简单的卷积神经网络,实现手写英文字母识别 |
您所在的位置:网站首页 › 手写体英文字母 › 简单的卷积神经网络,实现手写英文字母识别 |
简单的卷积神经网络,实现手写英文字母识别
|
简单的卷积神经网络,实现手写英文字母识别
1 搭建Python运行环境(建议用Anaconda),自学Python程序设计
安装Tensorflow、再安装Pycharm等环境。(也可用Pytorch) 1.1 Anaconda的安装及工具包下载方法总结参考文章: 手把手教你在Windows系统下安装Anaconda 在官网上下载AnacondaAnaconda官网 进入官网: 
点击Download 
选择对应的版本 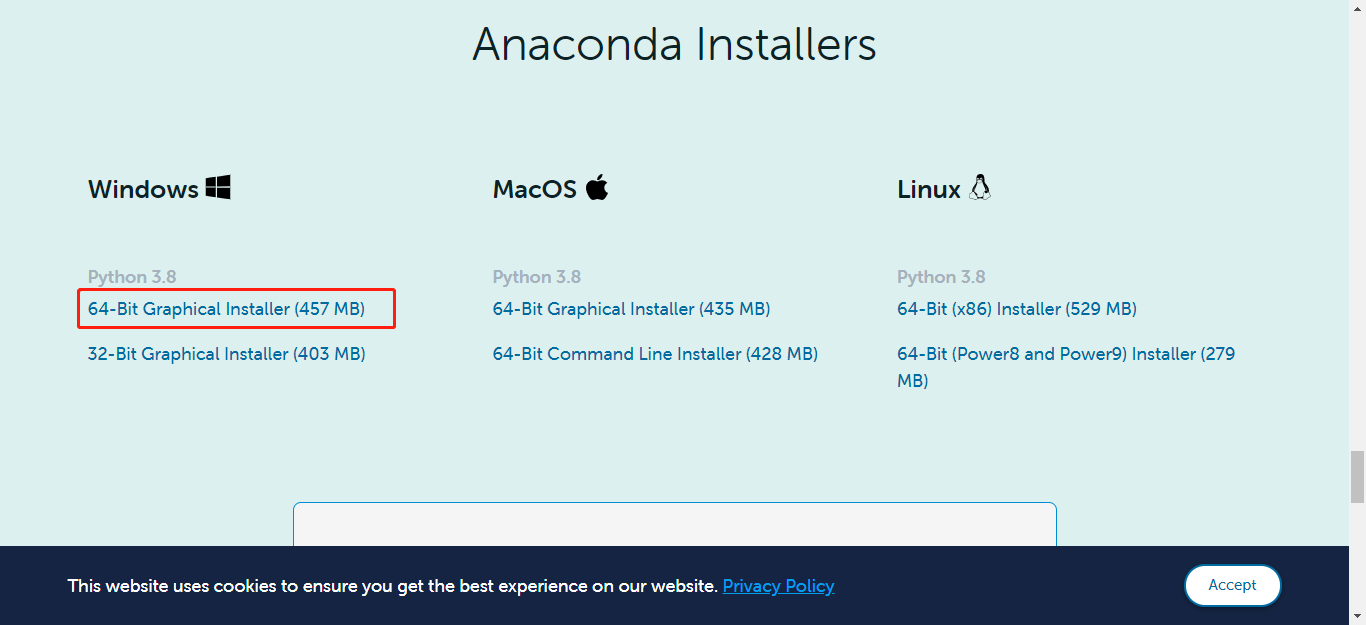
以下在windows系统中进行演示 安装流程下载完毕后,直接安装即可,我这里习惯把所有的程序都放在一个环境中 
环境变量请必须勾选,如果忘了,建议卸载重装 
至此,anaconda就安装完成了 打开Anaconda检查python版本打开Anaconda prompt,输入python --version即可。 如果打不开,或者点击之后没反应,但可以用管理员身份打开软件,那可能是anaconda指向的java jdk路径不对,以后有时间我再写个教程更改一下。 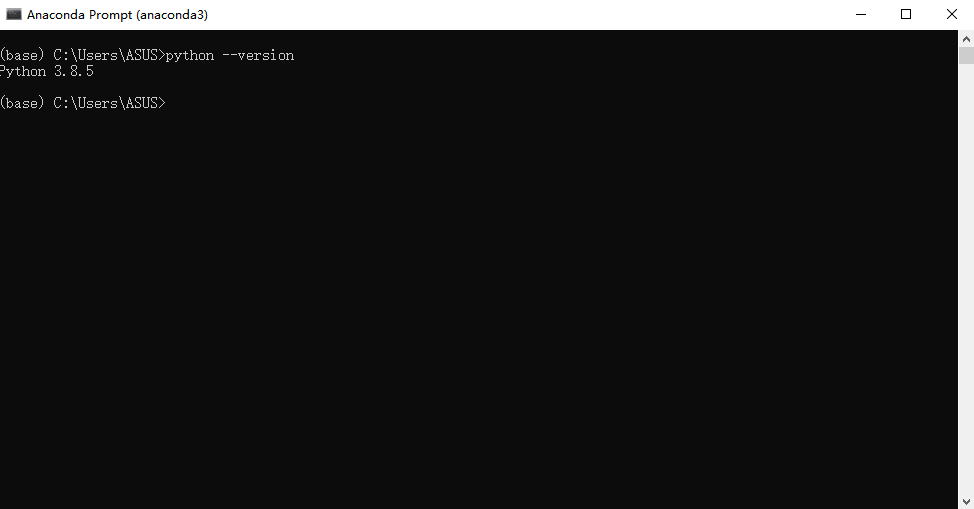 1.2 Windows下安装教程
1.2 Windows下安装教程
镜像的好处:满速下载,不能直接上网的服务器也可以下载相应的包(采用ipv6)等 一下以安装pytorch为例 在Anaconda安装Pytorch等一系列包 准备工作 安装好anaconda,具体参考1.1打开Anaconda Prompt,即可
 为了更好的管理安装pytorch、tensorflow等一系列包的路径,建议建立对应的环境,而不是直接安装在base中,用以下代码语句即可:
conda create -n xxx python3.8 #创建名为python3.8的xxx虚拟环境
conda env list #查看所有虚拟环境
conda activate xxx #进入xxx环境
conda deactivate xxx #退出xxx环境
为了更好的管理安装pytorch、tensorflow等一系列包的路径,建议建立对应的环境,而不是直接安装在base中,用以下代码语句即可:
conda create -n xxx python3.8 #创建名为python3.8的xxx虚拟环境
conda env list #查看所有虚拟环境
conda activate xxx #进入xxx环境
conda deactivate xxx #退出xxx环境
其他与环境相关的conda语句可以点击这里查看。 首先建立名为"jh"的环境; 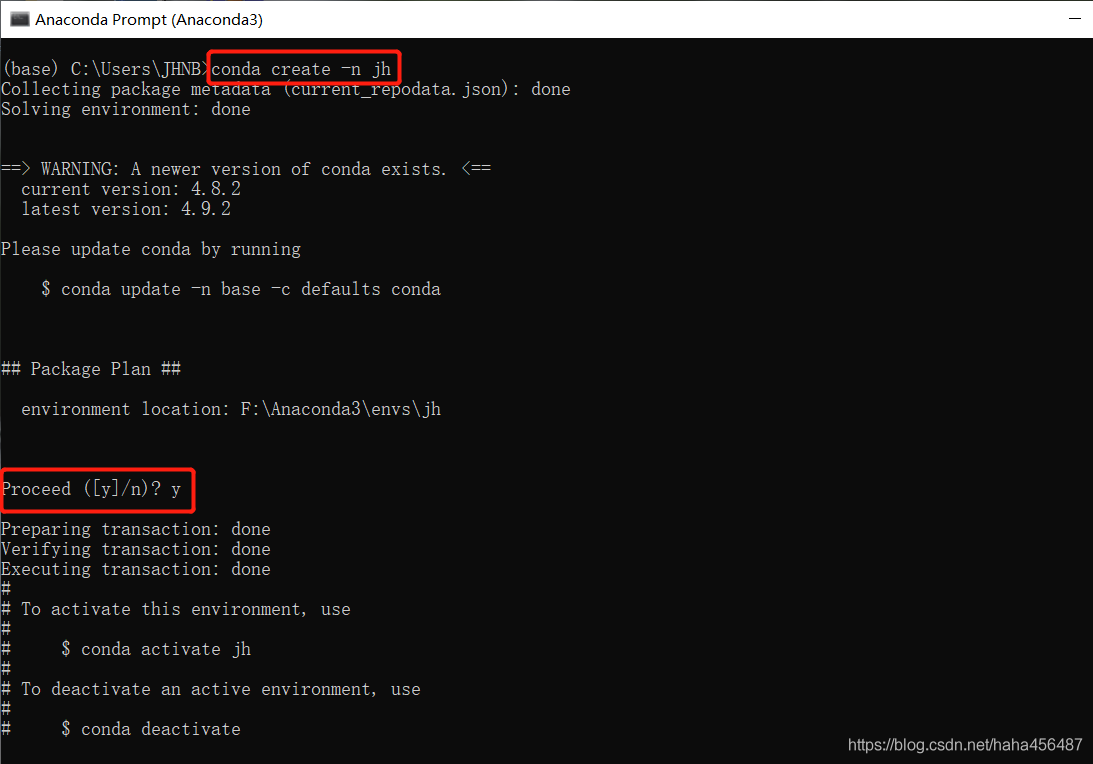
建立好后,查看已有的环境,此时“jh”环境已经出现 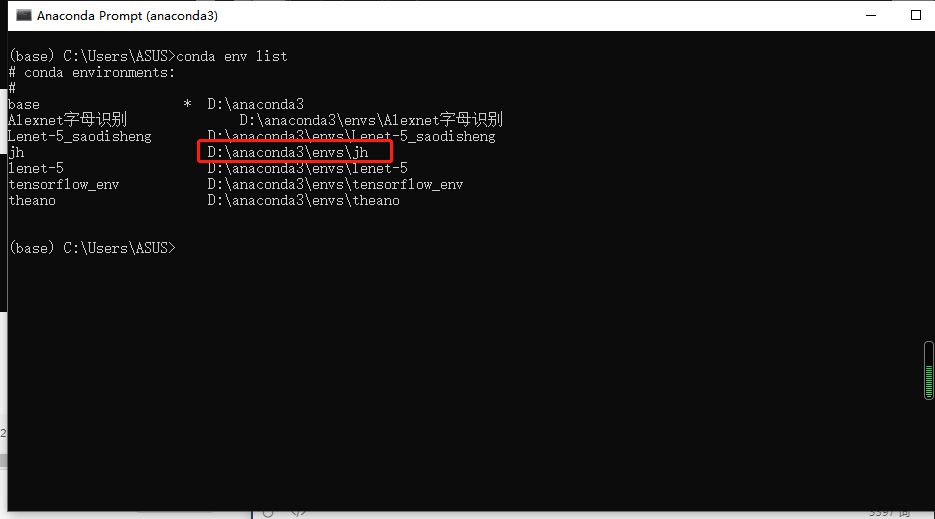
最后,进入(激活)“jh”环境 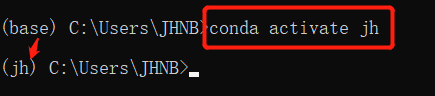
从base进入到jh环境,之后将所有需要安装的包全部安装在jh环境中。至于为什么要建立“jh”环境?因为如果你之后不再使用jh环境的时候,直接用一行conda语句删除掉这个环境,安装在jh里的包就全部删除掉了,管理起来很方便。 之后安装各种包就在“jh”环境中进行。 镜像源网站我经常使用清华镜像源,但最近北外的镜像源速度更快,所以就选用了北外开源镜像源。 点击下方红框的“使用帮助”、“anaconda”。 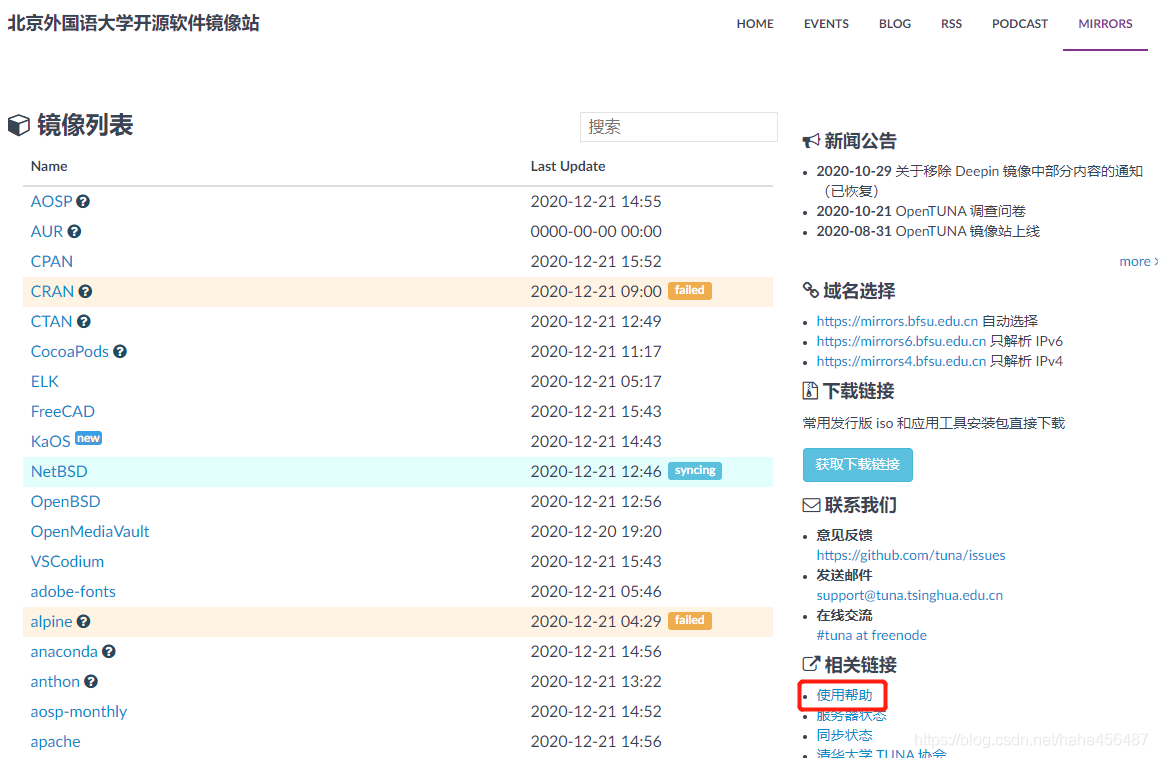
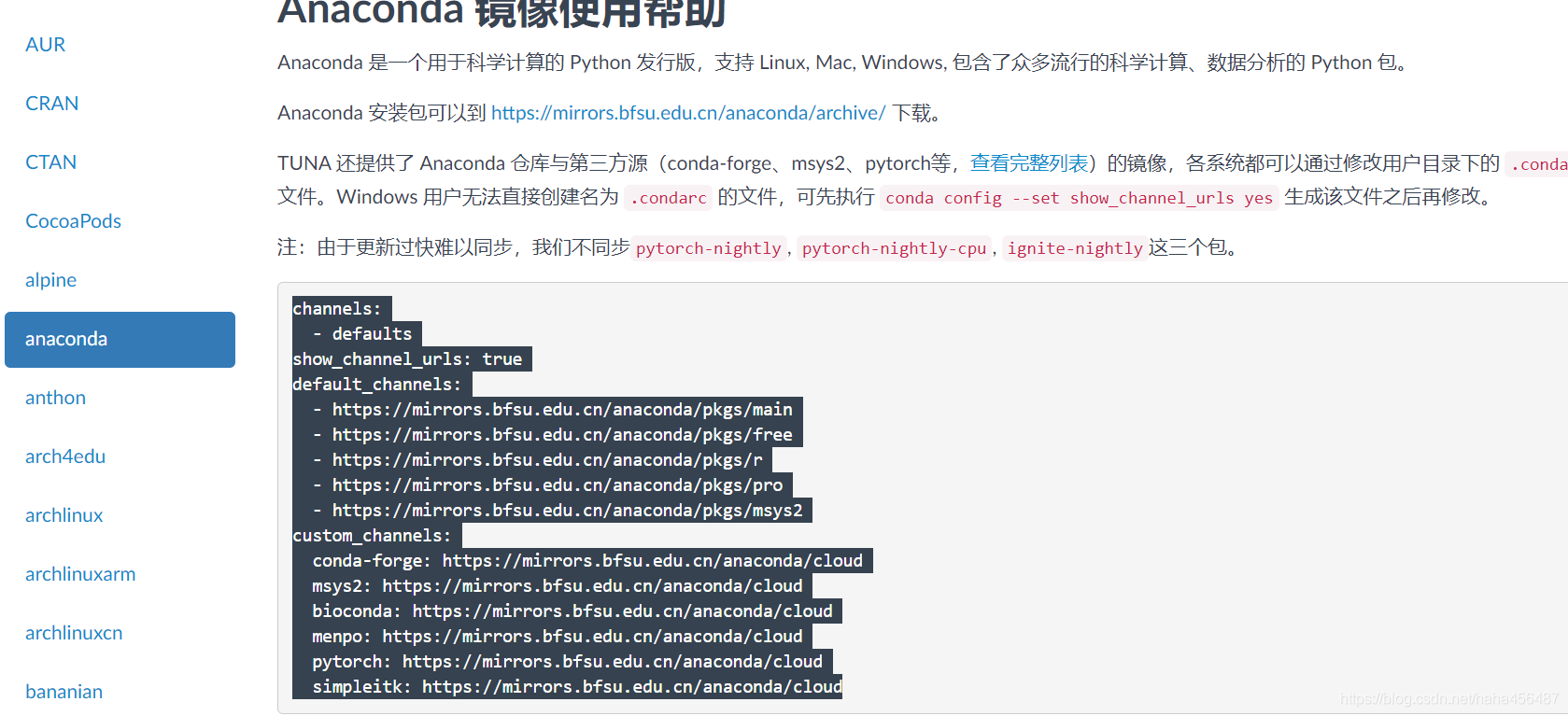
