EasyDL专业版使用体验和口罩识别的实现 |
您所在的位置:网站首页 › 戴口罩的感想 › EasyDL专业版使用体验和口罩识别的实现 |
EasyDL专业版使用体验和口罩识别的实现
|
目录
一、EasyDL专业版介绍二、EasyDL专业版分类模型的使用三、口罩识别的训练和实现
一、EasyDL专业版介绍
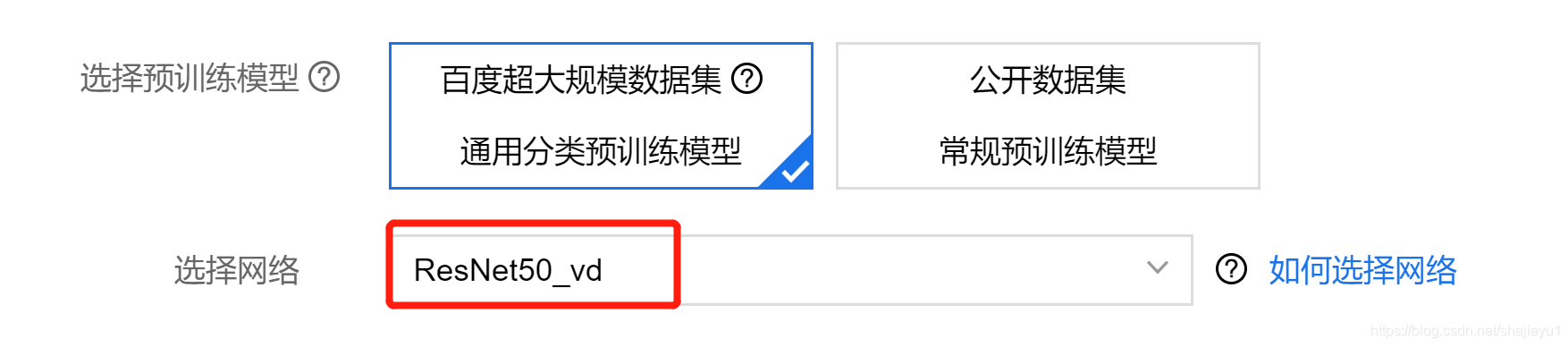
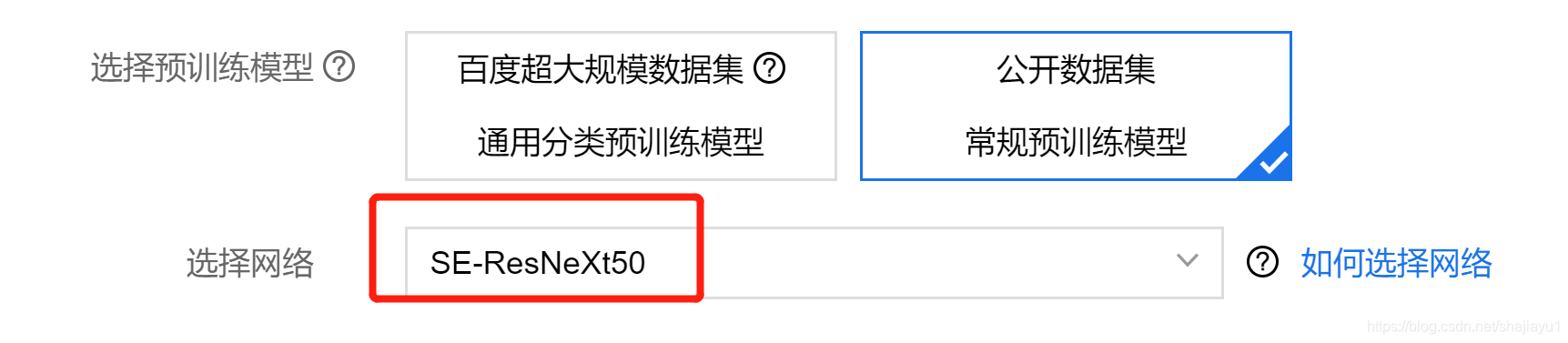
登录地址 EasyDL专业版适用于AI初学者及AI专业工程师,支持一站式获取视觉及自然语言处理两大技术方向相关AI能力,系统内置基于百度海量数据训练的预训练模型及预置网络,可在少量训练数据上达到更优的训练效果。模型部署上可将模型灵活部署为公有云API、私有服务器部署、设备端SDK、软硬一体方案。 EasyDL的公开课 二、EasyDL专业版分类模型的使用下面讲一下EasyDL做图像分类的一些体会和参数设置: 模型的选择 因为是分类任务,对比了上面图片的2个模型。实测结果是:在同样的参数配置下,百度超大规模数据集的Resnet50的比公开数据集的SE-Resnet50要更好一些。可见模型性能是一方面,训练的数据也非常重要。如果是迁移学习,还是要在超大规模数据集的模型基础上进行迁移。 Resnet50的召回率是 96.1%,SE-Resnet50的召回率是94.1%。其他指标也是百度超大规模数据集的Resnet50更好些。 自动增强和手动增强 label_smoothing label_smoothing是个选择项如果设置成true则启用label_smoothing,设置成false则禁止label_smoothing。一般会设置成true。也可以根据当前数据集进行对比测试确定是否启用label_smoothing。 mix-up数据增强 mix-up是个选择项如果设置成true则启用mix-up,设置成false则禁止mix-up。一般会设置成true。也可以根据当前数据集进行对比测试确定是否启用mix-up。 训练集、验证集和评测集 上传数据集以后,EasyDL会自动划分训练集和验证集。评测集需要单独上传。训练的结果受到了训练集和验证集的影响。评测集是单独的数据集,可以更加客观的评价模型的训练结果。如果是验证集更方面指标都比较好,但是评测集不理想则可能发生了过拟合。 