python刷抖音视频播放量 python 爬抖音 |
您所在的位置:网站首页 › 抖音视频播放量排名 › python刷抖音视频播放量 python 爬抖音 |
python刷抖音视频播放量 python 爬抖音
|
一、前言 前面我们已经用 appium 爬取了微信朋友圈,今天我们学习下 mitmproxy,mitmproxy 是干什么的呢,它跟 charles 和 fiddler类似,是一个抓包工具,以控制台的形式显示,mitmproxy 的重要性在于它可以对接 python,可以通过 python 处理抓包的数据。试想一下我们如果不用 mitmproxy,用 fiddler 抓取抖音的视频地址,我们可以抓到视频的地址,这些地址要是可以直接用requests 缓存下来就好了,mitmproxy 就派上用场了。 GitHub:https://github.com/FanShuixing/git_webspider
二、学习目标
可以根据抖音号和抖音名称爬取到对应的抖音小视频
三、学习资料(感谢分享)
崔大的mitmproxy安装教程:https://cuiqingcai.com/5391.html 抖音教程: fiddler的使用:
四、mitmproxy的安装
请先按照崔大的mitmproxy的安装 进行安装和证书的配置,如果安卓证书安装有问题,可以参看下面(华为手机,应该普遍适用): 把文件复制到手机qq后,可以在文件管理的下载中查看qq文件
第一个是我们下载的证书,长按后勾上它
点击下面的菜单,查看详情,这样可以看见这个证书的具体位置,一会有用
电脑打开360WiFi后,手机连接上360WiFi,在WiFi里面的菜单
安装证书就需要找到证书的位置,这样刚才我们在文件管理里面看到的位置就可以在这儿用到,找到证书安装即可。 配置代理 证书安装完成后,要配置手机和电脑处在同一个局域网内,我建议用360wifi,其它wifi应该也可以,但是最好不要用自己家路由器的wifi,我家wifi测试的时候没成功,360WiFi才成功了的。
如果弄完之后,在cmd中输入mitmdump,在手机中打开浏览器看看有没有网络,看看电脑的控制台有没有输出抓取信息,如果有,恭喜你安装成功。如果没有,憋着急,看看我的办法能不能帮助你: 建议:弄完后我发现手机浏览器中打不开网页,qq和微信是有网络的,我重新安装了一下mitmproxy,不过不是用pip安装,而是直接下载的 安装文件:https://github.com/mitmproxy/mitmproxy/releases, 选择个exe就行
安装好后,查看安装路径下的bin文件夹,里面有个mitmdump.exe,双击它打开代理服务,这个时候再在手机上刷新网页发现mitmdump有请求输出。
五、用fiddler分析接口
不知道大家用 fiddler不,我抓包更喜欢用它,方便简洁,mitmdump 的唯一优势是可以对接 python,但是我感觉它不好分析呀,所以我是把 fiddler开着,分析下接口,再用mitmdump对接python,fiddler我就不介绍了。 网上教程很多,可以参看:(博主大大写的超棒)
我们在手机中打开上图中的页面后,在fiddler中会发现,有一个这样的网址被抓取到
它的json数据中有视频信息
打开aweme_list中的一个{},里面是一个视频的信息,有对视频的描述,也有用户的id,也有video的url