找到中间选中的channels的内容,即 channels: - defaults show_channel_urls: true default_channels: - https://mirrors.bfsu.edu.cn/anaconda/pkgs/main - https://mirrors.bfsu.edu.cn/anaconda/pkgs/free - https://mirrors.bfsu.edu.cn/anaconda/pkgs/r - https://mirrors.bfsu.edu.cn/anaconda/pkgs/pro - https://mirrors.bfsu.edu.cn/anaconda/pkgs/msys2 custom_channels: conda-forge: https://mirrors.bfsu.edu.cn/anaconda/cloud msys2: https://mirrors.bfsu.edu.cn/anaconda/cloud bioconda: https://mirrors.bfsu.edu.cn/anaconda/cloud menpo: https://mirrors.bfsu.edu.cn/anaconda/cloud pytorch: https://mirrors.bfsu.edu.cn/anaconda/cloud simpleitk: https://mirrors.bfsu.edu.cn/anaconda/cloud一般有两种方法将此内容配置给anaconda,一般采用第一种方式: 第①种方式: 修改.condarc文件,该文件保存了anaconda的配置信息,此文件存储在 C:\Users\xxxx.conda\路径中,可用记事本打开,将channels内容全部粘贴在.condarc文件即可。 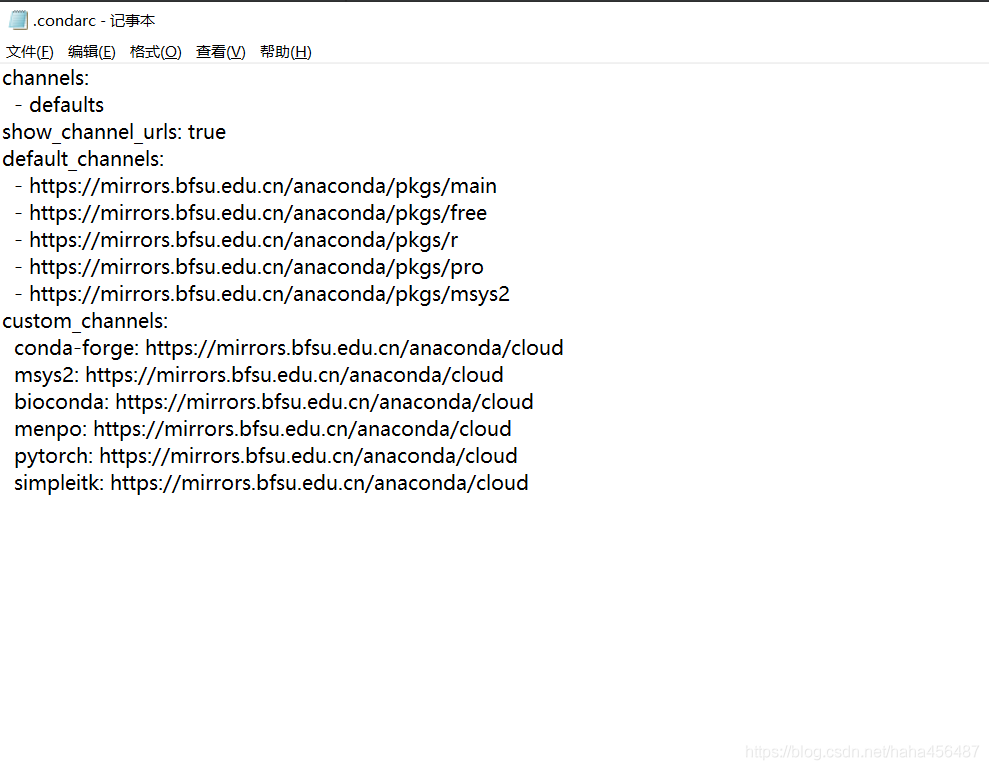
【注意!】如果 C:\Users\xxxx\.conda\路径中没有.condarc文件,可先在anaconda prompt中生成一个,代码如下: conda config --add channels https://xxx ##这里随便写一个channel的https即可。运行后就可在 C:\Users\xxxx\路径中找到.condarc文件 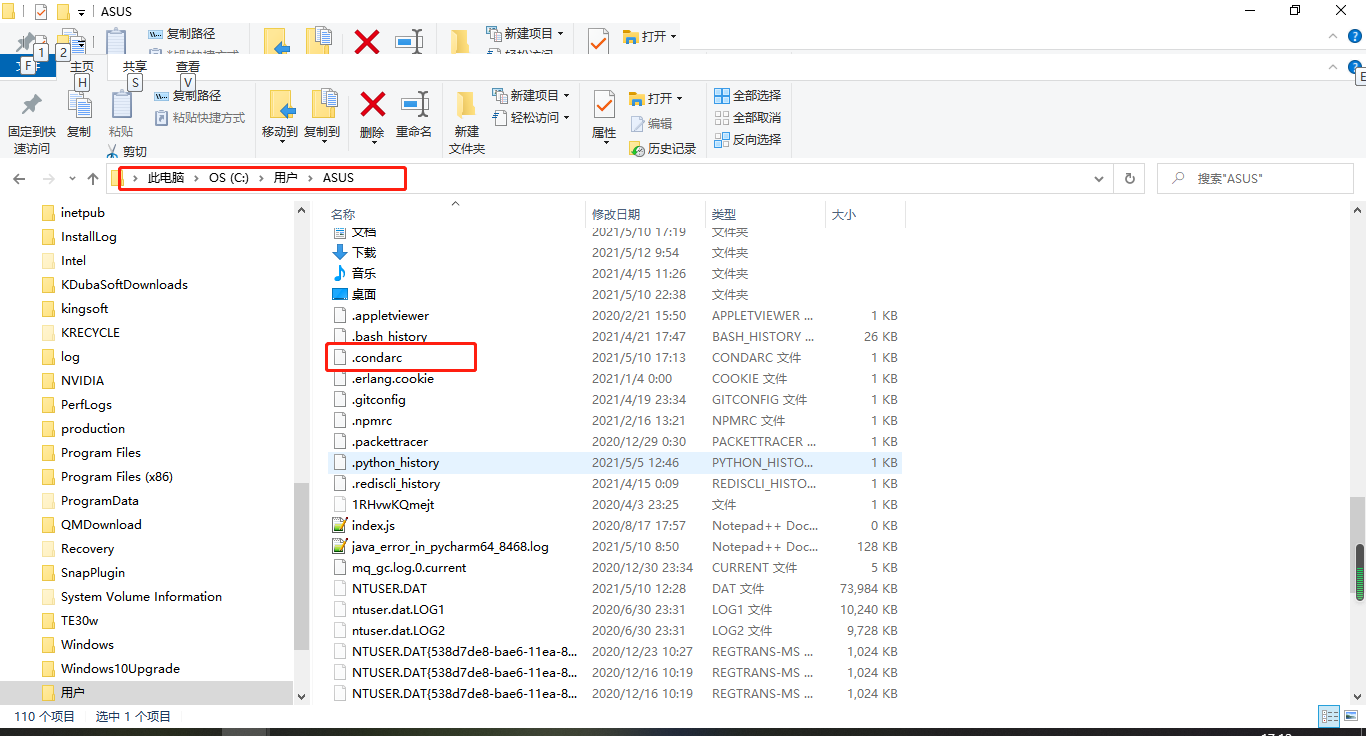
第②种方式: 用conda语句,一句一句的输入,例如需要安装pytorch conda config --add channels https://mirrors.bfsu.edu.cn/anaconda/cloud ... #https的内容对应于channels中的https; #将channels中的https一行一行的用conda语句配置给anaconda; 安装pytorch 打开pytorch官网(https://pytorch.org/),进度条往下拖,可以找到对应的安装语句。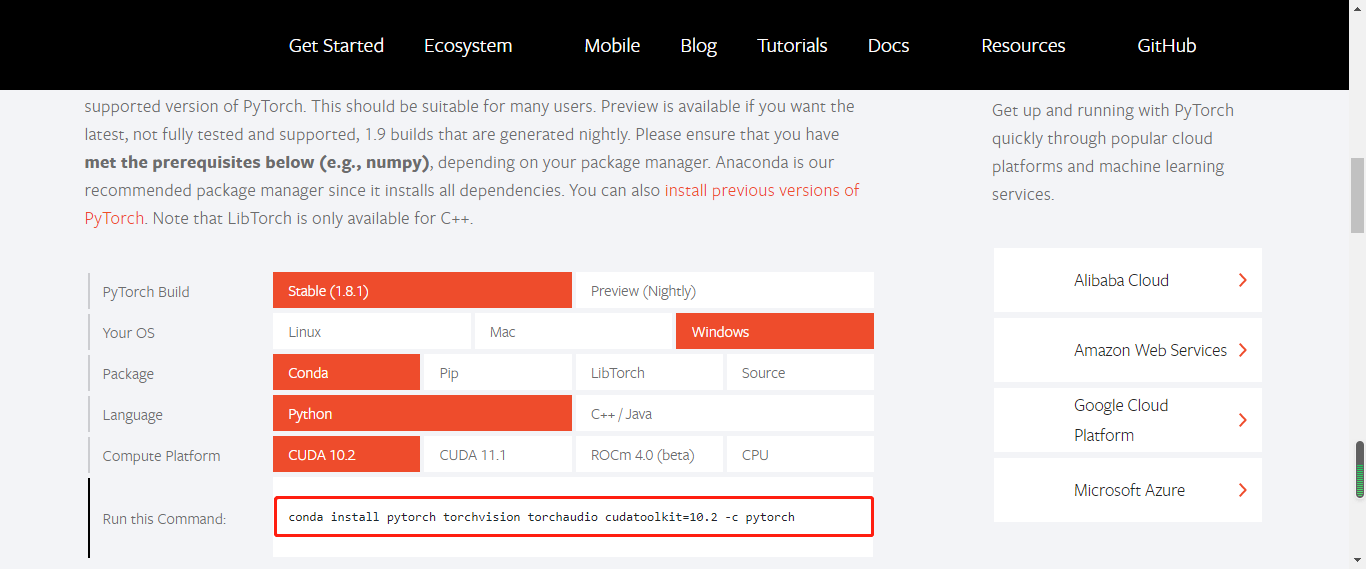
此处conda安装pytorch的语句(日期2021/05/14)为 conda install pytorch torchvision torchaudio cudatoolkit=10.2 -c pytorch 在anaconda prompt中进入你建好的环境中(如“jh”环境),并进行pytorch的安装即可。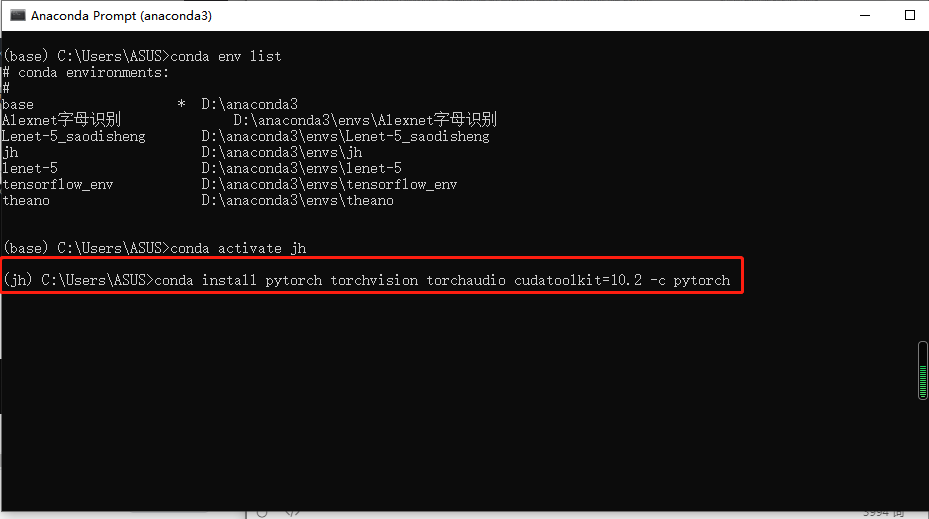 查看版本信息
查看版本信息
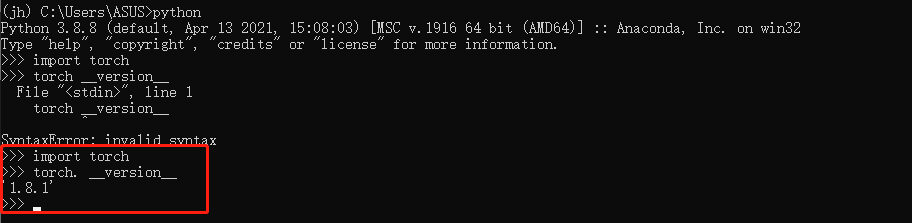
退出python可以在运行quit()或快捷键Ctrl+Z即可。 此外,还可以查看“jh”环境中所有安装包情况,conda语句如下(需在“jh”环境下运行该语句): conda list #查看该环境下的所有安装包情况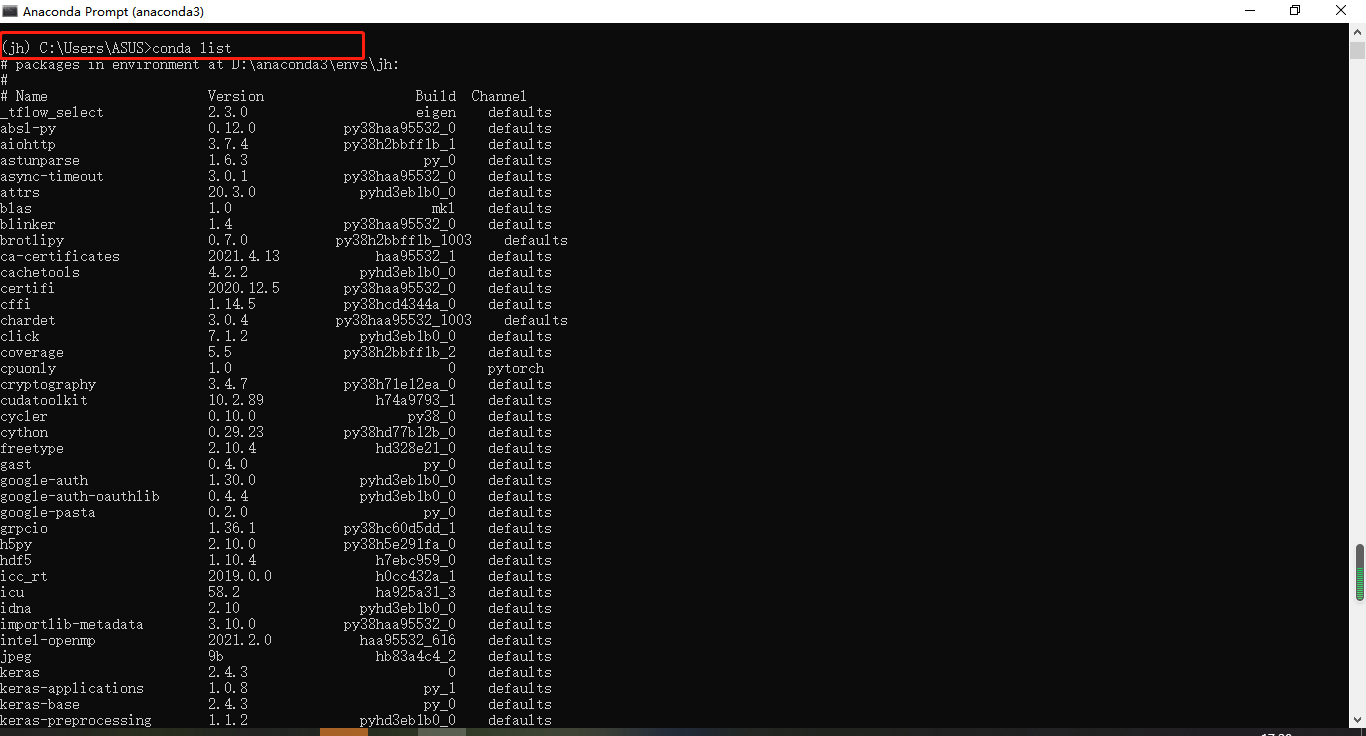
可以发现安装pytorch的时候,常用的numpy也一同被安装了。 如果要删除此环境,可以点击这里查看conda语句。 删除安装过程中下载的安装包,释放空间建议定期删除安装包,不删除的话就会一直积累在那里。 相关conda语句如下: conda clean -p #删除没有用的安装包 conda clean -y --all #删除所有安装包和cache 总结说明对于相关博客中介绍的方法个人觉得不是最方便的。 综合查看的一些资料将我个人觉得比较简单的方法应该是直接在Anaconda Navigator (anaconda3)面板上安装。 具体流程如下: 打开Anaconda Navigator (anaconda3) 打击Environments
