Python网络爬虫实战1:百度新闻数据爬取 |
您所在的位置:网站首页 › 找一下百度新闻 › Python网络爬虫实战1:百度新闻数据爬取 |
Python网络爬虫实战1:百度新闻数据爬取
|
目录 一. 获取网页源代码 1. 四行代码获取(有时不灵) 2. 五行代码获取(常用方法) 二、分析网页源代码信息 方法1:F12方法 方法2:右击选择“查看网页源代码” 方法3:在Python获得的网页源代码中查看 三、编写正则表达式爬取信息 1. 获取网页源代码 2. 获取信息的网址和标题 3. 获取信息的来源和日期 4. 数据清洗和打印输出 5. 完整代码 一. 获取网页源代码 1. 四行代码获取(有时不灵)首先通过最简单的四行代码来尝试一下获取百度新闻的网页源代码: import requests # 导入requests库 url = 'https://www.baidu.com/s?tn=news&rtt=1&bsst=1&cl=2&wd=阿里巴巴' # 输入网址 res = requests.get(url).text # 发送请求获取网页 print(res) # 输出网页源码获取到的源码如下图所示:
可以看到我们并没有真正获取到百度新闻的网页源代码,这是因为百度的资讯网站只同意浏览器发送的访问,不同意直接通过python发送的访问请求。这时我们就需要设置 requests.get()中headers参数,用来模拟浏览器进行访问。 2. 五行代码获取(常用方法)Headers参数记录的其实就是网站访问者的信息,代表这个访问的浏览器是哪家的浏览器,headers中的User-agent(中文叫作用户代理)就是反映是用什么浏览器登录的,其设置方式如下所示:(这里就是Chrome浏览器的User-Agent) 通过设定代理,可以爬取一些通过我们网络ip无法访问的网站。还有一些比较成熟的网站,如微博、豆瓣,它们会有非常高超的爬虫检测技术,这时我们就不能爬取它们的网站上的数据。 代理服务器的存在,可以应对网站禁止某个IP访问的反爬虫措施,代理服务器有着不同的匿名类型,通常我们会挑选中、高级别的代理服务器来访问网页。 headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'}
设置完headers之后,在通过requests.get()请求的时候需要加上headers信息,这样就能模拟一个浏览器来访问网站,网站是可以识别我们是否在使用Python进行爬取,需要我们在发送网络请求时,把header部分伪装成浏览器。代码如下: res = requests.get(url, headers=headers).text完整代码如下: import requests headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'} # 用户代理设置 url = 'https://www.baidu.com/s?tn=news&rtt=1&bsst=1&cl=2&wd=阿里巴巴' res = requests.get(url, headers=headers).text # 使用浏览器的用户代理向网站发送访问请求 print(res)运行结果
