软考 |
您所在的位置:网站首页 › 成绩表排名函数 › 软考 |
软考
|
一、函数依赖
1、定义
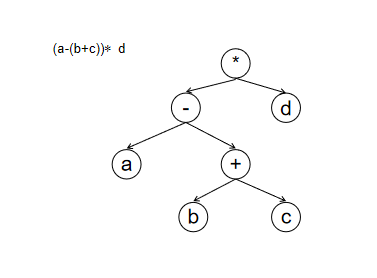
表中某一字段Y的值是由另外一个字段X的值来确定的,就称为Y函数依赖于X。 设X,Y是关系R的两个属性集合,当任何时刻R中的任意两个元组中的X属性值相同时,则它们的Y属性也是相同的,则称为X函数决定Y,或Y函数依赖X。 ①平凡函数依赖 当关系中属性集合Y是属性集合X的子集时(Y⊆X),存在函数依赖X→Y,即一组属性函数决定它的所有子集,这种函数依赖称为平凡函数依赖。 ②非平凡函数依赖 当关系中属性集合Y不是属性集合X的子集时,存在函数依赖X→Y,则称这种函数依赖为非平凡函数依赖。 ③完全函数依赖 设X,Y是关系R的两个属性集合,X’是X的真子集,存在X→Y,但对每一个X’都有X’!→Y,则称Y完全函数依赖于X。 ④部分函数依赖 设X,Y是关系R的两个属性集合,存在X→Y,若X’是X的真子集,存在X’→Y,则称Y部分函数依赖于X。 ⑤传递函数依赖 设X,Y,Z是关系R中互不相同的属性集合,存在X→Y(Y !→X),Y→Z,则称Z传递函数依赖于X。 2、属性关系属性之间有三种关系,但并不是每一种关系都存在函数依赖。 设R(U)是属性集U上的关系模式,X、Y是U的子集: ● 如果X和Y之间是1:1关系(一对一关系),如学校和校长之间就是1:1关系,则存在函数依赖X → Y和Y →X。 ● 如果X和Y之间是1:n关系(一对多关系),如年龄和姓名之间就是1:n关系,则存在函数依赖Y → X。 ● 若 X → Y,并且 Y → X, 则记为 X ←→ Y。 ● 若 Y 不函数依赖于 X, 则记为 X -\→ Y。 ●如果X和Y之间是m:n关系(多对多关系),如学生和课程之间就是m:n关系,则X和Y之间不存在函数依赖。 3、案例分析学生表S(学号Sno,姓名Sname,年龄Sage,性别Ssex,班级Sdept)。 年级表C(年级号Cno,年级等级Grade)。 成绩表CJ(学号,课程号,成绩)。 如果不允许重名,则有: 在关系模式R(U)中,对于U的子集X和Y: 1、如果 X → Y,但 Y 不为 X 的子集,则称 X → Y 是非平凡的函数依赖 例:在关系SC(学号,年级号,年级等级)中, 非平凡函数依赖: (学号,年级号) → 年级等级。 