打击Environments
 选中自己的执行文件夹
选中自己的执行文件夹
 通过搜索框查询需要的工具包进行安装即可。
通过搜索框查询需要的工具包进行安装即可。
通过以上的方式安装工具包,可以避免因为指令问题或版本问题导致的工具包和Anaconda不兼容的问题。 
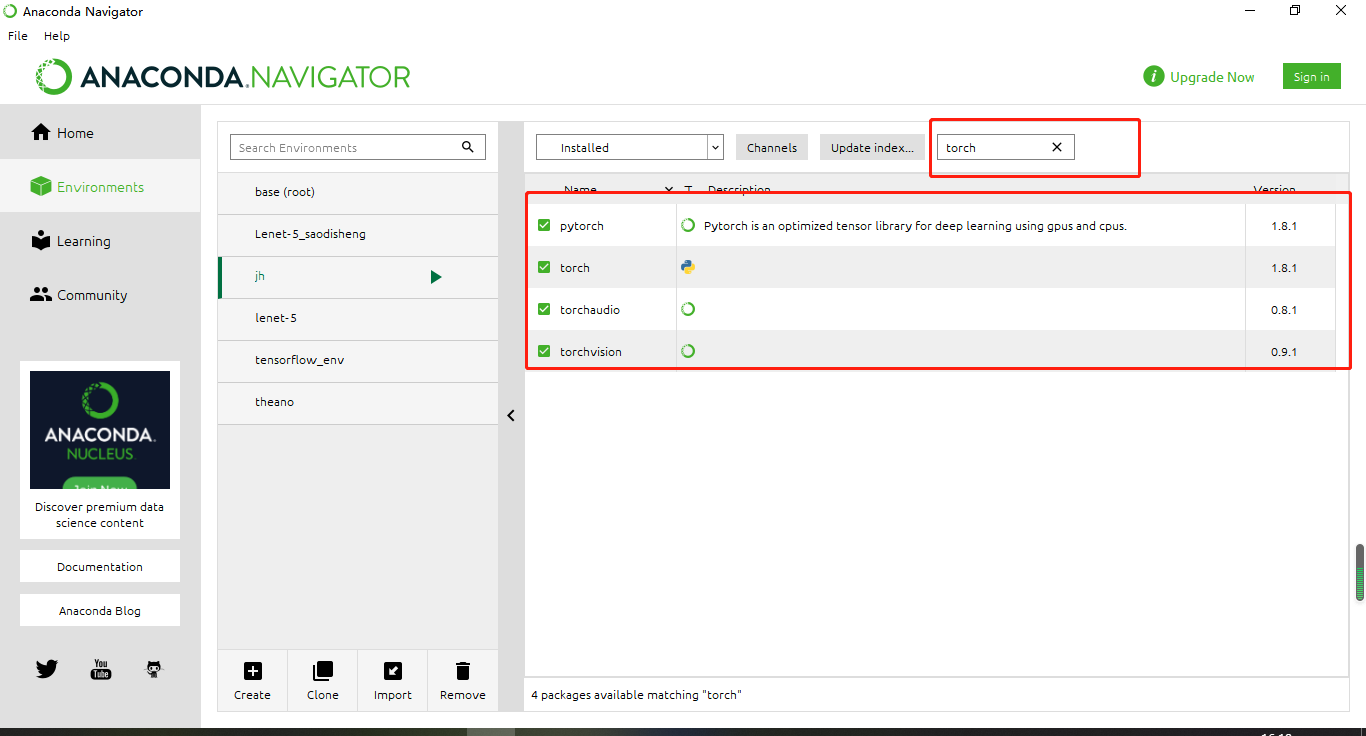
通过上图可以看到我这边已经安装了pytorch和Tensorflow 1.3 Pycharm安装Pycharm安装教程 安装配置PyCharm 是一款功能强大的 Python 编辑器,具有跨平台性,鉴于目前最新版 PyCharm 使用教程较少,为了节约时间,来介绍一下 PyCharm 在 Windows下是如何安装的。 这是 PyCharm 的下载地址 下载地址 进入该网站后,我们会看到如下界面: 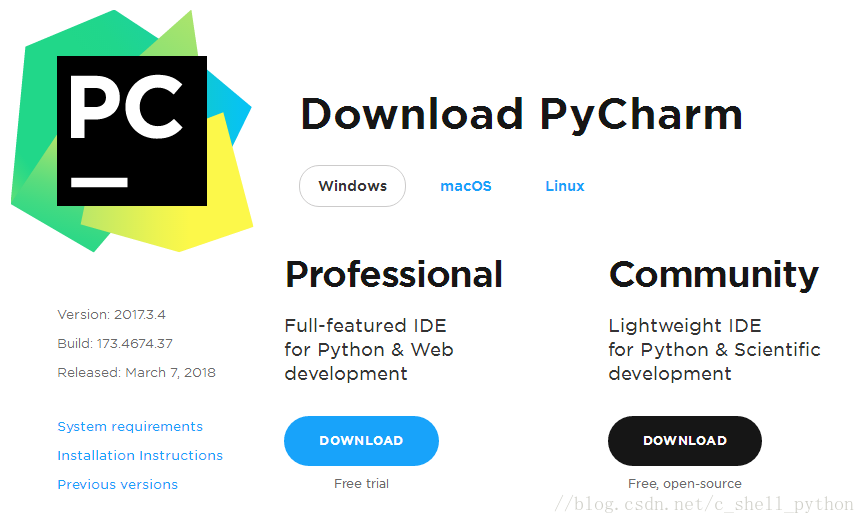
professional 表示专业版,community 是社区版,推荐安装社区版,因为是免费使用的。 1、当下载好以后,点击安装,记得修改安装路径,我这里放的是E盘,修改好以后,Next 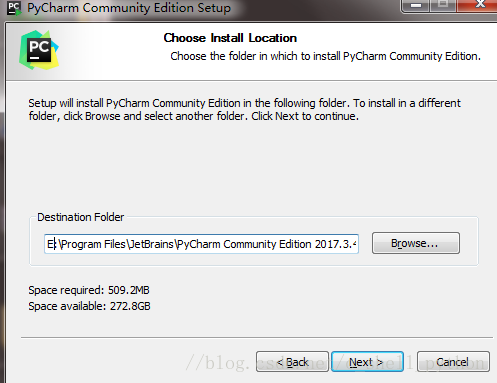
2、接下来是 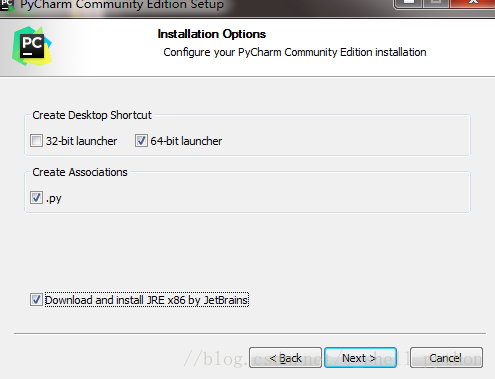
我们可以根据自己的电脑选择32位还是64位,目前应该基本都是64位系统 3、如下 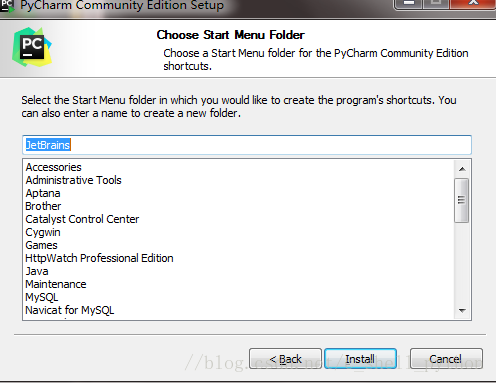
点击Install,然后就是静静的等待安装了。 4、我们进入该软件 
5、点击Create New Project,接下来是重点 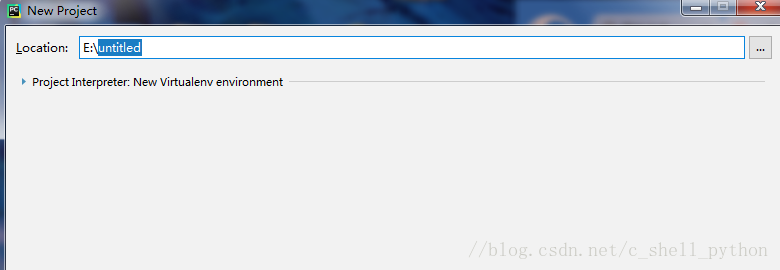
Location是我们存放工程的路径,点击  这个三角符号,可以看到pycharm已经自动获取了Python3.5 这个三角符号,可以看到pycharm已经自动获取了Python3.5
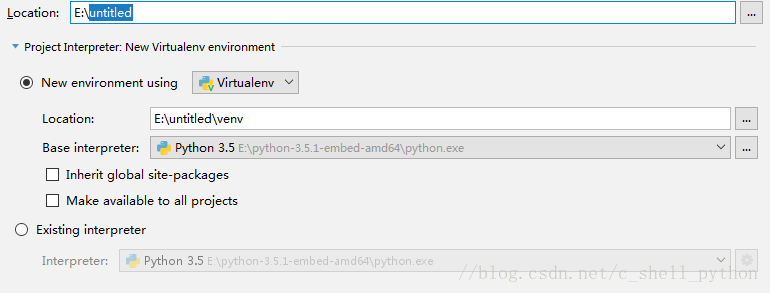
点击第一个  我们可以选择Location的路径,比如 我们可以选择Location的路径,比如
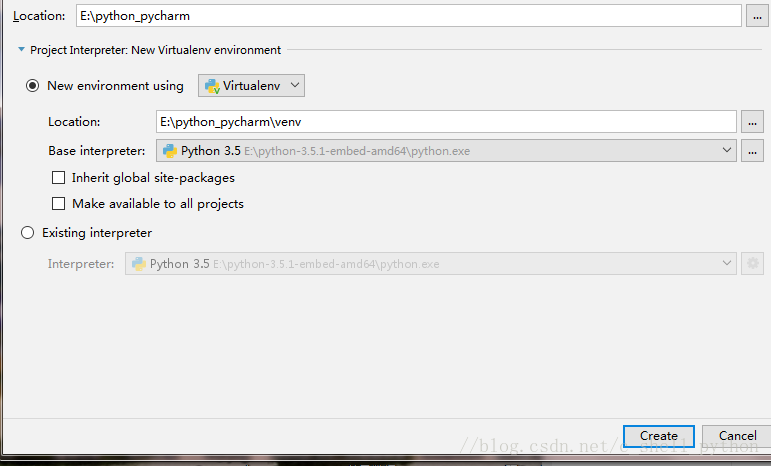
记住,我们选择的路径需要为空,不然无法创建,第二个Location不用动它,是自动默认的,其余不用点,然后点击Create。出现如下界面,这是Pycharm在配置环境,静静等待。最后点击close关掉提示就好了。 
6、建立编译环境 
右键  点击New,选择Python File 点击New,选择Python File
给file取个名字,点击OK 
系统会默认生成hello.py 
好了,至此,我们的初始工作基本完成。 7、我们来编译一下 
8、因为之前已经添加过了,所以可以直接编译,还有很重要的一步没说,不然pycharm无法找到解释器,将无法编译。 点击File,选择settings,点击 
添加解释器 
最后点击Apply。等待系统配置。 如果我们需要添加新的模块,点击绿色+号 
然后直接搜索pymysql 
然后点安装 
以上就是pycharm的安装过程以及初始化,还有Python解释器的安装配置。 注意点Pycharm的安装基本按照对应的教程就行。需要注意的是对应的python.exe一定要和自己的运行路径相对应,不然会出现我们安装了相应的工具包,但却无法导入的问题 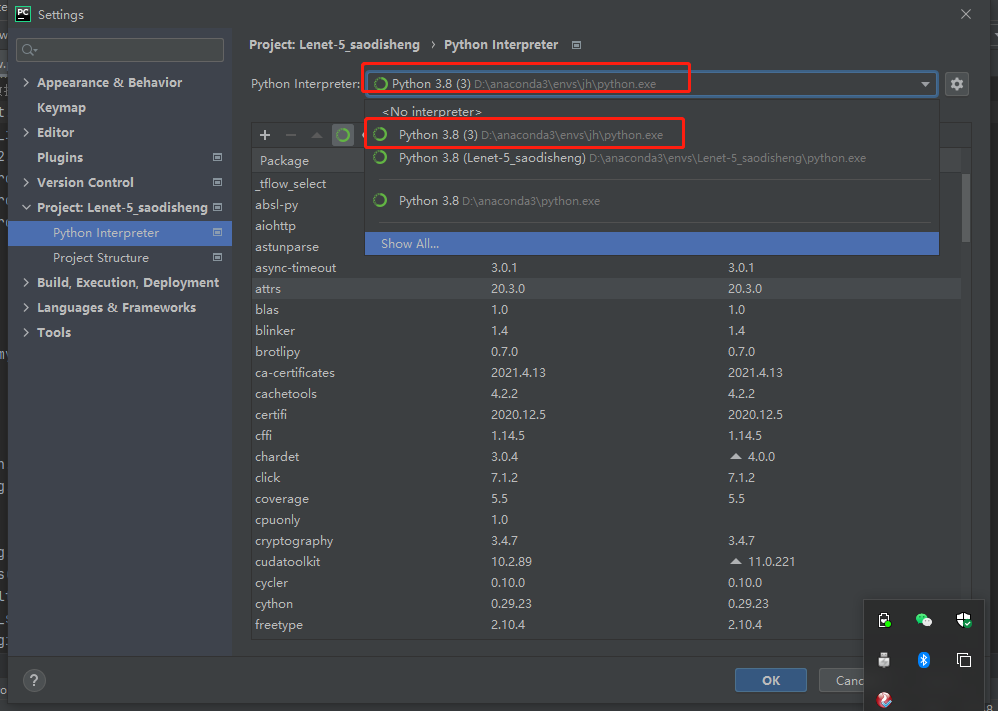 2 自学卷积神经网络的基础知识
2 自学卷积神经网络的基础知识
参考的学习视频 卷积神经网络百度解析 Lenet-5模型+代码实现 卷积神经网络 2.1 卷积卷积是两个变量在某范围内相乘后求和的结果。在卷积神经网络中就是指卷积核与指定视图某块区域的数值乘积之和,即对于给定的一幅图像来说,给定一个卷积核,卷积就是根据卷积窗口,进行像素的加权求和。 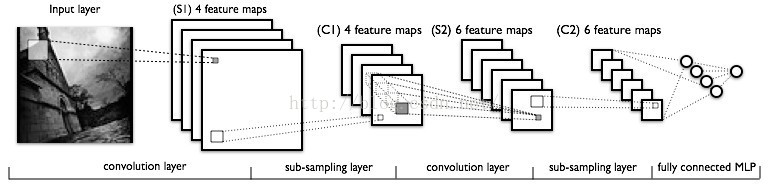
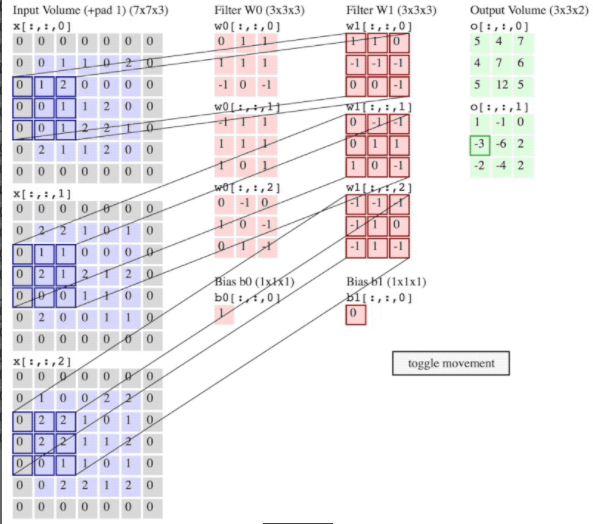 2.2 池化
2.2 池化
