手写数字识别(识别纸上手写的数字) |
您所在的位置:网站首页 › 手写体数字的识别 › 手写数字识别(识别纸上手写的数字) |
手写数字识别(识别纸上手写的数字)
|
说明
使用pytorch框架,实现对MNIST手写数字数据集的训练和识别。重点是,自己手写数字,手机拍照后传入电脑,使用你自己训练的权重和偏置能够识别。数据预处理过程的代码是重点。 分析要识别自己用手在纸上写的数字,从特征上来看,手写数字相比于普通的电脑上的数字最大的 不同就是数字的边缘会发生不同幅度的抖动。而且,在MNIST数据集中的数字是边缘为黑色的,然后数字是不同灰度的白色的,如下所示: 至此,对手写数字网络的训练已经结束,且训练的准确性为: 因为我们手机拍的照片和训练集的图片有很大的区别,所以无法将手机上拍的照片直接丢到训练好的网络模型中进行识别,需要先对图片进行预处理。有几点需要对原图进行改变: 图片的大小:肯定得将拍摄到的图片转换成 28 ∗ 28 28*28 28∗28尺寸大小的图片。图片的通道数:由于MNIST是灰度图,所以原图的channel也得转换成1。图片的背景:图片的背景得转换成MNIST相同的黑色,这样识别结果准确性更高。数字的颜色:毋庸置疑,数字的颜色得变成MNIST相同的白色。数字颜色中间深边缘前:观察MNIST的白色部分并不都是255全白,而是有渐变色的,这个渐变色模拟起来比较困难,算是难度最大的一点了。 接下来直接上代码了: import cv2 import numpy as np def image_preprocessing(): # 读取图片 img = cv2.imread("picture/test8.jpeg") # =====================图像处理======================== # # 转换成灰度图像 gray_img = cv2.cvtColor(img , cv2.COLOR_BGR2GRAY) # 进行高斯滤波 gauss_img = cv2.GaussianBlur(gray_img, (5,5), 0, 0, cv2.BORDER_DEFAULT) # 边缘检测 img_edge1 = cv2.Canny(gauss_img, 100, 200) # ==================================================== # # =====================图像分割======================== # # 