Hive hql语句 排序【全局排序、按别名排序、多个列排序、局部排序、分区排序】 |
您所在的位置:网站首页 › 按分类列排序怎么排 › Hive hql语句 排序【全局排序、按别名排序、多个列排序、局部排序、分区排序】 |
Hive hql语句 排序【全局排序、按别名排序、多个列排序、局部排序、分区排序】
|
文章目录
1.全局排序案例实操:
2.按照别名排序案例实操
3.多个列排序案例实操
4.每个MapReduce内部排序(Sort By)局部排序案例操作:(1)设置reduce个数(2)查看reduce个数(3)将查询结果按照成绩降序排列(4)将查询结果导入文件当中
5.分区排序案例实操
6.CLUSTER BY
1.全局排序
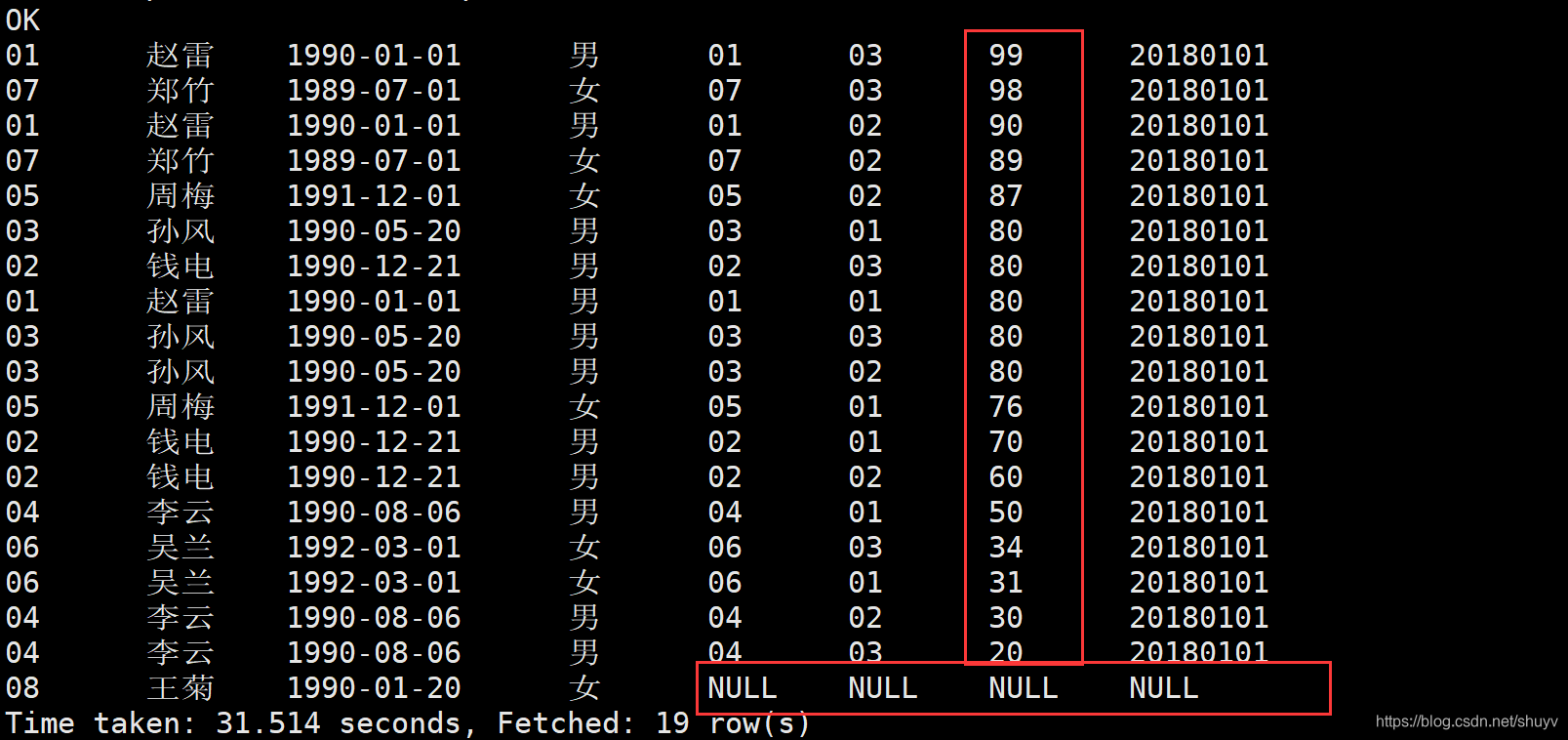
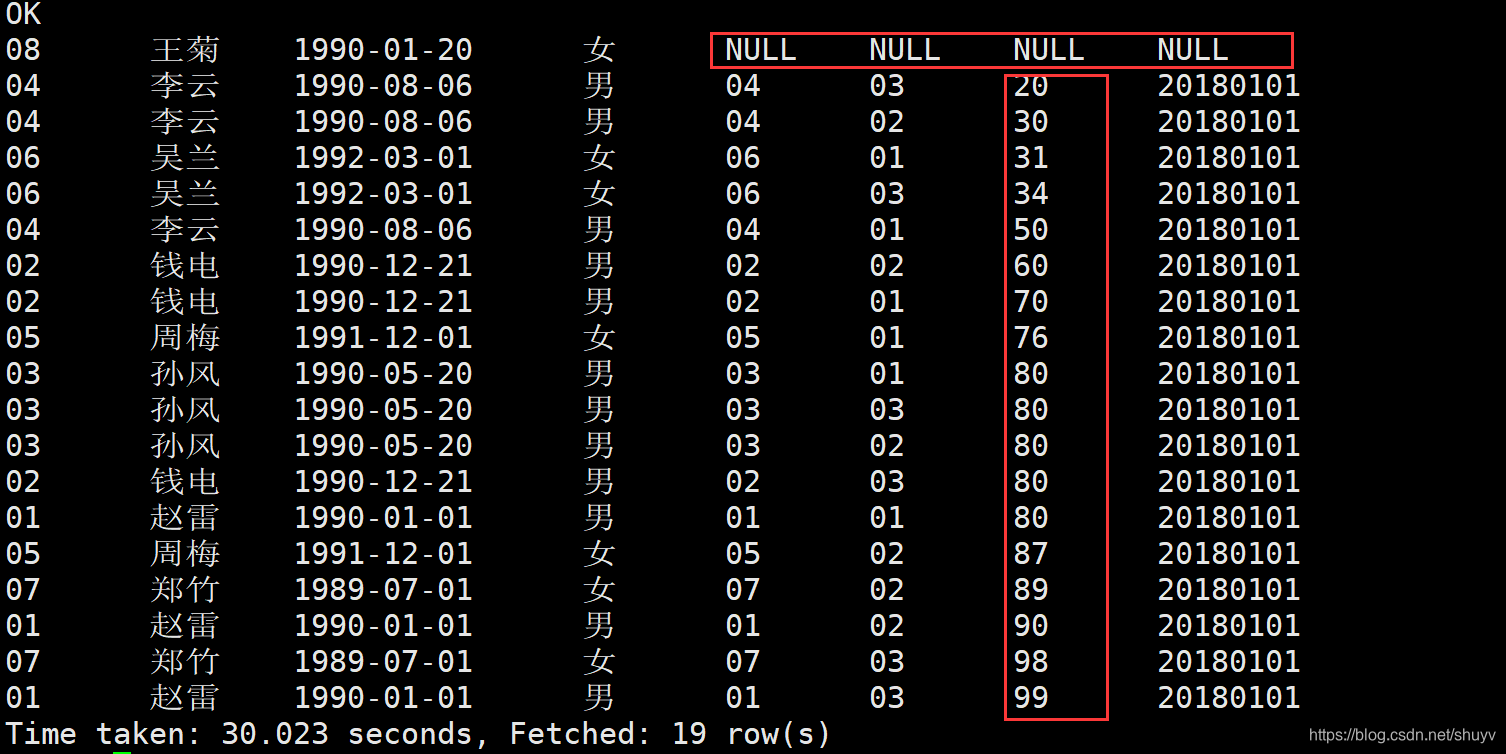
