样本抽样误差计算公式 |
您所在的位置:网站首页 › 抽样标准误计算公式有哪些 › 样本抽样误差计算公式 |
样本抽样误差计算公式
|
样本抽样误差计算公式
时间:2022-03-14
理论教育
版权反馈
【摘要】:设、Δp分别表示样本均值允许误差和样本成数允许误差,则有:由于抽样平均误差反映误差的一般水平,因此,抽样允许误差往往以抽样平均误差的Z倍来界定,即三、参数估计用样本统计量估计总体参数有点估计和区间估计两种形式。
参数估计_统计学教程
第一节 参数估计 一、参数估计的优良标准 参数估计(Parameter estimation)是以样本统计量作为未知总体参数的估计量,并通过对样本各单位的实际观察取得样本数据,计算样本统计量的取值作为被估计参数的估计值。 由于统计量是样本变量的函数,根据样本变量可以构造许多统计量,但并不是所有的统计量都能够充当总体参数良好的估计量。作为优良的估计量应符合以下三项标准: (一)无偏性(Unbiasedness) 即抽样指标的数学期望(均值)等于总体参数。也就是说,虽然每一次抽样指标可能与总体参数有一定偏差,但是,总体中所有可能的样本抽样指标的均值要等于总体参数。这是一个好的估计量必须具备的性质。 (二)有效性(Effectiveness) 当容量相同的两个样本统计量进行比较时,其中抽样分布的标准差较小的那个统计量比另一个更有效。因此,作为优良估计量的统计量,其标准差应小于其他统计量的标准差。 (三)一致性(Consistency) 以样本统计量估计总体参数,要求当样本的单位数充分大时,样本统计量也充分接近总体参数。也就是说,随着样本量n的无限增加,样本统计量和被估计的总体参数之差的绝对值小于任意小正数。 可以证明,样本均值 二、抽样误差 当用样本指标估计总体参数时,不可避免地要出现误差。产生这一误差的原因有两个方面:一方面是由抽样工作中人为因素造成的,包括调查过程中的登记性误差、不遵守随机原则故意多选有利的单位或不利的单位而造成的系统性误差;另一方面,在遵守随机原则前提下,由于抽样方法本身所致的样本结构与总体结构不一致而产生的偶然性的代表性误差。上述第一种误差是由于抽样过程中人为因素造成的,可通过采取措施预防其发生或将其减少到最小限度,而第二种误差则是抽样方法本身所固有的、无法消除的。所谓抽样误差(Sampling error),就是指按随机原则抽样时,在没有登记性误差和系统性误差的条件下,单纯由用样本得出估计量而产生的偶然性的代表性误差。 (一)抽样平均误差 由于样本统计量的随机性,抽样误差也是随机变量,因此,个别样本的抽样误差大小是很难估计的。然而,全部可能样本的样本指标与总体参数的平均离差程度是可以度量的,这个统计量称为抽样平均误差(Mean sampling error)。 1.抽样平均误差的计算。以样本均值为例,抽样平均误差的计算公式为:
所以,抽样平均误差即为样本均值的标准差,若已知总体标准差σ,即可方便地计算得到抽样平均误差。 在实际工作中,往往进行的是不放回抽样,在不放回抽样条件下,同样可以证明,抽样平均误差为:
当N很大,相对n很小时,不放回抽样与放回抽样的结果近似相等,实际中可以将不放回抽样按照放回抽样处理。 在计算抽样平均误差时,本标准差通常得不到总体标准差的数值,此时可用σ的无偏估计量S*来代替总体标准差。S*的计算公式是:
在大样本的情况下,也可以用样本标准差的一般公式计算S来代替总体标准差:
成数的抽样平均误差与均值相似,若用σp表示成数抽样平均误差,有: 放回抽样 不放回抽样 同样当N很大,相对n很小时,不放回抽样与放回抽样的结果近似相等,实际中可以将不放回抽样按照放回抽样处理。 在得不到总体成数P的资料时,如果n≥30也可以用总体成数的优良估计量即样本成数p来代替。 例6-1:一批食品罐头共60000桶,随机抽查300桶,发现其中6桶不合格,求合格率的抽样平均误差。 根据已知条件 放回抽样 不放回抽样
2.抽样平均误差的影响因素。抽样平均误差的大小受以下几个因素的影响: (1)样本量n的大小。在其他条件不变的情况下,抽样单位数越多,样本就越能反映总体,误差就越小。若当抽样单位数接近总体单位数时,此时的抽样调查已接近于全面调查,抽样误差接近于零。反之,抽样单位数越少,误差越大。 (2)总体方差σ2的大小。在其他条件不变的情况下,总体被研究标志的变异程度越小(σ2小),说明总体各单位标志值之间差异小,这样样本指标与总体指标之间的误差也小。相反,若总体被研究标志变异程度大(σ2大),则样本指标与总体指标之间的误差也大。 (3)抽样组织方式。采取不同的抽样组织方式,所抽出的样本对于总体的代表性也不相同,因此,抽样组织方式影响抽样误差的大小。在实践中,我们可以利用不同抽样组织方式下抽样误差的大小,来判断不同方式的有效性。 (4)抽样方法。抽样方法有放回和不放回抽样两种,若其他条件相同,不放回抽样的抽样误差一般小于放回抽样的误差,这是因为不放回抽样避免了总体单位的重复中选,因而更能反映总体结构,故抽样误差会较小些。 (二)抽样允许误差 以样本统计量估计总体参数必须考虑抽样误差的大小,误差越大则样本的价值越小;同时误差也非越小越好,因为在一定限度之下减少抽样误差会增加抽样的难度。所以在进行抽样估计时,应根据所研究对象的变异程度和分析任务的要求确定可允许的误差范围。这种可允许的误差范围称为抽样允许误差(Permissible sampling error),表现为样本统计量可允许变动的上限或下限与总体参数之差的绝对值。 设
由于抽样平均误差反映误差的一般水平,因此,抽样允许误差往往以抽样平均误差的Z倍来界定,即
三、参数估计 用样本统计量估计总体参数有点估计和区间估计两种形式。 点估计(Point estimator)就是估计总体参数的一个值,即直接用样本指标来代替总体指标。例如,为了掌握一批产品的平均寿命,从中随机抽取100件产品,测得该样本的平均寿命为960小时。因此,用点估计方法可以估计该批产品的平均寿命即为960小时。 由于点估计的结果具有很强的近似性,且没有办法掌握这一估计的把握程度,因此,实践中使用较少,而更多使用的是区间估计方法。 区间估计(Interral estimator)就是给出总体参数以一定的概率把握程度1-α可能落入的区间,这一区间称为估计区间或置信区间,一定的概率把握程度称为概率度或置信度,α称为显著性水平。 置信区间表达了区间估计的精确性,置信度表达了区间估计的可靠性。在进行区间估计时,必须同时考虑置信区间与置信度两个方面,若置信度定得比较大即可靠性高,则置信区间相应的也较大即准确性低。因此,可靠性与准确性要结合具体问题、具体要求全面考虑。 (一)总体均值的区间估计 1.一个总体均值的区间估计。一个总体均值的区间估计就是找出总体均值μ以一定的概率把握程度1-α可能落入的区间(
则,