获取原始图像的宽和高 high = img.shape[0] width = img.shape[1] # 分别初始化高和宽的和 add_width = np.zeros(high, dtype = int) add_high = np.zeros(width, dtype = int) # 计算每一行的灰度图的值的和 for h in range(high): for w in range(width): add_width[h] = add_width[h] + img_edge1[h][w] # 计算每一列的值的和 for w in range(width): for h in range(high): add_high[w] = add_high[w] + img_edge1[h][w] # 初始化上下边界为宽度总值最大的值的索引 acount_high_up = np.argmax(add_width) acount_high_down = np.argmax(add_width) # 将上边界坐标值上移,直到没有遇到白色点停止,此为数字的上边界 while add_width[acount_high_up] != 0: acount_high_up = acount_high_up + 1 # 将下边界坐标值下移,直到没有遇到白色点停止,此为数字的下边界 while add_width[acount_high_down] != 0: acount_high_down = acount_high_down - 1 # 初始化左右边界为宽度总值最大的值的索引 acount_width_left = np.argmax(add_high) acount_width_right = np.argmax(add_high) # 将左边界坐标值左移,直到没有遇到白色点停止,此为数字的左边界 while add_high[acount_width_left] != 0: acount_width_left = acount_width_left - 1 # 将右边界坐标值右移,直到没有遇到白色点停止,此为数字的右边界 while add_high[acount_width_right] != 0: acount_width_right = acount_width_right + 1 # 求出宽和高的间距 width_spacing = acount_width_right - acount_width_left high_spacing = acount_high_up - acount_high_down # 求出宽和高的间距差 poor = width_spacing - high_spacing # 将数字进行正方形分割,目的是方便之后进行图像压缩 if poor > 0: tailor_image = img[acount_high_down - poor // 2 - 5:acount_high_up + poor - poor // 2 + 5, acount_width_left - 5:acount_width_right + 5] else: tailor_image = img[acount_high_down - 5:acount_high_up + 5, acount_width_left + poor // 2 - 5:acount_width_right - poor + poor // 2 + 5] # ==================================================== # # ======================小图处理======================= # # 将裁剪后的图片进行灰度化 gray_img = cv2.cvtColor(tailor_image , cv2.COLOR_BGR2GRAY) # 高斯去噪 gauss_img = cv2.GaussianBlur(gray_img, (5,5), 0, 0, cv2.BORDER_DEFAULT) # 将图像形状调整到28*28大小 zoom_image = cv2.resize(gauss_img, (28, 28)) # 获取图像的高和宽 high = zoom_image.shape[0] wide = zoom_image.shape[1] # 将图像每个点的灰度值进行阈值比较 for h in range(high): for w in range(wide): # 若灰度值大于100,则判断为背景并赋值0,否则将深灰度值变白处理 if zoom_image[h][w] > 100: zoom_image[h][w] = 0 else: zoom_image[h][w] = 255 - zoom_image[h][w] # ==================================================== # return zoom_image在此,我在纸上写了个6,如下图所示: 预测代码如下: import torch # pretreatment.py为上面图片预处理的文件名,导入图片预处理文件 import pretreatment as PRE # 加载网络模型 net = torch.load('weight/test.pkl') # 得到返回的待预测图片值,就是pretreatment.py中的zoom_image img = PRE.image_preprocessing() # 将待预测图片转换形状 inputs = img.reshape(-1, 784) # 输入数据转换成tensor张量类型,并转换成浮点类型 inputs = torch.from_numpy(inputs) inputs = inputs.float() # 丢入网络进行预测,得到预测数据 predict = net(inputs) # 打印对应的最后的预测结果 print("The number in this picture is {}".format(torch.argmax(predict).detach().numpy()))最后得到结果如图所示: |
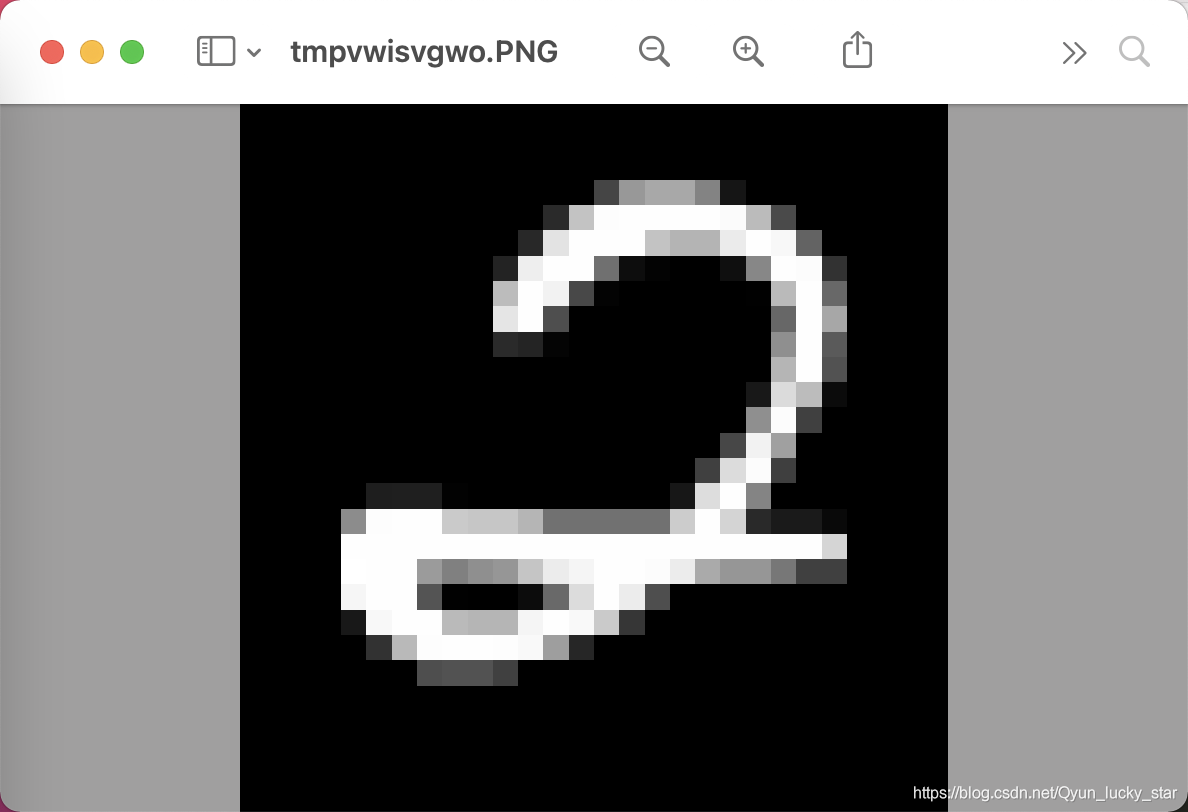 在数据集中,每个数据都是
28
∗
28
28*28
28∗28的灰度图,并且黑色部分都是零,其余白色的灰度值并不统一。因为如果训练时背景都是统一的时候我们测试用的图片背景也必须是统一的,否则基本无法识别出来。除非训练的时候换各种不同的背景大数据进行训练,这样特征就不会依托着背景而存在,剩下的就是要识别的物体自己所拥有的特征了。所以在这里我要做的就是在图片预处理的时候尽量让图片处理成接近测试图片的样子。
在数据集中,每个数据都是
28
∗
28
28*28
28∗28的灰度图,并且黑色部分都是零,其余白色的灰度值并不统一。因为如果训练时背景都是统一的时候我们测试用的图片背景也必须是统一的,否则基本无法识别出来。除非训练的时候换各种不同的背景大数据进行训练,这样特征就不会依托着背景而存在,剩下的就是要识别的物体自己所拥有的特征了。所以在这里我要做的就是在图片预处理的时候尽量让图片处理成接近测试图片的样子。 这个网络比较粗糙,所以准确性也只是一般,但如果要精确起来后面有很多文章可做。
