Scrapy爬虫轻松抓取网站数据 |
您所在的位置:网站首页 › 推特爬虫抓取 › Scrapy爬虫轻松抓取网站数据 |
Scrapy爬虫轻松抓取网站数据
|
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。 其最初是为了页面抓取 (更确切来说, 网络抓取 )所设计的, 也可以应用在获取API所返回的数据(例如 Amazon Associates Web Services ) 或者通用的网络爬虫。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
Scrapy 使用了 Twisted异步网络库来处理网络通讯。整体架构大致如下: 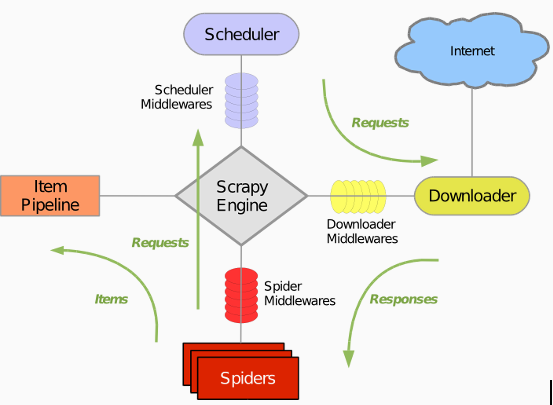
Scrapy主要包括了以下组件: 引擎:用来处理整个系统的数据流处理,触发事务。 调度器:用来接受引擎发过来的请求,压入队列中,并在引擎再次请求的时候返回。 下载器:用于下载网页内容,并将网页内容返回给蜘蛛。 蜘蛛:蜘蛛是主要干活的,用它来制订特定域名或网页的解析规则。 项目管道:负责处理有蜘蛛从网页中抽取的项目,他的主要任务是清晰、验证和存储数据。当页面被蜘蛛解析后,将被发送到项目管道,并经过几个特定的次序处理数据。 下载器中间件:位于Scrapy引擎和下载器之间的钩子框架,主要是处理Scrapy引擎与下载器之间的请求及响应。 蜘蛛中间件:介于Scrapy引擎和蜘蛛之间的钩子框架,主要工作是处理蜘蛛的响应输入和请求输出。 调度中间件:介于Scrapy引擎和调度之间的中间件,从Scrapy引擎发送到调度的请求和响应。 使用Scrapy可以很方便的完成网上数据的采集工作,它为我们完成了大量的工作,而不需要自己费大力气去开发。 Scrapy Tutorial在本文中,假定您已经安装好Scrapy。如若不然,请参考 Installation guide。(http://doc.scrapy.org/en/0.24/intro/install.html#intro-install) 接下来以爬取饮水思源BBS数据为例来讲述爬取过程,详见 bbsdmoz代码。 本篇教程中将带您完成下列任务: 1. 创建一个Scrapy项目2. 定义提取的Item3. 编写爬取网站的 spider 并提取 Item4. 编写 Item Pipeline 来存储提取到的Item(即数据) Scrapy由Python编写。如果您刚接触并且好奇这门语言的特性以及Scrapy的详情, 对于已经熟悉其他语言并且想快速学习Python的编程老手, 我们推荐 Learn Python The Hard Way ,(http://learnpythonthehardway.org/book/) 对于想从Python开始学习的编程新手, 非程序员的Python学习资料列表 (https://wiki.python.org/moin/BeginnersGuide/NonProgrammers)将是您的选择。 Creating a project在开始爬取之前,您必须创建一个新的Scrapy项目。进入您打算存储代码的目录中,运行下列命令: 1 scrapy startproject bbsdmoz 该命令将会创建包含下列内容的 bbsDmoz 目录: bbsDmoz/scrapy.cfgbbsDmoz/ __init__.py items.py pipelines.py settings.py spiders/ __init__.py ... 这些文件分别是: scrapy.cfg: 项目的配置文件 bbsDmoz/: 该项目的python模块。之后您将在此加入代码。 bbsDmoz/items.py: 项目中的item文件. bbsDmoz/pipelines.py: 项目中的pipelines文件. bbsDmoz/settings.py: 项目的设置文件. bbsDmoz/spiders/: 放置spider代码的目录. Defining our ItemItem 是保存爬取到的数据的容器;其使用方法和python字典类似,并且提供了额外保护机制来避免拼写错误导致的未定义字段错误。 类似在ORM中做的一样,您可以通过创建一个 scrapy.Item 类,并且定义类型为 scrapy.Field 的类属性来定义一个Item。(如果不了解ORM,不用担心,您会发现这个步骤非常简单) 首先根据需要从bbs网站获取到的数据对item进行建模。 我们需要从中获取url,发帖板块,发帖人,以及帖子的内容。对此,在item中定义相应的字段。编辑 bbsDmoz 目录中的 items.py 文件: 1 2 3 4 5 6 7 8 9 10 11 12 # -*- coding: utf-8 -*- # Define here the models for your scraped items # See documentation in: # http://doc.scrapy.org/en/latest/topics/items.html from scrapy.item import Item, Field class BbsDmozItem(Item): # define the fields for your item here like: # name = scrapy.Field() url = Field() forum = Field() poster = Field() content = Field() 一开始这看起来可能有点复杂,但是通过定义item, 您可以很方便的使用Scrapy的其他方法。而这些方法需要知道您的item的定义。 Our first SpiderSpider是用户编写用于从单个网站(或者一些网站)爬取数据的类。 其包含了一个用于下载的初始URL,如何跟进网页中的链接以及如何分析页面中的内容, 提取生成 item 的方法。 创建一个Spider为了创建一个Spider,保存在 bbsDmoz/spiders,您必须继承 scrapy.Spider 类,且定义以下三个属性: name: 用于区别Spider。该名字必须是唯一的,您不可以为不同的Spider设定相同的名字。 start_urls: 包含了Spider在启动时进行爬取的url列表。因此,第一个被获取到的页面将是其中之一。后续的URL则从初始的URL获取到的数据中提取。我们可以利用正则表达式定义和过滤需要进行跟进的链接。 parse() 是spider的一个方法。被调用时,每个初始URL完成下载后生成的 Response 对象将会作为唯一的参数传递给该函数。该方法负责解析返回的数据(response data),提取数据(生成item)以及生成需要进一步处理的URL的 Request 对象。 Selectors选择器从网页中提取数据有很多方法。Scrapy使用了一种基于 XPath 和 CSS 表达式机制: Scrapy Selectors。关于selector和其他提取机制的信息请参考 Selector文档 。 