根据第五章第二节所述,如果样本为大样本,或者为抽自方差已知正态总体的小样本,样本均值服从正态分布,这时上式中的zα/2为将样本均值分布转换成标准正态分布后的双侧上α/2分位点。根据事先给定的把握程度1-α,查附录二表2标准正态分布双侧分位数表,可得zα/2值。即
因而有:
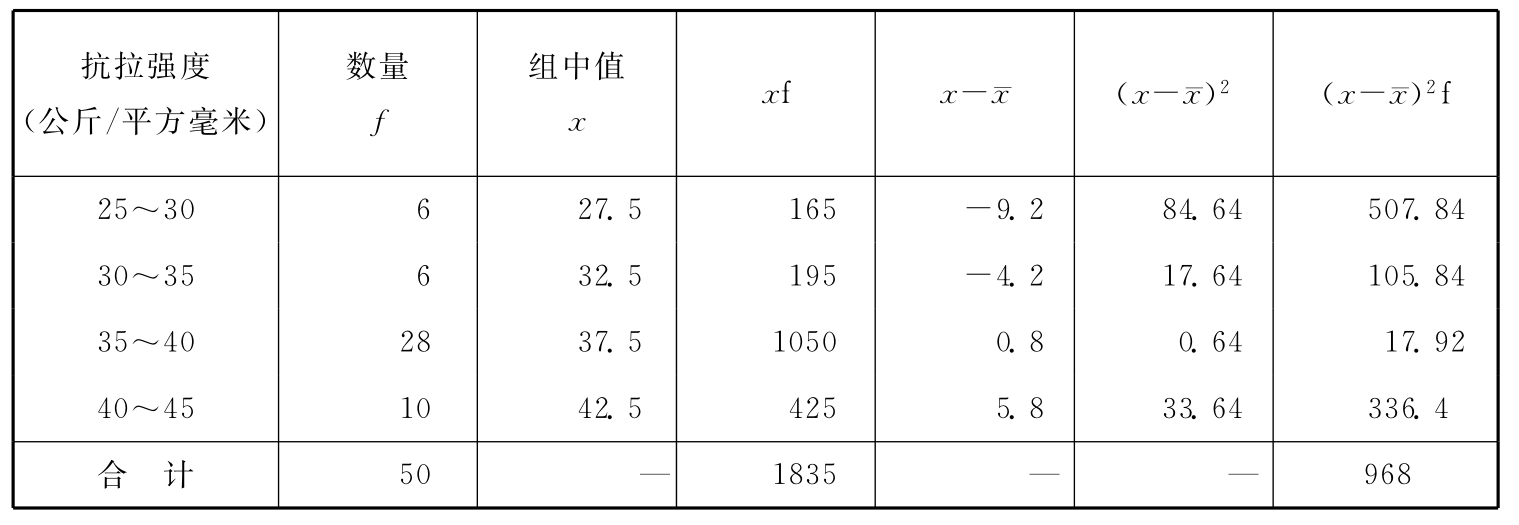
即总体均值μ在1-α的把握程度下的估计区间为 这里,把握程度1-α也称置信度,估计区间 在对μ的实际估计中,一般事先给定估计的概率保证程度1-α,即估计的把握程度,再由把握程度确定 例6-2:某轧钢厂生产一批圆钢,为了解这批圆钢的抗拉性能,从这批产品中随机抽出50根做抗拉强度试验,实测结果如表6-1所示。要求在95.45%的概率保证下估计这批圆钢的抗拉强度。 由表6-1计算出50根圆钢抗拉强度的样本均值(公斤/平方毫米):
由表6-1计算出50根圆钢抗拉强度的样本方差:
表6-1 样本均值与方差计算表
抽样平均误差: 此例的试验为破坏性的,因此属于不放回抽样,然而,此例N■n,所以按放回抽样公式计算的
由题意有zα/2=2,于是抽样允许误差(公斤/平方毫米)为:
故在95.45%的把握程度下可推断该批圆钢的抗拉强度范围为(36.7±1.24),即抗拉强度为35.44~37.94公斤/平方毫米。 由前述抽样推断原理可知,当样本量小于30,且抽自方差未知正态总体时,可以使用t分布对总体参数进行区间估计。 应用t分布估计总体参数时,抽样允许误差为:
式中t值根据给定的把握程度1-α及自由度(=样本量-1)由附录二表4 t分布双侧分位数表查得。t分布表的结构不同于正态分布表,查表时要使用自由度和α值两个参数。α值表示总体参数落入置信区间以外的概率,若要求以95%的把握估计总体参数取值范围,则α=100%-95%=5%。为方便起见,分位数表只给出对应几个常用α值的数值,如α=10%、5%、2%和1%。 式中 当放回抽样时
当不放回抽样时
在小样本情况下,采用不放回抽样很容易满足n/N很小的条件,因此,可以将不放回抽样按照放回抽样处理。 例6-3:某单位为了解其平均日耗电量情况,随机调查了15天的耗电情况。调查结果表明,这15天平均日耗电量为362千瓦·时,样本方差为493,若已知日耗电量服从正态分布,要求以95%的把握程度估计该单位的日耗电量水平。 由题意可知: 自由度为15-1=14,α=5% 于是由附录二表4 t分布表可查得t值为2.145。 由于总体耗电可认为是无限大,故按放回抽样公式计算
于是平均日耗电量的抽样允许误差为:
因此,在95%的把握程度下,该单位日耗电量水平范围为(362±12.3),即该单位平均日耗电量为349.7~374.3千瓦·时。 2.两个总体均值之差的区间估计。如果两个总体均为方差已知的正态总体,则有:
标准化转换后有:
则μ1-μ2的估计区间为:
例6-4:为测定甲、乙两厂生产的某种材料的拉力强度是否相同,从甲厂抽取36个样本,测得平均拉力为29公斤,从乙厂抽取25个样本,测得平均拉力为27公斤。根据过去的经验,两厂产品拉力强度的方差均为14,试以95%的把握程度估计两厂产品拉力强度的差,以确定两厂产品的拉力强度是否有显著差别。 解:据已知条件,
因此,μ1-μ2的估计区间为
即有95%的把握说明两厂产品的抗拉强度之差在0.09~3.91公斤之间。 如果两个总体均为正态总体,方差未知,但
式中:
则μ1-μ2的估计区间为:
例6-5:为了解某农作物两个品种的产量差异,随机调查了8个地区,结果如下(单位:公斤/亩): A品种 430,435,280,465,420,465,375,395 B品种 400,395,290,455,385,410,380,330 假定这两个品种的亩产量分别服从正态分布,且方差相等,试以95%的把握程度估计两个品种亩产量之差。 解:n1=n2=8为小样本,tα/2(n1+n2-2)=2.14,则
μA-μB的估计区间为:
即有95%的把握两个品种亩产量之差在-28.3~83.3公斤之间。 (二)总体成数的区间估计 1.一个总体成数的区间估计。由前述样本成数的抽样分布已知,在大样本情况下,样本成数趋于正态分布,因此,对于给定的把握程度1-α,一个总体成数P的估计区间为p±zα/2σp。 例6-6:在例6-2中若规定抗拉强度小于30公斤/平方毫米为不合格品,试在95.45%的概率保证下估计这批圆钢的合格率。 由例6-2中已知的资料可以计算出样本的合格率为 抽样平均误差的计算。因为总体N》n,所以用放回抽样公式计算,即:
由题意,zα/2=2,于是有抽样允许误差: Δp=zα/2σp=2×0.046=0.092 总体成数范围为: p-Δp≤P≤p+Δp 0.88-0.092≤P≤0.88+0.092 得 0.788≤P≤0.972 即在95.45%的把握程度下可以断定这批圆钢的合格率在78.8%~97.2%之间。 小样本情况下,样本成数服从二项分布,这时,对于给定的把握程度1-α,可以找到两个常数p1,p2,使 P(p1≤p≤p2)=1-α 并且满足
实际工作中,我们可以用已经编制好的二项分布参数P的置信区间表,而不必按照区间估计的原理确定区间的上下限。 2.两个总体成数之差的区间估计。如果两个样本分别抽自两个独立总体,则当样本容量足够大时,p1-p2近似服从正态分布,记作
标准化转换后,有:
则P1-P2的置信区间为:
例6-7:两家日化厂生产两种品牌洗衣粉,为比较两种洗衣粉的洗涤效果,现进行抽样调查,调查结果为:使用A厂洗衣粉的360人中144人认为洗涤效果明显,而使用B厂洗衣粉的320人中96人认为洗涤效果明显。试以95%的把握程度估计两种洗衣粉洗涤效果的差异。 解:根据已知条件,有
由于n1=360、n2=320均为大样本,zα/2=1.96,则P1-P2的估计区间为:
即使用A厂洗衣粉洗涤效果明显者所占比例与使用B厂洗衣粉洗涤效果明显者所占比例之差约为3%~17%之间,A厂洗衣粉洗涤效果好于B厂。 需要说明的是,在估计两个总体均值或成数之差时,若估计区间的上下限同为正或负数,可以据此判断两个总体特征值的差异;否则,不能据此判断两个总体特征值的差异。 (三)总体方差的区间估计 设随机变量X~N(μ,σ2),随机变量X1,X2,…,Xn为X的一个样本,则有:
对于给定的置信度1-α,有:
则可得σ2的置信区间为:
例6-8:已知某乳品厂生产的袋装奶粉的重量服从正态分布,但方差未知,现从中随机抽取12袋,测得重量如下(单位:克): 401 409 395 390 405 410 385 398 400 388 402 405 试以95%的把握程度估计总体方差σ2的置信区间。 解:
由n=12,1-α=0.95,查附录二表3得:
则σ2的置信区间为:
即有95%的把握程度总体方差σ2在30.2~173.4之间。 (四)不同抽样组织方式总体参数的区间估计 1.简单随机抽样。简单随机抽样的抽样误差计算、全及总体指标的估计就是本节前面介绍的方法,这里不再赘述。 2.分层抽样。以实际工作中通常采用的等比例抽样为例。 (1)总体均值估计。 首先,计算样本均值。若总体分为k组,则