这个网络比较粗糙,所以准确性也只是一般,但如果要精确起来后面有很多文章可做。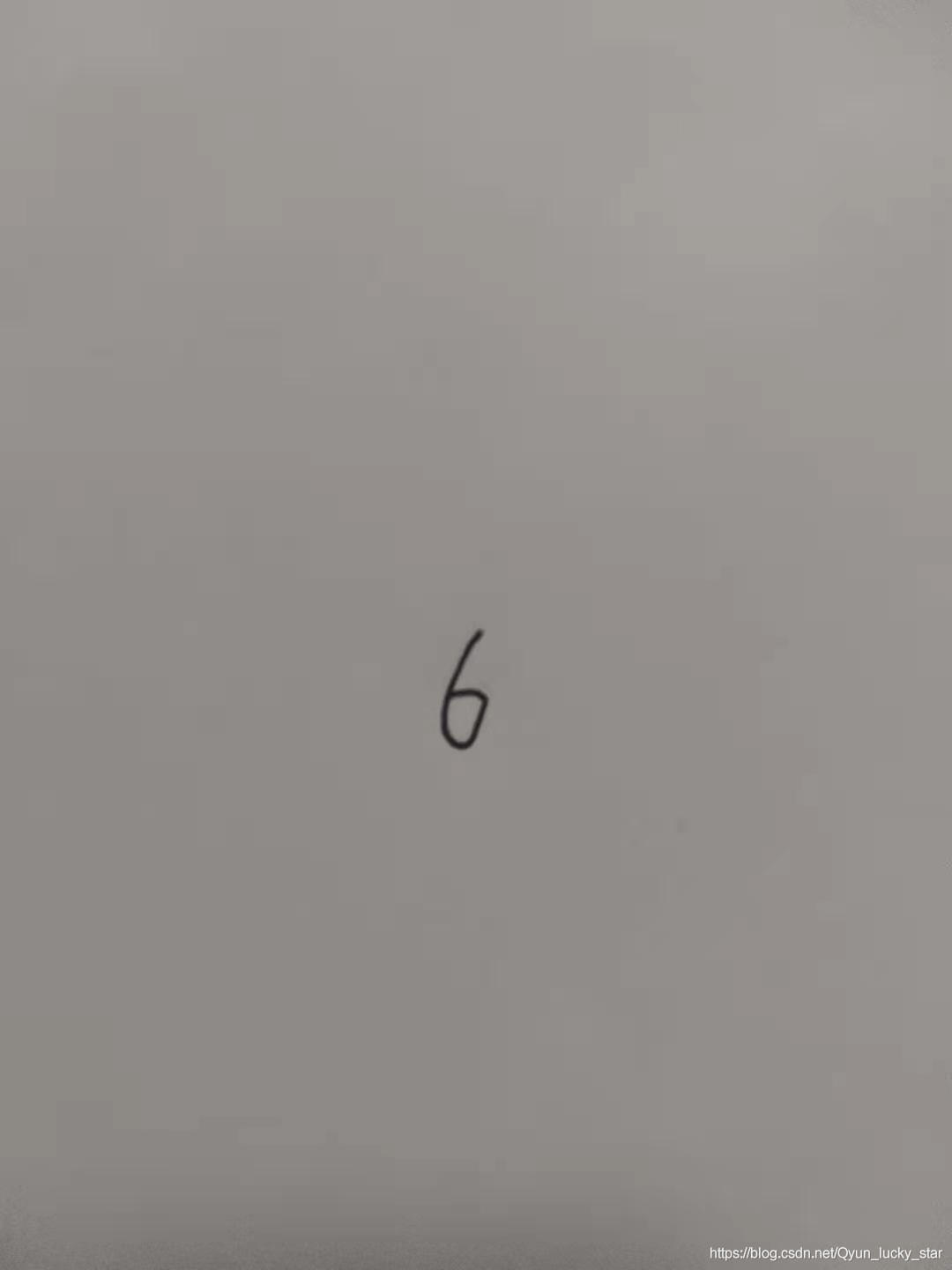 然后是对图像进行分割,首先要介绍下我分割图像的方法。下面是一张进行canny边缘检测后的6:
然后是对图像进行分割,首先要介绍下我分割图像的方法。下面是一张进行canny边缘检测后的6: 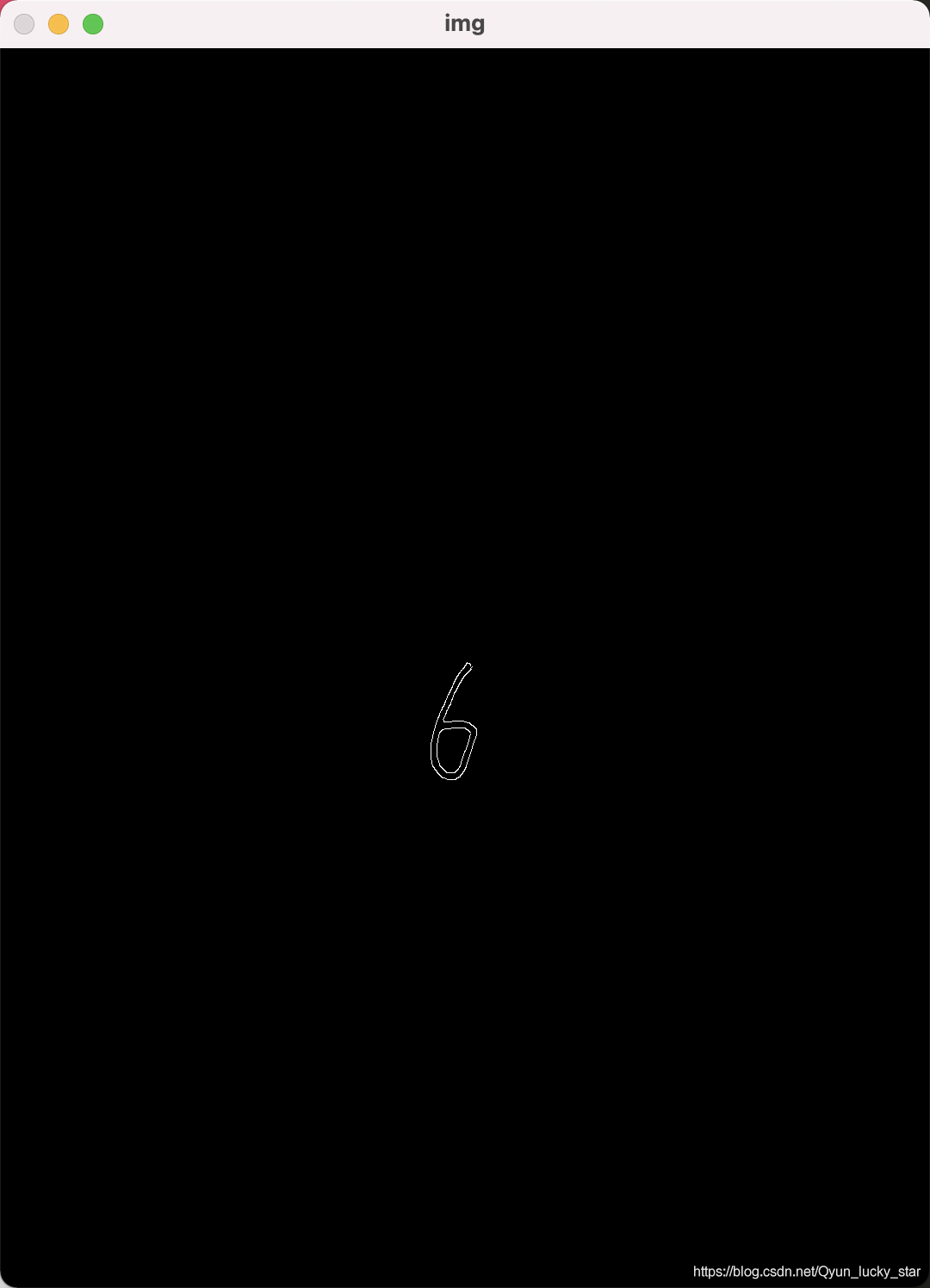 在这里这个6有个特点,就是被白边给包围着了,因为白色的灰度值为255,黑色的灰度值为0,所以我就假设以高为很坐标,然后每个高对应着的宽的灰度值进行相加。所以会很明显发现就6这个字的整体的值比较聚集,当然有可能有零星的散点,但并不影响对6所在位置的判断。最后以高为例,得到的值的坐标图如下:
在这里这个6有个特点,就是被白边给包围着了,因为白色的灰度值为255,黑色的灰度值为0,所以我就假设以高为很坐标,然后每个高对应着的宽的灰度值进行相加。所以会很明显发现就6这个字的整体的值比较聚集,当然有可能有零星的散点,但并不影响对6所在位置的判断。最后以高为例,得到的值的坐标图如下:  因为最大值比较容易找到,所以就找到最大值然后向两边延伸,当发现值为零时就可以把边界给标定出来了。 最后进行分割分割注意的是后面对图像进行裁剪的时候是将宽和高较长的一边减去较短的一边然后除以2平分给较短的一边的两侧,为了防止边缘检测没有包裹着数字,于是在数字四周都加了五个像素点进行裁剪,最后裁剪出来的效果如下:
因为最大值比较容易找到,所以就找到最大值然后向两边延伸,当发现值为零时就可以把边界给标定出来了。 最后进行分割分割注意的是后面对图像进行裁剪的时候是将宽和高较长的一边减去较短的一边然后除以2平分给较短的一边的两侧,为了防止边缘检测没有包裹着数字,于是在数字四周都加了五个像素点进行裁剪,最后裁剪出来的效果如下: 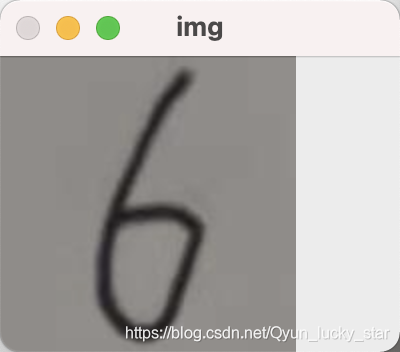 这个图片就是上述代码中的tailor_image所显示出来的图片,因为显示图片的代码只作为测试使用,而且又很简单,这里就没有展示出来。 好了,接下来就是要对辛辛苦苦裁剪出来的小图进行图像进行处理了,首先还是最基本的灰度化和高斯滤波处理,然后就是对图像进行大小转换,因为MNIST数据形状就是
28
∗
28
28*28
28∗28所以也要将输入图片转换成
28
∗
28
28*28