刚开始学习CNN的时候,看到这个词,好像高大上的样子,于是查了很多资料,理论一大堆? 池化,就是图片下采样。每一层通过卷积,然后卷积后进行下采样,而CNN也是同样的过程。CNN的池化主要要两种方法(肯定有很多,但在学习过程中,我主要接触到的就是最大值池化和平均值池化)。 其中最经典的是最大池化,因此我就解释一下最大池化的实现: 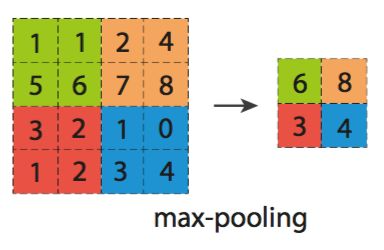
上图用到的池化2 * 2 的filter(类似卷积层的卷积核,只不过这里更加容易理解),在filter扫描范围中选取最大值作为这个区域的代表,就是最大化池化方法。 2.3 Lenet模型Lenet-5卷积神经网络的整体框架如下: 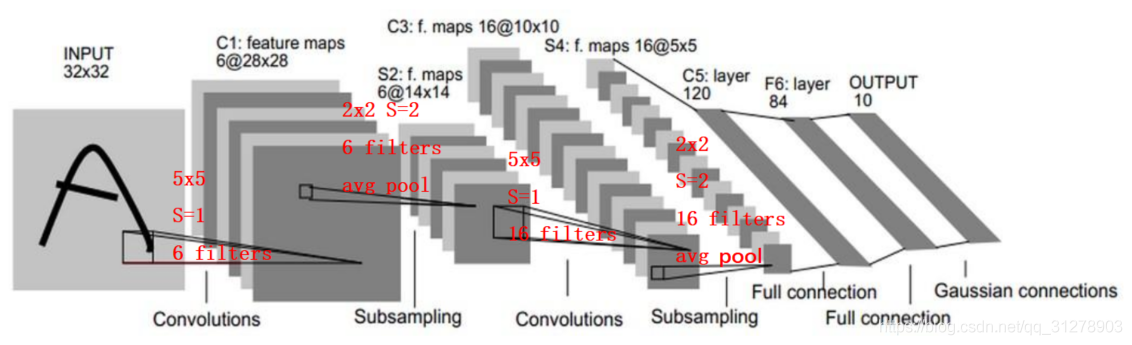
LeNet-5共有8层,包含输入层,每层都包含可训练参数;每个层有多个特征映射(Feature Map),每个特征映射通过一种卷积核(或者叫滤波器)提取输入的一种特征,然后每个特征映射有多个神经元。C层代表的是卷积层,通过卷积操作,可以使原信号特征增强,并且降低噪音。 S层是一个降采样层,利用图像局部相关性的原理,对图像进行子抽样,可以减少数据处理量同时保留有用信息。 计算公式:输入图像的大小为nxn,卷积核的大小为mxm,步长为s, 为输入图像两端填补p个零(zero padding),那么卷积操作之后输出的大小为(n-m+2p)/s + 1。 结合前面的学习视频来说,这个公式是很好理解的。 3 下载一个手写英文字母数据集The Chars74K dataset 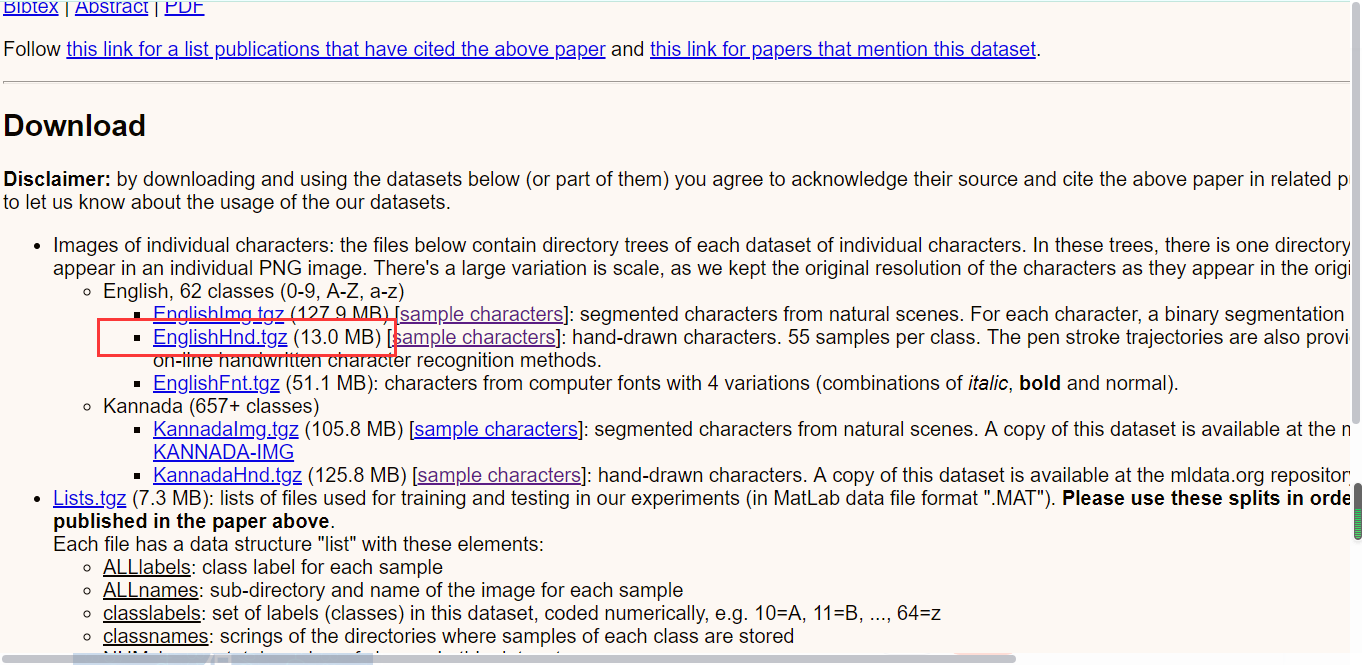
由于只需要训练识别英文字母,选择其中的Sample011到Sample062复制到任意目录下 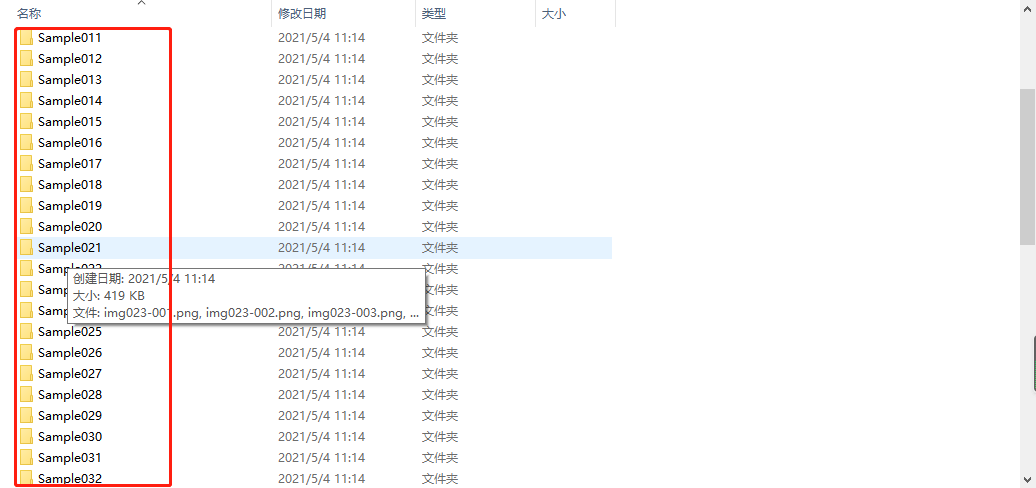
这里为了便于实验处理,将数据中的同一个字母的大小写放在了同一个文件夹 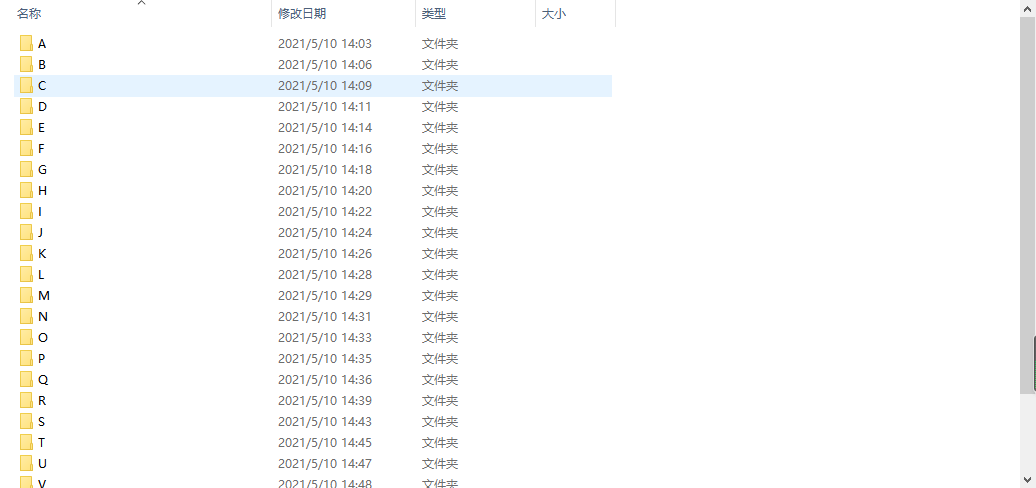 4 下载LeNet5,或更复杂的卷积神经网络代码
4 下载LeNet5,或更复杂的卷积神经网络代码
参考博客 5 将上述代码调试运行通过,并实现手写英文字母的识别 5.1 训练效果图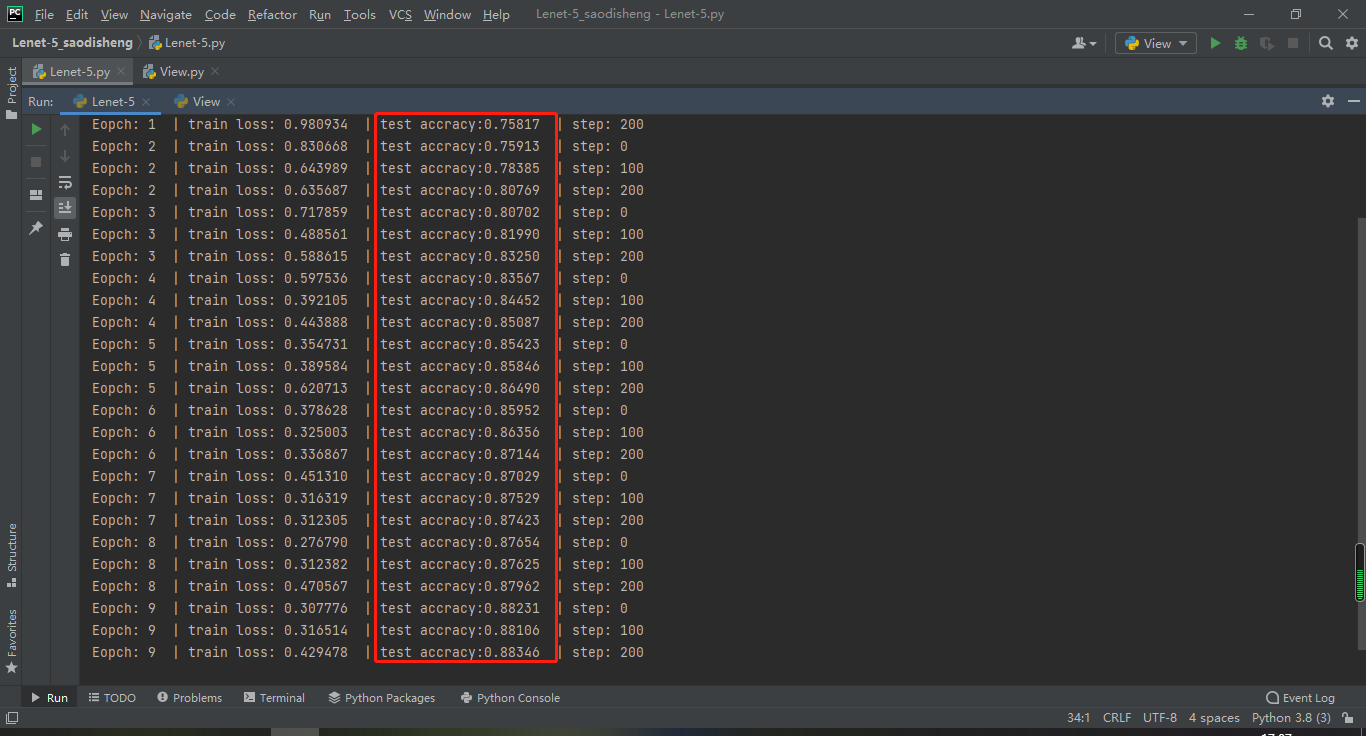
input(手写体): 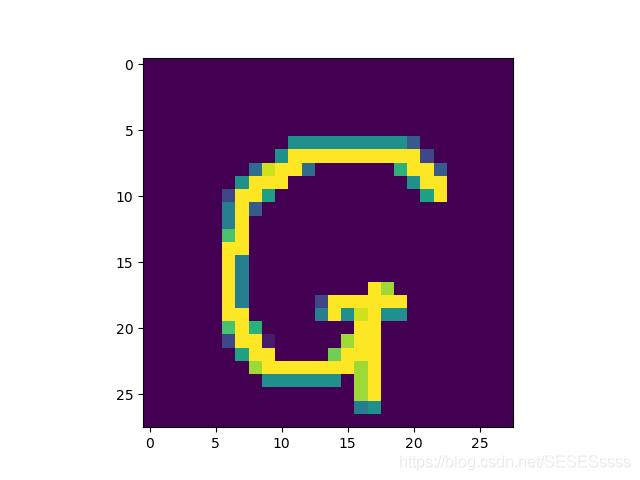
卷积层1: 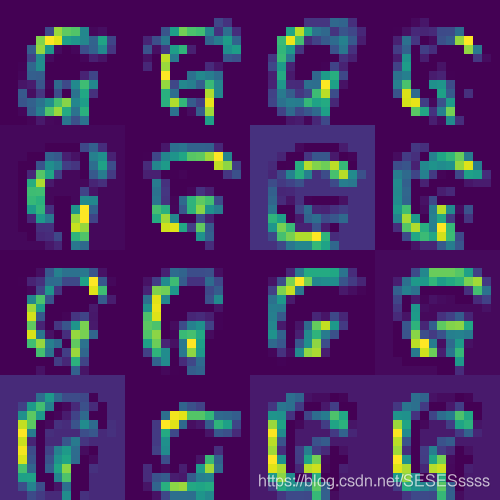
卷积层2: 
全连接层: 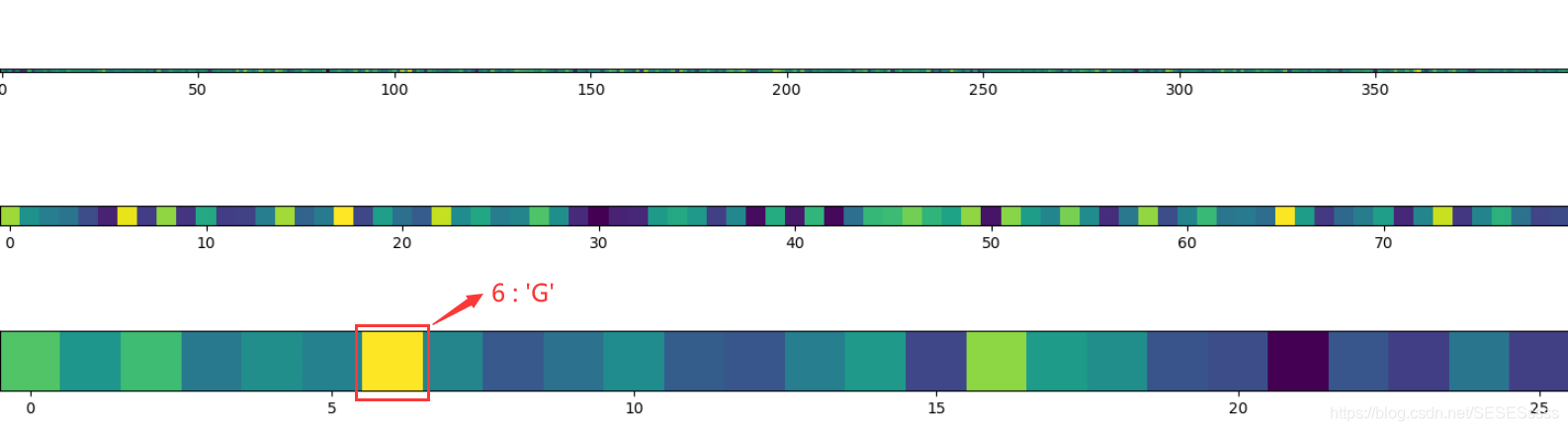
OUTPUT: predict character: G or g 代码说明 import torch import torch.nn as nn # torchvision已经预先实现了常用的Datast from torchvision.datasets import ImageFolder # ImageFolder是一个经常用到的Dataset import torchvision.models as models from torchvision import utils import torchvision.transforms as T import torch.utils.data as Data from PIL import Image import numpy as np import torch.optim as optim import os import matplotlib.pyplot as plt #使用tensorboardX进行可视化 from tensorboardX import SummaryWriter # 创建一个write实例,自动生成的文件夹路径为:./EMNIST_log SumWriter = SummaryWriter(log_dir = "./EMNIST_log") # 数据预处理 # 首先定义超参数 EPOCH = 10 # 训练的批次,下载的数据集每个字母都有5000张左右的图片,由于电脑性能的原因,对于每个字母的训练我只保留了1000张图片,同时为了保证训练准确度,将训练的次数调得比较多 BATCH_SIZE = 128 # 训练的最小规模(一次反向传播需要更新权值) LR = 1e-4 # 学习率 # 转为tensor 以及 标准化 