机器学习 |
您所在的位置:网站首页 › 感知机的原理及实现 › 机器学习 |
机器学习
|
神经网络知识总结
人工神经网络的由来为什么要使用神经网络?从人体神经网络系统到人工神经网络
最简单的神经网络——感知机感知机的构造感知机权值更新的概念和计算感知机的权值更新感知机详细计算过程
增加hidden layer的神经网络——BP神经网络为什么要增加隐层?delta学习规则BP神经网络权值更新的梯度下降法推导过程BP神经网络计算实例
notes:感知机和线性回归、逻辑回归的关联总结python实现——sklearn葡萄酒分类
人工神经网络的由来
为什么要使用神经网络?
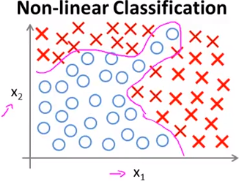
我们知道使用线性回归和逻辑回归可以解决线性可分问题,对于有些线性不可分的问题,也可以通过增加多项式来解决,但是对于决策边界较为复杂的情况:
感知机是二分类的线性分类模型,其输入是实例的特征向量,输出为实例的类别。感知器是最简单的神经网络,它只有输入层和输出层两层结构,没有中间层。 感知机的构造
感知器是怎样更新权值的呢?它通过输入信息的加权汇总,带入激活函数中,计算的输出值与target目标值(原本的标签)进行对比,若有差异,则调整权重,直到满足一定的迭代次数或者达到预设的最小误差值时停止。 简要理解感知器的权值更新过程(具体的推导请参考:《统计学习方法》第二章) 首先,我们要明了,感知机的权值更新同样采用梯度下降的方法: 当感知机采用sigmoid函数作为激活函数时,此时相当于逻辑回归!采用同样的决策边界,可以得到: O j = { − 1 , X w < 0 1 , X w > 0 O_j=\begin{cases} -1 ,&Xw0\end{cases} Oj={−1,1,Xw0 注意:此时采用双极性阈值,取值在-1~1! i)当 t = O = s i g n ( X w ) t=O=sign(Xw) t=O=sign(Xw)时,无需更新权值; ii)当 t ≠ O = s i g n ( X w ) t\not=O=sign(Xw) t=O=sign(Xw)时, { O < 0 , X w < 0 , Δ w = η ( t − O ) X = 2 η X > 0 , O 不 断 向 t = 1 靠 近 O > 0 , X w > 0 , Δ w = η ( t − O ) X = − 2 η X < 0 , O 不 断 向 t = − 1 靠 近 \begin{cases}O0,&Xw>0,\Delta w=\eta(t-O)X=-2\eta X0,Δw=η(t−O)X=−2ηX输入层权值更新: ∂ E ∂ w ( 1 ) = ∂ E ∂ a 1 ( 3 ) ⋅ ∂ a 1 ( 3 ) ∂ z 1 ( 3 ) ⋅ ∂ z 1 ( 3 ) ∂ a ( 2 ) ⋅ ∂ a ( 2 ) ∂ z ( 2 ) ⋅ ∂ z ( 2 ) ∂ w ( 1 ) \frac{\partial E}{\partial w^{(1)}}=\frac{\partial E}{\partial a_1^{(3)}}·\frac{\partial a_1^{(3)}}{\partial z_1^{(3)}}·\frac{\partial z_1^{(3)}}{\partial a^{(2)}}·\frac{\partial a^{(2)}}{\partial z^{(2)}}·\frac{\partial z^{(2)}}{\partial w^{(1)}} ∂w(1)∂E=∂a1(3)∂E⋅∂z1(3)∂a1(3)⋅∂a(2)∂z1(3)⋅∂z(2)∂a(2)⋅∂w(1)∂z(2) = − ( t − a 1 ( 3 ) ) ⋅ a 1 ( 3 ) ( 1 − a 1 ( 3 ) ) ⋅ w ( 2 ) ⋅ a ( 2 ) ( 1 − a ( 2 ) ) ⋅ X =-(t-a_1^{(3)})·a_1^{(3)}(1-a_1^{(3)})·w^{(2)}·a^{(2)}(1-a^{(2)})·X =−(t−a1(3))⋅a1(3)(1−a1(3))⋅w(2)⋅a(2)(1−a(2))⋅X = δ L ⋅ w ( 2 ) ⋅ a ( 