DIN模型 |
您所在的位置:网站首页 › 推荐算法embedding › DIN模型 |
DIN模型
|
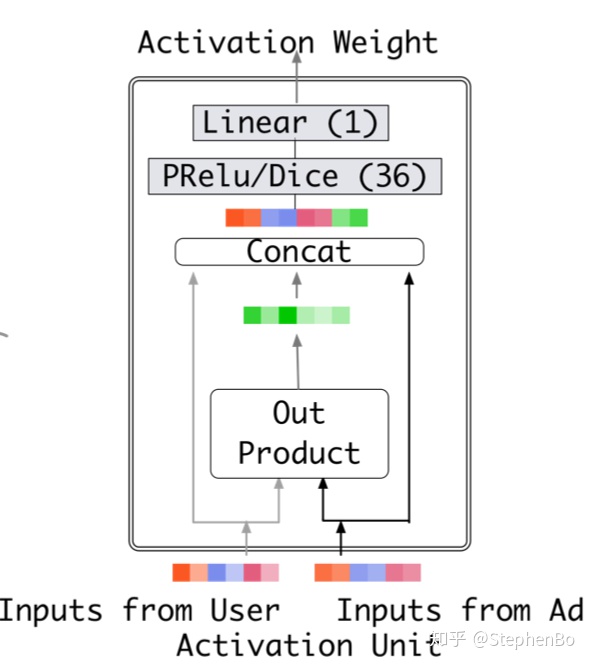
DIN模型提出得主要动机:通过考虑候选物品与用户历史行为得相关性从而自适应的计算用户兴趣得表征向量,提高了模型对用户兴趣得表征能力。 DIN主要有三个新颖得点:第一个是local activation unit,另外两个是面向工业界实践提出了两个重要得技术:分别是mini-batch aware regularization和Data Adaptive Activation Function(dice). 目录 1.local activation unit 2.mini-batch aware regularization 3.Data Adaptive Activation Function 1.local activation unit先来说第一个新颖点local activation unit:
就是计算了用户历史行为商品和候选商品得相关性,这个相关性相当于每个历史行为商品得权重,然后把这个权重与历史行为商品得embedding向量相乘,所有得历史行为商品得向量表征再求和作为用户得兴趣表征。
其中{e1,e2,...,eH}是用户历史行为商品得embedding,uA是候选商品得embedding,a(uA, ej)就是每个历史行为商品得权重即得到wj,这个a(.)就是上面的这个activation unit网络。其中不仅除了用户历史行为商品embedding,候选商品embedding,还计算了两者的外积(原文中说这个是有利于相关性建模的显性知识),另外还可以加入两者的差。 这里还有个需要注意的是,这里最终输出的得分没有归一化成权重总和为1的形式。解释如下: 传统方法使用softmax获得attention产出的权重被遗弃,因为传统方法使得attention的权重求和为1,这样求得的权重并不是用户兴趣的分布估计,采用神经网络最终使用sigmoid或其他激活函数得到序列attention权重分布,从而获得对用户兴趣的权重估计更适用于用户兴趣的表示。比如一个用户历史行为序列中90%都是衣服,10%是电子产品。如果目标商品是t恤和手机的话,传统attention方法会使得t恤的 vU 高于手机,因为用户的行为序列中大部分都是衣服,但是用户购买手机与否与他购买衣服与否是没有直接关联的,因而不能用传统的方法直接求softmax,softmax使得行为序列中的各个item都有了关联从而得出了商品权重。 2.mini-batch aware regularization为了防止模型过拟合,我们一般会加入正则化, 而L2正则化加入的时候,是对于所有的参数都会起作用, 而像这种真实数据集中,每个mini-batch的样本特征是非常稀疏的,我们看之前那个样本编码的例子就能看到,这种情况下根本就没有必要考虑所有的参数进去,这个复杂度会非常大, 而仅仅约束那些在当前mini-batch样本中出现的特征(不为0的那些特征)embedding就可以啦。 基于这个思路,作者最终用的正则化如下所示:
其中K表示特征数量,B表示batch的个数。
这个的意思指的是,我们只需要关注非0特征即可,因为对于不同的特征,其为非0值对应的样本不一样,所以这里取非0值最多的特征对应的样本集合,对这些样本的w进行约束。 3.Data Adaptive Activation Function这里提出了一个随着数据分布而动态调整的自适应激活函数,是泛化的PRelu。Prelu激活函数的公式如下:
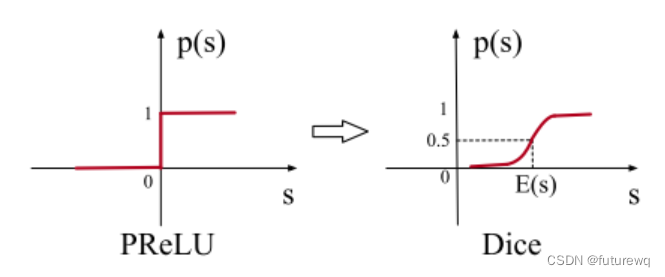
这里的p(s)的函数图像如下图左所示:
作者之处这个的不足是prelu采用了一个值为0的硬矫正点,当每个层的输入遵循不同的分布时,这可能不适合。所以作者这里设计了一个新的自适应激活函数叫做dice,它的p(s)时上图右边所示,具体公式如下: 这里的E(s)和Var(s)时每个mini-batch里面样本的均值和方差,当然这是训练部分,测试集的时候采用的时数据上平滑的均值和方差。由于把均值和方差考虑进去了,那么这个函数的调整就可以根据数据的分布进行自适应,这样会更加的灵活且合理。 另外看到了sigmoid的身影。。
|

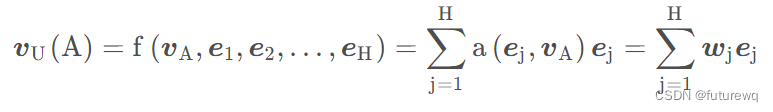
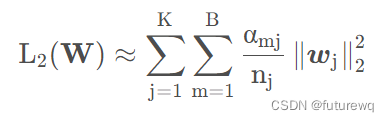
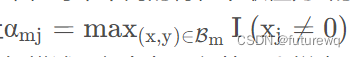
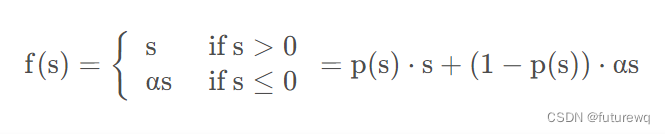
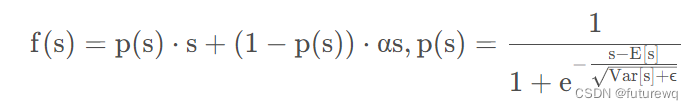
【本文地址】
今日新闻 |
推荐新闻 |