transform = T.Compose([ #转为灰度图像,这部分是便于图像识别的: T.Grayscale(num_output_channels=1), #将图片转换为Tensor,归一化至(0,1),在实验中发现如果没有归一化的过程,最后的预测效果会很差: T.ToTensor(), ]) #数据集要作为一个文件夹读入: # #读取训练集: # ImageFolder(root, transform=None, target_transform=None, loader=default_loader) # 它主要有四个参数: # root:在root指定的路径下寻找图片 # transform:对PIL Image进行的转换操作,transform的输入是使用loader读取图片的返回对象 # target_transform:对label的转换 # loader:给定路径后如何读取图片,默认读取为RGB格式的PIL Image对象 train_data = ImageFolder(root="./Emnist_letters_png/Train_png", transform=transform) # 训练集数据的加载器,自动将数据分割成batch,顺序随机打乱 # shuffle这个参数代表是否在构建批次时随机选取数据 train_loader = torch.utils.data.DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True) #读取测试集: test_data = ImageFolder(root="./Emnist_letters_png/Test_png", transform=transform) #之所以要将test_data转换为loader是因为网络不支持原始的ImageFolder类数据,到时候直接使用批训练,便是tensor类。 #batch_size为全部10000张testdata,在全测试集上测试精度 test_loader = torch.utils.data.DataLoader(dataset=test_data, batch_size=test_data.__len__()) label_num = len(train_data.class_to_idx) #数据可视化: to_img = T.ToPILImage() a=to_img(test_data[0][0]) #size=[1, 28, 28] plt.imshow(a) plt.axis('off') plt.show() # 卷积网络搭建:两层卷积网络(卷积+池化)+ 三层全连接层 class CNN(nn.Module): def __init__(self): super(CNN, self).__init__() # Sequantial()把不同的函数组合成一个模块使用 # 定义网络框架 # 卷积层1(卷积核=16) self.Conv1 = nn.Sequential( # 5个参数依次是: # in_channels:输入图像的通道数,这里为1表示只有一层图像 # out_channels:定义了16个卷积核,即输出高度为16 # kernel_size:卷积核大小为5 * 5 # stride: 步长,卷积核每次扫描的跨度 # padding: 边界填充0(如步长为1时,若要保证输出尺寸像和原尺寸一致, # 计算公式为:padding = (kernel_size-1)/2) nn.Conv2d(1, 16, 5, 1, 2), nn.BatchNorm2d(16), #激活函数层 nn.ReLU(), #最大池化层 通过最大值进行池化 nn.MaxPool2d(kernel_size=2) ) # 卷积层2 self.Conv2 = nn.Sequential( nn.Conv2d(16, 32, 5, 1, 2), nn.BatchNorm2d(32), #激活函数层 nn.Dropout(p=0.2), nn.ReLU(), #最大池化层 nn.MaxPool2d(kernel_size=2) ) #最后接上一个全连接层(将图像变为1维) #为什么是32*7*7: # (1,28,28)->(16,28,28)(conv1) # ->(16,14,14)(pool1) # ->(32,14,14)(conv2) # ->(32,7,7)(pool2)->output