恒源云GPU云服务操作总结 |
您所在的位置:网站首页 › 恒源云官网价格 › 恒源云GPU云服务操作总结 |
恒源云GPU云服务操作总结
|
前言
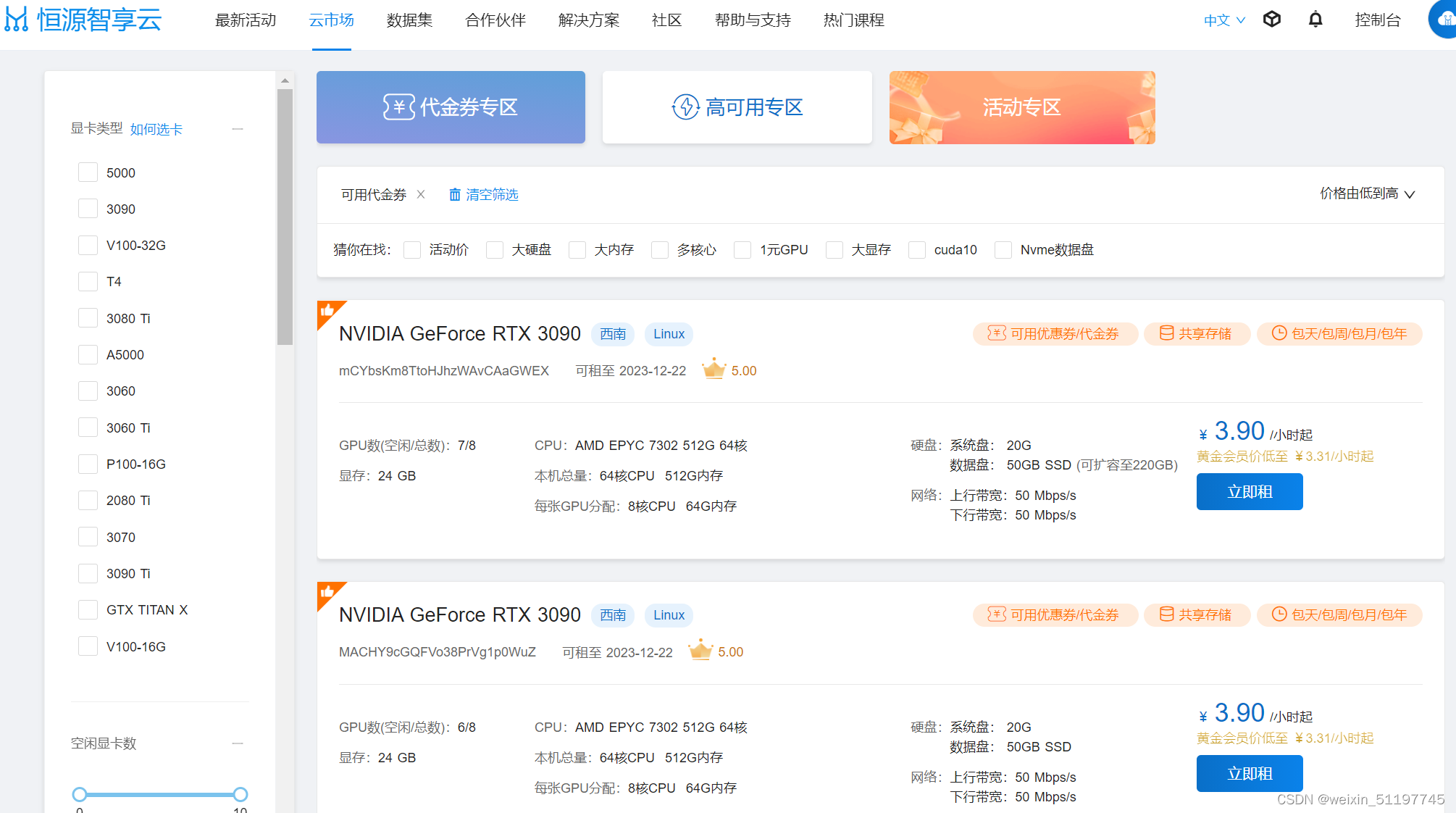
最近忙于实验论文,奈何实验室硬件资源不够,只能混迹于各家的GPU云服务器平台,经过近一段时间以来的摸索,同时根据自己在各家平台的使用体验,向大家分享一下一下恒源云GPU云服务器的的操作总结,方便大家参考。 如下是使用教程: 1、首先进入官网: 恒源云_GPUSHARE-恒源智享云 点击云市场我们可以看到当前提供的的各种显卡类型,可以看到显卡类型包括了NVIDIA的 RTX系列、Tesla系列、GTX系列,还是十分丰富的,而且也提供了低中高三种价位供选择,大家可根据自己的项目需求选择合适的显卡。 1、同时平台提供了100G的免费数据存储,并内置400+的公共数据集,大家可以点击公共数据集,查看是否有自己使用的。 3、平台提供了实例可视化监控功能,大家在使用的时候将代码中的可视化文件保存地址修改到tf_logs文件夹下即可: # 代码示例 save_tf_logs = './model_out/data_log' # 原tf_log文件保存路径 save_tf_logs = '/tf_logs/data_log' # 新的保存路径4、数据集尽量保存在/hy-tmp/...文件夹下,因为该目录为机器本地磁盘,训练速度最快,IO效率最高。但要注意,实例关机后,/hy-tmp/...文件夹下的文件只会保存24小时,大家要注意及时保存。 5、在代码末尾加上os.system("shutdown")可实现程序跑完自动关机。 import os if __name__ == "__main__": main(args) os.system("shutdown") 三、显卡选择在显卡选择上,我们可根据显卡的性能自己的使用需求来抉择。 显卡性能主要根据如下几个参数来判断: 显存: 显存即显卡内存,显存主要用于存放数据模型,决定了我们一次读入显卡进行运算的数据多少(batch size)和我们能够搭建的模型大小(网络层数、单元数),是对深度学习研究人员来说很重要的指标,简述来讲,显存越大越好。 架构: 在显卡流处理器、核心频率等条件相同的情况下,不同款的GPU可能采用不同设计架构,不同的设计架构间的性能差距还是不小的,显卡架构性能排序为:Ampere > Turing > Volta > Pascal > Maxwell > Kepler > Fermi > Tesla CUDA核心数量: CUDA是NVIDIA推出的统一计算架构,NVIDIA几乎每款GPU都有CUDA核心,CUDA核心是每一个GPU始终执行一次值乘法运算,一般来说,同等计算架构下,CUDA核心数越高,计算能力会递增。 Tensor(张量)核心数量: Tensor 核心是专为执行张量或矩阵运算而设计的专用执行单元,而这些运算正是深度学习所采用的核心计算函数,它能够大幅加速处于深度学习神经网络训练和推理运算核心的矩阵计算。Tensor Core使用的计算能力要比Cuda Core高得多,这就是为什么Tensor Core能加速处于深度学习神经网络训练和推理运算核心的矩阵计算,能够在维持超低精度损失的同时大幅加速推理吞吐效率。 半精度: 如果对运算的精度要求不高,那么就可以尝试使用半精度浮点数进行运算。这个时候,Tensor核心就派上了用场。Tensor Core专门执行矩阵数学运算,适用于深度学习和某些类型的HPC。