2、若 X → Y,但 Y 为 X 的子集, 则称 X → Y 是平凡的函数依赖 平凡函数依赖:(学号, 年级号) →学号,(学号, 年级号) →年级号。 3、若 x → y 并且,存在 x 的真子集 x1,使得 x1 → y, 则 y 部分依赖于 x。 例:学生表(学号,姓名,性别,班级,年龄)关系中, 部分函数依赖:(学号,姓名)→性别,学号 →性别。 所以(学号,姓名)→性别 是部分函数依赖。 4、若 x → y 并且,对于 x 的任何一个真子集 x1,都不存在 x1 → y 则称y完全依赖于x。 例:成绩表(学号,课程号,成绩)关系中, 完全函数依赖:(学号,课程号)→成绩,学号-\→成绩,课程号 -\→成绩。 所以(学号,课程号)→成绩 是完全函数依赖。 5、若x → y并且y → z,而y -\→ x,则有x → z,称这种函数依赖为传递函数依赖。 例:关系S1(学号,系名,系主任), 学号 →系名,系名 →系主任,并且系名 -\→学号,系主任 -\→系名。 所以学号 →系主任为传递函数依赖。 二、范式 范式的定义范式是关系数据库关系模式规范化的标准,从规范化的宽松到严格,分为不同的范式,通常使用的有第一范式、第二范式、第三范式及BC范式。范式是建立在函数依赖基础上的。 满足最低要求的范式是第一范式。在第一范式的基础上进一步满足更多要求的称为第二范式,其余范式以此类推 1、第一范式(1NF) 第一范式满足关系表中的属性不可分割。属性即关系表中的字段;不可分割即该属性/字段已经是不可分割的最小单位了。 一范式是关系数据库的基础。1NF是关系模式应具备的最起码的条件,如果数据库设计不能满足第一范式,就不能称为关系型数据库。关系数据库设计研究的关系规范化是在1NF之上进行的。 如果关系模式R是第一范式的模式,那么R的每一个关系r的属性都是原子项,不可分割。 如果关系模式R是1NF,且每一个非主属性完全依赖于候选建,那么就称R是第二范式。 第二范式要满足的条件:首先要满足第一范式,其次每一个非主属性要完全函数依赖于候选键,或者是主键。每个非主属性是由整个主键函数决定的,而不能由主键的一部分来决定。 第二范式(2NF):符合1NF,并且,非主属性完全依赖于码。一个候选码中的主属性也可能是好几个。