房价关键影响因素分析:从数据采集到建模全过程 |
您所在的位置:网站首页 › 房价相关数据有哪些 › 房价关键影响因素分析:从数据采集到建模全过程 |
房价关键影响因素分析:从数据采集到建模全过程
|
1.2空间坐标补全 原始数据最大的问题是没有空间坐标信息,但是不同区域的房价一般存在显著差异,比如限购圈内的房子很可能就比限购圈外贵,所以补充坐标信息,以反映房子所在区位情况是必不可少的一步。 同样,为了节约时间,简单地百度关键词“python获取百度坐标”,熟练地使用复制粘贴技能,并对代码稍作更正,就能实现坐标获取的目的。以下代码定义了一个函数,用于坐标的获取: import json,urllib,math # 根据地址获取经纬度 def getlnglat(address): url = 'http://api.map.baidu.com/geocoder/v2/' output = 'json' ak = 你的百度密钥 # 浏览器端密钥 address =urllib.parse.quote(address) # 由于本文地址变量为中文,为防止乱码,先用quote进行编码 uri = url + '?' + 'address=' + address + '&output=' + output + '&ak=' + ak try: req = urllib.request.urlopen(uri) res = req.read().decode() temp = json.loads(res) # 纬度 lat = temp['result']['location']['lat'] # 经度 lng = temp['result']['location']['lng'] # 地址查找失败 if math.isclose(lat,39.910925,rel_tol=1e-5): lat = None if math.isclose(lng, 116.413384, rel_tol=1e-5): lng = None except Exception as e: print(e) lng = None lat = None return lng, lat有了上面这段代买,我们就可以根据小区名称获取对应的百度坐标了。将小区名称另存为文本,在Python中简单2行代码即可搞定! f=open('./小区名称.txt').readlines() xy=[[getlnglat('宁波'+addr.split('\n')[0])[0],getlnglat('宁波'+addr.split('\n')[0])[1]] for addr in f] with open('result.csv','a') as res: for each in xy: res.writelines(str(each[0])+','+str(each[1])+'\n')这样坐标的问题就解决了。
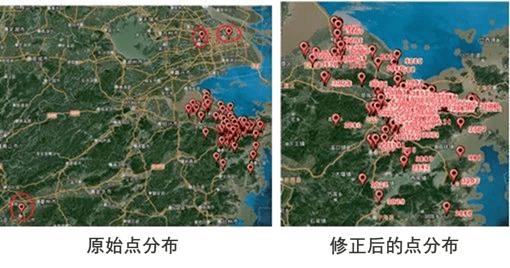
1.4数据清洗 原始数据准备就绪,但是接踵而至的问题很多: (1)数据是不是直接可用?显然不是; (2)哪些数据是重要的,哪些是不重要的?这个判断有利于减少工作量; (3)坐标怎么利用?等。 1.4.1坐标修正 坐标不对,分析结论和实际情况很可能大相径庭!因此,怀着对百度的不信任,需要人工复查一遍坐标。打开arcgis,将小区可视化在地图上。总体上来看,采集的数据点分布比较符合实际情况,呈现“中心密、郊区疏“的分布,且与各区县的经济发展情况大体一致。但是明显可以看到有些点已经超出了宁波市域范围,需要手动修正。
于是,我们可以初步观察下高房价都集中在哪些区域。图中比较亮的连片的区域事实上就是宁波的那些核心片区了。如天一附近、东部新城、南部新城等。
1.4.2增加经验性决策因素 从采集的原始数据字段来看,数据集并未体现很多我们关心的房价影响因素,这些因素有政策层面的、区位层面的、以及周边开发层面的等。因此我们需要进一步进行数据加工。 首先,567找到了宁波的限购圈范围,据此在arcgis中标志出小区是否在限购圈内,下图(右)中的蓝色点表示在限购圈内,以此反映限购政策对房价的影响。
其次,为了分析地铁站对房价的影响,需要识别小区对应的最近地铁站点,进而计算小区与地铁站的距离。567使用了arcgis中的空间关联方法实现了此步操作。 最后,为了体现小区的区位(核心区、郊区、城乡结合部等),567假设周边设施种类越多且设施数量越多则区位能级越高。为了补充这个数据,需要采集电子地图上的POI数据,这个有点小麻烦。同样,为了节约时间,567直接花了百来块大洋买了一份。这里567使用的是网格匹配法,将小区和POI均关联至所在网格(1000米X1000米),以网格聚合数据作为小区的POI数量和POI类型数。
1.4.3数据的初步清洗 数据的初步清洗是为下一步的分析和建模做准备,这与建模阶段的数据清洗有所区别,你可以理解为粗加工和精加工的区别。 因为567超级喜欢强大的powerquery,所以这里使用powerbi进行清洗,主要做了以下工作: Ø删除毫无意义的字段:链接、地址、经纪人等; Ø规范化数据表达:将带单位的面积、总价、建筑面积、首付等转化成数值类型,建造年份转化为日期等; Ø奇葩格式规整:去除数据中的空格、换行符、回车符等。
Ø统一类别表达:将五花八门的房屋朝向表述,统一规范为东西、南北等。
Ø去重:去除明显重复的数据,最后剩下的可用数据仅有1300多条。 1.4.4提取彩蛋性决策因素 从采集的数据中,我们发现有很多文本类描述信息,这些信息中非规范地表达了很多有用信息,比如学区房、在小区中的位置、采光等。这些在567看来就是非常重要的“彩蛋“性因素,能利用起来就能提高模型的分析价值。
为了从文本信息中获取更多信息,一个简单的思路是对文本信息进行分词和权重计算,据此提炼新的决策因素。针对分词,567直接使用现成jieba包,百度抄一段代码即可。分词完还需要统计各个词的词频或者权重,这里利用jieba包自带的TF/IDF算法计算了下权重,原理可以自行拓展阅读。 # -*- coding:utf-8 -*- import jieba import jieba.analyse as anls #关键词提取 import codecs import re from collections import Counter class WordCounter(object): def count_from_file(self, file, top_limit=0): with codecs.open(file, 'r', 'utf-8') as f: content = f.read() content = re.sub(r'\s+', r' ', content)#修饰空格 content = re.sub(r'\.+', r' ', content) return self.count_from_str(content, top_limit=top_limit) def count_from_str(self, content, top_limit=0): if top_limit 900):南北通透权重(600-700):精装 权重(200-400):楼层、配套、方便、花园、成熟、地段、品质、采光、地铁 权重( |
 均价热力图分布
均价热力图分布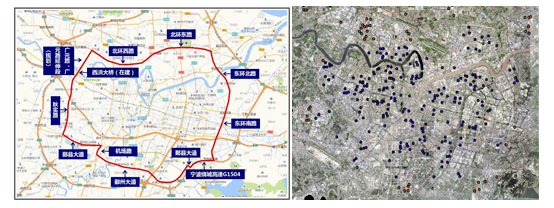
 POI数据样表
POI数据样表 网格匹配
网格匹配
【本文地址】