同目标模型生成的对抗样本而不是单个模型来扩充。EAT的优点是它有助于减轻单步攻击(例如FGSM)造成的尖锐曲率。然而,忽略了不同目标模型之间的相互作用[Tram`er等人,2018年]。具体而言,经过标准训练的目标模型可能具有类似的预测或表示[Dauphin等人,2014年],并共享对抗子空间[Tram`er等人,2017年],这可能会损害EAT的性能. 为了促进目标模型之间的多样性,后来的研究提出了几项改进,例如自适应多样性促进正则化器[Pang等人,2019],迫使不同的模型在非最大预测方面存在差异;最大化每个目标模型输入梯度之间的余弦距离[Kariyappa和Qureshi,2019](输入梯度是指输入的损失函数的梯度);并最大化漏洞多样性[Yang et al.,2020a],这被定义为两个模型的损失总和,其中精心制作的图像包含非鲁棒性特征[Ilyas等人,2019]。本质上,这种集成方法有助于在对抗训练中逼近内部最大化问题的最优值。正如[Tram`er等人,2018年]所证明的,无论扰动类型如何,用EA T训练的模型都具有更好的泛化能力。综上所述,在训练中增加目标模型的数量和多样性是一种实用且有用的方法,可以近似地描述对抗性示例的空间,这很难明确描述。 Adversarial Training with Adaptive δ 如方程(3)所示,攻击参数在训练期间是预先定义和固定的,例如δ。一些研究【Balaji等人,2019年;Ding等人,2020年】认为,单个数据点可能具有不同的内在稳健性,即到分类器决策边界的距离不同;然而,使用固定ǫ的对抗训练对所有数据都一视同仁。考虑到对抗鲁棒性的个体特征,研究人员建议在样本级别进行对抗训练。Balaji等人(2019年)首次提出了实例自适应对抗训练(IAAT),其中选择了尽可能大的δ, ensuring images within δ-ball of x are from the same class(翻译太奇怪了,还是用原文吧)。 该策略有助于IAAT缓解稳健性和准确性之间的权衡,尽管稳健性略有下降。与IAAT不同,另一项称为边际最大化对抗训练(MMA)的工作[Ding等人,2020年]直接最大化了数据点与模型决策边界之间的边际距离,这是通过最小量级的对抗扰动估计的。 在MMA中选择δ的方式更为合理,因为δ足够小,而且在空间域中如此小的δ几乎不会实质上改变图像的类别,特别是对于高分辨率图像。以下工作,即定制对抗训练(CA )[Cheng等人,2020年]进一步应用自适应标签不确定性,以防止基于自适应δ的过度自信预测。适应性对抗训练是一种很好的探索。然而,经验证据表明,许多标准数据集是分布分离的,即类间距离大于用于攻击的距离[Yang等人,2020b]。这反映了当前对抗训练方法在寻找适当决策边界方面的局限性。 Adversarial Training with Semi/Unsupervised Learning 监督对抗训练方法中的一个关键观察结果[Madry等人,2018;Zhang等人,2019b]是,测试中的对抗精确度远低于训练中的对抗精确度。对抗训练中存在很大的泛化差距(参见[Schmidt等人,2018年]中的图1)。最近的工作【Schmidt等人,2018年】从样本复杂性的角度研究了这个问题。理论证明,对抗稳健训练需要比标准训练大得多的数据集。然而,带标签的高质量数据集的收集成本很高,这在实践中特别有意义。或者,一些作品同时出现,探索使用其他未标记数据进行培训的可能性。 根据[Schmidt等人,2018年]中对高斯模型的分析,一些工作[Alayrac等人,2019年;Carmon等人,2011年;Zhai等人,2019]理论上表明,未标记的数据显著减少了标准训练和对抗训练之间的样本复杂性差距。它们有着相同的思想,即像TRADES这样分解对抗性鲁棒性,并利用未标记的数据实现稳定性,同时利用标记的数据进行分类。通过经验,他们调查了不同因素对对抗训练的影响,如标签噪声、分布偏移和附加数据量。另一方面,Najafi et al.(2019)引入了一些新的复杂性度量,如最小监督比,用于泛化的理论分析。 同时,自监督训练有助于对抗鲁棒性[Hendrycks等人,2019]。看到更多未标记数据带来的对抗鲁棒性改进,令人鼓舞。然而,理论或经验上仍无法保证到底需要多少额外数据。此外,这些方法的成本也不容忽视,包括收集数据和对比原始数据集大几倍的数据进行对抗性训练。 