python课程设计@爬取携程网信息并进行可视化 |
您所在的位置:网站首页 › 携程课程 › python课程设计@爬取携程网信息并进行可视化 |
python课程设计@爬取携程网信息并进行可视化
|
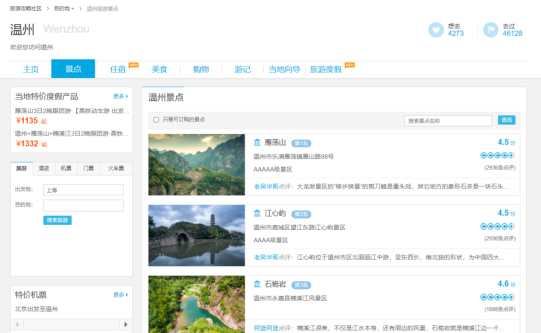
完成日期: 2021年6月18日 目录一、设计主题及功能介绍1.1 设计主题1.2 功能介绍二、采用的关键技术阐述2.1 requests库 ——获取网页内容2.2 BeautifulSoup4 库 ——网页内容查找[1]2.3 json库 ——字典和json对象转化2.4 tkinter库 ——GUI界面设计2.5 threading库、queue库 ——多线程爬虫[4]2.6 Pandas、Numpy库 —— 数据处理2.7 random库 —— 产生随机数[6]2.8 wordcloud库 —— 生成词云[7]2.9 Pyecharts库——将数据加载到地图的可视化方式三、实现的重点与难点3.1整体设计思路3.2 爬取某个地区所有景区信息——设计 Crawler_all_place类3.3 爬取某个景区的所有信息——设计Crawler_a_place.py类3.3 爬取单个景区所有评论——设计Crawler_comments.py类3.4 多线程爬虫初始化所有地区信息——设计Crawler_threading类3.5 UI界面设计 —— tkinter模块3.5.1 页面布局的选择——place 绝对布局3.5.2 多窗口的动态切换思路3.5.3 ui窗口类和爬虫类的衔接3.5.4 实现三个选择评论量、评分(即顺序推荐)与随机推荐互斥3.6 数据可视化之词云展示以及地图展示3.6.1 词云展示——wordcloud库3.6.2 地图可视化——pyecharts库4.3 选择推荐方式界面4.4 最终显示:当前景区全功能界面4.4.1 界面切换——返回、主页按钮4.4.2 景区切换——刷新按钮(显示爬虫结果)4.4.3 景区汇总——导出excel按钮(导出爬虫结果)4.4.4 获取评论、评分、排名的数据——评论、评分详情按钮4.4.5 生成词频统计后的词云 —— 查看词云按钮4.4.6 数据可视化地图——查看分析按钮五、总结、展望与待优化的地方5.1 总结与展望5.2 存在的不足与待优化的地方六、参考资料七、附件:原始代码 一、设计主题及功能介绍 1.1 设计主题早在2010年前后,全球就迎来了第三次信息化浪潮,全面进入了信息爆炸的时代。在互联网上,自媒体用户量、作品量成指数级增长。智能手机随处可见,极大多数人会用抖音、知乎、B站等手机社交应用作为娱乐放松的方式。 渐渐地,这样的生活方式悄然地改变了我们的生活,比如在平台上看到某位喜欢的关注者在进行直播带货,这时候就会有人选择支持一下,买下那个商品,尽管有时候自己并不是非常需要,又或者是看到旅游的Vlog,看到Vlog里的拍摄者非常欢快,自己也想去那个地方体验一下......这样的”从众心理”是很正常的,因为信息量过大,我们有时候无法很快做出决定,比如在即将到来的假期,我们想要去旅行,却不知道该去哪个景区,针对这种情况,本次报告就通过设计python程序,使用其中的部分官方库和部分第三方库,基于爬虫技术,数据来自携程网站的旅游信息,针对用户实现一款能够推荐旅游景区的小应用。其中囊括了对携程网的各类旅游相关信息进行数据采集、数据清洗、数据分析以及可视化等功能。 1.2 功能介绍1.提供友好的UI界面,用户可以点击各种按钮来产生不同的效果 2.以用户为主,为用户提供评论量、评分两种指标,最终可根据这两个指标推荐景区 3.爬取携程网某个城市的所有景区信息 4.爬取携程网某个景区的所有信息 5.对某个景区的评论进行词频统计并生成词云 6.可视化生成今年第一季度国内旅游行业游客量的地图 二、采用的关键技术阐述 2.1 requests库 ——获取网页内容Requests库是用python语言基于urllib编写的,采用的是Apache2 Licensed开源协议的HTTP库。与urllib相比,Requests更加方便,可以节约我们大量的工作。该库提供了python程序与http网络交互的接口,在整个项目中主要用该模块来爬取网站上的内容,分别通过get方式爬取单个地区的所有景区信息、景区的所有信息和post方式爬取景区的所有评论信息。 昂 2.2 BeautifulSoup4 库 ——网页内容查找[1]BeautifulSoup是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式。BeautifulSoup对象表示的是一个文档的全部内容.大部分时候,可以把它当作Tag对象,它支持遍历文档树和搜索文档树中描述的大部分的方法.find_all()方法搜索当前tag的所有tag子节点,并判断是否符合过滤器的条件,按照CSS类名搜索tag的功能非常实用,但标识CSS类名的关键字class在Python中是保留字,使用class做参数会导致语法错误.从Beautiful Soup的4.1.1版本开始,可以通过class_参数搜索有指定CSS类名的tag,这一点非常关键,有了find_all方法就可以查找html文本中指定的类名标签,比如... ,这里根据comment关键字可以看出,该标签存储的是和评论相关的信息,这使我们爬虫时节约了大量的时间来查找需要的内容,只需要指定类名形如find_all(‘.comment’) 这样的格式就能爬取到想要的信息。 