批量提取某音视频文案(二) |
您所在的位置:网站首页 › 抖音链接提取文案源码 › 批量提取某音视频文案(二) |
批量提取某音视频文案(二)
|
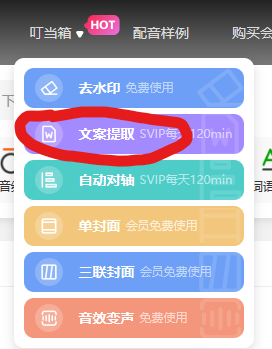
牙叔教程 简单易懂 之前写过一篇 批量提取某音视频文案 , 在之前的教程中, 我用的是微软的语音转文字功能, 今天我们换个方法, 使用 逗哥配音 的 文案提取 功能
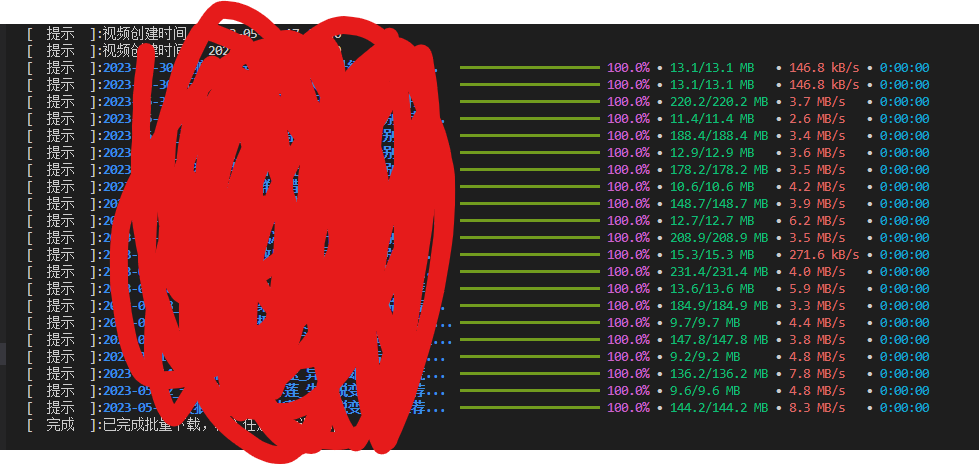
我在github找到的是这个仓库 https://github.com/Johnserf-Seed/TikTokDownload 注意一定要阅读 readme.md , 并且 一定运行 ./server.bat 启动本地接口解析, 每次我老是忘记运行 bat, 所以总是报错, 运行以后就不会报错了 这是我批量下载的视频和音频