2 ) ( 1 − a ( 2 ) ) ⋅ X =\delta_L·w^{(2)}·a^{(2)}(1-a^{(2)})·X =δL⋅w(2)⋅a(2)(1−a(2))⋅X 记: δ l = − ( t − a 1 ( 3 ) ) ⋅ a 1 ( 3 ) ( 1 − a 1 ( 3 ) ) ⋅ w ( 2 ) ⋅ a ( 2 ) ( 1 − a ( 2 ) ) \delta_l=-(t-a_1^{(3)})·a_1^{(3)}(1-a_1^{(3)})·w^{(2)}·a^{(2)}(1-a^{(2)}) δl=−(t−a1(3))⋅a1(3)(1−a1(3))⋅w(2)⋅a(2)(1−a(2)) 梯度下降更新权值: w : = w + Δ w = w + η ⋅ δ L ⋅ w ( 2 ) ⋅ a ( 2 ) ( 1 − a ( 2 ) ) ⋅ X w:=w+\Delta w=w+\eta·\delta_L·w^{(2)}·a^{(2)}(1-a^{(2)})·X w:=w+Δw=w+η⋅δL⋅w(2)⋅a(2)(1−a(2))⋅X BP神经网络计算实例基本BP算法包括信号的前向传播和误差的反向传播两个过程,我们通过一个例子详细计算BP神经网络的信号前向传播、误差反向反馈过程。 以上图为例, S t e p 1 ′ 信 号 向 前 传 播 Step 1' 信号向前传播 Step1′信号向前传播 第一层——数据输入为: X 1 , X 2 , X 3 即 a 1 ( 1 ) , a 2 ( 1 ) , a 3 ( 1 ) X_1,X_2,X_3即a_1^{(1)},a_2^{(1)},a_3^{(1)} X1,X2,X3即a1(1),a2(1),a3(1) 中间层—— a 1 ( 2 ) = g ( z 1 ( 2 ) ) , z 1 ( 2 ) = w 01 ( 1 ) x 0 + w 11 ( 1 ) x 1 + w 21 ( 1 ) x 2 + w 31 ( 1 ) x 3 a_1^{(2)}=g(z_1^{(2)} ),z_1^{(2)}=w_{01}^{(1)} x_0+w_{11}^{(1)} x_1+w_{21}^{(1)} x_2+w_{31}^{(1)} x_3 a1(2)=g(z1(2)),z1(2)=w01(1)x0+w11(1)x1+w21(1)x2+w31(1)x3 a 2 ( 2 ) = g ( z 2 ( 2 ) ) , z 2 ( 2 ) = w 02 ( 1 ) x 0 + w 12 ( 1 ) x 1 + w 22 ( 1 ) x 2 + w 32 ( 1 ) x 3 a_2^{(2)}=g(z_2^{(2)} ),z_2^{(2)}=w_{02}^{(1)} x_0+w_{12}^{(1)} x_1+w_{22}^{(1)} x_2+w_{32}^{(1)} x_3 a2(2)=g(z2(2)),z2(2)=w02(1)x0+w12(1)x1+w22(1)x2+w32(1)x3 a 3 ( 2 ) = g ( z 3 ( 2 ) ) , z 3 ( 2 ) = w 03 ( 1 ) x 0 + w 13 ( 1 ) x 1 + w 23 ( 1 ) x 2 + w 33 ( 1 ) x 3 a_3^{(2)}=g(z_3^{(2)} ),z_3^{(2)}=w_{03}^{(1)} x_0+w_{13}^{(1)} x_1+w_{23}^{(1)} x_2+w_{33}^{(1)} x_3 a3(2)=g(z3(2)),z3(2)=w03(1)x0+w13(1)x1+w23(1)x2+w33(1)x3 输出层—— O = h w ( x ) = a 1 ( 3 ) = g ( z 1 ( 3 ) ) , z 1 ( 3 ) = w 01 ( 2 ) a 0 ( 2 ) + w 11 ( 2 ) a 1 ( 2 ) + w 21 ( 2 ) a 2 ( 2 ) + w 31 ( 2 ) a 3 ( 2 ) O=h_w (x)=a_1^{(3)}=g(z_1^{(3)}),z_1^{(3)}=w_{01}^{(2)}a_0^{(2)}+w_{11}^{(2)}a_1^{(2)}+w_{21}^{(2)}a_2^{(2)}+w_{31}^{(2)}a_3^{(2)} O=hw(x)=a1(3)=g(z1(3)),z1(3)=w01(2)a0(2)+w11(2)a1(2)+w21(2)a2(2)+w31(2)a3(2) S