机器学习(三) |
您所在的位置:网站首页 › 支持向量机回归的基本思想 › 机器学习(三) |
机器学习(三)
|
针对支持向量机和神经网络问题参考了多方面资料,整合如下: 支持向量机的概念: 在统计学习理论中发展起来的支持向量机(Support Vector Machines, SVM)方法是一种新的通用学习方法,表现出理论和实践上的优势。 SVM在非线性分类、函数逼近、模式识别等应用中有非常好的推广能力,摆脱了长期以来形成的从生物仿生学的角度构建学习机器的束缚。此外,基于SVM的快速迭代方法和相关的简化算法也得到发展。 与神经网络相比,支持向量机方法具有更坚实的数学理论基础,可以有效地解决有限样本条件下的高维数据模型构建问题,并具有泛化能力强、收敛到全局最优、维数不敏感等优点。 目前,统计学习理论和SVM已经成为继神经网络之后机器学习领域最热门的研究方向之一,并有力推动了机器学习理论的发展。SVM已被初步研究使用在核天线阵列处理的波束成形,智能天线系统的波达角估计,盲均衡器的设计;盲波束成形器设计。 支持向量机中分类和预测: SVM分类,就是找到一个平面,让两个分类集合的支持向量或者所有的数据(LSSVM)离分类平面最远; SVR回归,就是找到一个回归平面,让一个集合的所有数据到该平面的距离最近。 SVR是支持向量回归(support vector regression)的英文缩写,是支持向量机(SVM)的重要的应用分支。 支持向量机和神经网络的对比: 二者在形式上有几分相似,但实际上有很大不同。 简而言之,神经网络是个“黑匣子”,优化目标是基于经验风险最小化,易陷入局部最优,训练结果不太稳定,一般需要大样本; 而支持向量机有严格的理论和数学基础,基于结构风险最小化原则, 泛化能力优于前者,算法具有全局最优性, 是针对小样本统计的理论。 目前来看,虽然二者均为机器学习领域非常流行的方法,但后者在很多方面的应用一般都优于前者。 SVM 就是个分类器,它用于回归的时候称为SVR(Support Vector Regression),SVM和SVR本质上都一样。下图就是SVM分类: 神经网络和支持向量机的优缺点对比: 1、神经网络优缺点 优点: 神经网络有很强的非线性拟合能力,可映射任意复杂的非线性关系,而且学习规则简单,便于计算机实现。具有很强的鲁棒性、记忆能力、非线性映射能力以及强大的自学习能力,因此有很大的应用市场。 缺点: (1)最严重的问题是没能力来解释自己的推理过程和推理依据。 (2)不能向用户提出必要的询问,而且当数据不充分的时候,神经网络就无法进行工作。 (3)把一切问题的特征都变为数字,把一切推理都变为数值计算,其结果势必是丢失信息。 (4)理论和学习算法还有待于进一步完善和提高。 2、SVM的优缺点 优点: (1)非线性映射是SVM方法的理论基础,SVM利用内积核函数代替向高维空间的非线性映射; (2)对特征空间划分的最优超平面是SVM的目标,最大化分类边际的思想是SVM方法的核心; (3)支持向量是SVM的训练结果,在SVM分类决策中起决定作用的是支持向量. (4)SVM 是一种有坚实理论基础的新颖的小样本学习方法.它基本上不涉及概率测度及大数定律等,因此不同于现有的统计方法.从本质上看,它避开了从归纳到演绎的传统过程,实现了高效的从训练样本到预报样本的“转导推理”,大大简化了通常的分类和回归等问题. (5)SVM 的最终决策函数只由少数的支持向量所确定,计算的复杂性取决于支持向量的数目,而不是样本空间的维数,这在某种意义上避免了“维数灾难”. (6)少数支持向量决定了最终结果,这不但可以帮助我们抓住关键样本、“剔除”大量冗余样本,而且注定了该方法不但算法简单,而且具有较好的“鲁棒”性.这种“鲁棒”性主要体现在: ①增、删非支持向量样本对模型没有影响; ②支持向量样本集具有一定的鲁棒性; ③有些成功的应用中,SVM 方法对核的选取不敏感 缺点: (1) SVM算法对大规模训练样本难以实施 由于SVM是借助二次规划来求解支持向量,而求解二次规划将涉及m阶矩阵的计算(m为样本的个数),当m数目很大时该矩阵的存储和计算将耗费大量的机器内存和运算时间.针对以上问题的主要改进有有J.Platt的SMO算法、T.Joachims的SVM、C.J.C.Burges等的PCGC、张学工的CSVM以及O.L.Mangasarian等的SOR算法 (2) 用SVM解决多分类问题存在困难 经典的支持向量机算法只给出了二类分类的算法,而在数据挖掘的实际应用中,一般要解决多类的分类问题.可以通过多个二类支持向量机的组合来解决.主要有一对多组合模式、一对一组合模式和SVM决策树;再就是通过构造多个分类器的组合来解决.主要原理是克服SVM固有的缺点,结合其他算法的优势,解决多类问题的分类精度.如:与粗集理论结合,形成一种优势互补的多类问题的组合分类器。 总结: 神经网络的优势要在数据量很大,计算力很强的时候才能体现,数据量小的话,很多任务上的表现都不是很好。 SVM属于非参数方法,拥有很强的理论基础和统计保障。损失函数拥有全局最优解,而且当数据量不大的时候,收敛速度很快,超参数即便需要调整,但也有具体的含义,比如高斯kernel的大小可以理解为数据点之间的中位数距离(Median heuristic)。在神经网络普及之前,引领了机器学习的主流,那时候理论和实验都同样重要。 |
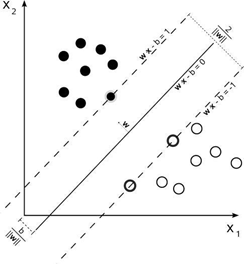 SVM的目的:寻找到一个超平面使样本分成两类,并且间隔最大。
SVM的目的:寻找到一个超平面使样本分成两类,并且间隔最大。【本文地址】
今日新闻 |
推荐新闻 |