MapReduce实战:统计手机号耗费的总上行流量和下行流量 |
您所在的位置:网站首页 › 手机上行和下行 › MapReduce实战:统计手机号耗费的总上行流量和下行流量 |
MapReduce实战:统计手机号耗费的总上行流量和下行流量
|
1.需求:
统计每一个手机号耗费的总上行流量、下行流量、总流量
2.数据准备:
(1)输入数据格式:
时间戳、电话号码、基站的物理地址、访问网址的ip、网站域名、数据包、接包数、上行/传流量、下行/载流量、响应码
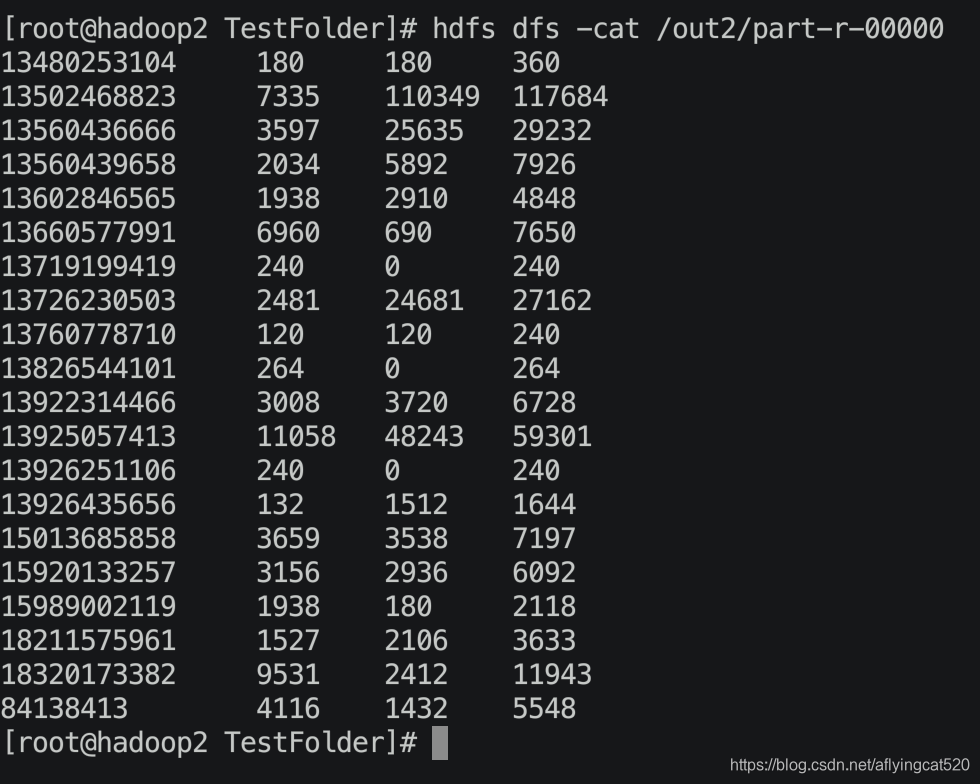
基本思路: (1)Map阶段: (a)读取一行数据,切分字段(b)抽取手机号、上行流量、下行流量©以手机号为key,bean对象为value输出,即context.write(手机号,bean); (2)Reduce阶段: (a)累加上行流量和下行流量得到总流量。(b)实现自定义的bean来封装流量信息,并将bean作为map输出的key来传输©MR程序在处理数据的过程中会对数据排序(map输出的kv对传输到reduce之前,会排序),排序的依据是map输出的key所以,我们如果要实现自己需要的排序规则,则可以考虑将排序因素放到key中,让key实现接口:WritableComparable。 然后重写key的compareTo方法。 4.程序代码: (1)编写流量统计的bean对象FlowBeanFlowBean.java package phoneData; import lombok.Getter; import lombok.Setter; import org.apache.hadoop.io.Writable; import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; // 1 实现writable接口 @Setter @Getter public class FlowBean implements Writable { //上传流量 private long upFlow; //下载流量 private long downFlow; //流量总和 private long sumFlow; //必须要有,反序列化要调用空参构造器 public FlowBean() { } public FlowBean(long upFlow, long downFlow) { this.upFlow = upFlow; this.downFlow = downFlow; this.sumFlow = upFlow + downFlow; } public void set(long upFlow, long downFlow){ this.upFlow = upFlow; this.downFlow = downFlow; this.sumFlow = upFlow + downFlow; } /** * 序列化 * * @param out * @throws IOException */ @Override public void write(DataOutput out) throws IOException { out.writeLong(upFlow); out.writeLong(downFlow); out.writeLong(sumFlow); } /** * 反序列化 * 注:字段属性顺序必须一致 * * @param in * @throws IOException */ @Override public void readFields(DataInput in) throws IOException { this.upFlow = in.readLong(); this.downFlow = in.readLong(); this.sumFlow = in.readLong(); } @Override public String toString() { return upFlow + "\t" + downFlow + "\t" + sumFlow; } } (2)编写MapperFlowCountMapper.java package phoneData; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; /** * LongWritable, Text ===> Map输入 * Text, FlowBean ======> Map的输出: */ public class FlowCountMapper extends Mapper { Text k = new Text(); FlowBean v = new FlowBean(); @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { //获取每一行数据 String line = value.toString(); //切割字段 //1363157995052 13826544101 