Yolov8改进:用于微小目标检测的上下文增强和特征细化网络ContextAggregation,助力小目标检测 |
您所在的位置:网站首页 › 改进YOLOv8的水面小目标检测算法 › Yolov8改进:用于微小目标检测的上下文增强和特征细化网络ContextAggregation,助力小目标检测 |
Yolov8改进:用于微小目标检测的上下文增强和特征细化网络ContextAggregation,助力小目标检测
|
1.Context Aggregation介绍  论文:https://arxiv.org/abs/2106.01401 摘要 卷积神经网络(CNNs)在计算机视觉中无处不在,具有无数有效和高效的变化。最近,Container——最初是在自然语言处理中引入的——已经越来越多地应用于计算机视觉。早期的用户继续使用CNN的骨干,最新的网络是端到端无CNN的Transformer解决方案。最近一个令人惊讶的发现表明,一个简单的基于MLP的解决方案,没有任何传统的卷积或Transformer组件,可以产生有效的视觉表示。虽然CNN、Transformer和MLP-Mixers可以被视为完全不同的架构,但我们提供了一个统一的视图,表明它们实际上是在神经网络堆栈中聚合空间上下文的更通用方法的特殊情况。我们提出了Container(上下文聚合网络),一个用于多头上下文聚合的通用构建块,它可以利用Container的长期交互作用,同时仍然利用局部卷积操作的诱导偏差,导致更快的收敛速度,这经常在CNN中看到。我们的Container架构在ImageNet上使用22M参数实现了82.7%的Top-1精度,比DeiT-Small提高了2.8,并且可以在短短200个时代收敛到79.9%的Top-1精度。比起相比的基于Transformer的方法不能很好地扩展到下游任务依赖较大的输入图像的分辨率,我们高效的网络,名叫CONTAINER-LIGHT,可以使用在目标检测和分割网络如DETR实例,RetinaNet和Mask-RCNN获得令人印象深刻的检测图38.9,43.8,45.1和掩码mAP为41.3,与具有可比较的计算和参数大小的ResNet-50骨干相比,分别提供了6.6、7.3、6.9和6.6 pts的较大改进。与DINO框架下的DeiT相比,我们的方法在自监督学习方面也取得了很好的效果。 仅需22M参数量,所提CONTAINER在ImageNet数据集取得了82.7%的的top1精度,以2.8%优于DeiT-Small;此外仅需200epoch即可达到79.9%的top1精度。不用于难以扩展到下游任务的Transformer方案(因为需要更高分辨率),该方案CONTAINER-LIGHT可以嵌入到DETR、RetinaNet以及Mask-RCNN等架构中用于目标检测、实例分割任务并分别取得了6.6,7.6,6.9指标提升。 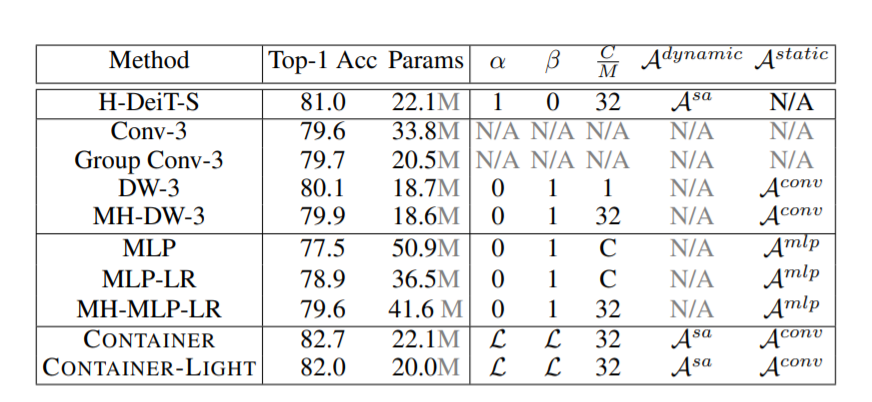 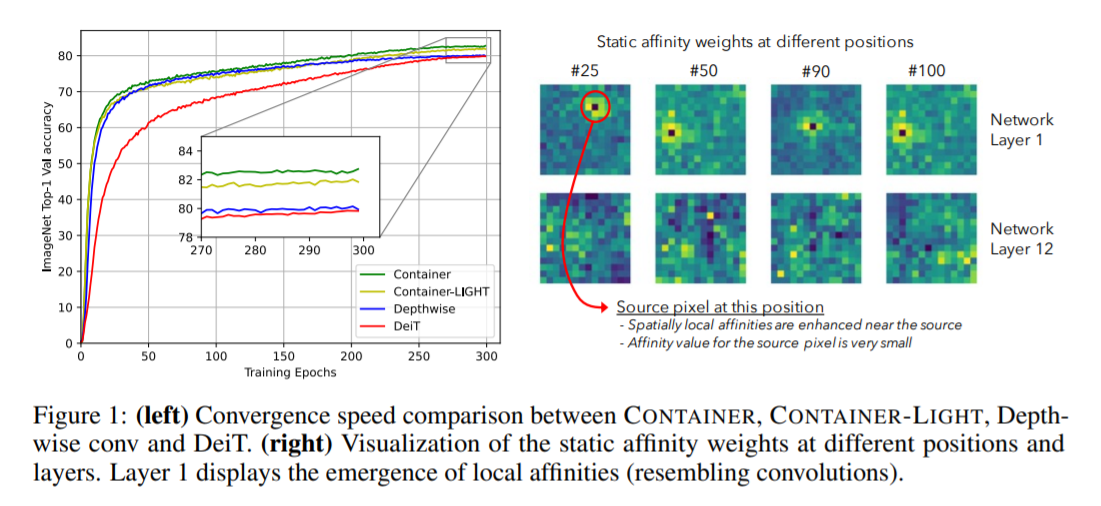 提供了一个统一视角表明:它们均是更广义方案下通过神经网络集成空间上下文信息的特例。我们提出了CONTAINER(CONText AggregatIon NEtwoRK),一种用于多头上下文集成(Context Aggregation)的广义构建模块 。 