Hive面试题汇总(2021) |
您所在的位置:网站首页 › 数仓SQL面试题及答案 › Hive面试题汇总(2021) |
Hive面试题汇总(2021)
|
Hive面试汇总(2021)
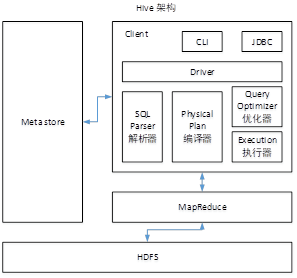
1. 简述Hive主要架构及解析成MR的过程
Hive元数据默认存储在derby数据库,不支持多客户端访问,所以需要将元数据存储在MySQL中,才支持多客户端访问。主要架构如下:
Hive解析成MR的过程: Hive通过给用户提供一系列交互接口,接收到用户的指令(sql语句),结合元数据(metastore),经过Driver内的解析器,编译器,优化器,执行器转换成mapreduce(将sql转换成抽象语法树AST的解析器,将AST编译成逻辑执行计划的编译器,在对逻辑执行计划进行优化的优化器,最后将逻辑执行计划转换成mapreduce),提交给hadoop中执行,最后将执行返回的结果输出到用户交互接口。 2. Hive与传统数据库的区别Hive和数据库除了拥有类型的查询语言外,无其他相似 存储位置:Hive数据存储在HDFS上。数据库保存在块设备或本地文件系统 数据更新:Hive不建议对数据改写。数据库通常需要经常修改 执行引擎:Hive通过MapReduce来实现。数据库用自己的执行引擎 执行速度:Hive执行延迟高,但它数据规模远超过数据库处理能力时,Hive的并行计算能力就体现优势了。数据库执行延迟较低 数据规模:hive大规模的数据计算。数据库能支持的数据规模较小 扩展性:Hive建立在Hadoop上,随Hadoop的扩展性。数据库由于ACID语义[wh1] 的严格限制,扩展有限 3. Hive内部表和外部表的区别 存储:外部表数据由HDFS管理;内部表数据由hive自身管理 存储:外部表数据存储位置由自己指定(没有指定location则在默认地址下新建);内部表数据存储在hive.metastore.warehouse.dir(默认在/uer/hive/warehouse) 创建:被external修饰的就是外部表;没被修饰是内部表 删除:删除外部表仅仅删除元数据;删除内部表会删除元数据和存储数据 4. Hive中order by,sort by,distribute by和cluster by的区别 order by:对数据进行全局排序,只有一个reduce工作 sort by:每个mapreduce中进行排序,一般和distribute by使用,且distribute by写在sort by前面。当mapred.reduce.tasks=1时,效果和order by一样 distribute by:类似MR的Partition,对key进行分区,结合sort by实现分区排序 cluster by:当distribute by和sort by的字段相同时,可以使用cluster by代替,但cluster by只能是升序,不能指定排序规则在生产环境中order by使用的少,容易造成内存溢出(OOM) 生产环境中distribute by和sort by用的多 5. row_number(),rank()和dense_rank()的区别都有对数据进行排序的功能 row_number():根据查询结果的顺序计算排序,多用于分页查询 rank():排序相同时序号重复,总序数不变 |
【本文地址】
今日新闻 |
推荐新闻 |