关于碎纸片拼接复原的算法研究 |
您所在的位置:网站首页 › 数字纸片 › 关于碎纸片拼接复原的算法研究 |
关于碎纸片拼接复原的算法研究
|
关于碎纸片拼接复原的算法研究
摘要
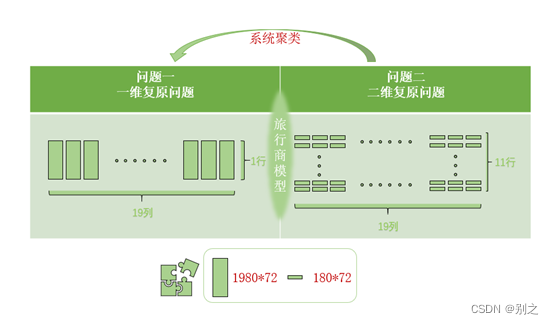
碎纸片的自动拼接技术是一个新兴的课题,也是图像处理与模式识别领域中一个较新却很典型的应用,它通过扫描或者图像提取技术来获得一些碎纸片的形状、颜色等信息,然后利用计算机进行相关的处理分析,从而实现对这些碎纸的拼接复原。当碎纸片数目很少时,可以通过纯手工把它们拼起来,但当其数量达到一定程度甚至几百上千,就会非常耗费人力物力,而且容易对碎纸造成破坏。故利用计算机取代繁琐重复的劳动是行之有效的方法[1]。 本文围绕几种不同类型的碎纸片拼接复原,建立碎纸片距离模型、旅行商模型和聚类分析模型,结合人工干预对几种不同类型的碎纸片拼接复原问题进行分析求解。 针对问题1,首先使用Matlab将碎片导入,将图像数值化,进而二值化,建立每两张碎片左右两侧的Jaccard距离模型,通过碎纸片最左侧的特征找到第一张碎纸片,建立旅行商模型,利用贪心算法确定最邻近距离,取最邻近距离的图片作为邻接图片求解子问题的最优路线,得到碎纸片拼接复原图及碎纸片序列。 针对问题2,首先使用Matlab将碎片导入,将图像数值化,进而二值化,以碎纸片的行平均值作为特征向量,使用Correlation**距离进行ward层次聚类,辅以人工干预,将碎纸片同一行的碎片分为一组,与问题1相同进行建立每两张碎片左右两侧的Jaccard距离模型,通过碎纸片最左侧的特征找到第一张碎纸片,建立旅行商模型,利用Lingo规划算法求最佳哈密尔顿圈**,由于每张碎纸片过小,通过Jaccard距离模型求解的最佳哈密尔顿圈未必正确,需要进行人工干预,找到每张碎片的正确邻接碎片,得到每行的碎纸片拼接复原图及碎纸片序列,再将拼好的行碎片转置,与问题1相似找出拼接顺序,得到总的碎纸片拼接复原图及碎纸片序列。 关键词:二值矩阵;Jaccard距离;旅行商模型;相关距离;系统聚类 目录 关于碎纸片拼接复原的算法研究 摘要 目录 一、问题重述 1.1 问题背景 1.2 目标任务 二、问题分析 2.1 数据分析及预处理 2.2 具体分析 2.1.1 对问题1的分析 2.1.2 对问题2的分析 三、模型假设 四、符号说明 五、模型的建立与求解 5.1 问题1模型建立与求解 5.1.1 特征因子的构建 5.1.2 Jaccard距离的定义 5.1.3 旅行商模型 5.1.4 复原模型以及算法 5.1.5 复原结果 5.2 问题2的模型建立与求解 5.2.1 相关距离 5.2.2 ward层次聚类 5.2.3 改进旅行商模型 5.2.4 确定头碎片 5.2.4 行拼接与列拼接 5.2.5 复原模型以及算法 5.2.6 人工干预 5.2.7 复原结果 5.3 问题1与问题2的区别与联系 六、模型的评价与推广 6.1 模型评价 6.2模型推广 附录 1.问题1 (1)拼接复原图 2.问题2 (1)聚类结果 (2)拼接复原图 (3)源码 一、问题重述 1.1 问题背景破碎文件的拼接在司法物证复原、历史文献修复以及军事情报获取等领域都有着重要的应用。传统上,拼接复原工作需由人工完成,准确率较高,但效率很低。特别是当碎片数量巨大,人工拼接很难在短时间内完成任务。 随着计算机技术的发展,人们试图开发碎纸片的自动拼接技术,以提高拼接复原效率。 1.2 目标任务问题1:对于给定的来自同一页印刷文字文件的碎纸机破碎纸片(仅纵切),建立碎纸片拼接复原模型和算法,并针对附件1、附件2给出的中、英文各一页文件的碎片数据进行拼接复原。如果复原过程需要人工干预,请写出干预方式及干预的时间节点。 问题2:对于碎纸机既纵切又横切的情形,请设计碎纸片拼接复原模型和算法,并针对附件3、附件4给出的中、英文各一页文件的碎片数据进行拼接复原。如果复原过程需要人工干预,请写出干预方式及干预的时间节点。 