我们使用XPath来从页面的HTML源码中选择需要提取的数据。这里给出XPath表达式的例子及对应的含义: /html/head/title: 选择HTML文档中 标签内的 元素 /html/head/title/text(): 选择上面提到的 元素的文字 //td: 选择所有的 元素 //div[@class="mine"]: 选择所有具有 class="mine" 属性的 div 元素 以饮水思源BBS一页面为例:https://bbs.sjtu.edu.cn/bbstcon?board=PhD&reid=1406973178&file=M.1406973178.A 观察HTML页面源码并创建我们需要的数据(种子名字,描述和大小)的XPath表达式。 通过观察,我们可以发现poster是包含在 pre/a 标签中的,这里是userid=jasperstream: 1 2 3 ... [回复本文][原帖] 发信人: jasperstream 因此可以提取jasperstream的 XPath 表达式为: 1 '//pre/a/text()' 同理我可以提取其他内容的XPath,并最好在提取之后验证其正确性。上边仅仅是几个简单的XPath例子,XPath实际上要比这远远强大的多。 如果您想了解的更多,我们推荐 这篇XPath教程。 为了配合XPath,Scrapy除了提供了 Selector 之外,还提供了方法来避免每次从response中提取数据时生成selector的麻烦。 Selector有四个基本的方法(点击相应的方法可以看到详细的API文档): xpath(): 传入xpath表达式,返回该表达式所对应的所有节点的selector list列表。 css(): 传入CSS表达式,返回该表达式所对应的所有节点的selector list列表. extract(): 序列化该节点为unicode字符串并返回list。 re(): 根据传入的正则表达式对数据进行提取,返回unicode字符串list列表。 如提取上述的poster的数据: 1 sel.xpath('//pre/a/text()').extract() 使用ItemItem 对象是自定义的python字典。您可以使用标准的字典语法来获取到其每个字段的值(字段即是我们之前用Field赋值的属性)。一般来说,Spider将会将爬取到的数据以 Item 对象返回。 Spider代码以下为我们的第一个Spider代码,保存在 bbsDmoz/spiders 目录下的 forumSpider.py 文件中: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 #-*- coding: utf-8 -*- ''' bbsSpider, Created on Oct, 2014 #version: 1.0 #author: chenqx @http://chenqx.github.com See more: http://doc.scrapy.org/en/latest/index.html ''' from scrapy.selector import Selector from scrapy.http import Request from scrapy.contrib.spiders import CrawlSpider from scrapy.contrib.loader import ItemLoader from scrapy.contrib.linkextractors.sgml import SgmlLinkExtractor from bbs.items import BbsItem class forumSpider(CrawlSpider): # name of spiders name = 'bbsSpider' allow_domain = ['bbs.sjtu.edu.cn'] start_urls = [ 'https://bbs.sjtu.edu.cn/bbsall' ] link_extractor = { 'page': SgmlLinkExtractor(allow = '/bbsdoc,board,\w+\.html$'), 'page_down': SgmlLinkExtractor(allow = '/bbsdoc,board,\w+,page,\d+\.html$'), 'content': SgmlLinkExtractor(allow = '/bbscon,board,\w+,file,M\.\d+\.A\.html$'), } _x_query = { 'page_content': '//pre/text()[2]', 'poster' : '//pre/a/text()', 'forum' : '//center/text()[2]', }
def parse(self, response): for link in self.link_extractor['page'].extract_links(response): yield Request(url = link.url, callback=self.parse_page)
def parse_page(self, response): for link in self.link_extractor['page_down'].extract_links(response): yield Request(url = link.url, callback=self.parse_page)
for link in self.link_extractor['content'].extract_links(response): yield Request(url = link.url, callback=self.parse_content) def parse_content(self, response): bbsItem_loader = ItemLoader(item=BbsItem(), response = response) url = str(response.url) bbsItem_loader.add_value('url', url) bbsItem_loader.add_xpath('forum', self._x_query['forum']) bbsItem_loader.add_xpath('poster', self._x_query['poster']) bbsItem_loader.add_xpath('content', self._x_query['page_content']) return bbsItem_loader.load_item() Define Item Pipeline当Item在Spider中被收集之后,它将会被传递到Item Pipeline,一些组件会按照一定的顺序执行对Item的处理。 每个item pipeline组件(有时称之为“Item Pipeline”)是实现了简单方法的Python类。