5C-0E-8B-C7-F1-E0:CMCC 120.197.40.4 4 0 264 0 200 String[] fields = line.split("\t"); //手机号 String phoneNum = fields[1]; //上传和下载 upFlow downFlow long upFlow = Long.parseLong(fields[fields.length - 3]); long downFlow = Long.parseLong(fields[fields.length - 2]); k.set(phoneNum); context.write(k,new FlowBean(upFlow,downFlow)); } } (3)编写ReducerFlowCountReducer.java package phoneData; import java.io.IOException; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; public class FlowCountReducer extends Reducer { @Override protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException { //上传和下载的总和初始化 long sum_upFlow = 0; long sum_downFlow = 0; // 1 遍历所用bean,将其中的上行流量,下行流量分别累加 for (FlowBean flowBean : values) { //所有的上传的流量加在一起 sum_upFlow += flowBean.getUpFlow(); //所有的下载的流量加在一起 sum_downFlow += flowBean.getDownFlow(); } // 2 封装对象 FlowBean resultBean = new FlowBean(sum_upFlow, sum_downFlow); // 3 写出 context.write(key, resultBean); } } (4)编写驱动FlowsumDriver.java package phoneData; import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class FlowsumDriver { public static void main(String[] args) throws IllegalArgumentException, IOException, ClassNotFoundException, InterruptedException { //args = new String[]{"/Users/macbook/TestInfo/phone_data.txt", "/Users/macbook/TestInfo/MovlePhone1"}; // 1 获取配置信息,或者job对象实例 Configuration configuration = new Configuration(); Job job = Job.getInstance(configuration); // 6 指定本程序的jar包所在的本地路径 job.setJarByClass(FlowsumDriver.class); // 2 指定本业务job要使用的mapper/Reducer业务类 job.setMapperClass(FlowCountMapper.class); job.setReducerClass(FlowCountReducer.class); // 3 指定mapper输出数据的kv类型 job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(FlowBean.class); // 4 指定最终输出的数据的kv类型 job.setOutputKeyClass(Text.class); job.setOutputValueClass(FlowBean.class); // job.setPartitionerClass(ProvincePartitioner.class); // job.setNumReduceTasks(6); // 5 指定job的输入原始文件所在目录 FileInputFormat.setInputPaths(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); // 7 将job中配置的相关参数,以及job所用的java类所在的jar包, 提交给yarn去运行 job.waitForCompletion(true); } } 5.运行结果: (1)打包上传到hadoop集群: (2)运行: hadoop jar Hadoop-1.0-SNAPSHOT.jar phoneData.FlowSumDriver /phone_data.txt /out2
|
【本文地址】