2.3 json库 ——字典和json对象转化Json全称是JavaScript Object Notation, 称作JS 对象简谱,是一种轻量级的数据交换格式。它基于 ECMAScript (欧洲计算机协会制定的js规范)的一个子集,采用完全独立于编程语言的文本格式来存储和表示数据。简洁和清晰的层次结构使得 JSON 成为理想的数据交换语言[2]。 易于人阅读和编写,同时也易于机器解析和生成,并有效地提升网络传输效率。以下是json格式的一个范例: { "name": "中国", "province": [{ "name": "黑龙江", "cities": { "city": ["哈尔滨", "大庆"] } }, { "name": "广东", "cities": { "city": ["广州", "深圳", "珠海"] } }] }可以观察出和Python的字典类似,所以本次报告中主要就是拿该模块进行python字典型和json文本型的数据交换。在requests模块提交post请求时,其中header参数可以直接为python的字典对象,而传入data参数时必须为json对象,所以就需要用到该模块的dumps方法,将python对象转化为json文本,而post方式返回的json文本也可以转化成python型的字典,调用load方法即可. 2.4 tkinter库 ——GUI界面设计Tkinter模块(Tk接口)是Python的标准Tk GUI工具包的接口.Tk 和Tkinter 可以在大多数的 Unix平台下使用,同样可以应用在Windows和Macintosh系统里。Tk8.0的后续版本可以实现本地窗口风格,并良好地运行在绝大多数平台中[3]。除了tkinter库以外,python还有其他两个常用GUI库,分别是wxPython、jython前者是一款开源软件,可设计出优美的图形界面兼容多个系统平台,后者保证程序可以和java无缝集成。 在本次报告中主要用到tkinter的组件有: 组件名 描述 实际运用 Frame 框架控件: 在屏幕上显示一个矩形区域,多用来作为容器 创建多个窗口,容纳其他的组件 Label 标签控件:可以显示文本和位图 显示提示的文本信息以及图片,为用户提供良好的交互体验 Button 按钮空间:在程序中显示按钮 方便用户根据提示进行下一步操作,按钮可以触发事件 Checkbutton 多选框空间:用在程序中提供多项选择框 在用户选择推荐方式时需要的组件 tkMessageBox 用于显示应用程序的消息框 弹窗提示 2.5 threading库、queue库 ——多线程爬虫[4]多线程类似于同时执行多个不同程序,多线程运行有如下特点: 可把占据长时间的程序任务放到后台去处理 加快程序的运行速度 线程不能够独立执行,必须依存在应用程序中,由应用程序提供多个线程执行控制。 每个线程都有自己的一组CPU寄存器,称为线程的上下文,它反映了线程上次运行该线程的CPU寄存器的状态。 线程可以被抢占(中断)。 在其他线程正在运行时,线程可以暂时搁置(也称为睡眠) 即线程的退让。Python的Queue库中提供了同步的、线程安全的队列类,包括FIFO(先入先出)队列Queue,LIFO(后入先出)队列LifoQueue,和优先级队列PriorityQueue。这些队列都实现了锁原语,能够在多线程中直接使用。可以使用队列来实现线程间的同步,本次报告主要用到FIFO(先入先出)队列Queue。 基于以上的库可以将爬虫的过程细分为两个阶段: 第一阶段,爬取网页内容,第二阶段,解析网页内容,这两个阶段在一定的条件下可以进行多线程运行,比如在第一阶段有10个网页待爬取,而当爬取了第1个网页后,第二个阶段解析网页内容就可以开始,而无需等待全部网页获取完毕后才开始进行解析,基于这样的思路,可以提高爬虫以及解析的速度。 2.6 Pandas、Numpy库 —— 数据处理Pandas库全称Python Data Analysis Library 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。pandas提供了大量能使我们快速便捷地处理数据的函数和方法[5]。可以认为Pandas库是使Python成为强大而高效的数据分析环境的重要因素之一。 在本次报告中需要实现对全国旅游信息数据的处理以及可视化、其中的处理阶段就需要用到Pandas库中的Dataframe对象,该对象提供方法read_excel(),可以在获取数据时将excel文件转化成python的Dataframe对象,从而进行数据处理,比如提取想要的一列数据,或者是对某一列数据进行排序。 2.7 random库 —— 产生随机数[6]Random库可以返回一个随机数,这对本次报告中随机推荐景区做出了重要贡献,在一切准备就绪后,所有的景区信息都保存到了一个DataFrame对象或者一个List列表里,为了实现出现随机的景区,我们需要对下标进行随机化处理,先随机化产生一个下标,调用randInt(a, b)方法就可以产生一个[a, b) 范围的随机数,接着在根据对应的数据类型取数据即可。 