如果一个主属性,它不能单独做为一个候选码,那么它也不能确定任何一个非主属性。 3、第三范式在第二范式的基础上,消除属性之间的传递依赖。即在第二范式的基础上,关系表若满足每个非主属性都不传递函数依赖于主键,就是第三范式。 什么是非主属性都不传递函数依赖于主键?关系表中有非主属性C依赖于非主属性B,非主属性B依赖于主键A,则非主属性C传递函数依赖与主键A。 例子: 简单来说,消除传递依赖,可以看做是“消除冗余”。即相关信息只能存储于一张表中,而不应该重复出现于多张表中。 例如大学分了很多系(中文系、英语系、计算机系……),系别管理表由以下字段系编号,系主任,系简介,… 组成。在学生信息表(学号、姓名、年龄、性别)中,我们能不能把学生的系编号,系主任、系简介添加至每条学生记录中?第三范式不允许!在组合表中,学号是主键,系编号依赖于学号,而系主任、系简介依赖于系编号,所以存在学号->系编号->系主任、系简介的函数传递依赖。因为系编号,系主任、系简介已经存在系别管理表中,你再存入学生信息表,就是冗余了。 解决该问题以满足第三范式的方法,就是在学生信息表中只存放系别管理表的主键,作为学生信息表的外键以消除冗余。 4、BC范式满足以下三点: 1)所有非主属性对每一个码都是完全函数依赖。(也是第二范式要求) 2)所有主属性对每一个不包含它的码也是完全函数依赖。(也就是排除了所有属性对码的部分依赖) 3)没有任何属性完全函数依赖于非码的任何一组属性。(排除传递函数依赖) 例子: 假设仓库管理关系表(仓库ID, 存储物品ID, 管理员ID, 数量),且有一个管理员只在一个仓库工作;一个仓库可以存储多种物品。 此关系模式已经属于了3NF,那么这个关系模式是否存在问题呢?我们来看以下几种操作: 1.先新增加一个仓库,但尚未存放任何物品,是否可以为该仓库指派管理员?——不可以,因为物品名也是主属性,根据实体完整性的要求,主属性不能为空。 2.某仓库被清空后,需要删除所有与这个仓库相关的物品存放记录,会带来什么问题?——仓库本身与管理员的信息也被随之删除了。 3.如果某仓库更换了管理员,会带来什么问题?——这个仓库有几条物品存放记录,就要修改多少次管理员信息。 从这里我们可以得出结论,在某些特殊情况下,即使关系模式符合3NF的要求,仍然存在着插入异常,修改异常与删除异常的问题,仍然不是 ”好“ 的设计。 