Order By : 1.使用order by 子句排序: ASC(ascend):升序(默认)DESC(descend):降序 2.order by 子句在select语句的结尾。 案例实操:(1)查询学生成绩,并按照分数降序排列。 select * from student s left join score sco on s.s_id = sco.s_id order by sco.s_score DESC;命令采用左外连接,按分数列降序查询 执行结果如下: (2)查询学生成绩,并且按照分数升序排列 select * from student s left join score sco on s.s_id = sco.s_id order by sco.s_score ASC;命令按照左外连接,按分数列升序查询。 执行结果如下: 执行结果如下: 上述hql命令,先对s_id进行分组,求平均值,然后进行排序,先是按照s_id进行排序,然后按照平均值avg(别名)进行排序。 结果如下: sort by:每个MapReduce内部进行排序,对全局结果集来说不是排序。 案例操作: (1)设置reduce个数 set mapreduce.job.reduces=3; (2)查看reduce个数 set mapreduce.job.reduces; (3)将查询结果按照成绩降序排列 select * from score sort by s_score;执行结果如下: 按照成绩降序排列 insert overwrite local directory '/usr/Data_train/out_result' select * from score sort by s_score;执行结果如下:在本地去查看hql语句的查询结果 Distribute By:类似于MR中的partation,进行分区,结合sort by使用。 注意事项: 1.Hive要求Distribute By 语句写在 sort by 语句之前。