本文有以下几点贡献: 提出了关于主流视觉架构的一个统一视角;提出了一种新颖的模块CONTAINER,它通过可学习参数和响应的架构混合使用了静态与动态关联矩阵(Affinity Matrix),在图像分类任务中表现出了很强的结果;提出了一种高效&有效的扩展CONTAINER-LIGHT在检测与分割方面取得了显著的性能提升。2. Yolov8引入ContextAggregation2.1 修改modules.py中核心代码: class ContextAggregation(nn.Module): """ Context Aggregation Block. Args: in_channels (int): Number of input channels. reduction (int, optional): Channel reduction ratio. Default: 1. conv_cfg (dict or None, optional): Config dict for the convolution layer. Default: None. """ def __init__(self, in_channels, reduction=1): super(ContextAggregation, self).__init__() self.in_channels = in_channels self.reduction = reduction self.inter_channels = max(in_channels // reduction, 1) conv_params = dict(kernel_size=1, act_cfg=None) self.a = ConvModule(in_channels, 1, **conv_params) self.k = ConvModule(in_channels, 1, **conv_params) self.v = ConvModule(in_channels, self.inter_channels, **conv_params) self.m = ConvModule(self.inter_channels, in_channels, **conv_params) self.init_weights() def init_weights(self): for m in (self.a, self.k, self.v): caffe2_xavier_init(m.conv) constant_init(self.m.conv, 0) def forward(self, x): #n, c = x.size(0) n = x.size(0) c = self.inter_channels #n, nH, nW, c = x.shape # a: [N, 1, H, W] a = self.a(x).sigmoid() # k: [N, 1, HW, 1] k = self.k(x).view(n, 1, -1, 1).softmax(2) # v: [N, 1, C, HW] v = self.v(x).view(n, 1, c, -1) # y: [N, C, 1, 1] y = torch.matmul(v, k).view(n, c, 1, 1) y = self.m(y) * a return x + y |
【本文地址】