具体原因是该数据库表中存在如下依赖关系: (仓库ID, 存储物品ID) →(管理员ID, 数量) (管理员ID, 存储物品ID) → (仓库ID, 数量) 所以,(仓库ID, 存储物品ID)和(管理员ID, 存储物品ID)都是候选关键字,表中的唯一非关键字段为数量,它是符合第三范式的。但是,由于存在如下依赖关系: (仓库ID) → (管理员ID) (管理员ID) → (仓库ID) 即存在关键字段依赖关键字段的情况,不满足说明中的第二条,所以其不符合BCNF范式。 第一范式、第二范式内容参考:https://www.cnblogs.com/rosesmall/p/9585655.html 第三范式、BC范式内容参考:https://www.jianshu.com/p/dd6a8d58d2dd 三、路由 1、路由类型 路由类型说明直连网络ID (Directly attached network ID)用于直接连接的网络,Interface (或 next hop) 可以为空远程网络ID (Remote network ID)用于不直接连接的网络,可以通过其他路由器到达这种网络,Interface 字段是本地路由器的IP地址主机路由 (Host route)到达特定主机的路由,子网掩码为255.255.255.255默认路由 (Default route)无法找到确定路由时使用的路由,目标网络和网络掩码都是0.0.0.0持久路由 (Persistent route)利用 route add-p命令添加的表项,每次初始化时,这种路由都会加入Windows的注册表中,同时加入路由表 四、数据结构与算法 1、表达式前缀表达式、中缀表达式、后缀表达式,是通过树来存储和计算表达式的三种不同方式。 表达式数据结构运算前缀表达式树的前序遍历波兰式队列中缀表达式树的中序遍历后缀表达式树的后序遍历逆波兰式栈●前序遍历:符号 - 左操作数 - 右操作数 ●中序遍历:左操作数 - 符号 - 右操作数 ●后序遍历:左操作数 - 右操作数 - 符号 例子: 公式:(a-(b+c))∗d。通过树来存储该公式,可以表示为:
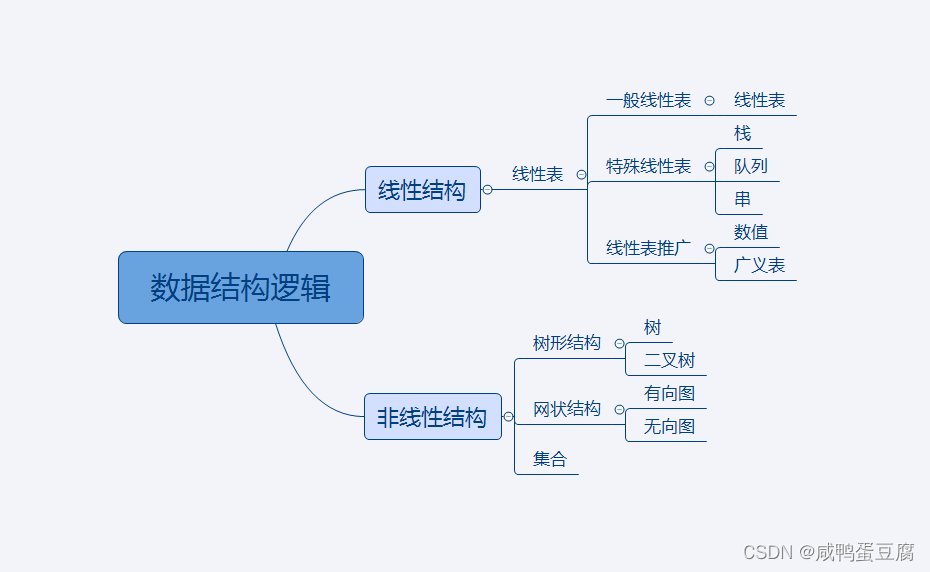
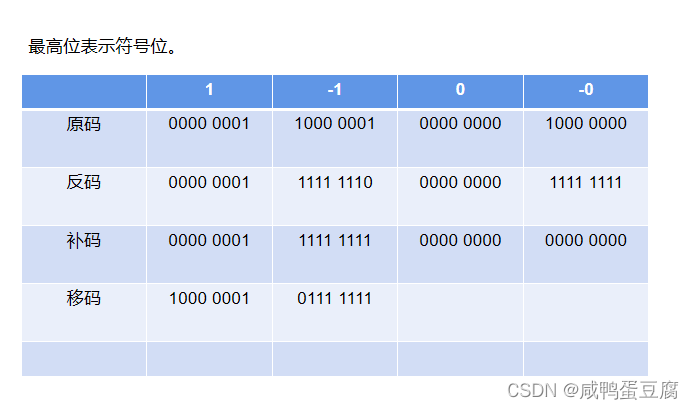