Efficient Adversarial Training 传统对抗训练方法(如PGD-AT)的一个众所周知的局限性是,在模型收敛之前,它们需要比标准训练长3-30倍的时间[Shafahi等人,2019]。主要原因是方程(3)中描述的最小-最大问题是迭代求解的。对抗训练的这一研究方向旨在降低时间成本,同时保持对抗训练的性能。作为第一次尝试,自由对抗训练(free AT)的核心思想[Shafahi et al.,2019]是在向前传播时重用后向传播中计算的梯度。在free-AT中,模型参数和图像扰动同时更新。具体而言,对于相同的小批量数据,相同的操作连续执行m次,相当于在PGD-aT中使用强大的对抗性样本。此外,根据Free-aT,Wong et al.(2020)提出了快速对抗性训练(FASTAT),它使用随机初始化的FGSM,与PGD-aT一样有效。他们还将基于FGSM的对抗训练方法的失败归因于灾难性过拟合和零初始化扰动。然而,Andriushchenko和Flamarion(2020年)发现这些快速训练方法[Shafahi等人,2019年;Wong等人,2020年]也遭受了灾难性的过拟合。 他们还指出,随机化在【Wong等人,2020年】中生效的原因是随机化略微降低了扰动的程度。Kim等人(2021)支持上述发现,并证明灾难性的过度拟合是因为单步对抗训练仅使用具有最大扰动的对抗性样本。为了防止灾难性的过度拟合,提出了许多改进,如梯度对齐[Andriushchenko和Flammarion,2020]、动态调度[Vivek和Babu,2020b]、内部区间验证[Kim等人,2021]、域自适应[Song等人,2019]和正则化方法-ods【Vivek和Babu,2020a;Huang等人,2020年】。Zhang et al.(2019a)从上述工作的内在出发,从蓬特里亚金的最大值原理的角度提出了“只传播一次”(YOO Only Propagate Once,YOPO)。根据他们对对抗训练的分析,他们观察到对手梯度更新只与神经网络的第一层有关。此属性使YOPO能够在冻结其他层的同时,将重点放在提议的网络体系结构的第一层以进行敌方计算,从而显著减少正向和反向传播的数量。作者声称,Free AT是YOPO的一个特殊案例。 Other Variants 除了对抗训练方法的上述分支之外,对抗训练的其他几种变体总结如下。一些工作修改了普通对抗训练的学习目标,如对抗分配训练[Dong等人,2020年],其中基于分配的最小-最大问题是从一般观点推导出来的;双边对抗训练[Wang和Zhang,2019],其中模型在扰动图像和标签上训练;以及基于特征分散的对抗性训练[Zhang和Wang,2019],该训练利用自然数据集及其对应数据集的距离度量,并在特征空间中生成对抗性示例。一些替代模型的基本组件以获得更好的性能,例如超球面嵌入[Pang等人,2020b],以及平滑的ReLU函数[Xie等人,2020年]。最后,一些人建议通过插值来增加对抗性示例,例如AVmixup[Lee et al.,2020]和对抗性插值训练[Zhang and Xu,2020]。 对抗训练中的泛化问题 对于深度学习算法,泛化是一个重要特征。尽管该研究群体的大部分努力都是为了改进给定对抗性攻击下的对抗性训练,但关于泛化的讨论声音越来越大。本小节主要从三个方面回顾了对抗训练的泛化研究:标准泛化、对抗鲁棒泛化和对隐蔽攻击的泛化。 Standard Generalization 尽管在提高神经网络对抗性攻击的鲁棒性方面取得了成功,但可以观察到对抗性训练严重损害了标准精度[Madry等人,2018年],这导致了对对抗性鲁棒性和标准精度之间关系的讨论。我们称之为Standard Generalization。 一个流行的观点是对抗性鲁棒性和标准准确性之间的权衡。Tsipras等人(2018年)声称,标准准确度和对抗鲁棒性可能不一致,并通过二进制分类任务证明了权衡的存在。Su等人(2018年)根据多个稳健性指标评估了最近基于SOTA ImageNet的模型。他们得出结论,模型分类精度的对数与模型鲁棒性之间呈线性负相关。Zhang等人(2019b)将稳健误差分解为自然误差和边界误差之和,并为其提供了一个严格的上界,从理论上描述了这种权衡机制。 然而,一些研究有不同的观点,即对抗性鲁棒性和标准准确性并不是对立的。Stutz等人(2019年)研究了多种对抗性样本和自然数据。