然后,计算抽样平均误差。 放回抽样 不放回抽样
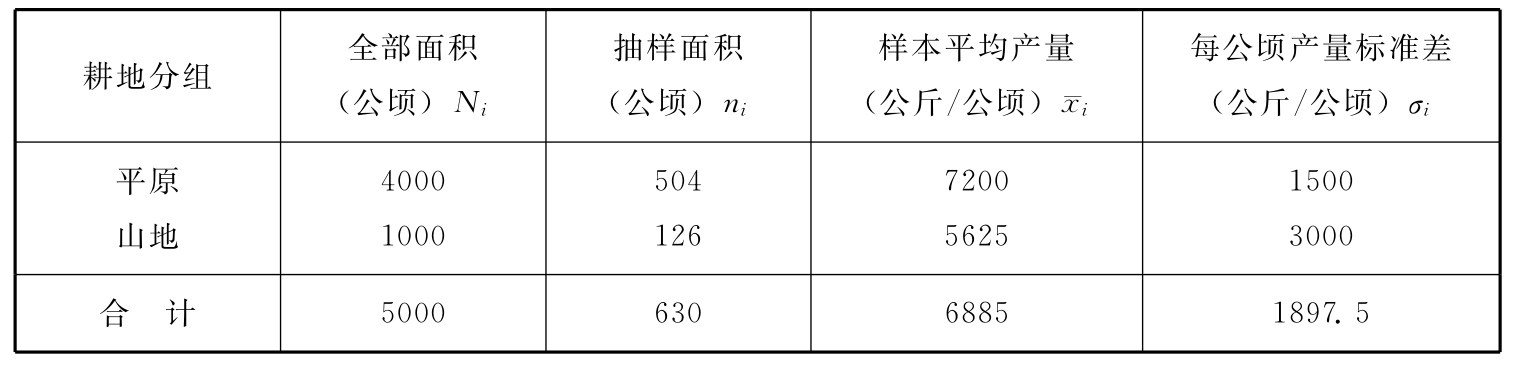
若当各组方差未知时,可以用样本方差代替。 例6-9:某乡种植粮食5000公顷,分种在平原和山地。为了解该乡粮食平均每公顷产量,现采用放回抽样法抽取630公顷作为样本,抽样时根据两种地的面积大小等比例进行抽样。抽样结果见表6-2。 表6-2 分层抽样计算表
由于采用等比例抽样,所以,两种地分别抽取504公顷和126公顷,即:
样本平均产量(公斤):
平均组内方差:
抽样平均误差(公斤):
当概率保证程度为95%时,抽样允许误差(公斤)为: Δ-x=zα/2σ-x=1.96×70.68=138.5 由 μ的置信区间: 有 6746.5≤μ≤7023.5 这就是说,有95%的把握程度认为该乡粮食平均每公顷产量为6746.5~7023.5公斤。 (2)总体成数估计。在对总体进行成数估计时,当总体存在明显的分组且各组的成数相差较大时,应采用分层抽样法。 然后,计算样本方差
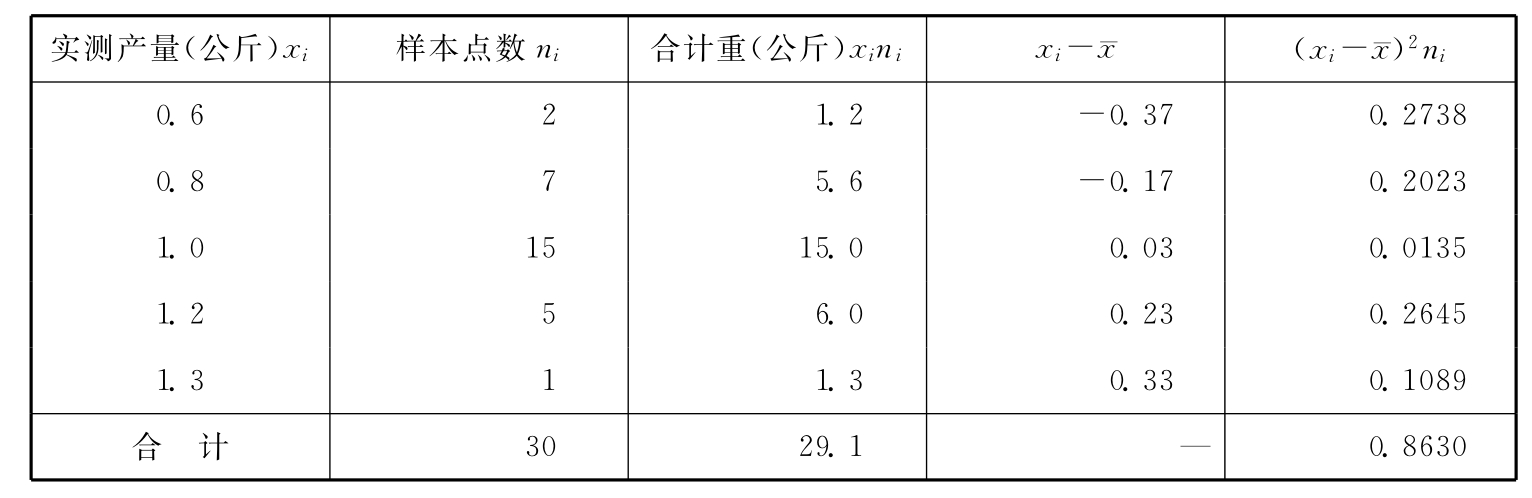
最后,计算抽样平均误差。 放回抽样 不放回抽样 3.等距抽样。等距抽样的抽样平均误差是个很难解决的问题,因此在实践中常用简单随机抽样误差公式近似计算,尤其是对于按无关标志排队的总体。 例6-10:有一长方形麦地,地长300米,宽100米,共200垅。为了解该地小麦的平均每公顷产量及总产量,现采用等距抽样方式抽取30个3米长的垅段作为样本,要求在95.45%的概率保证下估计总体参数。
即每隔2000米选一个样本点。从地角一边样本距离的一半处抽取第一个样本,即第1000米为第一点,该点前后1.5米的垅段为第一个样本,以后每隔2000米如此取样,直至抽够30个样本。设30个样本点的实测数据如表6-3所示。 表6-3 等距抽样样本指标计算表
每垅小麦产量的样本均值(公斤):
即平均每3米长的垅段产小麦0.97公斤。
抽样平均误差(公斤): 由于
则
即每3米长垅段的小麦产量在(0.97±0.062)公斤之间。 下面计算每公顷平均产量:
于是样本每公顷产量(公斤/公顷)为:
即样本每公顷产量在6053~6880公斤之间,该地总产量(公斤)则为: 6050×3=18150 6880×3=20640 即该地总产量在18150~20640公斤之间。 4.整群抽样。整群抽样中,群的划分有等群与不等群两种,即各群所含单位数可以相等也可以不等。下面我们所要讨论的是等群的整群抽样估计方法。 (1)总体均值估计。设总体全部单位划分为R群,从R群中随机抽取r群组成样本,于是有: 总体均值:
其中:μi表示总体各群的均值。 样本均值:
其中: 总体方差与样本方差。由于整群抽样群内各单位是全面检查的。因此,整群抽样的抽样误差取决于各群之间差异的大小。于是有 总体群间方差:
样本群间方差:
抽样平均误差的计算。整群抽样均是按不放回抽样法进行的,不存在放回抽样,于是有抽样平均误差:
例6-11:某化肥厂一天可生产化肥14400袋,平均每分钟生产10袋化肥。为了解某一天所生产化肥的平均每袋净重,现在对某天生产的化肥采用整群抽样方法进行调查,即每隔144分钟抽出1分钟的化肥进行检查,共抽10分钟的产量。要求在95%的概率保证下,估计这一天每袋净装化肥的平均重量。抽样结果见表6-4。 表6-4 整群抽样计算表