问题3:上述所给碎片数据均为单面打印文件,从现实情形出发,还可能有双面打印文件的碎纸片拼接复原问题需要解决。附件5给出的是一页英文印刷文字双面打印文件的碎片数据。请尝试设计相应的碎纸片拼接复原模型与算法,并就附件5的碎片数据给出拼接复原结果。 二、问题分析 2.1 数据分析及预处理因为颜色在计算机中用数值表示,故将附件中的每一张bmp碎片用一个矩阵来表示。又碎片的颜色只有黑白灰三种,故建立的矩阵即为灰度矩阵,只要对每张图的灰度矩阵做处理比较即可。 考虑到由于每个字的灰度多种,会使相邻图的一一匹配对数下降,故将灰度矩阵二值化为只有0(黑色像素)和255(白色像素)的矩阵。我们所说的图像的二值化,就是将本题中的灰色像素点转化为白色或者黑色像素点。 2.2 具体分析 2.1.1 对问题1的分析问题1为一维复原问题,仅考虑碎片左右(x轴方向)端的特征即可。 首先需要计算每两张碎片相邻边缘像素列01值的匹配度,寻找与被匹配图存在最高匹配度的碎片,即可判定为被匹配图的相邻碎片。 建立匹配度矩阵后需要找出文章的最左端,由于原文页边距一定为空白部分,所以可以通过碎片最左端的数字特征来寻找,最左端空白区域最多的那张碎片即为文章的最左端。 找出最左端的碎片,并根据每张碎片的最优后继碎片就能以此从左往右拼出全文。 2.1.2 对问题2的分析问题2属于二维复原问题,不仅考虑碎片左右(x轴方向)端特征,还需考虑上下(y轴方向)端特征。 首先我们计算每张碎片的特征向量,使用特征向量进行系统聚类,目的是将208张碎片同为一行的碎片分为一类,共11行。 然后针对每一行碎片进行拼接处理,仍然建立Jaccard距离矩阵,此时问题从二维转换为一维,但由于碎片较之问题1的碎片在高度上大大减小,故需使用更加精确的寻找最左端碎片、寻找后继碎片方法。
图 2.1.1 问题分析 三、模型假设假设文章为黑白双色打印。破碎文件形状规则,大小一致。 假设不存在字迹缺失问题。 假设人工干预时的每次判断均是正确的,不存在手误问题。 碎片进行了横向及纵向切割,假设在切割之后,图像不存在平移、旋转、缩放等多种变换,图像边界平滑,像素信息保持完整[2]。 四、符号说明本文涉及到的主要变量符号说明: 表格 1符号说明
注:未说明的变量以其在符号出现处的具体解释为准。 五、模型的建立与求解 5.1 问题1模型建立与求解 5.1.1 特征因子的构建为了叙述以及编程的方便,在分析过程中给予附件碎片新编号,附件的碎片编号去除无效0位后统一加上1作为新编号,如 汉字是由各种特定的点和线构成的,在笔画上有一定的连续性。本文算法就是基于文字的连续性,对碎片像素矩阵的最左侧和最右侧的列向量做相关,遍历所有图片寻找相关度最大的那张[3]。 碎片
旅行商问题(Traveling Salesman Problem,TSP),是最基本的路线问题,单一旅行者由起点出发,通过所有给定的需求点之后,最后再回到原点,需要求出最短距离。可以从距离矩阵中产生一个近似最佳解的途径,有节省法、插入法、途程改善法、合成启发法等求解途径。 使用Jaccard距离建立距离矩阵d,利用贪心算法确定最邻近距离,取最邻近距离的图片作为邻接图片,利用贪心算法继续求解子问题的最优路线。得到排序结果 step1:将19张碎片导入,建立一个矩阵 step2:使用19张碎片的灰度矩阵得到对应的二值矩阵,并将其存放在集合 step3:建立一个用于存放各碎片最左端和最右端的二值矩阵 step4:计算每两张不同碎片间的Jaccard距离,并定义一个矩阵 step5:利用最优化的方法为第 张图向右找到它的最优匹配第
step6:算出19张碎片最左端的留白长度,得到长度最大的碎片即为原图最左端的碎片,编号为 step7:根据
step8:根据 图 5.1.1 问题1复原模型流程图 5.1.5 复原结果以下给出附件1和附件2的复原图片拼接序号。 表格 2问题1附件1图片拼接序号 8 14 12 15 3 10 2 16 1 4 5 9 13 18 11 7 17 0 6 表格 3问题1附件2图片拼接序号 3 6 2 7 15 18 11 0 5 1 9 13 10 8 12 14 17 16 4 5.2 问题2的模型建立与求解 5.2.1 相关距离Correlation距离主要用来度量每两个碎片特征向量的线性相关程度。