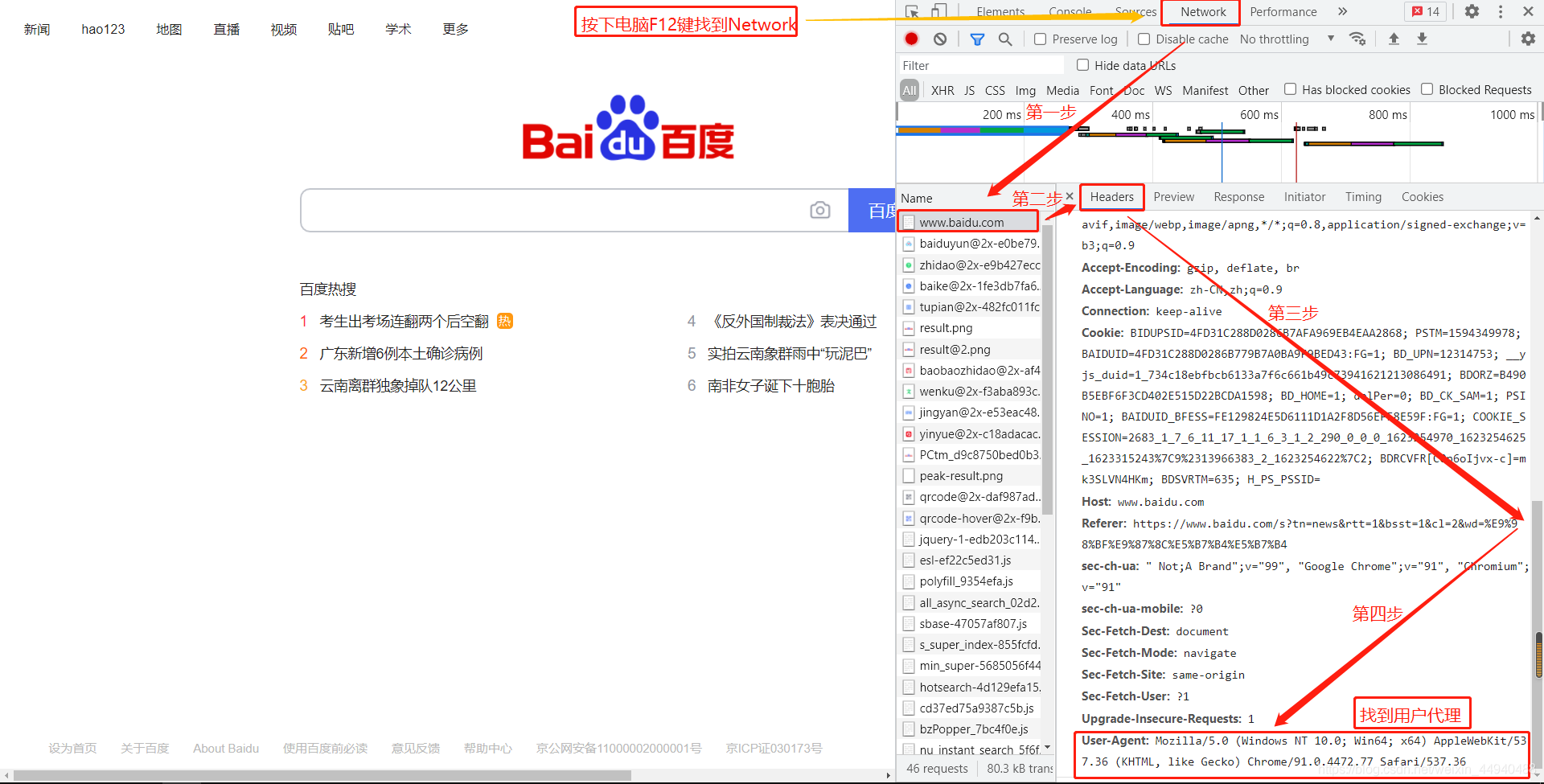
总结:headers只要在开头设置一次,之后直接在requests.get()中添加headers=headers即可,这样可以避免可能会出现的爬取失败。可以看到通过短短5行代码,我们就能够获得网页的源代码了,而这个可以说是网络数据挖掘中最重要的一步了,之后所需要做的工具就是信息提取和分析了。 二、分析网页源代码信息获取到网页源代码后,我们想提炼其中的新闻标题、网址、日期和来源等信息。在提炼这些信息之前,我们有三种常见的分析方法来观察这些信息的特征。 方法1:F12方法点击选择按钮,选择一个标题,可以在Elements中看到,我们所需要的标题内容就在这一片内容中,用同样的的方法可以查看信息日期和来源等信息。
如果看不到其中的中文信息,那是因为它被折叠了,点击折叠箭头展开折叠就可以看到中文了。不过有时通过F12看到的源代码并不一定准确,所以也常常和下面两种方法一起使用。 方法2:右击选择“查看网页源代码”和之前提到过的一样,我们在浏览器上右击,选择“查看网页源代码”,到了源代码网页的时候,可能得往下滚动一下滚轮才能看到内容,然后便可以通过Ctrl + F快捷键(快速搜索快捷键)定位关心的内容了。  方法3:在Python获得的网页源代码中查看
方法3:在Python获得的网页源代码中查看
在获取到源代码的输出框内通过Ctrl + F组合键,调出搜索框,搜索所关心的信息,这种方法也比较常见,不过需要先通过程序获得网页源代码信息。
在源代码里可以看到,关于新闻的标题,来源日期以及正文其实都已经有了,只不过被一些英文、空格以及换行包围着,需要通过一个手段将这些信息提取出来。一个常见的提取信息的手段就是通过正则表达式来进行提取,下面就通过使用正则表达式来提取我们需要的信息。 三、编写正则表达式爬取信息 1. 获取网页源代码 import requests import re headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.83 Safari/537.36'} url = 'https://www.baidu.com/s?tn=news&rtt=1&bsst=1&cl=2&wd=阿里巴巴' # 把链接中rtt参数换成4即是按时间排序,默认为1按焦点排序 res = requests.get(url, headers=headers).text # 加上headers用来告诉网站这是通过一个浏览器进行的访问 print(res)
|







【本文地址】
今日新闻 |
推荐新闻 |