他们证实了在多种自然数据上存在对抗性示例,对抗性鲁棒性相当于泛化。Yang等人(2020b)研究了从MNIST到Restricted ImageNet的各种数据集,表明这些数据集是分布式分离的,分离通常大于2(不同数据集的值不同,例如,MNIST的值为0.1,CIFAR的值为8)。这表明存在健壮且准确的分类器。他们还声称,现有的训练方法未能强加本地的利普希茨(Lipschitzness)或不够普遍。【Raghunathan等人,2019年】的实验支持了这一说法,额外的未标记数据被证明有助于缓解这种权衡。正如[Yang等人,2020b]所指出的,这种权衡可能不是固有的,而是当前对抗性训练方法的结果。尽管研究人员尚未就这种权衡的原因达成共识,但现有证据确实揭示了对抗训练的一些局限性。对手的稳健性不应以牺牲标准准确性为代价。从经验上看,对抗训练的一些变体表现出更好的标准泛化,例如第3.2节中回顾的对抗训练的适应性δ、强大的局部特征[Song等人,2020年]和L1惩罚[Xing等人,2020)。 Adversarially Robust Generalization 在[Madry等人,2018年]中首次观察到对抗训练模型在对抗扰动测试数据上表现不佳的现象。换句话说,训练精度和对抗数据测试精度之间存在很大差距。除了CIFAR-10,在多个数据集上观察到类似的实验结果,例如SVHN、CIFAR-100和ImageNet[Rice等人,2020年]。这些差距表明,在当前的对抗训练方法中,发生了严重的过度训练。这种过拟合最初是由[Schmidt等人,2018年]研究的,他们将其称为对抗稳健泛化。 Schmidt等人(2018)揭示了获得稳健模型的困难,因为对抗稳健泛化需要更多的训练数据。后来,人们在经验上做出了许多努力来改进泛化,例如采用半无监督学习、AVmixup和强大的局部特征的对抗训练[Song等人,2020年]。相反,Rice等人(2020年)系统地研究了深度学习中使用的各种技术,如ℓ1和ℓ2正规化、切断、混淆和提前停止,其中提前停止最为有效,并得到【Pang等人,2020a】的确认。 另一方面,尽管研究人员试图使用不同的工具,如Rademacher复杂性[Yin等人,2019]和VC维度[Cullina等人,2018]来分析这个泛化问题,但理论进展实际上是有限的,泛化问题远未解决。 Generalization on Unseen Attacks 对抗性训练的最后一个重要特性是对看不见的攻击进行泛化。事实证明,特定类型的攻击不足以表示可能的扰动空间[Tramèr等人,2018;Goodfellow等人,2015]。然而,在对抗训练中,内部最大化问题的约束:lp范数和δ是预先确定的。因此,经过对抗训练的模型,对特定攻击具有鲁棒性,例如,l∞ 对抗性样本可以通过不同类型的攻击轻松规避,例如,其他lp规范、更大的δ或不同的目标模型[Kang等人,2019]。在对抗训练中,简单地将扰动与不同的lp范式结合起来也被证明是无用的[Tramer和Boneh,2019]。这种对其他攻击的泛化能力差,大大降低了对抗训练的可靠性。 这种局限性本质上是由对抗训练本身造成的,关键是如何妥善解决内部问题。EAT中的研究路线可以看作是通过在训练期间增加目标模型的数量和多样性来逼近内部问题的最佳解决方案的第一次尝试。同样,Maini et al.(2020)采用了不同lp范数下的扰动,并使用梯度下降近似内部问题的最优值。Dong等人(2020)建议明确建模每个样本周围的对抗性样本的分布,替换扰动集B(x,ǫ)。从另一个角度来看,Stutz等人(2020年)建议在对抗训练期间校准置信分数。 虽然意义重大,但对隐形攻击的对抗训练的泛化问题目前只是偶尔研究。一个可能的原因是,我们对对抗性样本的理解是有限的和不完整的。对抗性例子的真相仍旧underground,这也需要付出很多努力。 用到再看具体的对抗训练方法吧,太多了也。。。 对抗攻击和防御方法介绍FGM和FGSM PGD C&W attack 对于计算机视觉,对抗性扰动常用的 ℓp 范数包括 、ℓ2、ℓ1 和 ℓ0 范数。1 在制作对抗性示例时,ℓp 范数系列具有物理意义。 范数限制所有维度的最大变化,ℓ2 范数测量 x 和 x0 之间的欧氏距离,ℓ1 范数测量 x 和 x0 之间的总变化(绝对值)之和,ℓ0 范数测量修改过的元素(例如,修改过的图像像素)。根据上下文,我们可以在优化公式中以约束或惩罚函数的形式使用混合规范进行对抗性攻击。