Query Rewrite |
您所在的位置:网站首页 › 拓展思维的句子 › Query Rewrite |
Query Rewrite
|
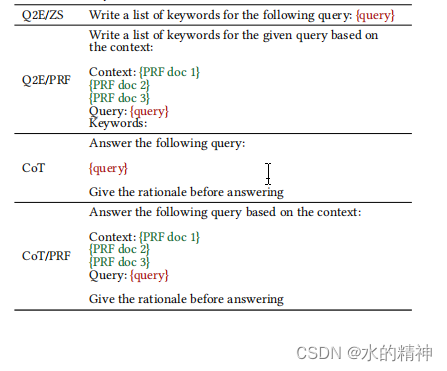
谷歌的通过使用大模型,来做query改写,提升召回率的研究。 论文:https://arxiv.org/pdf/2305.03653.pdf 论文中,提出了思维链(CoT)提示,指导模型逐步分解答案。 摘要查询扩展是一种广泛应用于提高搜索系统召回率的技术。在本文中,我们提出了一种利用大型语言模型(llm)的生成能力的查询扩展方法。与传统的查询扩展方法,如伪相关反馈(PRF),它依赖于检索一组好的伪相关文档来扩展查询不同,我们依赖于LLM的生成和创造性能力,并利用模型中固有的知识。我们研究了各种不同的提示,包括零射击、少射击和思维链(CoT)。我们发现CoT提示对于查询扩展特别有用,因为这些提示指示模型逐步分解查询,并可以提供大量与原始查询相关的术语。在MS-MARCO和BEIR上的实验结果表明,由llm生成的查询扩展比传统的查询扩展方法更强大。 一、论文中,研究了八种不同的提示query扩展方式 Q2D:Query2Doc [31]少样本提示,要求模型编写一个回答查询的段落。Q2D/ZS:Q2D的零样本版本。Q2D/PRF:类似于Q2D/ZS的零样本提示,但还包含了以查询为基础的前三个检索到的PRF文档的额外上下文。Q2E:类似于Query2Doc少样本提示,但用查询扩展术语的示例代替文档。Q2E/ZS:Q2E的零样本版本。Q2E/PRF:类似于Q2E/ZS的零样本提示,但包含了类似于Q2D/PRF的PRF文档的额外上下文。CoT:零样本的Chain-of-Thought提示,指导模型提供其回答的原因。CoT/PRF:类似于CoT的提示,但还包含了以查询为基础的前三个检索到的PRF文档的额外上下文。零样本提示(Q2D/ZS和Q2E/ZS)是最简单的,因为它们由简单的纯文本指令和输入查询组成。少样本提示(Q2D和Q2E)还包含几个示例以支持上下文学习,例如它们包含查询和相应的扩展。Chain-of-Thought(CoT)提示通过要求模型逐步分解其响应来制定指令,以获得更详细的输出。最后,伪相关反馈(·/PRF)变种的提示使用前三个检索到的文档作为模型的额外上下文。 对应的Prompt如下
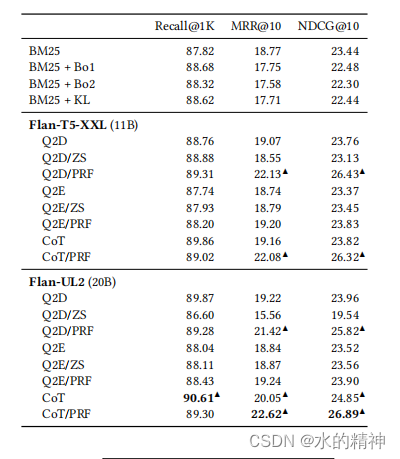
模型的输出结果如下(下表显示了对Flan-T5- Large(770M)模型大小和Flan-UL2(20B)模型大小进行查询扩展的结果。首先,请注意,在较小的模型尺寸下,CoT和Q2D提示不会产生正确的答案,这对检索性能有害。CoT/PRF提示,更加基于其PRF文档,避免了这个问题,并正确地生成了答案“塔塔汽车”,这有助于检索相关的段落。在较大的型号尺寸(Flan-UL2)下,所有的提示Q2D、CoT和CoT/PRF都会产生正确的答案“塔塔汽车”。然而,CoT提示对其答案提供了最冗长的解释,并与相关段落有许多术语重叠,提高了其整体检索性能)
最后,通过CoT(以及相应的PRF增强的提示符CoT/PRF)获得了最佳的性能。这个特殊的提示指示模型通过将其答案分解为步骤来生成冗长的解释。我们假设,这种冗长可能会导致许多对查询扩展有用的潜在关键字。最后,我们发现,在提示中添加PRF文档显著有助于跨模型和提示的MRR@10和NDCG@10等头重脚轻的排名指标,如MRR@10。一种可能的解释是,llm可以有效地提取PRF文档,其中可能已经包含了相关的段落,通过关注最有前途的关键字,并在输出中使用它们。我们在附录B中提供了一个更具体的提示输出示例。
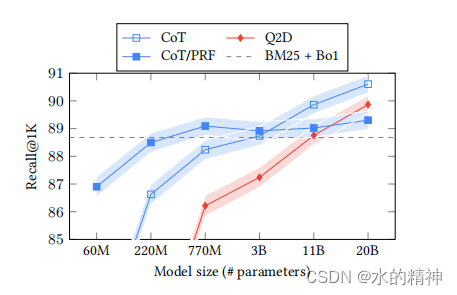
从论文中的数据来看,可以得出两条结论。 其中CoT/PRF这种方式是最有效的。top1000召回率提升了3%(我觉得这个意义不大,实际检索中,根本看不到top1000)。top10的召回提升了3%。模型参数规模越大提升效果越好。
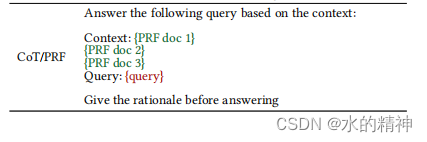
思维链只对稀疏检索(BM25),扩展有效。密集的检索系统(例如,双编码器)不太容易出现词汇表差距,因此,也不太可能从查询扩展中获益。Wang等人( Liang Wang, Nan Yang, and Furu Wei. 2023. Query2doc: Query Expansion with Large Language Models. arXiv preprint arXiv:2303.07678 (2023))已经对这个设置进行了更详细的研究。 该只适用于即席搜索(ad-hoc search)场景。而现代的搜索系统很多支持会话搜索(session search),类似于多轮对话,搜索结果会考虑一个会话中的前几次搜索信息,则没有作用。 四、CoT/PRF如何使用害怕上边的Prompt没有看懂,这再说一下怎么使用。Prompt如下:其中PRF是原始query召回的top3的段落。
拼接公式
先用原始的条件进行检索。然后获取too3的数据。然后top3的数据拼接上原始query,通过模型生成思维链。最后把原始query拼接5次,再拼接上由模型生成的思维链,去做BM25的搜索召回。威为什么要拼接5次?因为LLM的输出可能很冗长,所以我们重复原始的查询术语5次,以增加它们的相对重要性。 五、个人建议整体看完论文,通过使用模型,来生成思维链的方式扩展query。有提升,但是只有3%。操作过程不是太复杂,但是请求链路的延迟会加大。且以来模型的能力,资源花费增加较多。除非有专用的小模型来做这件事,但是这又是一个悖论,小模型生成的内容和原始的query可能会有较大的偏差,会引入更多的噪音数据。 论文中的测试场景和每个业务的真实场景有很大的不同。具体提升效果要在自己的场景下做测试。 |


【本文地址】
今日新闻 |
推荐新闻 |