self.Linear = nn.Sequential( nn.Linear(32*7*7,400), # Dropout按指定概率随机舍弃部分的神经元 nn.Dropout(p = 0.5), # 全连接层激活函数 nn.ReLU(), nn.Linear(400,80), # nn.Dropout(p=0.5), nn.ReLU(), nn.Linear(80,label_num), ) # 前向传播 def forward(self, input): input = self.Conv1(input) input = self.Conv2(input) #input.size() = [100, 32, 7, 7], 100是每批次的数量,32是厚度,图片尺寸为7*7 #当某一维是-1时,会自动计算它的大小(原则是总数据量不变): input = input.view(input.size(0), -1) #(batch=100, 1568), 最终效果便是将二维图片压缩为一维(数据量不变) #最后接上一个全连接层,输出为10:[100,1568]*[1568,10]=[100,10] output = self.Linear(input) return output # 读取网络框架 cnn = CNN() # 仅保存训练好的参数 torch.save(cnn.state_dict(), 'EMNIST_CNN.pkl') # 加载训练好的参数 cnn.load_state_dict(torch.load('EMNIST_CNN.pkl')) # 进行训练 cnn.train() # 显示网络层结构 # print(cnn) #定义优化器 optimizer = torch.optim.Adam(cnn.parameters(), lr=LR) #定义损失函数,因为是分类问题,所以使用交叉熵损失 loss_func = nn.CrossEntropyLoss() # 训练与模式保存 # 根据EPOCH自动更新学习率,2次EPOCH学习率减少为原来的一半: # scheduler = torch.optim.lr_scheduler.StepLR(optimizer, 2, gamma = 0.6, last_epoch = -1) for epoch in range(EPOCH): # enumerate() 函数用于将一个可遍历的数据对象组合为一个索引序列。例:['A','B','C']->[(0,'A'),(1,'B'),(2,'C')], # 这里是为了将索引传给step输出 for step, (x, y) in enumerate(train_loader): output = cnn(x) loss = loss_func(output, y) loss.backward() optimizer.step() optimizer.zero_grad() if step % 100 == 0: # enumerate() 函数用于将一个可遍历的数据对象组合为一个索引序列。例:['A','B','C']->[(0,'A'),(1,'B'),(2,'C')] for (test_x, test_y) in test_loader: # print(test_y.size()) # 在所有数据集上预测精度: # 预测结果 test_output.size() = [10000,10],其中每一列代表预测为每一个数的概率(softmax输出),而不是0或1 test_output = cnn(test_x) # torch.max()则将预测结果转化对应的预测结果,即概率最大对应的数字:[10000,10]->[10000] pred_y = torch.max(test_output,1)[1].squeeze() # squeeze()默认是将a中所有为1的维度删掉 # pred_size() = [10000] accuracy = sum(pred_y == test_y) / test_data.