风格迁移0 |
您所在的位置:网站首页 › 怎样进行论文解读工作 › 风格迁移0 |
风格迁移0
|
以下链接是个人关于stylegan所有见解,如有错误欢迎大家指出,我会第一时间纠正,如有兴趣可以加微信:17575010159 相互讨论技术。 风格迁移0-00:stylegan-目录-史上最全:https://blog.csdn.net/weixin_43013761/article/details/100895333 前言其实我很纠结,不知道从那个点开始切入讲解。一直犹豫是先讲解代码,还是论文,或者论文结合代码一起讲解。因为在源码的解读过程中,我发现,该代码十分的恶心,其复杂程度比论文还能难理解,是我工作以来遇到过的最复杂的代码。当然,也不可否认代码作者的高超水平,因为功底真的很好,封装实用性都很强,但是对于我们读者却是一件痛苦的事情。最终我还是决定从论文开始吧,然后再论文结合代码讲解,这样应该能让读者更加舒适的理解。那么我们就开始吧(再前面的博客中,我推荐了一篇翻译总结的文章:StyleGAN-基于样式的生成对抗网络(论文阅读总结))。 注意:下面的分析,仅仅是个人理解,仅供参考 \color{#FF0000}{注意:下面的分析,仅仅是个人理解,仅供参考} 注意:下面的分析,仅仅是个人理解,仅供参考 如有错误的地方,希望能够提醒本人,我会在第一时间进行纠正,方便后来人阅读理解,谢谢大家 框架类比下图是论文中,最重要的一副图,可以说全文都是围绕着该图进行讲解。 再之前的传统的生成网络中,有一个问题存在,就是特征纠缠(tanglement翻译过来大概这个意思),那么这个是什么呢?如上图左边,传统的生成网络,我们可以看到,其输入一个latent Z Z Z,一般为512的一个向量。假设这个向量代表一个人的脸,那么该向量就会存在特征纠缠。因为一个脸是有很多特征的,并不是一个512维的向量就能完全表示的,如果非要表示,只能是这种方式,如下: 假设:维度1代表头发粗细,维度2代表皮肤颜色,维度3代表鼻子大小…,当512个维度全部是用完之后,其只能通过多个维度再去表示其他的特征,如:维度1与维度2综合起来表示了头发的颜色。这样,通过两个或者多个组合,512的向量,就能表示出接近无数的特征。 但是这样就很明显出现了一个问题,那就是我们怎么去控制我们想要图片的单个特征呢?如,我只想改变头发的粗细,但是又不能直接去修改第一个维度,因为第一个维度会影响其他的维度,可能会影响到皮肤的颜色,但是有的时候,我偏偏需要该表他头发的颜色,不修改皮肤的颜色。 再这种情况下,传统的生成网络,如LapGAN,PGGAN(也称ProGAN)等等,都不能很好的解决,或者说根本不能解决(本人对之前的网络不是很了解,或许有说得不对的地方,希望大家不要介意,并且指出,我好做修改,方便后来人)。 但是stylegan,就突破了这个局限性。再上图我们可以看到,stylegan网络结构中多出了Mapping network。那么他又什么优势? 我们先看看传统的网络,我们可以的发现,其就像流水线一样,我们没有办法对整个网络进行细微的控制,从网络的输入开始,几乎就与外界隔绝了,所以该网络想生成什么样的图片,几乎就是什么样的图片,我们没有办法对图像形成方向进行定向。 既然传统的不可以,但是我们的stylegan是可以的,图片中的右边部分b,看到laten Z Z Z输入之后,没有直接送入到Synthesis network,而是想通过一个Mapping network(下面就叫mapnet吧),mapnet的结构很简单,都是全连接成,其目的就是解开纠缠(Disentanglement),laten Z Z Z的特征不是纠缠在一起的吗?那么就通过网络去学习,学习怎么去把这些特征分开来,如鼻子就是对应鼻子,不会影响其他的特征。其从laten Z Z Z通过学习,进行空间映射到latent space W。 这样我们就完成了解纠缠,其实,我觉得这里还没有完全的解纠缠,完全的解纠缠应该话要加上途中的A(文中称为反射变换,这里的反射变换是需要机器自己去学习的,并不是opencv中的反射变化),为什么我会这样说呢? latent space W 到 affine transform A通过前面的理解,我们知道通过mapnet网络实现了解纠缠,但是这里大家肯定发现了问题,那就是特征向量能表示的特征减少了,因为他们没有纠缠在一起了,虽然现在不会相互影响。在这里,我感觉作者是用过图中的反射变化A解决的。在不同的分辨率中都加入了反射变化A。 说到这里的分辨率,大家或许有一些疑惑,为什么我们在制作训练数据的时候,需要有那么多的分辨率。主要是stylegan延续了之前一些生成网络gan的思想。可以这样的理解,我们假设去画一个人,我们做开始的时候可能会先画他的轮廓,轮廓出来之后,在把鼻子眼镜画好,然后再会皱纹到,最后再给皮肤上色。