从零写一个编译器(九):语义分析之构造抽象语法树(AST) |
您所在的位置:网站首页 › 抽象语法树构建 › 从零写一个编译器(九):语义分析之构造抽象语法树(AST) |
从零写一个编译器(九):语义分析之构造抽象语法树(AST)
|
项目的完整代码在 C2j-Compiler 前言在上一篇完成了符号表的构建,下一步就是输出抽象语法树(Abstract Syntax Tree,AST) 抽象语法树(abstract syntax tree 或者缩写为 AST),是源代码的抽象语法结构的树状表现形式,这里特指编程语言的源代码。树上的每个节点都表示源代码中的一种结构。 AST对于编译器是至关重要的,现在的编译型语言一般通过AST来生成IR,解释型语言也可以不用虚拟机而直接遍历AST来解释执行,之后要写解释器和编译器都依赖这个AST 这一篇主要文件有: AstBuilder.java AstNode.java AstNodeImpl.java NodeKey.java NodeFactory.java 主要数据结构 AST节点的表示 public interface AstNode { AstNode addChild(AstNode node); AstNode getParent(); ArrayList getChildren(); void setAttribute(NodeKey key, Object value); Object getAttribute(NodeKey key); boolean isChildrenReverse(); void reverseChildren(); AstNode copy(); }这是对AstNode接口的实现,并且继承HashMap,这里的NodeKey是 TokenType, VALUE, SYMBOL, PRODUCTION, TEXT对应的value, TokenType就是非终结符的类型 Text用来存储解析对象的文本信息 Symbol对应的就是变量的符号对象 Value是对应对象解析的值,比如int a = 1,那么value的值就为1 public class AstNodeImpl extends HashMap implements AstNode { private Token type; private AstNodeImpl parent; private ArrayList children; String name; private boolean isChildrenReverse = false; public AstNodeImpl(Token type) { this.type = type; this.parent = null; this.children = new ArrayList(); setAttribute(NodeKey.TokenType, type); } @Override public AstNode addChild(AstNode node) { if (node != null) { children.add(node); ((AstNodeImpl) node).parent = this; } return node; } @Override public AstNode getParent() { return parent; } @Override public void reverseChildren() { if (isChildrenReverse) { return; } Collections.reverse(children); isChildrenReverse = true; } @Override public boolean isChildrenReverse() { return isChildrenReverse; } @Override public ArrayList getChildren() { reverseChildren(); return children; } @Override public void setAttribute(NodeKey key, Object value) { if (key == NodeKey.TEXT) { name = (String) value; } put(key, value); } @Override public Object getAttribute(NodeKey key) { return get(key); } @Override public String toString() { String info = ""; if (get(NodeKey.VALUE) != null) { info += "Node Value is " + get(NodeKey.VALUE).toString(); } if (get(NodeKey.TEXT) != null) { info += "\nNode Text is " + get(NodeKey.TEXT).toString(); } if (get(NodeKey.SYMBOL) != null) { info += "\nNode Symbol is " + get(NodeKey.SYMBOL).toString(); } return info + "\n Node Type is " + type.toString(); } @Override public AstNode copy() { AstNodeImpl copy = (AstNodeImpl) NodeFactory.createICodeNode(type); Set attributes = entrySet(); Iterator it = attributes.iterator(); while (it.hasNext()) { Map.Entry attribute = it.next(); copy.put(attribute.getKey(), attribute.getValue()); } return copy; } } NodeFactoryNodeFactory就是简单的返回一个节点的实现 public class NodeFactory { public static AstNode createICodeNode(Token type) { return new AstNodeImpl(type); } } 构造ASTAST的创建也是需要在语法分析过程中根据reduce操作进行操作的。