url_list里面的url就是视频的url,随便选一个就是了。
六、对接python # douyin_t.py import json def response(flow): url = 'https://api.amemv.com/aweme/v1/aweme/post/' # 筛选出以上面url为开头的url if flow.request.url.startswith(url): text = flow.response.text # 将已编码的json字符串解码为python对象 data = json.loads(text) print(data) 我把代码保存在了D:\my-python-run\web spider目录下,所以我得先到这个目录下,这样mitmdump才能找到我的python脚本,然后运行命令 mitmdump -s douyin_t.py
在手机上打开抖音,搜索到你想下载的用户的抖音主页
可以发现mitmdump有数据输出
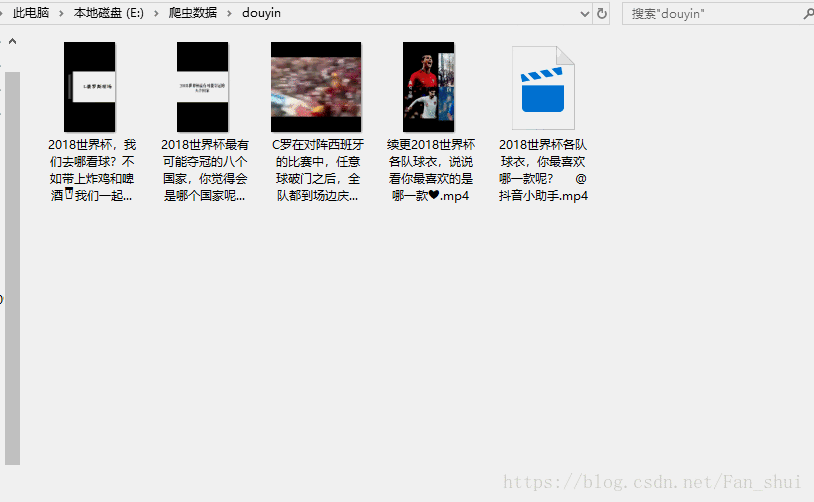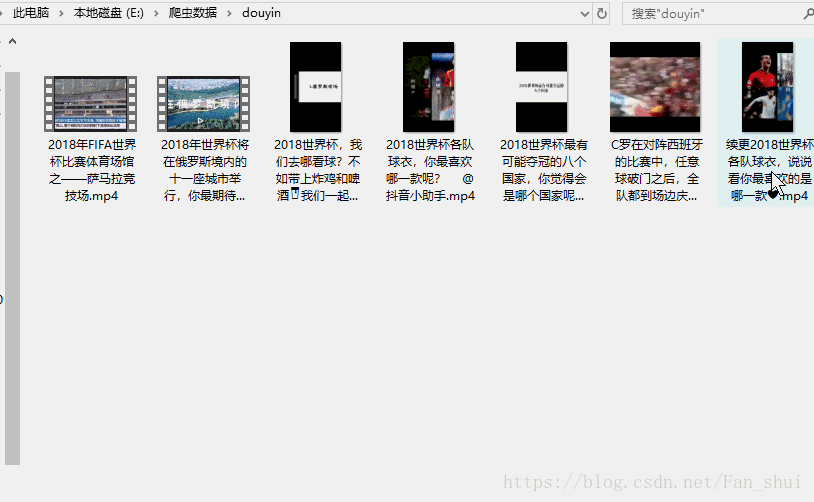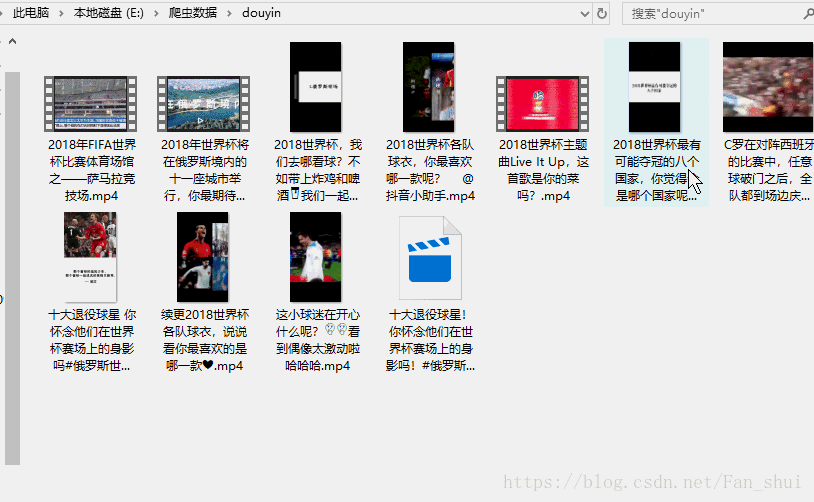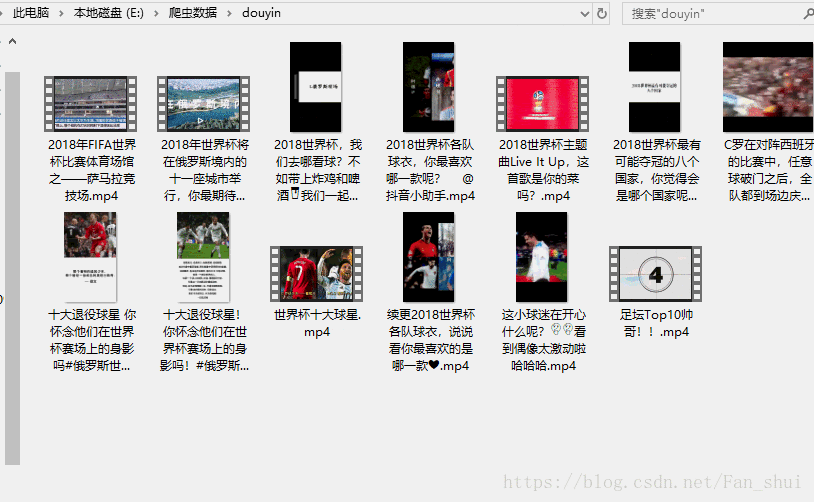
接下来我们只需提取视频的url,并缓存视频到本地 # douyin_t.py import json, os def response(flow): url = 'https://api.amemv.com/aweme/v1/aweme/post/' # 筛选出以上面url为开头的url if flow.request.url.startswith(url): text = flow.response.text # 将已编码的json字符串解码为python对象 data = json.loads(text) # print(data) # 在fiddler中刚刚看到每一个视频的所有信息 # 都在aweme_list中 video_url = data['aweme_list'] path = 'E:/爬虫数据/douyin' if not os.path.exists(path): os.mkdir(path) for each in video_url: # 视频描述 desc = each['desc'] url = each['video']['play_addr']['url_list'][0] print(desc, url)运行如下:
现在只需要用requests把这些url缓存到本地,首先要导入requests库 # douyin_t.py import json, os import requests def response(flow): url = 'https://api.amemv.com/aweme/v1/aweme/post/' # 筛选出以上面url为开头的url if flow.request.url.startswith(url): text = flow.response.text # 将已编码的json字符串解码为python对象 data = json.loads(text) # print(data) # 