batch_size batch_size选择16,这个根据训练GPU的性能决定,尽量选择大的数值。更大的batch_size会有更好的训练效果。 epochs 如果采用了数据增强,一般会增加训练的epochs。数据增强其实增加了数据集的数量,需要增加训练次数。EasyDL的数据增强不会保存增加的数据集,是在训练的过程当中随机产生新数据。 三、口罩识别的训练和实现口罩识别可以用分类模型也可以选择目标检测模型。目标检测除了给出分类结果还可以提供目标的位置信息。如果是训练目标检测模型会更复杂一些,训练的时间一般也会更长一些。 口罩佩戴识别是比较基础的深度学习任务。分为戴口罩和不戴口罩。 还可以同时检测口罩是否佩戴正确。正确戴口罩,错误戴口罩和不戴口罩。错误戴口罩还分为戴口罩露鼻子、口罩上下戴反。或者还有其他可以细化的分类。细化分类标签有利于模型训练。可以观察每种分类的准确率,精确率和召回率等。针对性的补充数据再次训练。 口罩识别使用YOLO-V3模型多一些。 |
 数据增强在模型训练中的作用是非常大的。成本比较低,效果比较明显。比起修改模型,完善模型细节,数据增强也更加容易实现。 EasyDL有提供默认配置,手动配置和自动搜索三种数据增强的策略。 手动配置和自动搜索是用户一般选择的策略。如果对数据集有比较深入的研究和体会可以自己设置手动配置。一般用户直接选择自动搜索即可。 自动搜索数据增强策略会占用GPU时间。百度会赠送EasyDL新用户100个小时的GPU训练时间。自动搜索会占用1个小时以上的GPU训练时间。 可以先用自动搜索策略确定数据增强的参数。然后根据自动搜索的结果再进行手动配置。不断尝试找到更理想的数据增强参数。当然这样比较消耗时间。
数据增强在模型训练中的作用是非常大的。成本比较低,效果比较明显。比起修改模型,完善模型细节,数据增强也更加容易实现。 EasyDL有提供默认配置,手动配置和自动搜索三种数据增强的策略。 手动配置和自动搜索是用户一般选择的策略。如果对数据集有比较深入的研究和体会可以自己设置手动配置。一般用户直接选择自动搜索即可。 自动搜索数据增强策略会占用GPU时间。百度会赠送EasyDL新用户100个小时的GPU训练时间。自动搜索会占用1个小时以上的GPU训练时间。 可以先用自动搜索策略确定数据增强的参数。然后根据自动搜索的结果再进行手动配置。不断尝试找到更理想的数据增强参数。当然这样比较消耗时间。【本文地址】
今日新闻 |
推荐新闻 |