Tensor Core执行融合乘法加法,其中两个44 FP16矩阵相乘,然后将结果添加到44 FP16或FP32矩阵中,最终输出新的4*4 FP16或FP32矩阵。NVIDIA将Tensor Core进行的这种运算称为混合精度数学,因为输入矩阵的精度为半精度,但乘积可以达到完全精度。Tensor Core所做的这种运算在深度学习训练和推理中很常见。 单精度: Float32 是在深度学习中最常用的数值类型,称为单精度浮点数,每一个单精度浮点数占用4Byte的显存。 双精度: 双精度适合要求非常高的专业人士,例如医学图像,CAD。 具体的显卡使用需求,还要根据使用显卡处理的任务内容进行选择合适的卡,除了显卡性能外,还要考虑CPU、内存以及磁盘性能,关于GPU、CPU、内存、磁盘IO性能。 对于不同类型的神经网络,主要参考的指标是不太一样的。下面给出一种指标顺序的参考: 卷积网络和Transformer:Tensor核心数>单精度浮点性能>显存带宽>半精度浮点性能 循环神经网络:显存带宽>半精度浮点性能>Tensor核心数>单精度浮点性能 云市场也给了我们三种选择方法:DJQ专区、高可用专区、活动专区。 活动专区为当前参与活动折扣的机器,与其它同型号GPU并无差异,大家可以经常关注一下。 对于稳定性要求较高的用户可进入高可用专区进行选择。 |