例如,陈等人。 (2018b) 提出了对深度神经网络的弹性网络攻击(EAD 攻击),它使用 ℓ1 和 ℓ2 范数的混合来寻找稀疏的对抗样本,并被证明可以提高 C&W 攻击的攻击性能。苏等。 (2019) 提出了一种基于 ℓ0 范数的攻击,该攻击仅修改少量像素即可引起预测变化。我们还可以利用卷积过滤器并使用群体规范来设计 Xu 等人提出的结构化对抗攻击。 (2019b)。 早期,在研究界,关于防御如何有效对抗攻击的讨论非常活跃,因为根据攻击者和防御者的行动顺序不同,结论会大相径庭,这是攻击者的重要规范。威胁模型。如果攻击者首先通过创建对抗性示例采取行动,随后防御者开始识别那些生成的对抗性示例,例如在数据推理之前使用基于输入过滤或数据重建的技术,那么可以减轻或减轻许多攻击。另一方面,如果防御者首先采取行动,而攻击者知道防御到位,那么在后一种情况下,许多防御被证明是无效的或“被破坏的”(Carlini 和 Wagner,2017a;Athalye 等人., 2018 年;Carlini 等人,2019a)。 后一种设置称为自适应白盒攻击设置,它基本上假设在进行对抗性攻击时防御对攻击者是完全透明的(除了一些不可控的随机性)。此设置对于实施实际攻击可能不切实际,但它提供了关于机器学习 24 对抗鲁棒性的真实鲁棒性的诚实(最坏情况)评估 保护模型免受对抗性攻击,超出攻击者和防御者之间信息不对称的优势。否则,有人认为,如果在第一个设置中稳健的模型对自适应攻击不稳健,它们可能会给人一种错误的安全感或稳健感(Carlini 和 Wagner,2017a;Athalye 等,2018;Carlini 等, 2019a).正如 Athalye 等人所讨论的,一个典型的例子是防御带来的所谓“梯度混淆”效应,这种效应由于信息混淆(例如,输入空间中损失景观上的梯度过度平滑或噪声过大)而混淆了基于梯度的攻击。 (2018)。然而,了解防御机制的攻击者可以提出高级方法或采用基于非梯度的攻击来使这些防御失效。卡里尼等人。 (2019a) 提供了许多基于自适应攻击评估对抗性鲁棒性的原则。 例如 C&W 和 EAD,我们使用二分搜索策略来调整系数 λ,正如 Carlini 和 Wagner (2017b) 提出的那样,它平衡了攻击成功和失真。对于 C&W 攻击,我们使用 ℓ2 范数惩罚。对于 EAD 攻击,我们使用混合 ℓ1 2 范数惩罚(即弹性网络范数∥x − x0∥2 x − x0∥1 和 10−3)并根据弹性网络范数选择最佳失真(EN 规则)或ℓ1 范数(ℓ1 规则)。从表 2.1 可以看出,所有 • 超出 ℓp 规范的对抗性攻击包括语义相似的示例,例如颜色空间移动(Hosseini 和 Poovendran,2018 年)和空间变换(例如旋转)(Xiao 等人,2018 年;Engstrom 等人,2019b)。蔡等人。 (2022) 提出了考虑多种攻击类型及其攻击顺序的复合对抗攻击。 白盒对抗性攻击 27 28 机器学习的对抗性鲁棒性 同时考虑多个 ℓp 规范的对抗性攻击(Xu 等人,2019b;Tramer 和 Boneh,2019)。 30 机器学习模型细节的对抗性鲁棒性。在软标签黑盒攻击设置中,攻击者可以观察(部分)类预测及其相关的置信度分数。在硬标签黑盒攻击(基于决策)设置中,攻击者只能观察到 top-1 标签预测,这是保持模型效用所需返回的最少信息。除了攻击成功率,查询效率也是黑盒攻击性能评估的重要指标。 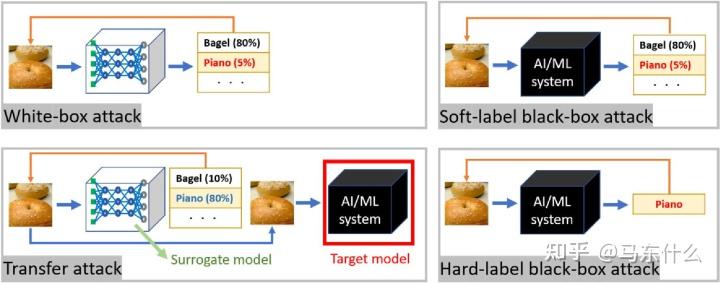 编辑切换为居中 添加图片注释,不超过 140 字(可选) 转移攻击是黑盒攻击的一个分支,它使用从白盒代理模型生成的对抗样本来攻击目标黑盒模型。代理模型可以是预训练的(Liu 等人, 2017b) or distilled from a set of data samples with soft labels given by the target model as their training labels (Papernot et al., 2016, 2017). 2017b) 或从一组数据样本中提取,这些样本具有目标模型给出的软标签作为训练标签 (Papernot et al., 2016, 2017)。 