t e p 2 ′ 误 差 反 向 反 馈 Step 2'误差反向反馈 Step2′误差反向反馈 输出层—>隐层 δ L = − ( t − a 1 ( 3 ) ) ⋅ a 1 ( 3 ) ( 1 − a 1 ( 3 ) ) \delta_L=-(t-a_1^{(3)})·a_1^{(3)}(1-a_1^{(3)}) δL=−(t−a1(3))⋅a1(3)(1−a1(3)) 隐层—>输入层 δ l = δ L ⋅ w ( 2 ) ⋅ a ( 2 ) ( 1 − a ( 2 ) ) \delta_l=\delta_L·w^{(2)}·a^{(2)}(1-a^{(2)}) δl=δL⋅w(2)⋅a(2)(1−a(2)) S t e p 3 ′ 权 值 更 新 Step 3'权值更新 Step3′权值更新 W ( 2 ) : = W ( 2 ) + η ⋅ δ L ⋅ a ( 2 ) W^{(2)}:=W^{(2)}+\eta·\delta_L·a^{(2)} W(2):=W(2)+η⋅δL⋅a(2) W ( 1 ) : = W ( 1 ) + η ⋅ δ l ⋅ X W^{(1)}:=W^{(1)}+\eta·\delta_l·X W(1):=W(1)+η⋅δl⋅X notes:感知机和线性回归、逻辑回归的关联① 感知机+sigmoid/logit函数——>逻辑回归 ② 感知机+f(x)=wx+b线性函数——>线性回归 ③ 三层网络+sigmoid/logit函数——>非线性回归 总结本文主要介绍了神经网络入门必须要了解的两个算法:感知机和BP神经网络。从人工神经网络的由来到感知机算法的原理、BP算法的原理及推导。 python实现——sklearn葡萄酒分类 导入所需库 from sklearn.neural_network import MLPClassifier from sklearn.model_selection import train_test_split #用于数据分割 from sklearn.preprocessing import StandardScaler #做数据标准化 from sklearn.metrics import classification_report,confusion_matrix import numpy as np 导入所需数据 data = np.genfromtxt('data/wine_data.csv', delimiter=',') data 数据转化——区分X和Y x_data = data[:,1:] y_data = data[:,0] #第一列是标签值 数据分割 x_train, x_test, y_train, y_test = train_test_split(x_data, y_data) 数据标准化 scaler = StandardScaler() x_train = scaler.fit_transform(x_train) x_test = scaler.fit_transform(x_test) 调用神经网络包并传入参数,拟合模型 mlp = MLPClassifier(hidden_layer_sizes=(100, 50),max_iter=500) mlp.fit(x_train, y_train) 模型预测并输出混淆矩阵 predictions = mlp.predict(x_test) print(classification_report(y_test, predictions)) print(confusion_matrix(y_test,predictions)) |
 此时,往往需要引入较多的多项式,对于变量较多的情况极为复杂,甚至容易出现过拟合。 由于大量数据的涌入和收集(大数据的驱动)我们有了新的算法:人工神经网络(ANN),它的研究是由试图模拟生物神经系统而激发的。