红色的是视频 蓝色的是音频
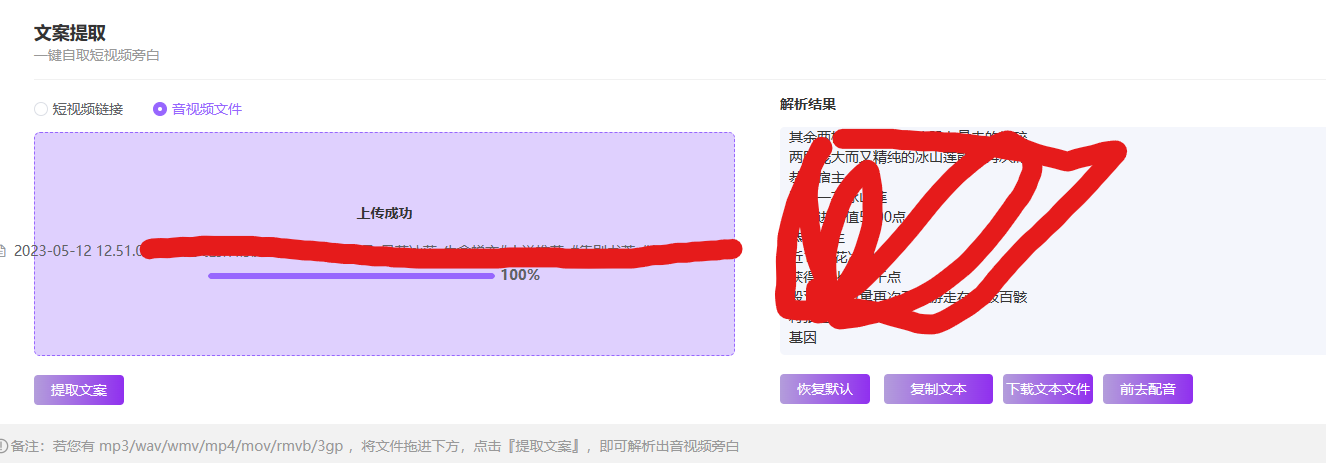
把音频上传, 然后点击提取文案即可, 10分钟的音频, 消耗时间 25 秒 文案就提取出来了
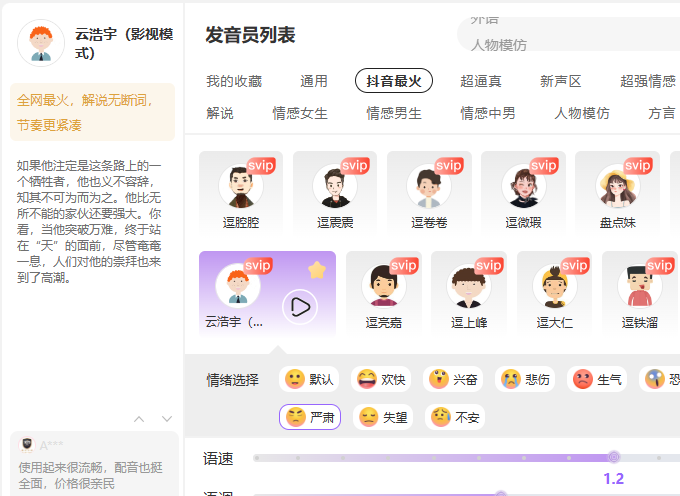
提取文案以后, 我们改吧改吧就要把它变成视频, 改文案的两种工具 ChatGPTClaude 改文案技巧把文案喂给 AI , 让 AI 模仿写作专家来写文案, 让 AI 当 古龙, 金庸, 司马迁, 鲁迅, 把指定作家的作品告诉给 AI , 让他拥有这个作者的人格和技能 AI 写出文案以后, 我们自己仍然要修改一遍, 因为他写的人称, 描述, 动作, 可能不一定符合你的想法 文案有了以后, 