Between the spectrum of white-box and black-box attacks, variations in 在白盒和黑盒攻击的范围之间,变化 the threat models and the attacker’s capability will result in different gray-box attacks. 威胁模型和攻击者的能力会导致不同的灰盒攻击。 黑盒攻击算法通常采用基于惩罚(例如,Eq.(2.9))或基于预算(例如,Eq.(2.1))的公式。由于在黑盒设置中无法获得攻击者损失的输入梯度,一种主要方法是使用模型进行梯度估计 queries and then using the estimated gradient to replace the true gradient in white-box attack algorithms, leading to the zeroth-order optimization (ZOO) based black-box attacks (Chen et al., 2017a). 查询,然后使用估计的梯度代替白盒攻击算法中的真实梯度,导致基于零阶优化(ZOO)的黑盒攻击(Chen 等人,2017a)。 Without loss of generality, it suffices to denote the target model as a classification function parameterized by θ, defined as f 0, 1]d K , that takes a d-dimensional scaled data sample as its input and yields a vector of prediction scores of all K classes, such as the prediction probabilities for each class. The term “soft labels” refers to the fact that an attacker can observe the prediction score of each class. We further consider the case of applying an entrywise monotonic transformation M (f to the output of fθ for black-box attacks, since a monotonic transformation preserves the ranking of the class predictions and can alleviate the problem of large score variation in fθ (e.g., the transformation of probability to log probability is monotonic). 在不失一般性的情况下,只需将目标模型表示为由 θ 参数化的分类函数,定义为 f 0, 1]d K ,它将 d 维缩放数据样本作为其输入并产生预测向量所有 K 个类的分数,例如每个类的预测概率。术语“软标签”指的是攻击者可以观察到每个类别的预测分数。我们进一步考虑将入口单调变换 M (f 应用于黑盒攻击的 fθ 输出的情况,因为单调变换保留了类预测的排名并且可以缓解 fθ 中大分数变化的问题(例如,概率到对数概率的转换是单调的)。 在这里,我们使用基于惩罚的损失来制定软标签黑盒目标攻击。该公式可以很容易地适应无针对性的攻击。设 (x0, t0) 表示自然图像 x0 及其真实类别标签 t0,设 (x, t) 表示 x0 的对抗样本和目标攻击类别标签 t t0。寻找对抗样本的问题可以表述为采用一般形式的优化问题  其中 Dist(x, x0) 测量 x 和 x0 之间的失真,Loss 是一个攻击目标,反映了预测 t k 1,...,K M (f x k, 0 是正则化系数,约束 x 0, 1]d 将对抗图像 x 限制在有效的缩放数据空间中。考虑加性输入扰动的情况,Dist(x, x0) 通常由定义为 Dist(x, x0 x − x0∥p) 的 ℓp 范数进行评估,其中 x − x0 是对 x0 的加性扰动。攻击目标损失 可以是用于分类的训练损失(例如,交叉熵)或基于边距的 C&W 损失(Carlini 和 Wagner,2017b),如第 2 章所述。逐项单调变换函数M常采用对数运算。 |
【本文地址】