他们接收到Item并通过它执行一些行为,同时也决定此Item是否继续通过pipeline,或是被丢弃而不再进行处理。 以下是item pipeline的一些典型应用: 清理HTML数据 验证爬取的数据(检查item包含某些字段) 查重(并丢弃) 将爬取结果保存,如保存到数据库、XML、JSON等文件中 编写 Item Pipeline编写你自己的item pipeline很简单,每个item pipeline组件是一个独立的Python类,同时必须实现以下方法: process_item(item, spider) 每个item pipeline组件都需要调用该方法,这个方法必须返回一个 Item (或任何继承类)对象,或是抛出 DropItem异常,被丢弃的item将不会被之后的pipeline组件所处理。 参数:item (Item object) – 由 parse 方法返回的 Item 对象 spider (Spider object) – 抓取到这个 Item 对象对应的爬虫对象 此外,他们也可以实现以下方法: open_spider(spider) 当spider被开启时,这个方法被调用。 参数: spider (Spider object) – 被开启的spiderclose_spider(spider) 当spider被关闭时,这个方法被调用,可以再爬虫关闭后进行相应的数据处理。 参数: spider (Spider object) – 被关闭的spider 本文爬虫的item pipeline如下,保存为XML文件: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 # -*- coding: utf-8 -*- # Define your item pipelines here # Don't forget to add your pipeline to the ITEM_PIPELINES setting # See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html from scrapy import signals from scrapy import log from bbsDmoz.items import BbsDmozItem from twisted.enterprise import adbapi from scrapy.contrib.exporter import XmlItemExporter from dataProcess import dataProcess class XmlWritePipeline(object): def __init__(self): pass @classmethod def from_crawler(cls, crawler): pipeline = cls() crawler.signals.connect(pipeline.spider_opened, signals.spider_opened) crawler.signals.connect(pipeline.spider_closed, signals.spider_closed) return pipeline def spider_opened(self, spider): self.file = open('bbsData.xml', 'wb') self.expoter = XmlItemExporter(self.file) self.expoter.start_exporting() def spider_closed(self, spider): self.expoter.finish_exporting() self.file.close() # process the crawled data, define and call dataProcess function # dataProcess('bbsData.xml', 'text.txt') def process_item(self, item, spider): self.expoter.export_item(item) return item 启用和设置 Item Pipeline为了启用一个Item Pipeline组件,你必须将它的类添加到 ITEM_PIPELINES 就像下面这个例子: 1 2 3 ITEM_PIPELINES = { 'bbsDmoz.pipelines.XmlWritePipeline': 1000, } 分配给每个类的整型值,确定了他们运行的顺序,item按数字从低到高的顺序,通过pipeline,通常将这些数字定义在0-1000范围内。 SettingsScrapy设定(settings)提供了定制Scrapy组件的方法。您可以控制包括核心(core),插件(extension),pipeline及spider组件。 设定为代码提供了提取以key-value映射的配置值的的全局命名空间(namespace)。 设定可以通过下面介绍的多种机制进行设置。 设定(settings)同时也是选择当前激活的Scrapy项目的方法(如果您有多个的话)。 在setting配置文件中,你可一定以抓取的速率、是否在桌面显示抓取过程信息等。详细请参考内置设定列表请参考 。 本爬虫的setting配置如下: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 # -*- coding: utf-8 -*- # Scrapy settings for bbs project # For simplicity, this file contains only the most important settings by # default. All the other settings are documented here: # http://doc.scrapy.org/en/latest/topics/settings.html BOT_NAME = 'bbsDomz' CONCURRENT_REQUESTS = 200 LOG_LEVEL = 'INFO' COOKIES_ENABLED = True RETRY_ENABLED = True SPIDER_MODULES = ['bbsDomz.spiders'] NEWSPIDER_MODULE = 'bbsDomz.spiders' # JOBDIR = 'jobdir' ITEM_PIPELINES = { 'bbsDomz.pipelines.XmlWritePipeline': 1000, } Crawling写好爬虫程序后,我们就可以运行程序抓取数据。进入项目的根目录bbsDomz/下,执行下列命令启动spider: 1 scrapy crawl bbsSpider 这样就等程序运行结束就还可以啦。
|
【本文地址】
今日新闻 |
推荐新闻 |