2.8 wordcloud库 —— 生成词云[7]WordClout库是一个词云展示的第三方库,它具有的特点如下: 官方 filling all available space. being able to use arbitraty masks. having a stupid simple algorithm (with an efficient implementation) that can be easily modified. being in Python自译 填充所有空间 可以使用仲裁掩码 非常简单的算法(伴随有效的实现)便于修改 基于python另外, wordcloud 库把词云当作一个WordCloud对象,而wordcloud.WordCloud()代表一个文本对应的词云,可以根据文本中词语出现的频率等参数绘制词云,绘制词云的形状、尺寸和颜色均可设定,以某个图片作为背景进行词云展示。 在本次报告主要用于展示景区的评论,通过展示游客评论的高频词汇,用户可以非常直观地观察到一个景区的评价情况,方便用户选择。 2.9 Pyecharts库——将数据加载到地图的可视化方式Echarts 是一个由百度开源的数据可视化,凭借着良好的交互性,精巧的图表设计,得到了众多开发者的认可。而 Python 是一门富有表达力的语言,很适合用于数据处理。当数据分析遇上数据可视化时,pyecharts 诞生了[8]。 特点:简洁的 API 设计,使用如丝滑般流畅,支持链式调用、囊括了 30+ 种常见图表,应有尽有、支持主流 Notebook 环境,Jupyter Notebook 和 JupyterLab、可轻松集成至 Flask,Django 等主流 Web 框架、高度灵活的配置项,可轻松搭配出精美的图表、详细的文档和示例,帮助开发者更快的上手项目、多达 400+ 地图文件以及原生的百度地图,为地理数据可视化提供强有力的支持。 本次报告就使用该库对2021年第一季度国内大陆各省份景区每日游客量的数据进行了一个地图可视化。 三、实现的重点与难点 3.1整体设计思路(1)设计交互UI界面类——基于python tkinter库,它可以创建组件的有窗口,按钮、图片标签、文字标签等,实现用户和程序的友好交互,另外按钮可以添加对应的事件处理,在按钮被单击后可以执行一系列操作,比如在单击按钮后,显示出一张景区的图片,再单击一次就显示另一个景区的图片,这和web访问有什么区别?在web网站上用户可以直接看到所有的景区信息,但是因为信息过多,用户肯定会难以抉择,面对众多选择根本难以决策,而本次项目则有效地解决这个问题,基于tkinter库建立起一个较完整的景区分析可视化窗口,使得用户接受的信息量更为集中、有效。 (2)设计爬虫类——基于requests库、beautisoup库和json库实现对网页内容的提取及美化,用re库即正则表达式提取需要的内容。可以在UI界面类中创建爬虫类,这样就可以在UI界面中实现爬虫的一系列操作,将爬虫的有效信息展现在ui窗口上。 (3)数据分析及可视化——基于jieba、wordcloud库,对评论进行分词、编写代码进行词频统计后可绘制出词云图。基于pyecharts库生成可视化的中国地图 3.2 爬取某个地区所有景区信息——设计 Crawler_all_place类该类实现对如下图网页的景区信息爬取
图. 携程温州地区的景区页面 Crawler_all_place类的主要设计构造如下: 方法名称 返回值 描述 init(self, url, placeId) self 初始化,保存当前地区的id号,并调用下方的initResource方法获取bs对象 initResource(self, url) None get获取url的网页内容, 并用bs构造方法,进行html分析 getName(self) List 获取当前地区所有景区名称 getRank(self) List 获取排名 getAddress(self) List 获取地址 getComment(self) List 获取热评 getScore(self) List 获取评分 getAllImageLink(self) List 获取图片链接 getLink(self) List 获取景区对应网址 getPagenum(self) Int 获取地区的景区页数 getNum(self) Int 获取地区的景区个数 getAllPageAll(self) DataFrame 获取前百个景区信息,保存数据到self.df对象 getOnePageAll(self) None 获取一页的景区信息,保存到self.data对象,类型为List sortByCommentnum(self) None 根据评论量对self.df进行排序 sortByScore None 根据分数对self.df进行排序 sortByCommentNumAndScore None 同时根据评论量和分数对self.df进行排序在每个get方法中的具体实现中,主要调用了BeautifulSoup库的select方法,通过类名对html文本内容进行查找, 找到对应的html类标签后,在调用re库的findall方法,利用正则表达式提取出需要的信息,以爬取景区地址的方法为例: Crawler_all_place.py -> def getAddress(self) def getAddress(self): # 获取当前页面的所有景区地址 ADDRESS = ''.join([str(x) for x in self.soup.select('.rdetailbox > dl > .ellipsis')]) self.ADDRESS = re.findall(r'\n([^([^([\\-0-9:^ |
【本文地址】