此时,往往需要引入较多的多项式,对于变量较多的情况极为复杂,甚至容易出现过拟合。 由于大量数据的涌入和收集(大数据的驱动)我们有了新的算法:人工神经网络(ANN),它的研究是由试图模拟生物神经系统而激发的。 人的大脑主要由称为神经元(节点)的神经细胞组成,神经元通过突触的纤维丝连在一起。当神经元受到刺激时,神经脉冲(输入)通过轴突从一个神经元传到另一个神经元。一个神经元的树突连接到其他神经元的轴突,其连接点称为神经建(权重)。 神经学家发现,人的大脑通过在同一个脉冲(输入)反复刺激下改变神经元之间的神经建连接强度(权值)来进行学习。 PS.以一个例子来看人工神经网络的运作方式: 这里借用朱江老师上课所讲的例子——《甄嬛传》高潮部分:滴血认亲 看过甄嬛传的同学应该不会忘了这一集,剧情是相当刺激~内容是这样的,祺嫔张罗一群人来指认甄嬛腹中双生子并非皇上的,而是太医温实初的。
人的大脑主要由称为神经元(节点)的神经细胞组成,神经元通过突触的纤维丝连在一起。当神经元受到刺激时,神经脉冲(输入)通过轴突从一个神经元传到另一个神经元。一个神经元的树突连接到其他神经元的轴突,其连接点称为神经建(权重)。 神经学家发现,人的大脑通过在同一个脉冲(输入)反复刺激下改变神经元之间的神经建连接强度(权值)来进行学习。 PS.以一个例子来看人工神经网络的运作方式: 这里借用朱江老师上课所讲的例子——《甄嬛传》高潮部分:滴血认亲 看过甄嬛传的同学应该不会忘了这一集,剧情是相当刺激~内容是这样的,祺嫔张罗一群人来指认甄嬛腹中双生子并非皇上的,而是太医温实初的。  (PS.图片为博主原创,转载请注明出处,谢谢!) 如上图,开始有祺嫔、丫鬟佩儿、侍女玢儿、尼姑净白被幕后主使召集起来,分别指认甄嬛腹中并非龙种,此时,这四个人作为信息的输入(input)作为幕后主使的皇后,和当事人甄嬛分别对输入信息加权汇总找出对自己有利的信息,并适当为收集信息“添油加醋”。上图连接线的粗细表示信息的权重(Weights),作为皇上,自然担心自己孩子血统是否纯正,因此对于皇后观点权重较大,此时皇上作为对全部信息的汇总输出,可能得出结论:孩子不是自己的。但是根据不断的信息涌入和转换,对权重进行调整,最终的结果是皇上认为:孩子是自己的。 以上就是一个人工神经网络传递信息的例子。由上可知,人工神经网络的一些组成是:
{
输
入
I
n
p
u
t
:
x
1
,
x
2
,
.
.
.
,
x
n
(
n
个
特
征
)
权
值
W
e
i
g
h
t
s
:
w
1
,
w
2
,
.
.
.
,
w
3
激
活
函
数
f
(
x
)
[
可
想
象
为
皇
后
对
输
入
信
息
“
添
油
加
醋
”
]
输
出
O
u
t
p
u
t
:
对
加
权
和
套
用
激
活
函
数
的
结
果
\begin{cases}输入Input:x1,x2,...,xn(n个特征)\\权值Weights:w1,w2,...,w3\\激活函数f(x)[可想象为皇后对输入信息“添油加醋”]\\输出Output:对加权和套用激活函数的结果\end{cases}
⎩⎪⎪⎪⎨⎪⎪⎪⎧输入Input:x1,x2,...,xn(n个特征)权值Weights:w1,w2,...,w3激活函数f(x)[可想象为皇后对输入信息“添油加醋”]输出Output:对加权和套用激活函数的结果 下面,我们从最简单的神经网络:感知机出发,详细捋一捋神经网络的知识。
(PS.图片为博主原创,转载请注明出处,谢谢!) 如上图,开始有祺嫔、丫鬟佩儿、侍女玢儿、尼姑净白被幕后主使召集起来,分别指认甄嬛腹中并非龙种,此时,这四个人作为信息的输入(input)作为幕后主使的皇后,和当事人甄嬛分别对输入信息加权汇总找出对自己有利的信息,并适当为收集信息“添油加醋”。上图连接线的粗细表示信息的权重(Weights),作为皇上,自然担心自己孩子血统是否纯正,因此对于皇后观点权重较大,此时皇上作为对全部信息的汇总输出,可能得出结论:孩子不是自己的。但是根据不断的信息涌入和转换,对权重进行调整,最终的结果是皇上认为:孩子是自己的。 以上就是一个人工神经网络传递信息的例子。由上可知,人工神经网络的一些组成是:
{
输
入
I
n
p
u
t
:
x
1
,
x
2
,
.
.
.
,
x
n
(
n
个
特
征
)
权
值
W
e
i
g
h
t
s
:
w
1
,
w
2
,
.