优点: ● 按照索引查询速度快、遍历数组方便 缺点: ● 数组大小固定后无法扩容; ● 数组只能存储一种类型的数据; ● 添加删除慢(需要移动其它元素)。 使用场景: 频繁查询,对存储空间要求不大;增加删除少的情况。 ② 栈栈是一种特殊的线性表,仅能在线性表的一端操作,栈顶允许操作,栈底不允许操作 。 特点: 先进后出 使用场景 : 栈常应用于实现递归功能方面的场景,例如斐波那契数列。 ③ 队列队列也是一种线性表 。 不同的是,队列可以在一端添加元素,在另一端取出元素 。 特点: 先进先出 使用场景 : 因为队列先进先出的特点,在多线程阻塞队列管理中非常适用。 ④ 链表链表是物理存储单元上非连续的、非顺序的存储结构,数据元素的逻辑顺序是通过链表的指针地址实现,每个元素包含两个结点,一个是存储元素的数据域(内存空间),另一个是指向下一个结点的指针域。 根据指针的指向,链表能形成不同的结构。例如:单链表,双向链表,循环链表等。 优点: ● 常用的一种数据结构,不需要初始化容量,可以任意加减元素; ● 添加或删除元素时只需要改变前后两个元素结点的指针域指向地址即可,添加删除速度很快。 缺点: ● 因含有大量的指针域,占用空间较大; ● 查找元素需要遍历链表来查找,非常耗时。 使用场景: 数据量较小,需要频繁添加删除操作的场景。 ⑤ 树树是由结点或顶点和边组成的(可能是非线性的)且不存在着任何环的一种数据结构。 特点: ● 每个结点有零个或多个子结点; ● 没有父结点的结点为根节点; ● 每个非根结点有且只有一个父结点; ● 除了根结点外,每个子结点可以分为多个不相交的子树。 ⑥ 散列表散列表(Hash table,也叫哈希表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。 这个映射函数叫做散列函数,存放记录的数组叫做散列表。 ⑦ 堆堆(Heap)是计算机科学中一类特殊的数据结构的统称。堆通常是一个可以被看做一棵完全二叉树的数组对象。 特点: ● 堆中某个节点的值总是不大于或不小于其父节点的值;堆总是一棵完全二叉树; ● 将根节点最大的堆叫做最大堆或大根堆,根节点最小的堆叫做最小堆或小根堆。常见的堆有二叉堆、斐波那契堆等。 ⑧ 图图是另一种非线性数据结构。在图结构中,数据结点一般称为顶点,而边是顶点的有序偶对。