由题意可知,每次抽出1分钟的产品进行检查,因此每1分钟产品即为一群,又由于全天24小时连续生产,于是 全天生产的化肥总群数(群)为: R=24×60=1440 或 抽得的样本群数(群)为:
样本的平均每袋重量(公斤/袋)为:
群间方差为:
抽样平均误差(公斤/袋)为:
当概率保证为95%时,查表得zα/2=1.96。 于是有抽样允许误差(公斤/袋):
所以 μ的置信区间: 即在95%的概率保证下,可以推断该天生产化肥的平均每袋重量在48.5~50.5公斤之间。 (2)总体成数估计。设Pi为全及总体各群的成数,pi为样本群的成数,于是有总体和样本成数:
总体和样本的群间方差分别为:
抽样平均误差为:
5.阶段抽样。下面我们将着重介绍两阶段的抽样方法和总体参数估计。 设将总体划分为R组,每组包含Mi个单位。第一步从R组中随机抽取若干组,第二步从中选的组(共r组)中分别随机抽取mi个单位,然后组成样本。用字母表示以上数字关系为: 总体单位数:N=M1+M2+…+MR 样本单位数:n=m1+m2+…+mr 上面的各Mi值可以是相等的,也可以是不相等的;各mi值也可有相等和不相等之分。下面我们将讨论Mi和mi均分别相等的情况,即:N=RM,n=rm。 设Xij为第i个样本组中第j个样本单位的标志值,则第i个样本组的样本均值为:
所有r组的样本均值为:
抽样平均误差为:
式中: 当总体的 例6-12:调查某地区居民人均月收入情况。该地区共有60个街道,平均每个街道有100户居民。现采取两阶段抽样方法,先从总体中抽取5个街道,然后从中选的街道中再抽取6户居民进行调查,调查结果见表6-5。要求,在95.45%的概率保证下,估计这一地区居民的人均月收入水平。 表6-5 两阶段抽样样本指标计算表
中选户人均收入的均值(元)计算:
样本平均组内方差计算: 各组的方差为
于是,有平均组内方差:
组间方差:
于是,中选户人均收入的抽样平均误差(元)为:
由题意可知zα/2=2,于是中选户人均收入的抽样允许误差(元)为:
于是,可以以95.45%的概率估计该地区居民人均月收入为296.26~325.34元之间。 四、样本单位数的确定 从理论上讲,样本量越大,样本指标的代表性越强,但是,如果样本量过大,必然增加抽样调查的难度。因此,在抽样调查方案的设计中,需要根据所研究问题的性质确定允许的误差范围和必要的概率保证程度,然后通过历史资料或其他试点资料确定总体标准差σ,运用抽样允许误差公式来推算必要的样本单位数n。 这里我们以简单随机抽样且样本统计量服从或近似服从正态分布为例介绍确定样本单位数的方法。 (一)估计均值的样本量 1.放回抽样: 由 有 2.不放回抽样: 由 得 上面式中的σ2往往是利用以往的经验数据,因为这时还没有抽样,因此不可能用样本方差来代替未知的总体方差σ2。 (二)估计成数的样本量 1.放回抽样: 由 得 2.不放回抽样: 由 得 与前面遇到的问题一样,式中P往往不知道,一般情况是利用以往的资料来确定。 例6-13:现要对某种型号电池的电流强度进行检验,按以往正常生产经验,电池电流强度的标准差为0.4安培,电池合格率为90%。现用放回抽样方式,并要求概率保证程度为95.45%,若电流平均强度的抽样允许误差不超过0.08安培,合格率的抽样允许误差不超过5%,求必要的抽样单位数。 在放回抽样条件下,检测电流强度: 由σ=0.4,zα/2=2, 需要检测电流强度的电池数(只)为:
在放回抽样条件下抽检电池合格率: 由p=0.9,zα/2=2,Δp≤0.05 需抽检的电池数(只)为:
由上面计算可知,若分别抽检电流强度和电池合格率指标,样本单位数分别取100和144。如果要求同时检查电流强度和合格率指标,则应取n=144进行抽样,以满足两种指标的抽样要求。 免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。 我要反馈 |
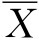 和样本成数p均满足上述三条标准,因此,它们是总体参数μ和P的优良估计量。
和样本成数p均满足上述三条标准,因此,它们是总体参数μ和P的优良估计量。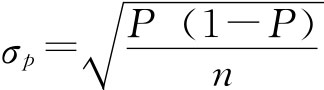
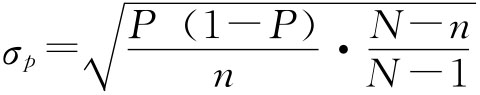
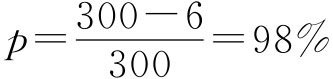
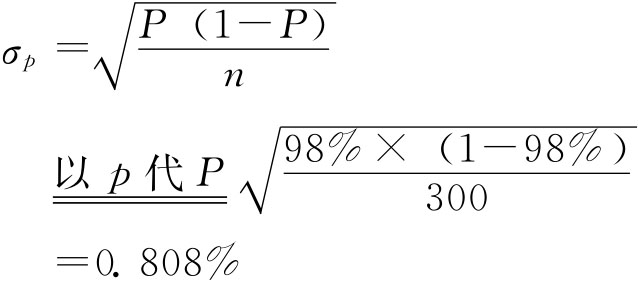
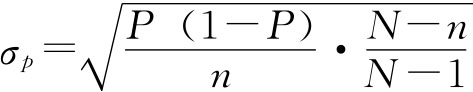
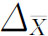 、Δp分别表示样本均值允许误差和样本成数允许误差,则有:
、Δp分别表示样本均值允许误差和样本成数允许误差,则有: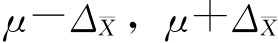 ),其中,
),其中,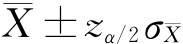 。
。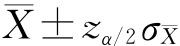 也称置信区间。
也称置信区间。 。
。
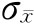 (公斤/平方毫米)为:
(公斤/平方毫米)为: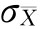 的计算:
的计算: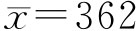 ,s2=493
,s2=493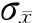 :
: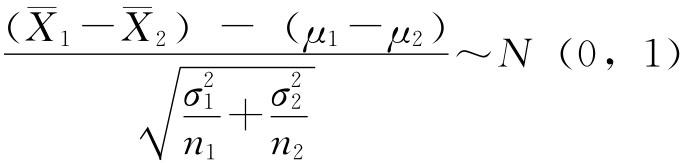
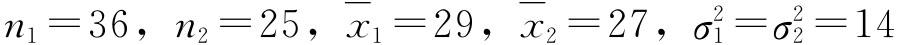
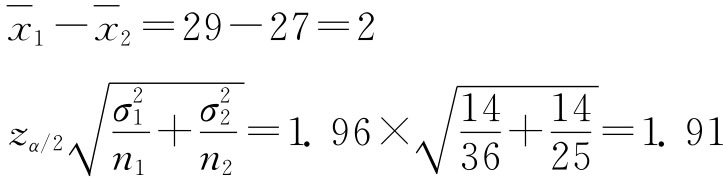
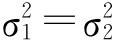 ,则有:
,则有: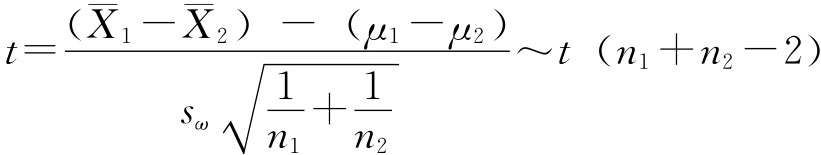
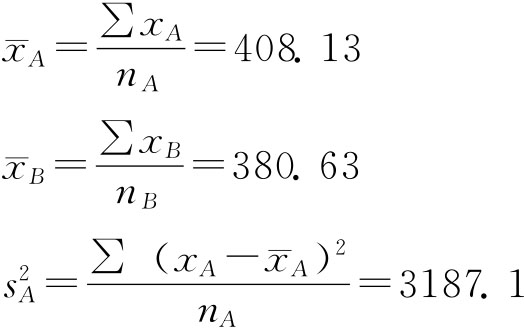
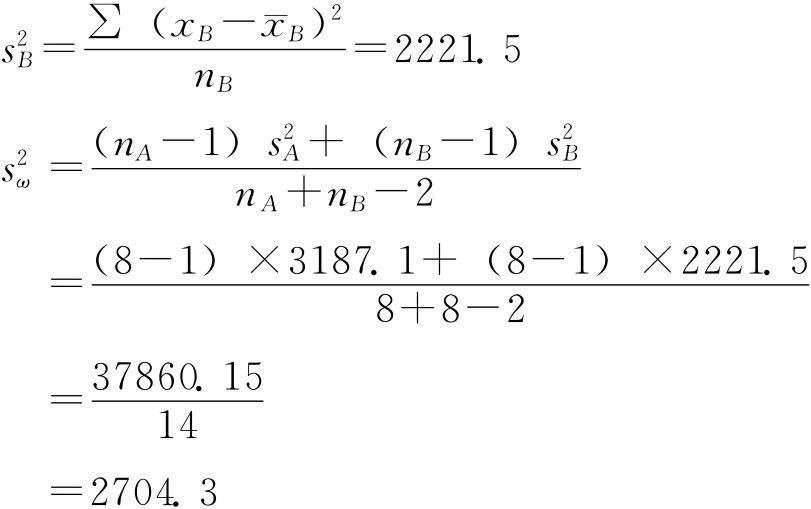
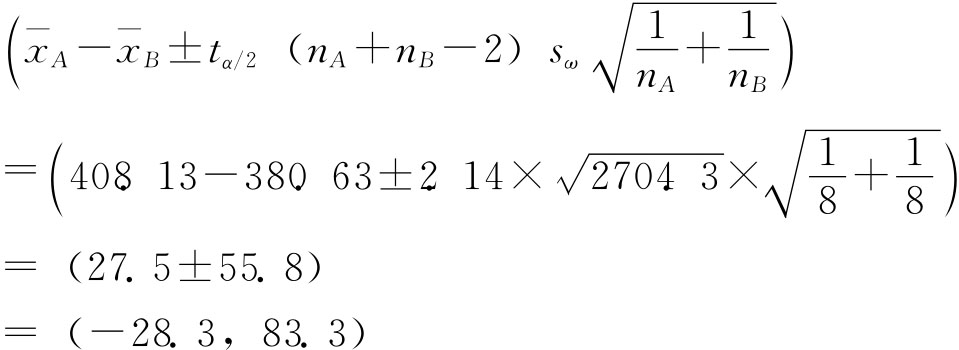
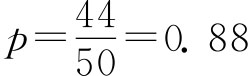 。
。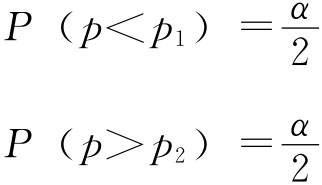