就要转成音频了 文案转音频我们使用 逗哥配音 的 角色 云浩宇, 全网最火, 语速就参考一下同行的语速, 一般都比较快, 很有有文案需要较慢的语速 如果不知道声音的参数如何设置, 可以看 逗哥配音 的帮助文档, 里面还有 AU 调试声音的教程
音频有了以后, 逗哥配音 还可以导出字幕
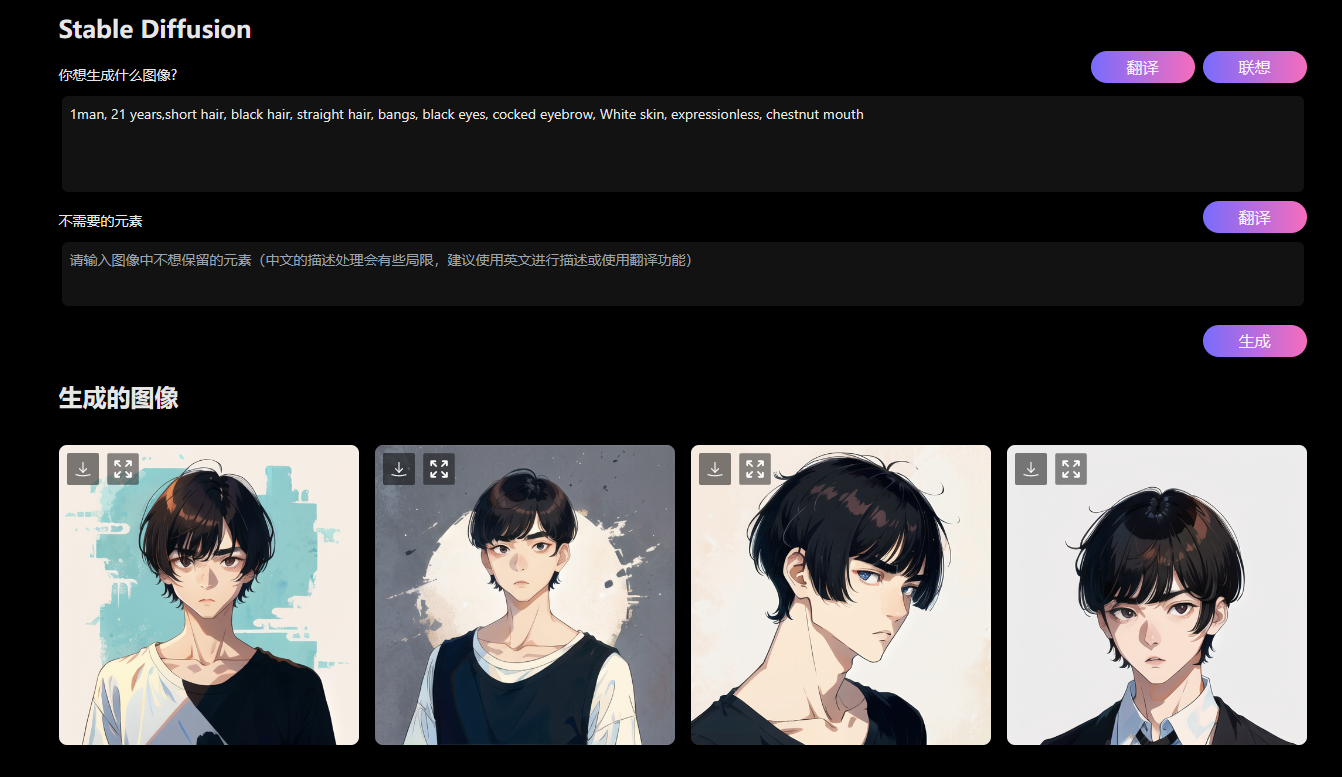
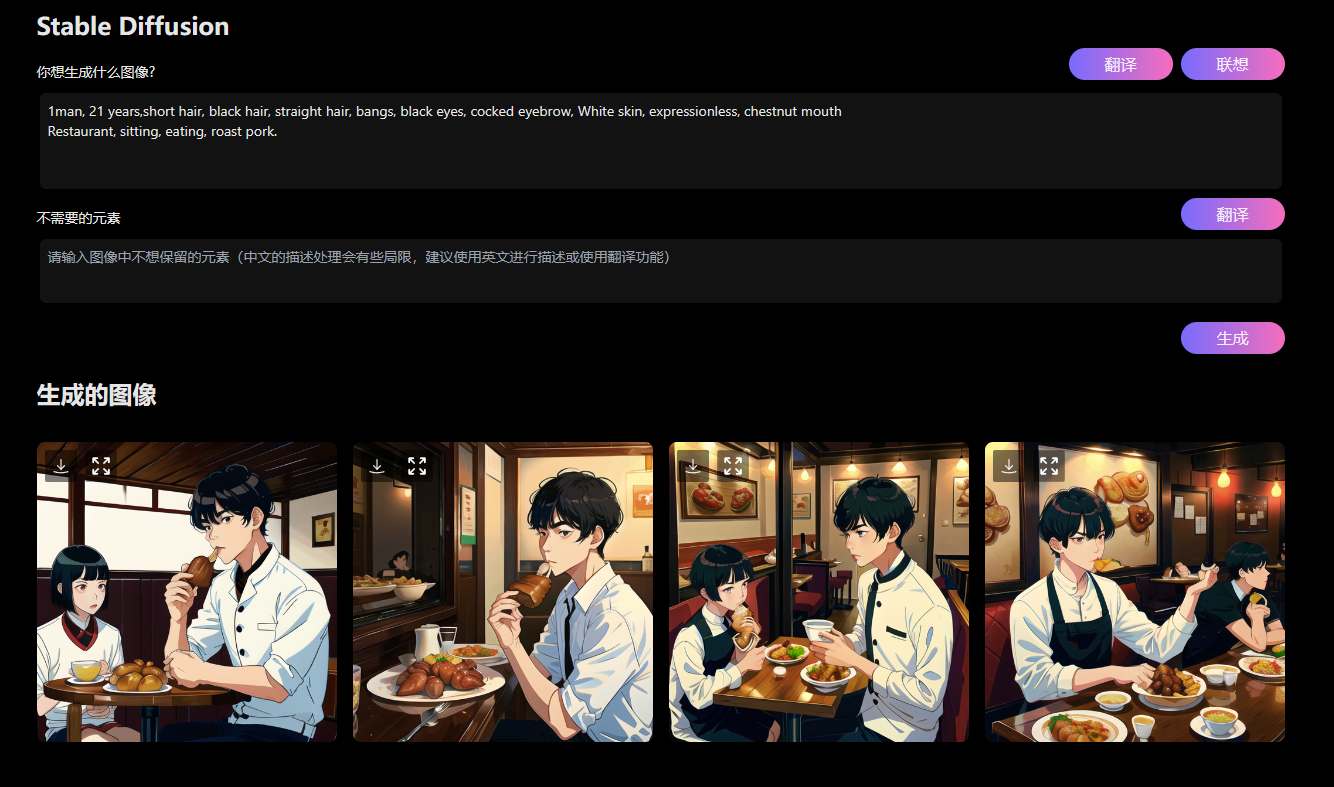
文案转成音频, 并且提取字幕以后, 我们就要出图了 生成图片技巧图片中肯定会有人物出现, 如何固定人物? 我们要指定人物的样子, 尤其是头发和五官 生成图片, 我们使用的是 ChatGPT联网版, Stable Diffusion画图, 这个星球全都有, 低调使用, 别外传 这是人物咒语 1名男子,21岁,短发,黑发,刘海,黑眼睛,眉毛上翘,白皮肤,无表情,栗色嘴巴 1man, 21 years,short hair, black hair, straight hair, bangs, black eyes, cocked eyebrow, White skin, expressionless, chestnut mouth
让他吃饭 餐厅, 坐着, 吃饭, 红烧肉, 1man, 21 years,short hair, black hair, straight hair, bangs, black eyes, cocked eyebrow, White skin, expressionless, chestnut mouth Restaurant, sitting, eating, roast pork.