在fiddler中刚刚看到每一个视频的所有信息 # 都在aweme_list中 video_url = data['aweme_list'] path = 'E:/爬虫数据/douyin' if not os.path.exists(path): os.mkdir(path) for each in video_url: # 视频描述 desc = each['desc'] url = each['video']['play_addr']['url_list'][0] print(desc, url)不幸的是,我只是导入了个requests库,其他什么都没有改程序便报错了
No module named ‘requests’,简直黑人问号脸,怎么会没有requests呢,我天天都在用,怎么会报这个错呢? 解决办法:相信大家也都安装了requests库了的,如果你也报这种错误,我们就再来捣鼓下路径问题,提示是没有requests模块,我非常确定我有这个模块,那只能说明mitmdump在执行脚本的时候没有找到requests模块,那我们可以把我们的脚本douyi_t.py放在与requests一个文件下执行
可以通过上述命令看到我的requests库在D:\my-install\Anaconda\Lib\site-packages,我们把douyin_t.py放在这儿
现在就没有再报错了,接下来的事情就顺利成章了 # douyin_t.py import json, os import requests def response(flow): url = 'https://api.amemv.com/aweme/v1/aweme/post/' # 筛选出以上面url为开头的url if flow.request.url.startswith(url): text = flow.response.text # 将已编码的json字符串解码为python对象 data = json.loads(text) # print(data) # 在fiddler中刚刚看到每一个视频的所有信息 # 都在aweme_list中 video_url = data['aweme_list'] path = 'E:/爬虫数据/douyin' if not os.path.exists(path): os.mkdir(path) for each in video_url: # 视频描述 desc = each['desc'] url = each['video']['play_addr']['url_list'][0] # print(desc,url) filename = path + '/' + desc + '.mp4' # print(filename) req = requests.get(url=url, verify=False) with open(filename, 'ab') as f: f.write(req.content) f.flush() print(filename, '下载完毕')
这个只要我们没有关闭mitmdump运行窗口,我们可以搜索其他的抖音用户的页面,也会被下载下来,不知道大家是更喜欢appium自动化,还是喜欢自己用手滑,嘿嘿嘿嘿 若针对requests导入错误有更好的建议,欢迎分享(●ˇ∀ˇ●)
|






















【本文地址】