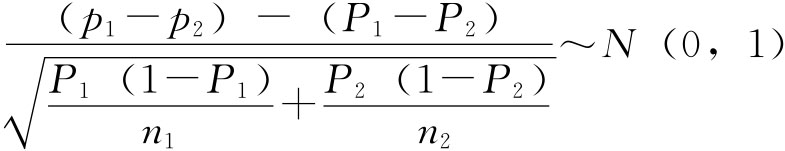
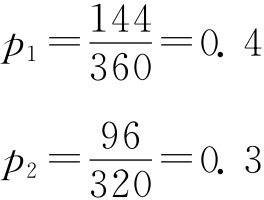
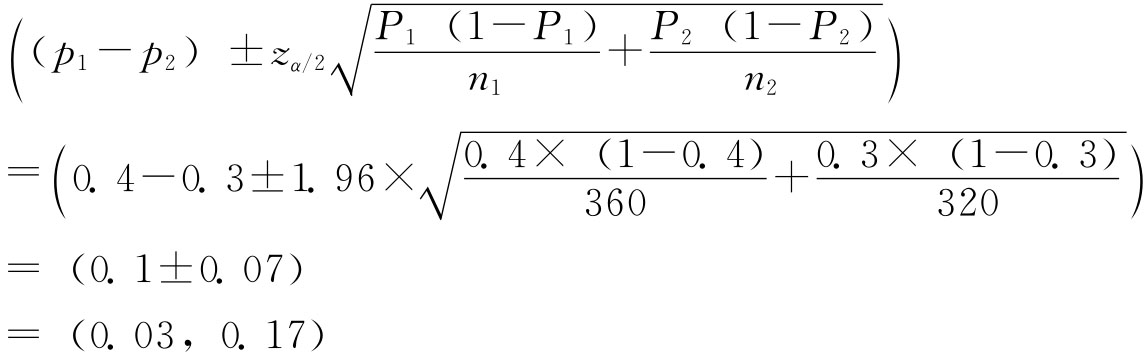
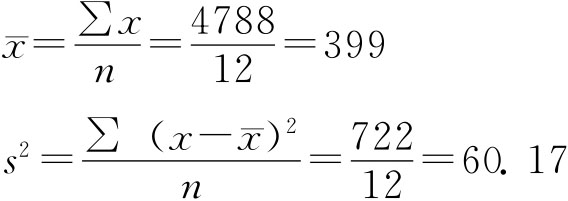
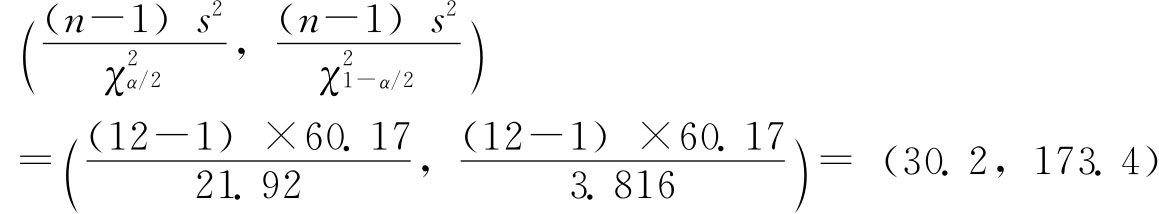
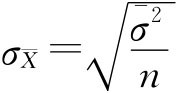
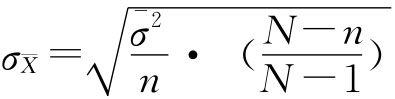

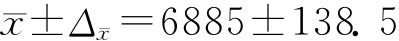
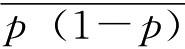 。
。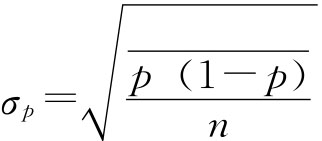
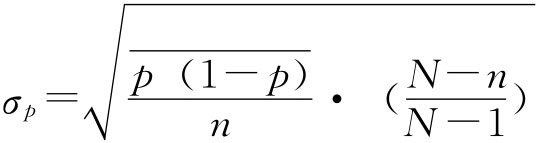
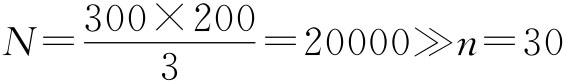 ,所以,采用放回抽样公式计算。
,所以,采用放回抽样公式计算。
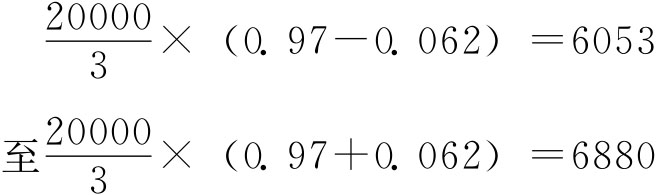
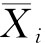 表示样本中各群的均值。
表示样本中各群的均值。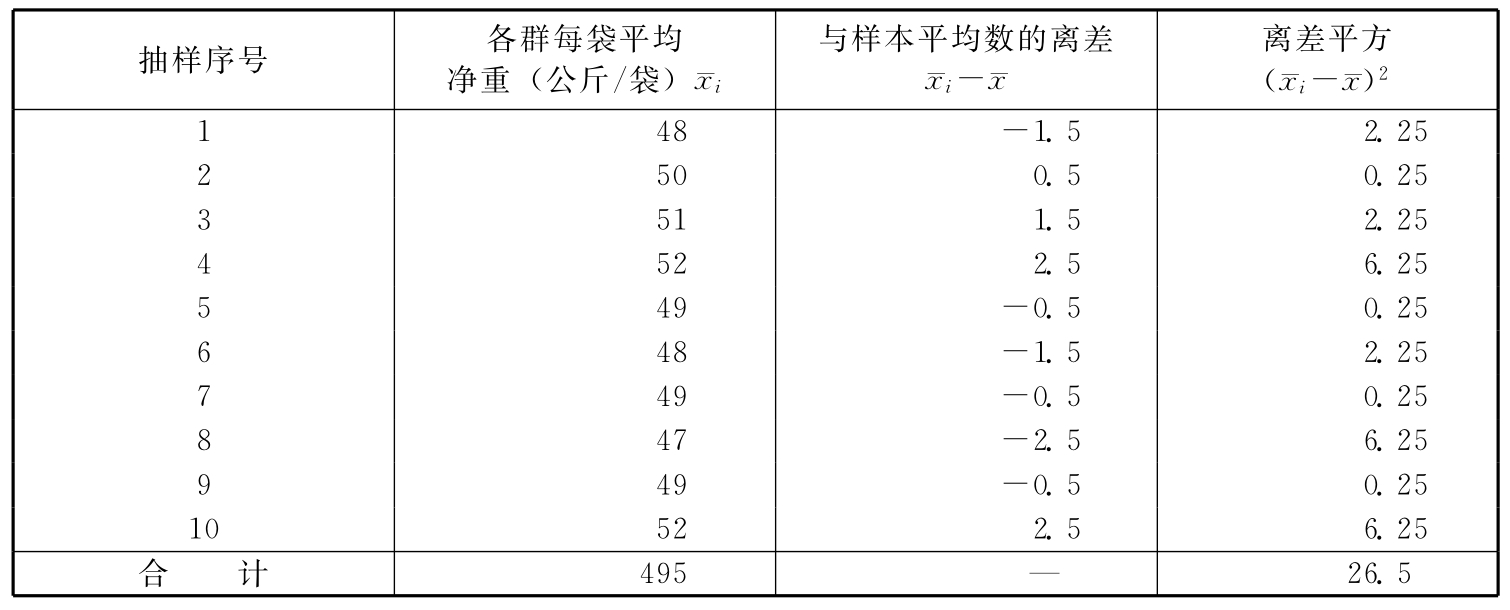
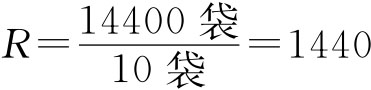
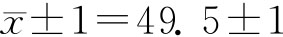
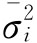 表示各组内方差的平均值;δ2表示组间方差。
表示各组内方差的平均值;δ2表示组间方差。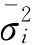 与δ2未知时,可以用样本的相应指标来代替。
与δ2未知时,可以用样本的相应指标来代替。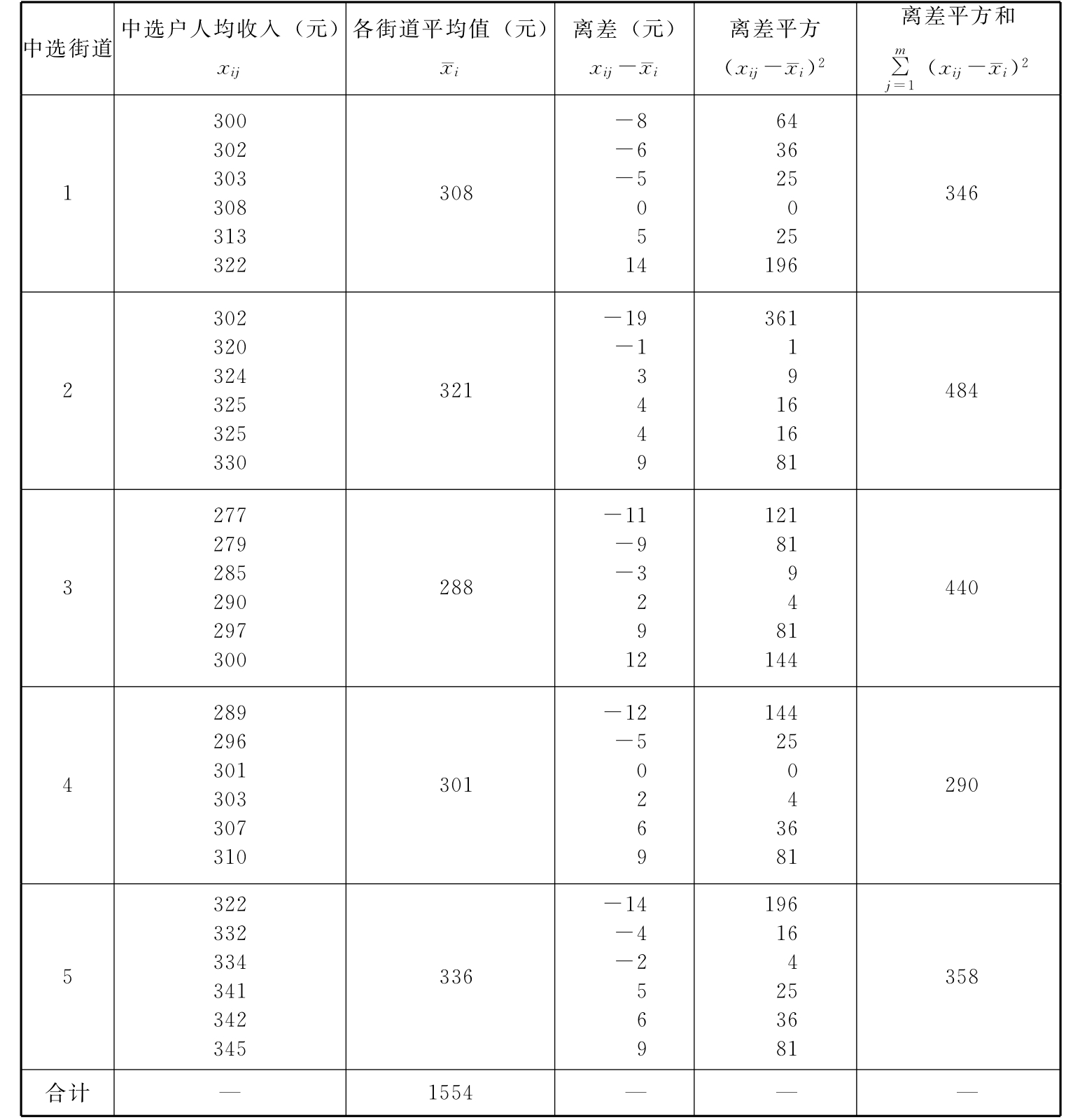
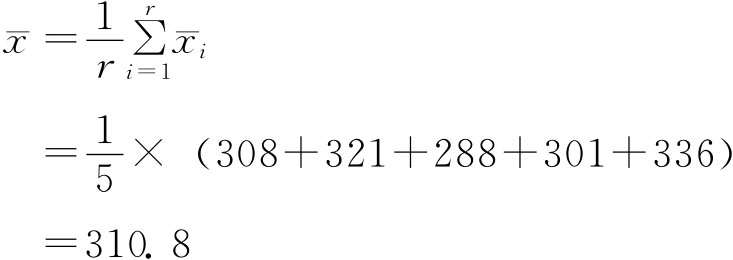
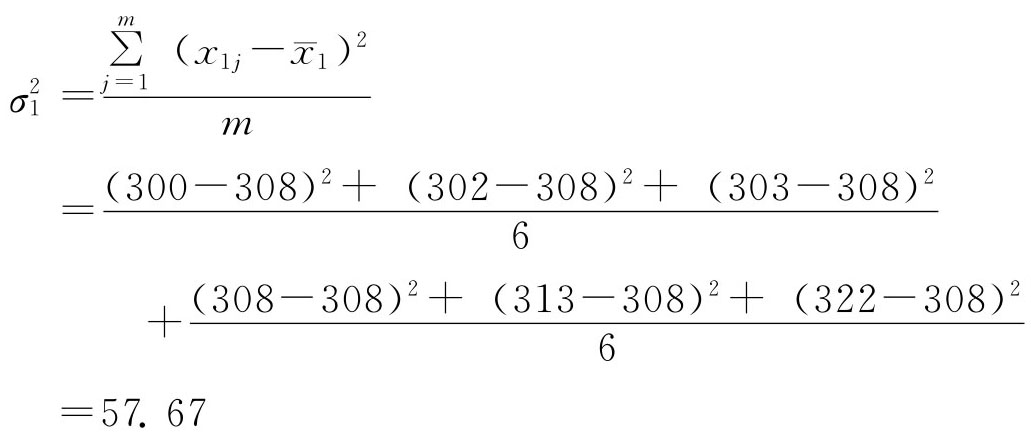
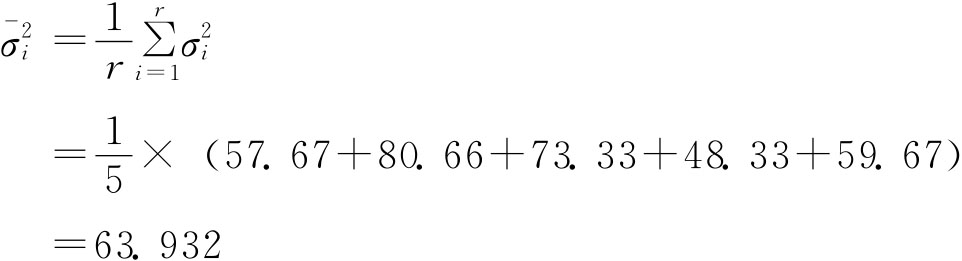
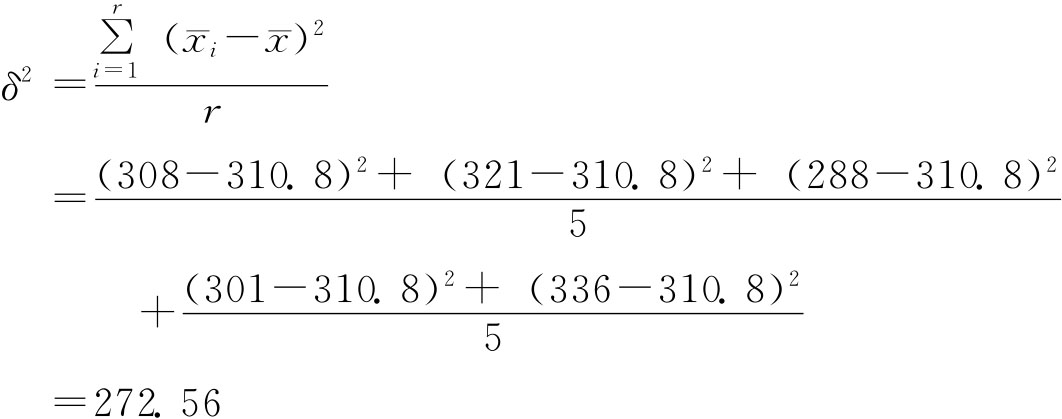
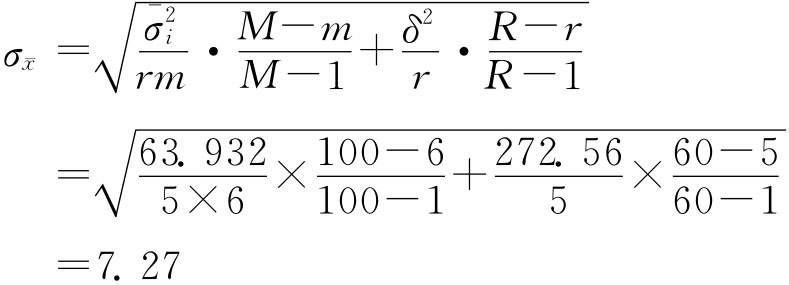
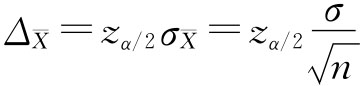
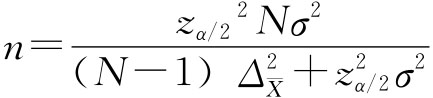
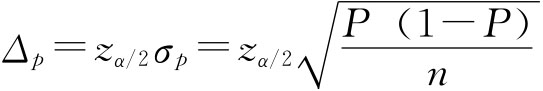
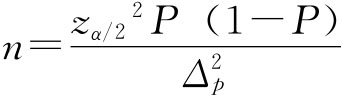
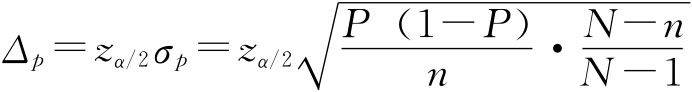
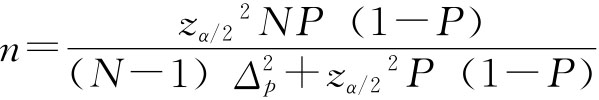
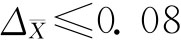
【本文地址】
今日新闻 |
推荐新闻 |