如果两个顶点之间存在一条边,那么就表示这两个顶点具有相邻关系。 五、数据库设计数据库设计一般分为需求分析、概念设计、逻辑设计和物理设计几个阶段。 阶段需求分析数据流图(DFD图)、数据字典概念设计E-R图、UML图逻辑设计设计关系模式、相关视图物理设计设计数据的物理组织 1、ER图实体关系图,又称ERD、ER图或ER模型,是一种用于数据库设计的结构图。 ERD包含不同的符号和连接器,它们可视化两个重要的信息:系统范围内的主要实体,以及这些实体之间的相互关系。 例子: 以学生选课为例,建立简单的ER图。 事务的四大属性ACID即事务的原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability) 英文属性说明Atomicity原子性事务是一个不可分割的工作单位,事务中的操作要么都发生,要么都不发生事务要么全部执行完,要么不被执行,与现实业务相对应Consistency一致性事务必须使数据库从一个一致性状态变换到另外一个一致性状态事务的执行结果要与现实业务产生的信息相一致,数据库也就处于一致性状态Isolation隔离性多个用户并发访问数据库时,数据库为每一个用户开启的事务,不能被其他事务的操作数据所干扰,多个并发事务之间要相互隔离多个事务并发执行时不能相互干扰造成结果的错误Durability持久性一个事务一旦被提交,它对数据库中数据的改变就是永久性的,接下来即使数据库发生故障也不应该对其有任何影响事务一旦提交,其执行结果应被存入数据库而不被丢失一个事务对应了现实中的一项业务,会涉及多条对数据库的更新指令。 七、病毒 事务的属性 手机病毒电脑病毒X病毒勒索病毒CIH病毒梅利莎病毒冲击波病毒爱虫病毒震荡波病毒大无极贝革热蠕虫病毒SQL Slammer霸王虫MyDoom欢乐时光熊猫烧香 八、SQL语言数据查询语言DQL,数据操纵语言DML,数据定义语言DDL,数据控制语言DCL。 1、数据操纵语言DML用来对数据库里的数据进行操作的语言。 SELECTUPDATEINSERTDELETECALLEXPLAIN PLANLOCK查询更新插入删除锁 2、数据定义语言DDL数据定义语言主要是用在定义或改变表的结构、数据类型、表之间的链接和约束等初始化工作上,大多在建立表时使用。 