 下面结合我的使用体验进行详细介绍。
下面结合我的使用体验进行详细介绍。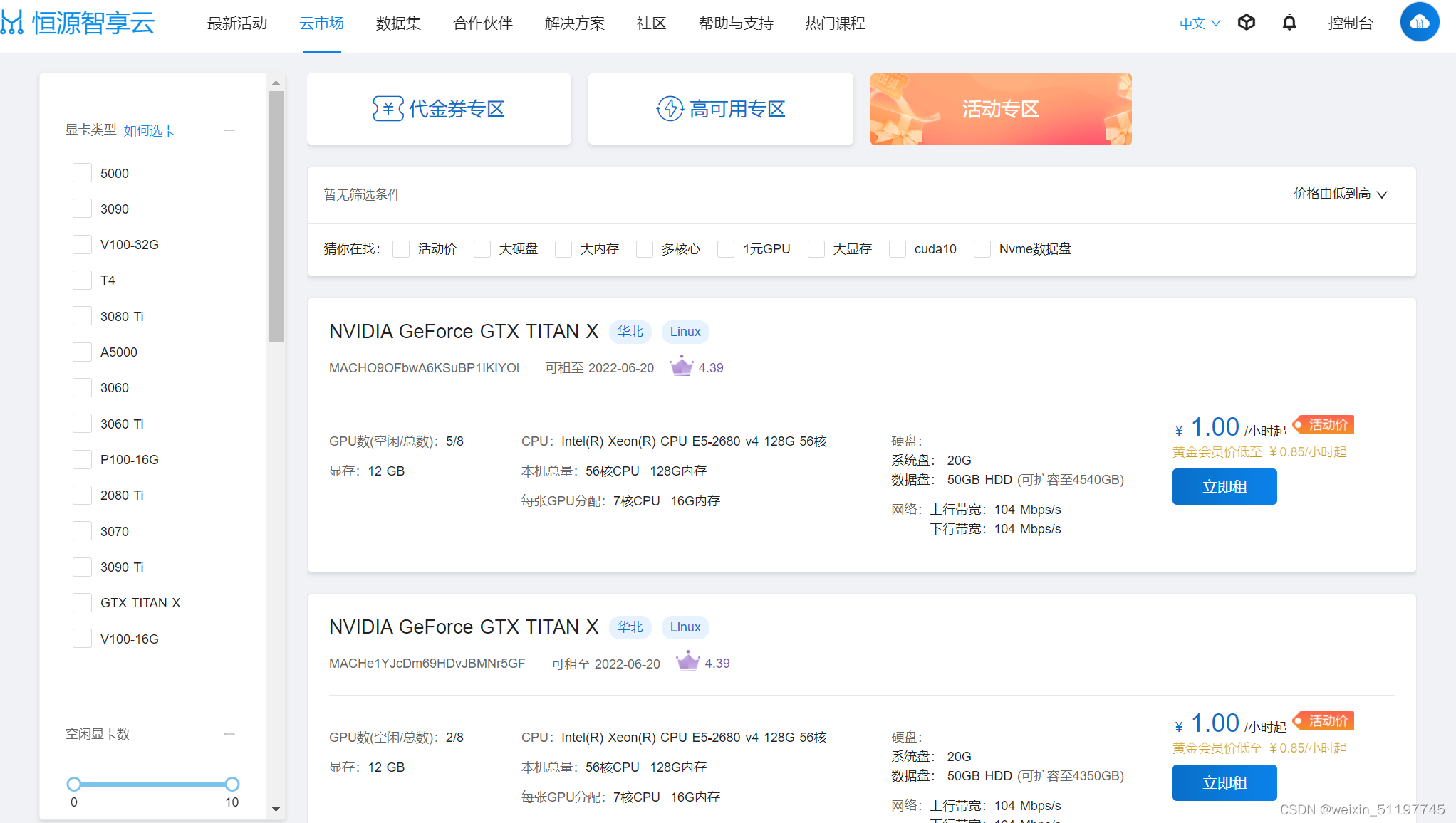
 2、点击立即租,即可进入服务器配置界面,这里以RTX 3090显卡为例,计费模式有按量、包天、包周、包月、包年等多种选择,所以我们选择按量模式;镜像配置大家可按照官方推荐,里面已经为大家预装好了各种常用的深度学习环境,如tensorflow、pytorch等,或者使用自己的备份镜像,或者在镜像市场选择想要的镜像;最后点击创建实例,就创建好了。
2、点击立即租,即可进入服务器配置界面,这里以RTX 3090显卡为例,计费模式有按量、包天、包周、包月、包年等多种选择,所以我们选择按量模式;镜像配置大家可按照官方推荐,里面已经为大家预装好了各种常用的深度学习环境,如tensorflow、pytorch等,或者使用自己的备份镜像,或者在镜像市场选择想要的镜像;最后点击创建实例,就创建好了。 