__len__() print('Eopch:', epoch, ' | train loss: %.6f' % loss.item(), ' | test accracy:%.5f' % accuracy, ' | step: %d' % step)INPUT层-输入层 首先是数据 INPUT 层,输入图像的尺寸统一归一化为28 * 28 C1层-卷积层 输入图片:28 * 28 卷积核大小:5*5 卷积核种类:16 步长为:1 边界填充0 输出的特征映射大小为 28 * 28 (因为使用了边界填充,所以图像大小没有发生变化),因为有16个卷积核,所以此阶段有16个特征映射图 第一次池化 采样区域 2 * 2 方式:最大值池化 输出的特征映射大小 14 * 14 这是也是16份特征映射图 C2卷积层 输入图片:14 * 14 卷积核大小:5*5 卷积核种类:32 步长为:1 边界填充0 输出的特征映射大小为 14 * 14 (因为使用了边界填充,所以图像大小没有发生变化),因为有32个卷积核,所以此阶段有32个特征映射图 第二次池化 采样区域 2 * 2 方式:最大值池化 输出的特征映射大小 7 * 7 这时也是32份特征映射图 可视化测试 import torch import torch.nn as nn import torchvision.transforms as transforms from torchvision.datasets import ImageFolder import torchvision.models as models from torchvision import utils import torchvision.transforms as T import torch.utils.data as Data from PIL import Image import numpy as np import torch.optim as optim import cv2 import matplotlib.pyplot as plt class CNN(nn.Module): def __init__(self): super(CNN, self).__init__() self.Conv1 = nn.Sequential( #卷积层1 nn.Conv2d(1, 16, 5, 1, 2), nn.BatchNorm2d(16), #激活函数层 nn.ReLU(), #最大池化层 nn.MaxPool2d(kernel_size=2) ) self.Conv2 = nn.Sequential( #卷积层2 nn.Conv2d(16, 32, 5, 1, 2), nn.BatchNorm2d(32), nn.Dropout(p=0.2), #激活函数层 nn.ReLU(), #最大池化层 nn.MaxPool2d(kernel_size=2) ) #最后接上一个全连接层(将图像变为1维) #为什么是32*7*7:(1,28,28)->(16,28,28)(conv1)->(16,14,14)(pool1)->(32,14,14)(conv2)->(32,7,7)(pool2)->output self.Linear = nn.Sequential( nn.Linear(32*7*7,400), nn.Dropout(p=0.2), nn.ReLU(), nn.Linear(400,80), nn.ReLU(), nn.Linear(80,26), ) def forward(self, input): input = self.Conv1(input) input = self.Conv2(input) #view可理解为resize #input.size() = [100, 32, 7, 7], 100是每批次的数量,32是厚度,图片尺寸为7*7 #当某一维是-1时,会自动计算他的大小(原则是总数据量不变): input = input.view(input.size(0), -1) #(batch=100, 1568), 最终效果便是将二维图片压缩为一维(数据量不变) #最后接上一个全连接层,输出为10:[100,1568]*[1568,10]=[100,10] output = self.Linear(input) return output #读取网络框架 cnn = CNN() #读取权重: cnn.load_state_dict(torch.load('EMNIST_CNN.pkl')) #test_x:(10000行1列,每列元素为28*28矩阵) # 提供指定的数据进行测试: my_img = plt.imread("Emnist_letters_png/Pre_jpg/C.jpg") my_img = my_img[:,:,0] # 转换为单通道 my_img = cv2.resize(my_img,(28,28)) # 转换为28*28尺寸 my_img = torch.from_numpy(my_img) # 转换为张量 my_img = torch.unsqueeze(my_img, dim=0) # 添加一个维度 my_img = torch.unsqueeze(my_img, dim=0)/255. # 再添加一个维度并把灰度映射在(0,1之间) #可视化部分: #输入原图像: plt.imshow(my_img.squeeze()) plt.show() #Conv1: cnt = 1 my_img = cnn.Conv1(my_img) img = my_img.squeeze() for i in img.squeeze(): plt.axis('off') fig = plt.gcf() fig.set_size_inches(5,5) # 输出width*height像素 plt.margins(0,0) plt.imshow(i.detach().numpy()) plt.subplot(4, 4, cnt) plt.axis('off') plt.imshow(i.detach().numpy()) cnt += 1 plt.subplots_adjust(top=1,bottom=0,left=0,right=1,hspace=0,wspace=0) plt.show() #Conv2: cnt = 1 my_img = cnn.Conv2(my_img) img = my_img.squeeze() for i in img.squeeze(): plt.axis('off') fig = plt.gcf() fig.set_size_inches(5,5)#输出width*height像素 plt.margins(0,0) plt.imshow(i.detach().numpy()) plt.subplot(4, 8, cnt) plt.axis('off') plt.imshow(i.detach().numpy()) cnt += 1 #plt.subplots_adjust(top=1,bottom=0,left=0,right=1,hspace=0,wspace=0) plt.show() #全连接层: my_img = my_img.view(my_img.size(0), -1) fig = plt.gcf() fig.set_size_inches(10000,4) # 输出width*height像素 plt.subplots_adjust(top=1,bottom=0,left=0,right=1,hspace=0,wspace=0) plt.margins(0,0) my_img = cnn.Linear[0](my_img) plt.subplot(3, 1, 1) plt.imshow(my_img.detach().numpy()) my_img = cnn.Linear[1](my_img) my_img = cnn.Linear[2](my_img) my_img = cnn.Linear[3](my_img) plt.subplot(3, 1, 2) plt.imshow(my_img.detach().numpy()) my_img = cnn.Linear[4](my_img) my_img = cnn.Linear[5](my_img) plt.subplot(3, 1, 3) plt.imshow(my_img.detach().numpy()) plt.show() #输出预测结果: pred_y = int(torch.max(my_img,1)[1]) print('\n %s : %s' % ("待预测字母对应字母表可能位置的概率为" , my_img)) #chr()将数字转为对应的的ASCAII字符 print('\n predict character: %c or %c' % (chr(pred_y+65), chr(pred_y+97))) |
【本文地址】
今日新闻 |
推荐新闻 |