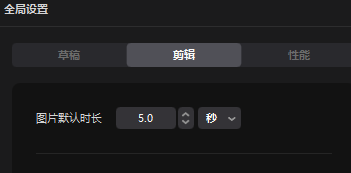
可以看到, 人物相似度是差不多的, 是满足小说推文, 制作视频需求的 图片排序图片生成完以后, 我们要整理图片, 按顺序编号1,2,3, 这样在导入剪映的时候, 图片就是编排好, 后期就不用一个一个找图片了 就按照文案, 按照字幕, 提前给图片排序 剪映图片默认时长是 5 秒
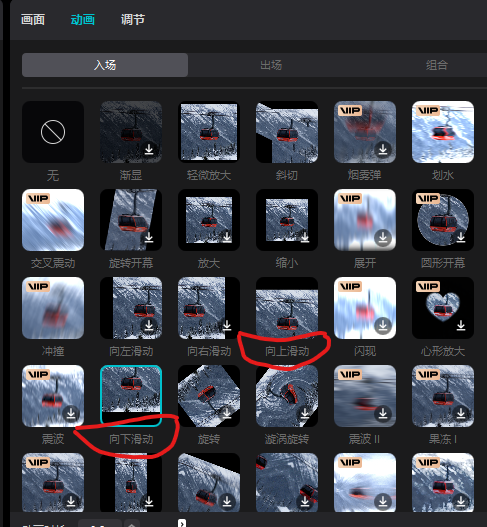
使用剪映做小说推文必用的快捷键 分割图片 Ctrl + B 上一分割点 ↑ 下一分割点 ↓ 上一帧 ← 下一帧 → 轨道放大缩小 Ctrl + 滚轮 轨道左右移动 Alt + 滚轮 打关键帧不懂关键帧的可以看这篇教程 剪映 自动打关键帧 AutoHotkey 关键帧如果打错位置的话, 可以用鼠标拖动关键帧, 直接拖到图片尾部 除了图片要打关键帧, 有时候, 蒙版有时候也要打关键帧, 方法都是一样的. 如果要做 双开门 , 就需要用到 动画 , 向上滑动和向下滑动
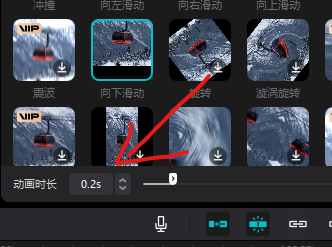
动画时长 0.2 秒
为什么是 0.2 秒呢? 我们看看 ChatGPT 如何解释 将图片的闪现时长设置在0.1-0.3秒,可以使观众在短时间内注意到图片内容。这个建议来自于人眼对视觉刺激的反应时间。 当一个视觉刺激呈现在我们面前时,大脑需要一定的时间来处理这个信息。根据研究,人类对视觉刺激的反应时间大约为0.1-0.4秒不等。所以,将图片的闪现时长设定在0.1-0.3秒之间,能够让观众在短时间内注意到图片,同时又让图片保持了突出的效果。 然而,请注意,在显示速度非常快的情况下,过多快速闪现的画面可能会导致观众感到不适。因此,在设计视频时,请确保在更突出的闪现效果与观众舒适度之间找到平衡。 关键帧打完以后, 就要给视频前几十秒加特效了 特效
特效有以下几种 媒体音频贴纸特效转场滤镜模板男频用音频和特效 女频可能还会用模板 特效加完以后, 就要开始配乐了 配乐伤感文案不能配搞笑音乐, 大佬用啥你用啥 声音渐入渐出
大佬用啥你用啥
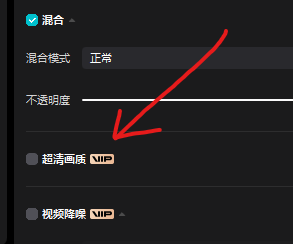
视频一般都取第一帧做封面, 所以我们要在视频开头留下封面的空间 按三下 →, 这三帧就放封面图片 封面之后才开始放其他图片 图片高清Stable Diffusion 生成的图片一般是 512X512 我们可以用512做, 然后再把图片变成高清图片 图片高清软件, 可以看这个教程 图片无损放大-AI为图片开光 这个软件还支持批量处理图片, 并且图片处理之后会覆盖源文件, 名字也是一样的, 当然了, 你也可以设置把处理后的图片放到另外的文件夹 我懒得弄高清, 直接用的剪映的 超清画质
这个超清画质和那些批量高清软件一样, 也是一张一张处理图片 该星球提供 ChatGPT 和 Stable Diffusion支持N多大模型, 就不用你自己一个一个去上传大几G的模型数据了
还支持微调模型, 以及各种VAE
星球提供的ChatGPT可以参考这个教程, 可以直接听歌和看电影 ChatGPT联网版, Stable Diffusion画图, 这个星球全都有, 低调使用, 别外传 微信公众号 牙叔教程 |


【本文地址】
今日新闻 |
推荐新闻 |