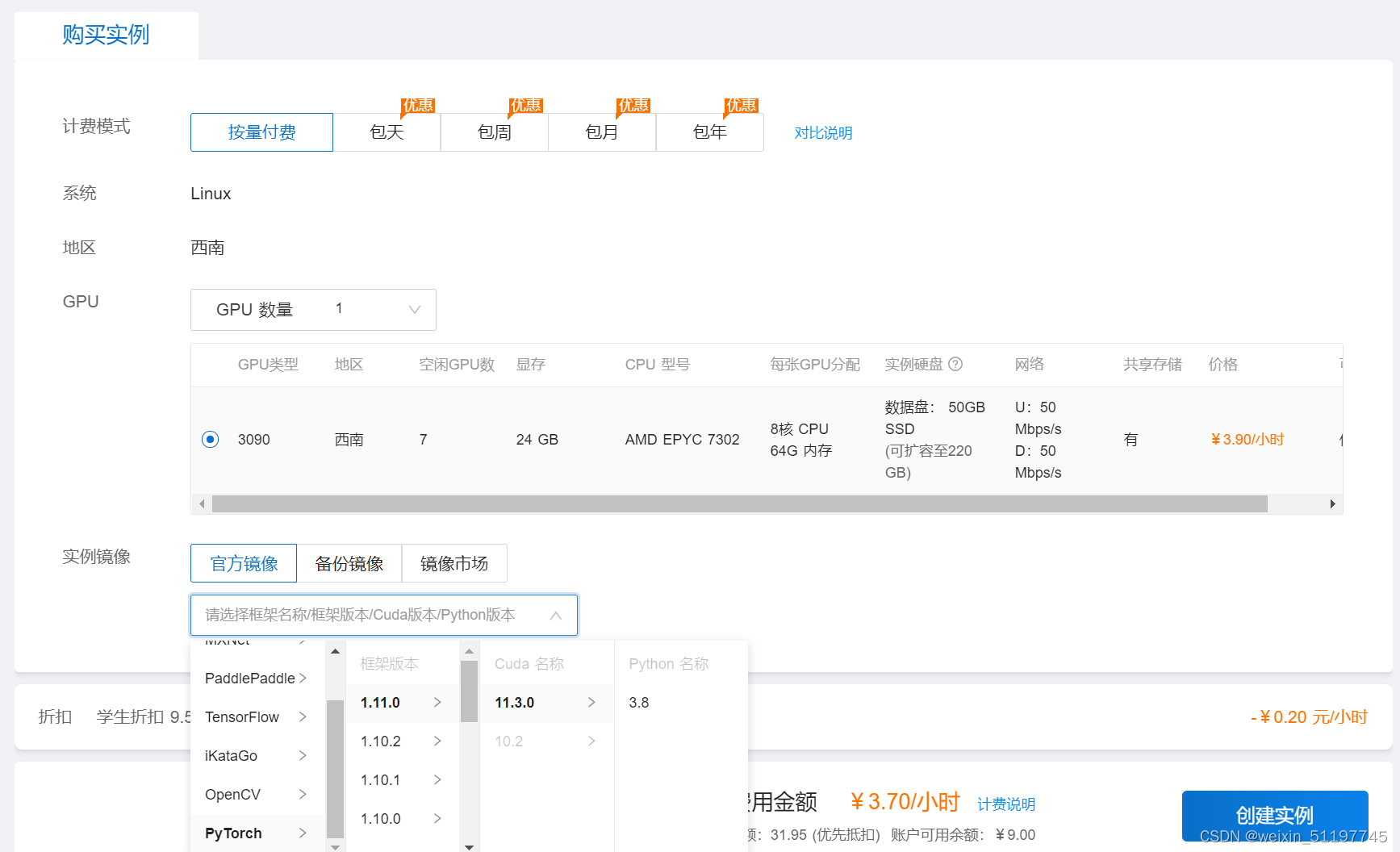 3、点击控制台下的我的实例即可看到创建好的实例,点击实例管理中的启动即可开启实例,然后就可以轻松愉快的使用3090显卡,享受速度带来的乐趣了。
3、点击控制台下的我的实例即可看到创建好的实例,点击实例管理中的启动即可开启实例,然后就可以轻松愉快的使用3090显卡,享受速度带来的乐趣了。 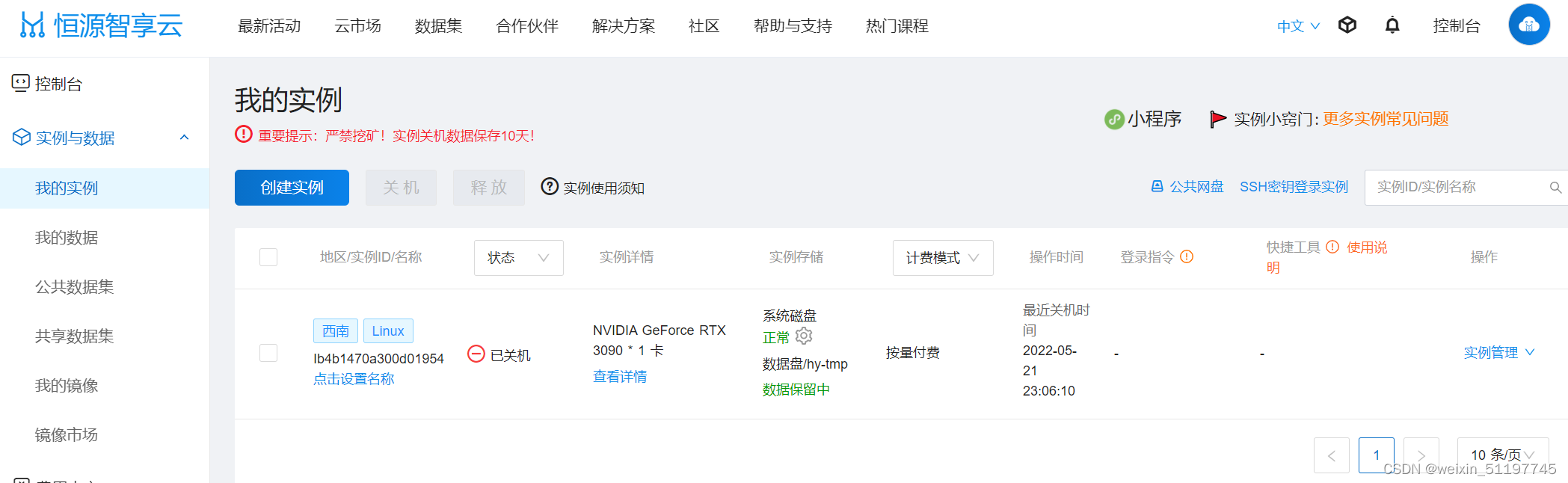 4、启动后,点击JupyterLab即可进入notebook操作界面,大家可以开始自由操作了。
4、启动后,点击JupyterLab即可进入notebook操作界面,大家可以开始自由操作了。 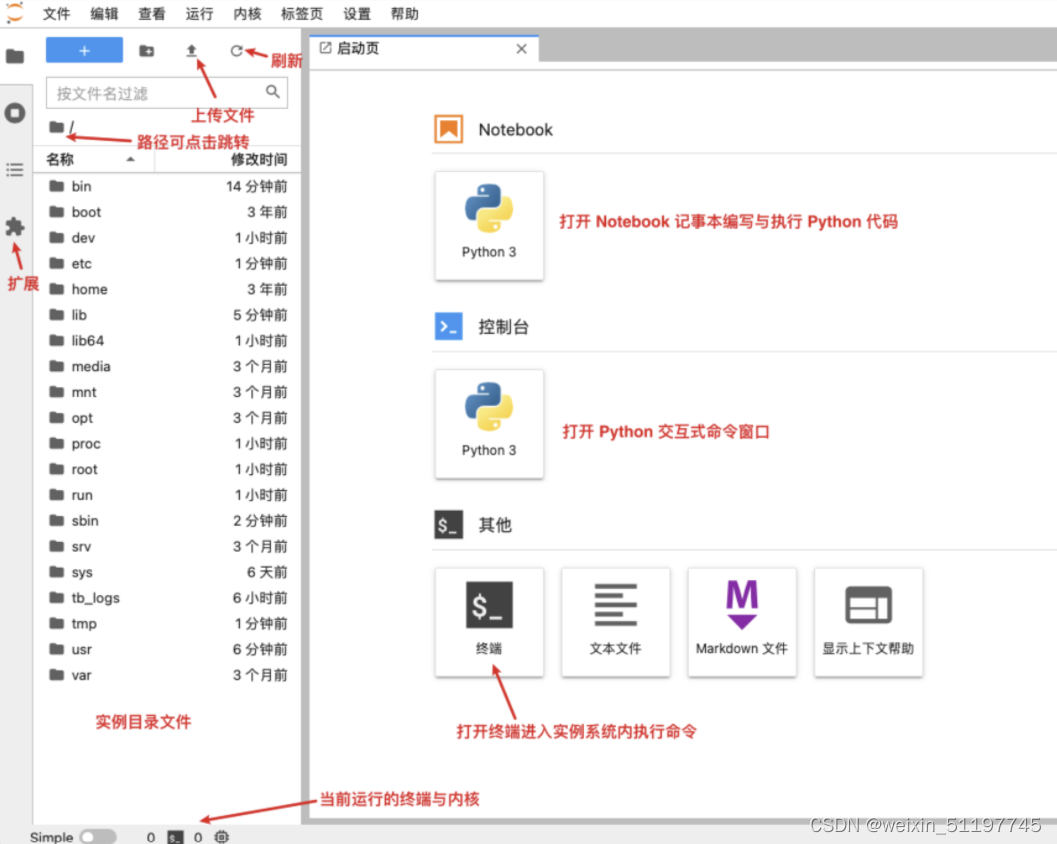
 2、数据的上传可通过平台推荐的oss工具,速度快,可节约大量时间。
2、数据的上传可通过平台推荐的oss工具,速度快,可节约大量时间。 DJQ专区即可使用DJQ的机器,平台会定期推出各项活动(如新人活动、学生认证等),大家可通过完成任务获得。
DJQ专区即可使用DJQ的机器,平台会定期推出各项活动(如新人活动、学生认证等),大家可通过完成任务获得。【本文地址】