将每个碎片的行平均值作为特征向量,相关系数是衡量两个碎片之间特征向量之间相关程度的一种方法,取值范围 。相关系数的绝对值越大,表明碎片X和Y的相关程度越高。当取值为1时表明正线性相关,-1时表明负线性相关。 5.2.2 ward层次聚类对灰度图像或彩色图像中的相似灰度或色度合并的方法称之为聚类,通过聚类将图像表示为不同区域即所谓的聚类分割方法。此方法的实质是将图像分割问题转化为模式识别的聚类分析[5]。 聚类和分类不同,聚类是根据数据特征的不同而将数据划分为若干个簇或类,其所要求划分的类是未知的。通常聚类问题被看作是一种优化问题,用于对目标函数或者准则函数进行优化[6]。 聚类分析以相似性为基础,在一个聚类中的模式之间比不在同一聚类中的模式之间具有更多的相似性。对碎纸片进行拼接复原,每一行具有较高的相似性,通过层次聚类中的ward方法将208张碎纸片分为11组,通过人工干预将碎纸片均分。 Ward聚类过程: ① 计算每个cluster的ESS:
② 计算合并每两个cluster后总的ESS。 ③ 取合并后ESS最小的两个cluster进行合并,重复上述步骤直到合并完所有cluster。 5.2.3 改进旅行商模型由于问题1中每个碎片大小为
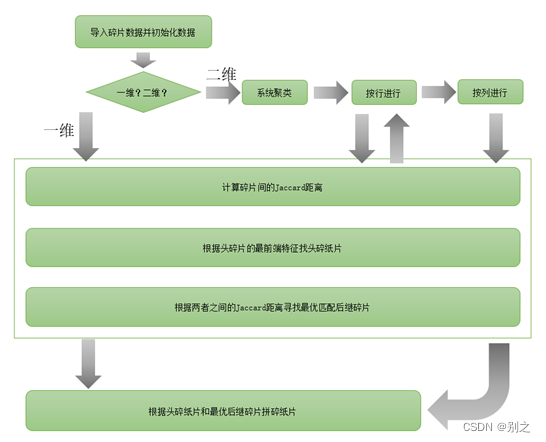
图 5.2.1 问题2复原模型流程图 5.2.6 人工干预由于纸片较小,将碎片的行平均值作为特征向量和两碎片间Jaccard距离的定义未必能准确反应原来的情况,这是对结果作为人为干预,使拼接效果更好。 1.聚类误差 找出类元素个数大于19的类,找出不属于该类中的元素,将其移动到元素个数小于19的类中,使所有类的类元素个数均为19。 2.后继元素误差 观察找出不能完美衔接的图片,改变前一张碎片的后继元素值,重复进行此操作,直至肉眼无法观察明显错位为止。 5.2.7 复原结果以下给出附件3和附件4的复原图片拼接序号,其聚类结果分布见附件。 表格 4问题2附件3图片拼接序号 1412831598219913512731602031691343931511071151769434841839047121421241447711214997136164127584312513182109197161841101876610615021173157181204139145296411120159218048377555442061010498172171597208138158126681754517401375356931537016632196891461021541144015120715514018510811741011131941191234954651431862571921781181909512928911881411122611978676999162961317963116163726177205236168100766214230412314719150179120861952618718381484616124358118912210313019388167258910574711568313220017803320219815133170205851521652760表格 5问题2附件4图片拼接序号 