2.对于distracte by进行测试,一定要多分配reduce进行处理,否则无法看到distribute by的效果。 案例实操首先按照学生id进行分区,然后再按照学生成绩进行排序 (1)设置reduce的个数,将我们对应的s_id划分到对应的reduce当中去。 set mapreduce.job.reduces=7;(2)通过distribute by进行数据的分区。 insert overwrite local directory '/export/servers/hivedatas/sort' select * from score distribute by s_id sort by s_score;
当distribute by和sort by字段相同时,可以使用cluster by方式。 cluster by除了具有distribute by的功能外还兼具sort by的功能。但是排序只能是倒序排序,不 能指定排序规则为ASC或者DESC。 例如下面俩种写法等价: select * from score cluster by s_id; select * from score distribute by s_id sort by s_id; |
 mV0L3NodXl2,size_16,color_FFFFFF,t_70)
mV0L3NodXl2,size_16,color_FFFFFF,t_70)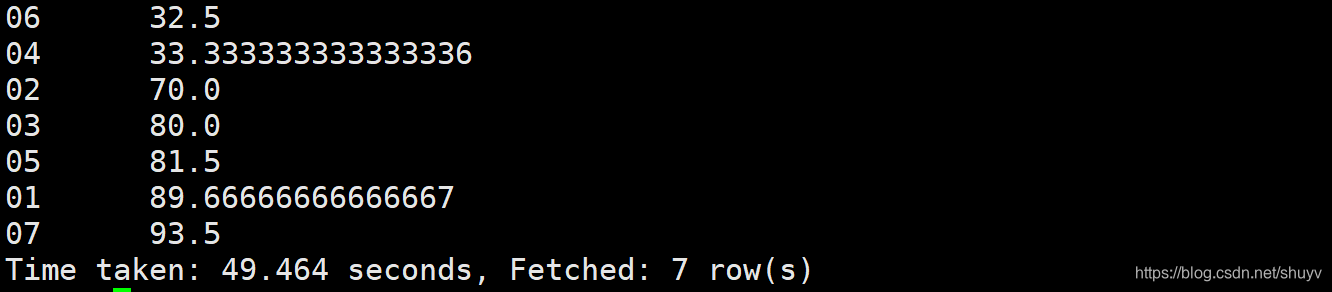
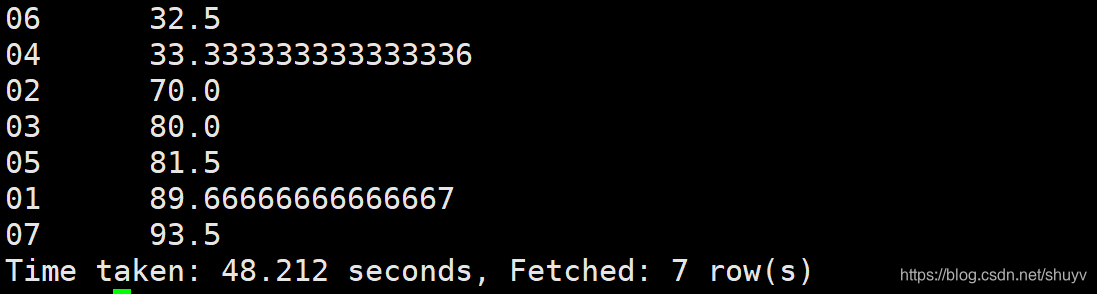
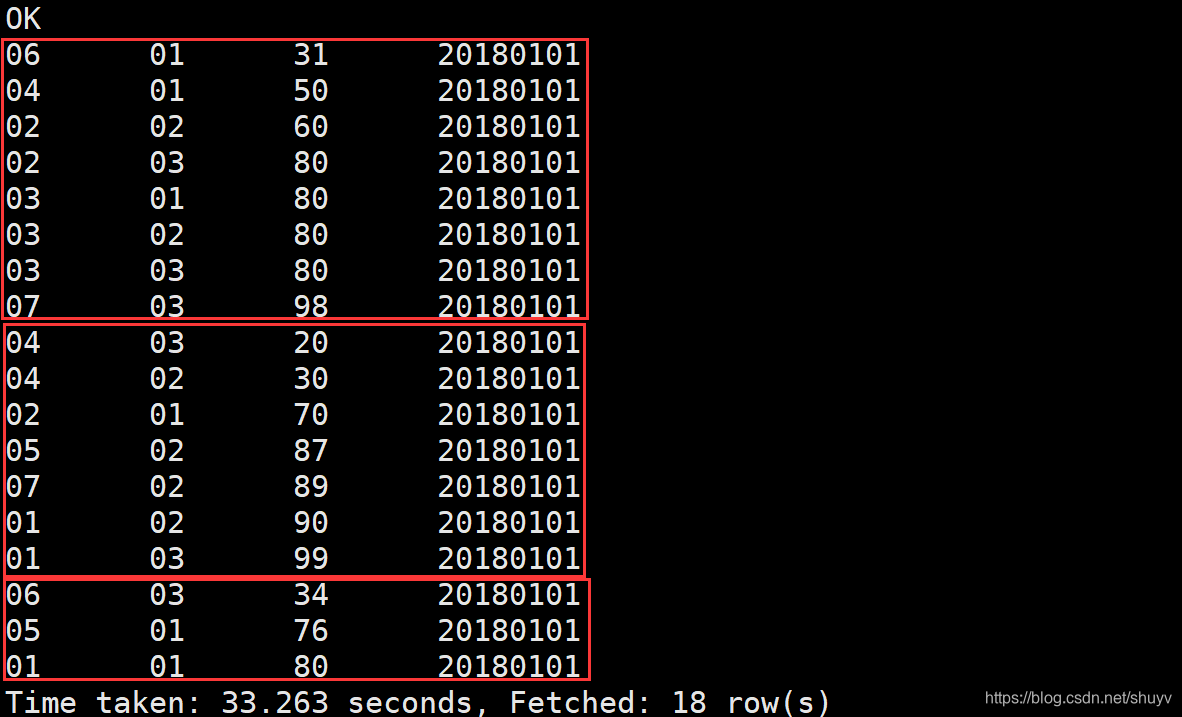 局部排序,三个reduce的结果
局部排序,三个reduce的结果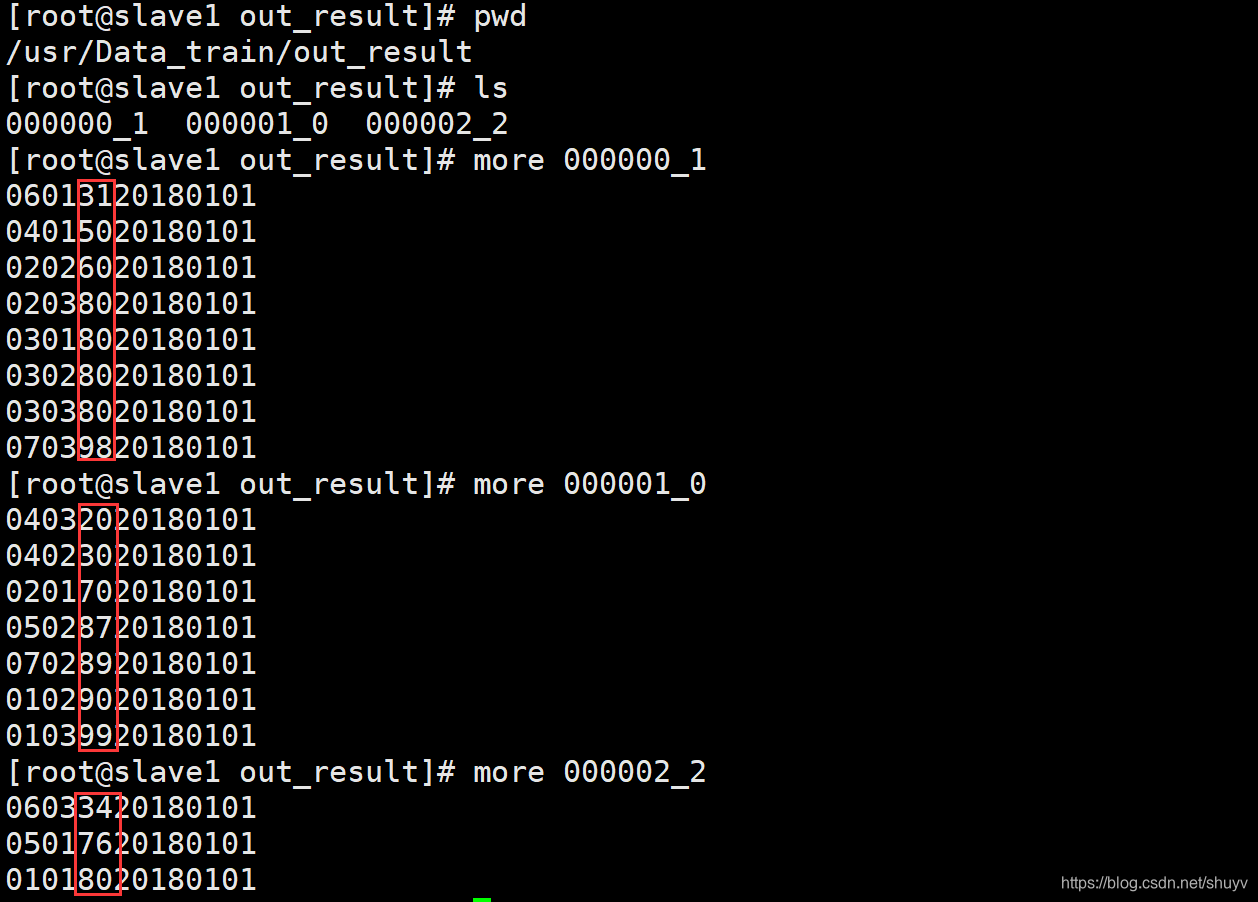

【本文地址】