28∗28的大小。大小转换完成后,就是要完成把灰度图转换成背景为0,然后数字变成白色的图片,因为这样和MNIST数据集里的数字图片特别的像。在这里我用了阈值控制的方法将背景变成黑色的。至于这100当然是将图片的灰度值打出来后观察得出来的。但是这种方法是比较危险的,因为这样的鲁棒性并不强,但后面如果要加强鲁棒性则同样可以用边缘检测把数字包裹住,然后数字之外的背景清零,这确实是一个很好的思路,但在这里就建议的用阈值控制的方法来实现背景黑化了。黑化背景后当然就是将数字白化了,之前有将数字部分都是255值,但发现识别的效果并不理想,所以这里我采用了用255-原先数字的值,这样如果原先的数字黑度深的部分就会变成白色程度深,就简单的实现了数字边缘浅,中间深的变换。最后处理得到的图像如下:
这个图片就是上述代码中的tailor_image所显示出来的图片,因为显示图片的代码只作为测试使用,而且又很简单,这里就没有展示出来。 好了,接下来就是要对辛辛苦苦裁剪出来的小图进行图像进行处理了,首先还是最基本的灰度化和高斯滤波处理,然后就是对图像进行大小转换,因为MNIST数据形状就是
28
∗
28
28*28
28∗28所以也要将输入图片转换成
28
∗
28
28*28
28∗28的大小。大小转换完成后,就是要完成把灰度图转换成背景为0,然后数字变成白色的图片,因为这样和MNIST数据集里的数字图片特别的像。在这里我用了阈值控制的方法将背景变成黑色的。至于这100当然是将图片的灰度值打出来后观察得出来的。但是这种方法是比较危险的,因为这样的鲁棒性并不强,但后面如果要加强鲁棒性则同样可以用边缘检测把数字包裹住,然后数字之外的背景清零,这确实是一个很好的思路,但在这里就建议的用阈值控制的方法来实现背景黑化了。黑化背景后当然就是将数字白化了,之前有将数字部分都是255值,但发现识别的效果并不理想,所以这里我采用了用255-原先数字的值,这样如果原先的数字黑度深的部分就会变成白色程度深,就简单的实现了数字边缘浅,中间深的变换。最后处理得到的图像如下:  虽说看起来没有第一张图那么完美,但大概还是能达到验证数据所需的要求了。至此,数据预处理已经完成了,接下来就是激动的预测了。
虽说看起来没有第一张图那么完美,但大概还是能达到验证数据所需的要求了。至此,数据预处理已经完成了,接下来就是激动的预测了。 这样,整个手写数字识别基本已经完成了。
这样,整个手写数字识别基本已经完成了。【本文地址】
今日新闻 |
推荐新闻 |