也就是在takeActionForReduce方法中调用AstBuilder的buildSyntaxTree方法 在AstBuilder里面还是需要两个堆栈来辅助操作 private Stack nodeStack = new Stack(); private LRStateTableParser parser = null; private TypeSystem typeSystem = null; private Stack valueStack = null; private String functionName; private HashMap funcMap = new HashMap(); private static AstBuilder instance;构造AST的主要逻辑在buildSyntaxTree方法里,需要注意的是有一些节点在解释执行和代码生成的时候是不一样的,有时代码生成需要的节点解释执行的话并不需要 在这里提一下UNARY这个非终结符,这个非终结符和NAME很像,但是它一般是代表进行运算和一些操作的时候,比如数组,++,--或者函数调用的时候 其实构建AST的过程和符号表的构建过程有点儿类似,都是根据reduce操作来创建信息和组合信息,符号表是组合修饰符说明符等,而AST则是组合节点间的关系变成一棵树 我们只看几个操作 Specifiers_DeclList_Semi_TO_Def这个节点需要注意的是,从堆栈的什么地方拿到Symbol,这个需要从reduce次数和推导式中得出 * DEF -> SPECIFIERS DECL_LIST SEMI * DECL -> VAR_DECL * VAR_DECL -> NEW_NAME * | VAR_DECL LP RP * | VAR_DECL LP VAR_LIST RP * | LP VAR_DECL RP * | START VAR_DECL从推导式可以看出,DEF节点的符号应该在valueStack.size() - 3,但是DECL和VAR_DECL没有做reduce操作,所以符号应该在valueStack.size() - 2。这其实和前面的符号表构建算出之前符号的位置是一样的。 TO_UNARY这里则是变量、数字或者字符串的节点,如果是个变量的号,这个节点就需要一个Symbol的value了 case SyntaxProductionInit.Number_TO_Unary: case SyntaxProductionInit.Name_TO_Unary: case SyntaxProductionInit.String_TO_Unary: node = NodeFactory.createICodeNode(Token.UNARY); if (production == SyntaxProductionInit.Name_TO_Unary) { assignSymbolToNode(node, text); } node.setAttribute(NodeKey.TEXT, text); break;其余的节点无非是把一些语句拆分它的逻辑然后组成节点,真正的求值部分像Name_TO_Unary比较少,更多是比如把一个if else块分成if节点、判断节点、else节点,之后再按照这棵树进行解释执行或者代码生成 public AstNode buildSyntaxTree(int production, String text) { AstNode node = null; Symbol symbol = null; AstNode child = null; if (Start.STARTTYPE == Start.INTERPRETER) { int p1 = SyntaxProductionInit.Specifiers_DeclList_Semi_TO_Def; int p2 = SyntaxProductionInit.Def_To_DefList; int p3 = SyntaxProductionInit.DefList_Def_TO_DefList; boolean isReturn = production == p1 || production == p2 || production == p3; if (isReturn) { return null; } } switch (production) { case SyntaxProductionInit.Specifiers_DeclList_Semi_TO_Def: node = NodeFactory.createICodeNode(Token.DEF); symbol = (Symbol) valueStack.get(valueStack.size() - 2); node.setAttribute(NodeKey.SYMBOL, symbol); break; case SyntaxProductionInit.Def_To_DefList: node = NodeFactory.createICodeNode(Token.DEF_LIST); node.addChild(nodeStack.pop()); break; case SyntaxProductionInit.DefList_Def_TO_DefList: node = NodeFactory.createICodeNode(Token.DEF_LIST); node.addChild(nodeStack.pop()); node.addChild(nodeStack.pop()); break; case SyntaxProductionInit.Number_TO_Unary: case SyntaxProductionInit.Name_TO_Unary: case SyntaxProductionInit.String_TO_Unary: node = NodeFactory.createICodeNode(Token.UNARY); if (production == SyntaxProductionInit.Name_TO_Unary) { assignSymbolToNode(node, text); } node.setAttribute(NodeKey.TEXT, text); break; case SyntaxProductionInit.Unary_LP_RP_TO_Unary: node = NodeFactory.createICodeNode(Token.UNARY); node.addChild(nodeStack.pop()); break; case SyntaxProductionInit.Unary_LP_ARGS_RP_TO_Unary: node = NodeFactory.createICodeNode(Token.UNARY); node.addChild(nodeStack.pop()); node.addChild(nodeStack.pop()); break; case SyntaxProductionInit.Unary_Incop_TO_Unary: case SyntaxProductionInit.Unary_DecOp_TO_Unary: case SyntaxProductionInit.LP_Expr_RP_TO_Unary: case SyntaxProductionInit.Start_Unary_TO_Unary: node = NodeFactory.createICodeNode(Token.UNARY); node.addChild(nodeStack.pop()); break; case SyntaxProductionInit.Unary_LB_Expr_RB_TO_Unary: node = NodeFactory.createICodeNode(Token.UNARY); node.addChild(nodeStack.pop()); node.addChild(nodeStack.pop()); break; case SyntaxProductionInit.Uanry_TO_Binary: node = NodeFactory.createICodeNode(Token.BINARY); child = nodeStack.pop(); node.setAttribute(NodeKey.TEXT, child.getAttribute(NodeKey.TEXT)); node.addChild(child); break; case SyntaxProductionInit.Binary_TO_NoCommaExpr: case SyntaxProductionInit.NoCommaExpr_Equal_NoCommaExpr_TO_NoCommaExpr: node = NodeFactory.createICodeNode(Token.NO_COMMA_EXPR); child = nodeStack.pop(); String t = (String) child.getAttribute(NodeKey.TEXT); node.addChild(child); if (production == SyntaxProductionInit.NoCommaExpr_Equal_NoCommaExpr_TO_NoCommaExpr) { child = nodeStack.pop(); t = (String) child.getAttribute(NodeKey.TEXT); node.addChild(child); } break; case SyntaxProductionInit.Binary_Plus_Binary_TO_Binary: case SyntaxProductionInit.Binary_DivOp_Binary_TO_Binary: case SyntaxProductionInit.Binary_Minus_Binary_TO_Binary: case SyntaxProductionInit.Binary_Start_Binary_TO_Binary: node = NodeFactory.createICodeNode(Token.BINARY); node.addChild(nodeStack.pop()); node.addChild(nodeStack.pop()); break; case SyntaxProductionInit.Binary_RelOP_Binary_TO_Binray: node = NodeFactory.createICodeNode(Token.BINARY); node.addChild(nodeStack.pop()); AstNode operator = NodeFactory.createICodeNode(Token.RELOP); operator.setAttribute(NodeKey.TEXT, parser.getRelOperatorText()); node.addChild(operator); node.addChild(nodeStack.pop()); break; case SyntaxProductionInit.NoCommaExpr_TO_Expr: node = NodeFactory.createICodeNode(Token.EXPR); node.addChild(nodeStack.pop()); break; case SyntaxProductionInit.Expr_Semi_TO_Statement: case SyntaxProductionInit.CompountStmt_TO_Statement: node = NodeFactory.createICodeNode(Token.STATEMENT); node.addChild(nodeStack.pop()); break; case SyntaxProductionInit.LocalDefs_TO_Statement: node = NodeFactory.createICodeNode(Token.STATEMENT); if (Start.STARTTYPE == Start.CODEGEN) { node.addChild(nodeStack.pop()); } break; case SyntaxProductionInit.Statement_TO_StmtList: node = NodeFactory.createICodeNode(Token.STMT_LIST); if (nodeStack.size() > 0) { node.addChild(nodeStack.pop()); } break; case SyntaxProductionInit.FOR_OptExpr_Test_EndOptExpr_Statement_TO_Statement: node = NodeFactory.createICodeNode(Token.STATEMENT); node.addChild(nodeStack.pop()); node.addChild(nodeStack.pop()); node.addChild(nodeStack.pop()); node.addChild(nodeStack.pop()); break; case SyntaxProductionInit.StmtList_Statement_TO_StmtList: node = NodeFactory.createICodeNode(Token.STMT_LIST); node.addChild(nodeStack.pop()); node.addChild(nodeStack.pop()); break; case SyntaxProductionInit.Expr_TO_Test: node = NodeFactory.createICodeNode(Token.TEST); node.addChild(nodeStack.pop()); break; case SyntaxProductionInit.If_Test_Statement_TO_IFStatement: node = NodeFactory.createICodeNode(Token.IF_STATEMENT); node.addChild(nodeStack.pop()); node.addChild(nodeStack.pop()); break; case SyntaxProductionInit.IfElseStatemnt_Else_Statemenet_TO_IfElseStatement: node = NodeFactory.createICodeNode(Token.IF_ELSE_STATEMENT); node.addChild(nodeStack.pop()); node.addChild(nodeStack.pop()); break; case SyntaxProductionInit.While_LP_Test_Rp_TO_Statement: case SyntaxProductionInit.Do_Statement_While_Test_To_Statement: node = NodeFactory.createICodeNode(Token.STATEMENT); node.addChild(nodeStack.pop()); node.addChild(nodeStack.pop()); break; case SyntaxProductionInit.Expr_Semi_TO_OptExpr: case SyntaxProductionInit.Semi_TO_OptExpr: node = NodeFactory.createICodeNode(Token.OPT_EXPR); if (production == SyntaxProductionInit.Expr_Semi_TO_OptExpr) { node.addChild(nodeStack.pop()); } break; case SyntaxProductionInit.Expr_TO_EndOpt: node = NodeFactory.createICodeNode(Token.END_OPT_EXPR); node.addChild(nodeStack.pop()); break; case SyntaxProductionInit.LocalDefs_StmtList_TO_CompoundStmt: node = NodeFactory.createICodeNode(Token.COMPOUND_STMT); node.addChild(nodeStack.pop()); break; case SyntaxProductionInit.NewName_LP_RP_TO_FunctDecl: case SyntaxProductionInit.NewName_LP_VarList_RP_TO_FunctDecl: node = NodeFactory.createICodeNode(Token.FUNCT_DECL); node.addChild(nodeStack.pop()); child = node.getChildren().get(0); functionName = (String) child.getAttribute(NodeKey.TEXT); symbol = assignSymbolToNode(node, functionName); break; case SyntaxProductionInit.NewName_TO_VarDecl: nodeStack.pop(); break; case SyntaxProductionInit.NAME_TO_NewName: node = NodeFactory.createICodeNode(Token.NEW_NAME); node.setAttribute(NodeKey.TEXT, text); break; case SyntaxProductionInit.OptSpecifiers_FunctDecl_CompoundStmt_TO_ExtDef: node = NodeFactory.createICodeNode(Token.EXT_DEF); node.addChild(nodeStack.pop()); node.addChild(nodeStack.pop()); funcMap.put(functionName, node); break; case SyntaxProductionInit.NoCommaExpr_TO_Args: node = NodeFactory.createICodeNode(Token.ARGS); node.addChild(nodeStack.pop()); break; case SyntaxProductionInit.NoCommaExpr_Comma_Args_TO_Args: node = NodeFactory.createICodeNode(Token.ARGS); node.addChild(nodeStack.pop()); node.addChild(nodeStack.pop()); break; case SyntaxProductionInit.Return_Semi_TO_Statement: node = NodeFactory.createICodeNode(Token.STATEMENT); break; case SyntaxProductionInit.Return_Expr_Semi_TO_Statement: node = NodeFactory.createICodeNode(Token.STATEMENT); node.addChild(nodeStack.pop()); break; case SyntaxProductionInit.Unary_StructOP_Name_TO_Unary: node = NodeFactory.createICodeNode(Token.UNARY); node.addChild(nodeStack.pop()); node.setAttribute(NodeKey.TEXT, text); break; default: break; } if (node != null) { node.setAttribute(NodeKey.PRODUCTION, production); nodeStack.push(node); } return node; } 小结其实构造AST和创建符号表上非常相似,都是依据reduce操作的信息来完成。在AST的构建中的主要任务就是对源代码语句里的逻辑进行分块,比如对于一个ifelse语句: 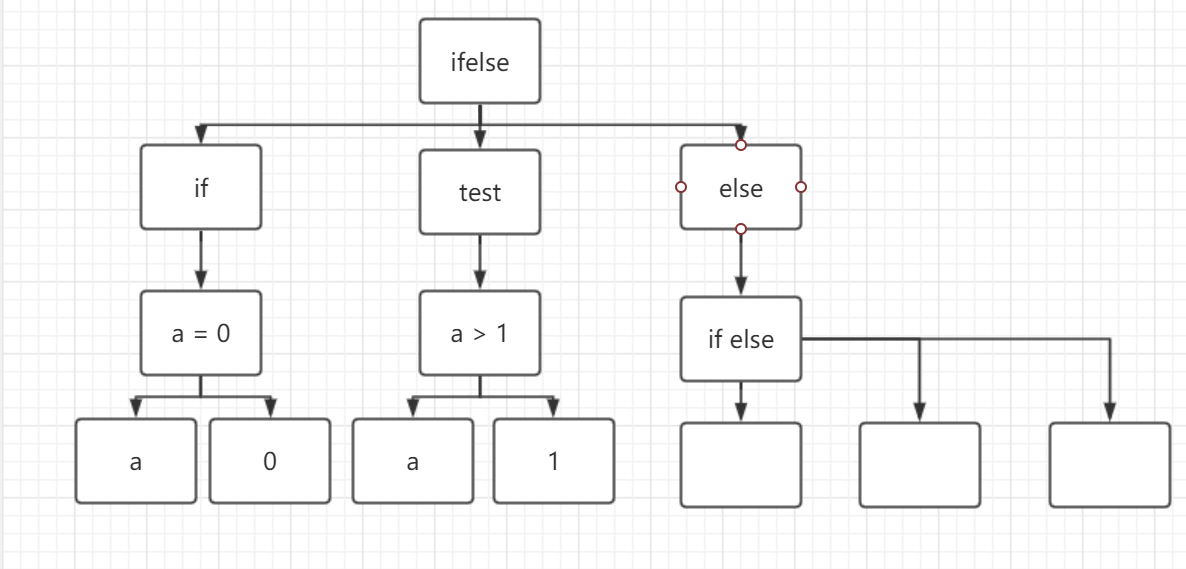
上面的图是我依据这个意思话的,和上面构造出来的AST不完全一致 另外,欢迎Star这个项目! |
【本文地址】
今日新闻 |
推荐新闻 |