.
.
,
w
3
激
活
函
数
f
(
x
)
[
可
想
象
为
皇
后
对
输
入
信
息
“
添
油
加
醋
”
]
输
出
O
u
t
p
u
t
:
对
加
权
和
套
用
激
活
函
数
的
结
果
\begin{cases}输入Input:x1,x2,...,xn(n个特征)\\权值Weights:w1,w2,...,w3\\激活函数f(x)[可想象为皇后对输入信息“添油加醋”]\\输出Output:对加权和套用激活函数的结果\end{cases}
⎩⎪⎪⎪⎨⎪⎪⎪⎧输入Input:x1,x2,...,xn(n个特征)权值Weights:w1,w2,...,w3激活函数f(x)[可想象为皇后对输入信息“添油加醋”]输出Output:对加权和套用激活函数的结果 下面,我们从最简单的神经网络:感知机出发,详细捋一捋神经网络的知识。 如上图,每个神经元都是多输入,单输出的信息处理单元,输入信号通过带权重的连接传递,和阈值对比后得到总输入值,再通过激活函数的处理产生单个输出。 PS.激活函数的意义就是通过进行映射,解决非线性可分问题,激活函数有:
如上图,每个神经元都是多输入,单输出的信息处理单元,输入信号通过带权重的连接传递,和阈值对比后得到总输入值,再通过激活函数的处理产生单个输出。 PS.激活函数的意义就是通过进行映射,解决非线性可分问题,激活函数有:  其中,常用的激活函数为:sigmoid函数、tanH函数和强大的ReLU函数。 此时,从激活函数到输出有: 输入:
w
1
x
1
+
w
2
x
2
+
x
3
x
3
w_1x_1+w_2x_2+x_3x_3
w1x1+w2x2+x3x3 输出:
O
=
f
(
w
1
x
1
+
w
2
x
2
+
x
3
x
3
+
阈
值
)
O=f(w_1x_1+w_2x_2+x_3x_3+阈值)
O=f(w1x1+w2x2+x3x3+阈值) 为了方便计算,我们常将偏置因子b作为
w
0
w_0
w0,引入偏置神经元:
x
0
=
−
1
x_0=-1
x0=−1 将阈值也看做加权和的一部分——
w
0
x
0
w_0x_0
w0x0(+阈值或-阈值),即引入了
x
0
x_0
x0列 x0:取值1或-1 w0:阈值 输出:
f
(
w
0
x
0
+
w
1
x
1
+
w
2
x
2
+
.
.
.
+
w
n
x
n
)
f(w_0x_0+w_1x_1+w_2x_2+...+w_nx_n)
f(w0x0+w1x1+w2x2+...+wnxn) 和我们刚才所说人脑的神经网络系统一样,我们的人工神经网络也是:输入一定,通过调整权重来影响输出。下面,我们看一看感知器的权值更新计算过程。
其中,常用的激活函数为:sigmoid函数、tanH函数和强大的ReLU函数。 此时,从激活函数到输出有: 输入:
w
1
x
1
+
w
2
x
2
+
x
3
x
3
w_1x_1+w_2x_2+x_3x_3
w1x1+w2x2+x3x3 输出:
O
=
f
(
w
1
x
1
+
w
2
x
2
+
x
3
x
3
+
阈
值
)
O=f(w_1x_1+w_2x_2+x_3x_3+阈值)
O=f(w1x1+w2x2+x3x3+阈值) 为了方便计算,我们常将偏置因子b作为
w
0
w_0
w0,引入偏置神经元:
x
0
=
−
1
x_0=-1
x0=−1 将阈值也看做加权和的一部分——
w
0
x
0
w_0x_0
w0x0(+阈值或-阈值),即引入了
x
0
x_0
x0列 x0:取值1或-1 w0:阈值 输出:
f
(
w
0
x
0
+
w
1
x
1
+
w
2
x
2
+
.
.
.
+
w
n
x
n
)
f(w_0x_0+w_1x_1+w_2x_2+...+w_nx_n)
f(w0x0+w1x1+w2x2+...+wnxn) 和我们刚才所说人脑的神经网络系统一样,我们的人工神经网络也是:输入一定,通过调整权重来影响输出。下面,我们看一看感知器的权值更新计算过程。【本文地址】