CREATEALTERDROPTRUNCATECOMMENTGRANTREVOKE创建修改删除截断注释授权收回授权 3、数据控制语言DCL是用来设置或更改数据库用户或角色权限的语句。在默认状态下,只有sysadmin、dbcreator、db_owner或db_securityadmin等人员才有权力执行DCL。 COMMITSAVEPOINTROLLBACKSET TRANSACTION提交保存点回滚设置当前事务的特性 九、操作系统 1、操作系统功能①进程管理: 其工作主要是进程调度,在单用户单任务的情况下,处理器仅为一个用户的一个任务所独占, 进程管理的工作十分简单。但在多道程序或多用户的情况 下,组织多个作业或任务时,就要解决处理器的调度、 分配和回收等问题 。 ②存储管理分为几种功能: 存储分配、存储共享、存储保护 、存储扩张。 ③设备管理分有以下功能: 设备分配、设备传输控制 、设备独立性。 ④文件管理: 文件存储空间的管理、目录管理 、文件操作管理、文件保护。 ⑤作业管理: 负责处理用户提交的任何要求。 十、原码、反码、补码● 原码:十进制数据的二进制表现形式就是原码,原码最左边的一个数字就是符号位,0为正,1为负。 ● 反码:正数的反码是其本身(等于原码),负数的反码是符号位保持不变,其余位取反。 反码的存在是为了正确计算负数,因为原码不能用于计算负数。 ● 补码:正数的补码是其本身,负数的补码等于其反码 +1。因为反码不能解决负数跨零(类似于 -6 + 7)的问题,所以补码出现了。 ● 移码:补码的符号位取反。
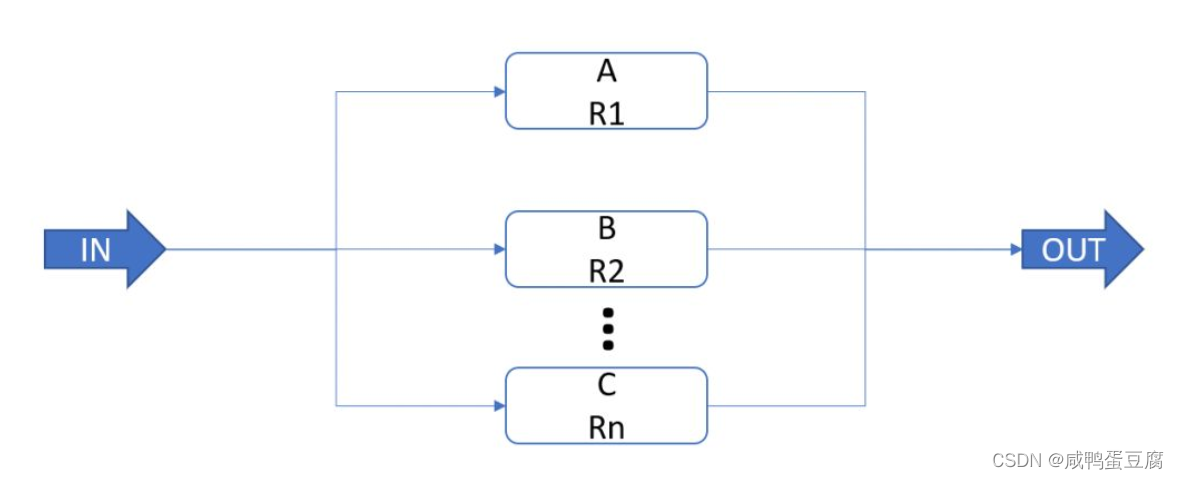
可靠性R=R1R2…*Rn 可靠性R=1-(1-R1)(1-R2)(1-Rn)
● 无条件的连接:笛卡尔积(无意义)。 ● 有条件的连接:θ连接、等值连接、自然连接。
除法:同时从水平和垂直方向进行运算。 例子: ● 在R中找两者相同属性外的属性列A和B作投影;
|
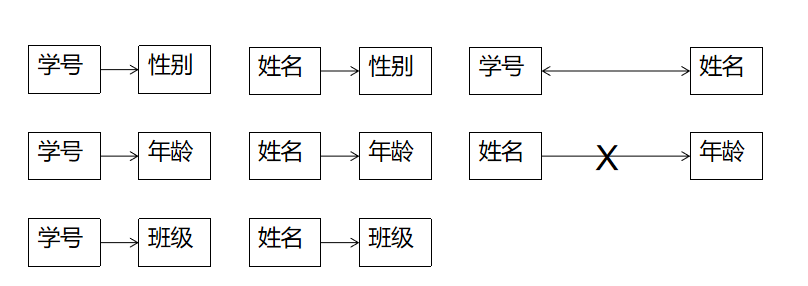 学号→ 性别, 学号→ 年龄, 学号 → 班级,学号 ←→ 姓名, 姓名→ 性别, 姓名→ 年龄, 姓名→ 班级,性别-\→ 年龄。