1917511154190184210418064106414932204653967147201148170196198941131647810391801012610061728146865110729401581869824117150559589230374612719194931418812112610515511417618215122572027116582159139112963138153533812312017585501601879720331204110811613673362071351576431994517379161179143208217496111933142168621695419213311818916219711270846014681741371958471721569623991229018510913218195691671631661881111442063130341311025271781714266205101577414583134551856351691831524481771282001315212514019387894872121771240102115 5.3 问题1与问题2的区别与联系问题1为一维复原问题,仅考虑碎片左右(x轴方向)端的特征即可;问题2属于二维复原问题,不仅考虑碎片左右(x轴方向)端特征,还需考虑上下(y轴方向)端特征;且问题2碎片较之问题1的碎片在高度上大大减小,故需使用更加精确的寻找最左端碎片、寻找后继碎片方法。 下面用流程图直观地表达该两个问题算法大致步骤。
图 5.3.1 问题1、2的算法大致流程 六、模型的评价与推广 6.1 模型评价本文中的模型对于解决纵向碎纸片拼接问题,其正确率能达到100%,拼接效果较好,且不需要人工干预。 对于问题二中的横纵切割的碎纸片拼接问题,在无人工不预的情况下,具有一定的拼接误差,需要通过人工协助分类以及排序,其拼接效果不是很好。 对于以上两个种类型的拼接问题,中文拼接成功率大于英文拼接成功率。 6.2模型推广本文种所介绍的碎纸片拼接问题高限在方近切割上,但在现实生活中,往往纵向垂直的切割和横向水平的切割很难做到,因此在本文的基础上,可以考虑斜向切割的碎纸片拼接问题,通过将斜向的碎纸片摆正等操作,将问题转换为本文的水平与竖直切割的醉纸片拼接问题。 本文的碎纸片字迹残边非常清晰,但在现实生活中,一般通过切割的碎纸片的边缘将会存在“毛刺”,使得识别碎纸片的字迹残边的准确率大大降低,因此,可以在本文的基础上对图片进行降噪处理,使其能够处理更为一般的切割情形。 七、参考文献 [1].刘威,王军民,刘克勤.基于边缘匹配的纵向碎纸拼接方法[J].计算机与现代化,2019(02):55-59. [2].曾晓晶,樊斌.基于规则形状的碎纸片自动拼接技术研究[J].信息与电脑(理论版),2015(24):115-116+119. [3].刘亚威,王军民,刘威.基于相关矩阵的纵向碎纸拼接方法[J].计算机与现代化,2019(10):43-47. [4].崔婧. 基于Jaccard的植物叶片图像识别方法研究[D].兰州大学,2021.DOI:10.27204/d.cnki.glzhu.2021.000738. [5].贾海燕. 碎纸自动拼接关键技术研究[D].国防科学技术大学,2005. [6].侯颖,何翼,刘合财.基于聚类分析的规则文字碎片拼接技术研究[J].贵阳学院学报(自然科学版),2014,9(04):18-19.DOI:10.16856/j.cnki.52-1142/n.2014.04.006. 附录 1.问题1 (1)拼接复原图 附件1附件2  (2)源码
%% I. 清空环境
clear
clc
close all
%% II. 导入bmp格式图片,基于阈值将图像转换为二值图像,取二值图像前后各一列
for i = 0:18
if i
(2)源码
%% I. 清空环境
clear
clc
close all
%% II. 导入bmp格式图片,基于阈值将图像转换为二值图像,取二值图像前后各一列
for i = 0:18
if i |



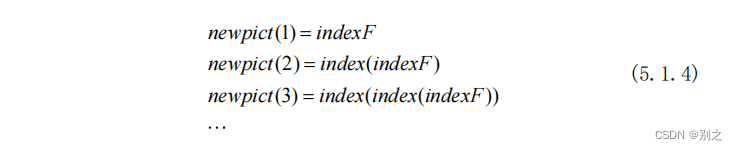

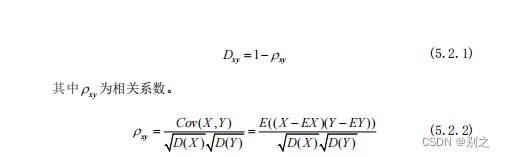
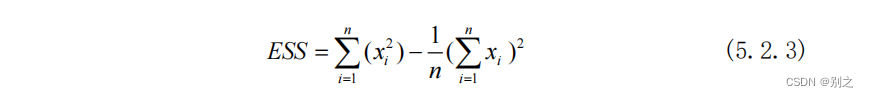





【本文地址】