学号→ 性别, 学号→ 年龄, 学号 → 班级,学号 ←→ 姓名, 姓名→ 性别, 姓名→ 年龄, 姓名→ 班级,性别-\→ 年龄。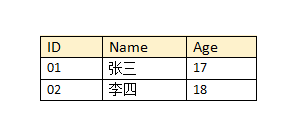
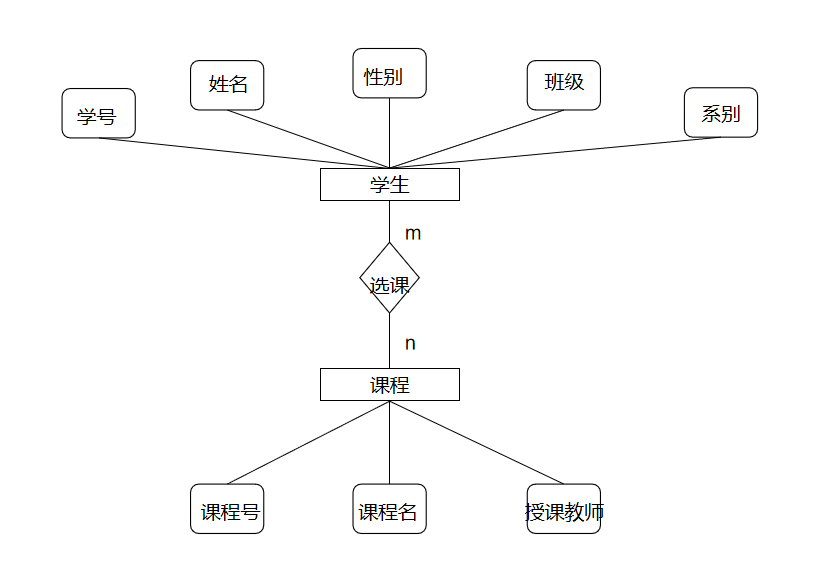

 例子:
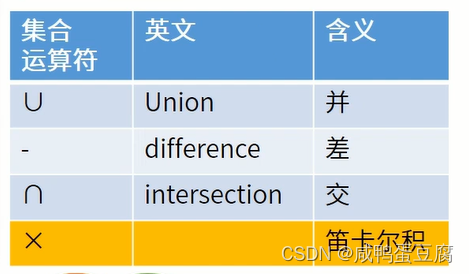
例子: 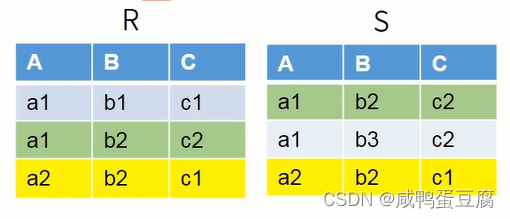 ① 并:∪
① 并:∪ 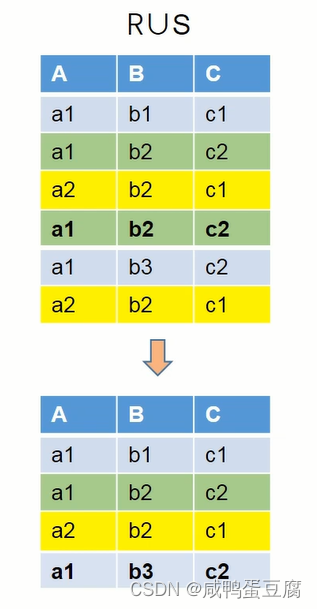 ②差:-
②差:- 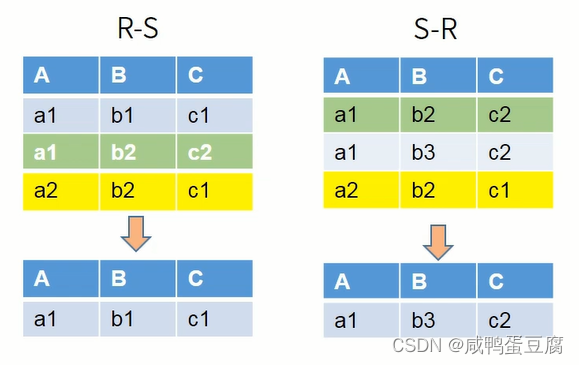 ③交:∩
③交:∩ 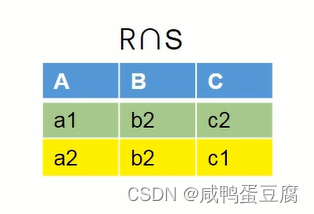 ④笛卡尔积:× 列数:R列数+S列数 行数:R行数*S行数
④笛卡尔积:× 列数:R列数+S列数 行数:R行数*S行数 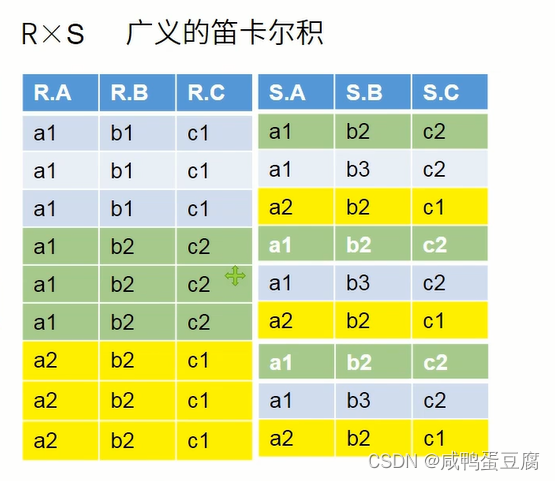
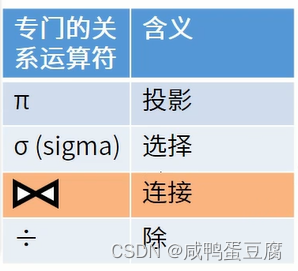 例子:
例子: 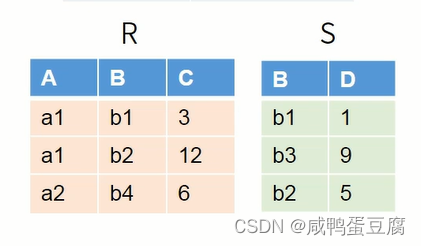
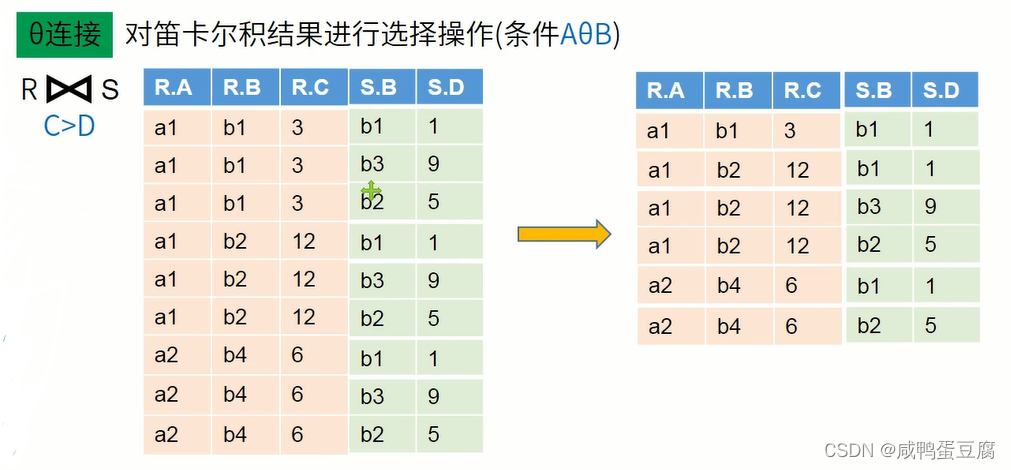
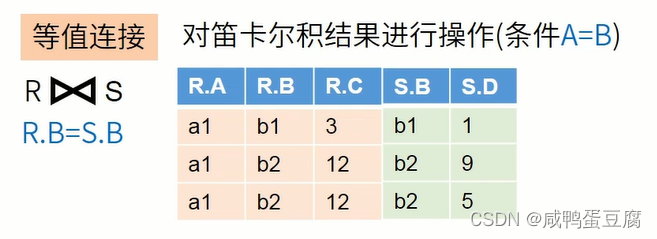
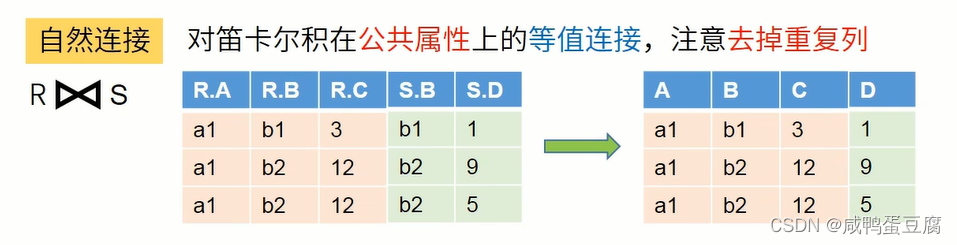
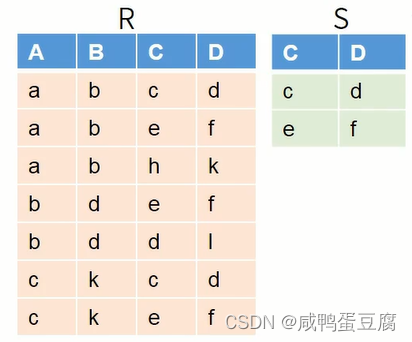 计算步骤: ● 找出R和S中相同属性列C和D,在S中对其作投影;
计算步骤: ● 找出R和S中相同属性列C和D,在S中对其作投影; 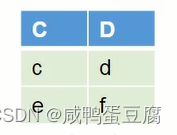
 ● 找出A和B投影属性列在R中对应的象集;
● 找出A和B投影属性列在R中对应的象集; 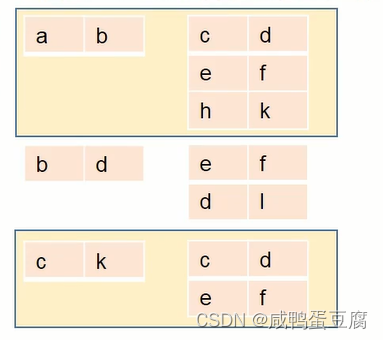 ● 判断象集的包含关系;
● 判断象集的包含关系; 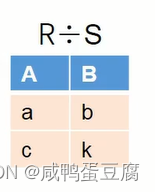
【本文地址】
今日新闻 |
推荐新闻 |