机器也是这个样子的,再训练的时候,我们先用低分辨率(4x4,16x16,32x32)的图像,告诉他怎么去画轮廓,或者总体的布局。再让他知道怎么去画鼻子,眼镜(64x64,128x128,256x256)最后就是皮肤发丝的风格了(512x512,1024x1024)。 那么他的原理是什么呢?其实也比较简单,比如一副图像假设原来分辨很大的时候,你是能清晰的看到他皮肤的细腻程度,但是如果经过多次下采样之后,我们就看不清楚了,只能模模糊糊的知道这是一个人,甚至可能男人女人都分辨不出来了,再经过下采样,可能就是一坨莫名奇妙的颜色。如下面就是网络学习的一个过程: 多张图片,每张都是8x8的分辨率, 这样大家了解到了整个网络学习过程的大致过程。回到原来的地方,这里和之前反射变换A有什么关系呢?图中我们可以看到每个分辨率都会对应两个经过,反射变化的A。也就是说针对低分辨率,轮廓控制的特征向量并不是W,而是W还要再次经过变化。再实际的网络中有18个反射变化,这也就是说,并不是1个512维的W去控制网络图片的生成,而是W经过反射变换后,有18个512维的向量去控制。这样就实现了完全的解纠缠。 并且,再这里,我们还能通过控制反射变化A去控制图片的生成过程,如图片融合等等,这个再后续为大家详细的讲解。 AdaIN通过前面的讲解,相信大家对于stylegan已经有了大致的一个了解,那么下面讲解一下主干网络,即Synthesis network(后面就叫synnet,本人有点懒)。这个网络,就是我们图片的生成网络,其结构如下: G_synthesis/4x4/Const 534528 (?, 512, 4, 4) (512,) G_synthesis/4x4/Conv 2885632 (?, 512, 4, 4) (3, 3, 512, 512) G_synthesis/ToRGB_lod8 1539 (?, 3, 4, 4) (1, 1, 512, 3) G_synthesis/8x8/Conv0_up 2885632 (?, 512, 8, 8) (3, 3, 512, 512) G_synthesis/8x8/Conv1 2885632 (?, 512, 8, 8) (3, 3, 512, 512) G_synthesis/ToRGB_lod7 1539 (?, 3, 8, 8) (1, 1, 512, 3) G_synthesis/Upscale2D - (?, 3, 8, 8) - G_synthesis/Grow_lod7 - (?, 3, 8, 8) - G_synthesis/16x16/Conv0_up 2885632 (?, 512, 16, 16) (3, 3, 512, 512) G_synthesis/16x16/Conv1 2885632 (?, 512, 16, 16) (3, 3, 512, 512) G_synthesis/ToRGB_lod6 1539 (?, 3, 16, 16) (1, 1, 512, 3) G_synthesis/Upscale2D_1 - (?, 3, 16, 16) - G_synthesis/Grow_lod6 - (?, 3, 16, 16) - G_synthesis/32x32/Conv0_up 2885632 (?, 512, 32, 32) (3, 3, 512, 512) G_synthesis/32x32/Conv1 2885632 (?, 512, 32, 32) (3, 3, 512, 512) G_synthesis/ToRGB_lod5 1539 (?, 3, 32, 32) (1, 1, 512, 3) G_synthesis/Upscale2D_2 - (?, 3, 32, 32) - G_synthesis/Grow_lod5 - (?, 3, 32, 32) - G_synthesis/64x64/Conv0_up 1442816 (?, 256, 64, 64) (3, 3, 512, 256) G_synthesis/64x64/Conv1 852992 (?, 256, 64, 64) (3, 3, 256, 256) G_synthesis/ToRGB_lod4 771 (?, 3, 64, 64) (1, 1, 256, 3) G_synthesis/Upscale2D_3 - (?, 3, 64, 64) - G_synthesis/Grow_lod4 - (?, 3, 64, 64) - G_synthesis/128x128/Conv0_up 426496 (?, 128, 128, 128) (3, 3, 256, 128) G_synthesis/128x128/Conv1 279040 (?, 128, 128, 128) (3, 3, 128, 128) G_synthesis/ToRGB_lod3 387 (?, 3, 128, 128) (1, 1, 128, 3) G_synthesis/Upscale2D_4 - (?, 3, 128, 128) - G_synthesis/Grow_lod3 - (?, 3, 128, 128) - G_synthesis/256x256/Conv0_up 139520 (?, 64, 256, 256) (3, 3, 128, 64) G_synthesis/256x256/Conv1 102656 (?, 64, 256, 256) (3, 3, 64, 64) G_synthesis/ToRGB_lod2 195 (?, 3, 256, 256) (1, 1, 64, 3) G_synthesis/Upscale2D_5 - (?, 3, 256, 256) - G_synthesis/Grow_lod2 - (?, 3, 256, 256) - G_synthesis/512x512/Conv0_up 51328 (?, 32, 512, 512) (3, 3, 64, 32) G_synthesis/512x512/Conv1 42112 (?, 32, 512, 512) (3, 3, 32, 32) G_synthesis/ToRGB_lod1 99 (?, 3, 512, 512) (1, 1, 32, 3) G_synthesis/Upscale2D_6 - (?, 3, 512, 512) - G_synthesis/Grow_lod1 - (?, 3, 512, 512) - G_synthesis/1024x1024/Conv0_up 21056 (?, 16, 1024, 1024) (3, 3, 32, 16) G_synthesis/1024x1024/Conv1 18752 (?, 16, 1024, 1024) (3, 3, 16, 16) G_synthesis/ToRGB_lod0 51 (?, 3, 1024, 1024) (1, 1, 16, 3) G_synthesis/Upscale2D_7 - (?, 3, 1024, 1024) - G_synthesis/Grow_lod0 - (?, 3, 1024, 1024) - G_synthesis/images_out - (?, 3, 1024, 1024) -结合前面的网络图,我们可以知道,网络的开始,是一个 G_synthesis/4x4/Const (?, 512, 4, 4) 的向量,经过第一次卷积,依旧为(?, 512, 4, 4),但是之后会通过一个(1, 1, 512, 3)的卷积核,变成一张(?, 3, 4, 4)的RGB图像,重上面我们可以看到: G_synthesis/ToRGB_lod8 G_synthesis/ToRGB_lod7 G_synthesis/ToRGB_lod6 G_synthesis/ToRGB_lod5 G_synthesis/ToRGB_lod4 G_synthesis/ToRGB_lod3 G_synthesis/ToRGB_lod2 G_synthesis/ToRGB_lod1 G_synthesis/ToRGB_lod0其都是转化为RGB图像进行输出,大家可能会比较奇怪,为什么要做这个操作,在前面我们制作训练数据的时候可以知道,我们把图片制作成了多个分辨率得数据。其目的,就是与这里生成的图像计算损失。(该处是本人猜测,因为还没有详细的分析源码,不过没有关系,在后续的章节会为大家详细讲解)。其分辨率的增加,主要是通过图片的上采样。 下面我们就来看看AdaIN: 在这里,可能还有一个奇怪的问题: 总的来说反射变换之后的A,会只图像的风格直接产生影响,这里使用两个反射变化A以及两个AdaIN,是为了对图片产生的过程中进行控制。如果只有一个,能把两张图片的特征进行融合。 噪声对于噪声,我就不做详细的讲解了,大家直接看论文或者其他的博客都能找到很好的答案: 本片文章,到2019/09/18为止,只讲解了大致的部分,后续我在源码的阅读过程中,会为这篇文章增加更多的细节,方便后来人了解。下小节我们将对源码进行解剖。 不过比较抱歉的是,我不知道什么时候会进行书写,因为最近要做一个行人重识别的项目,可能没有多余的时间去对源码进行解析了,希望大家多等等。下面是行人行人重识别的链接(绝对的精彩,让你意想不到): 行人重识别0-00:DG-Net(ReID)-目录-史上最新无死角讲解:https://blog.csdn.net/weixin_43013761/article/details/102364512 |
 首先说说stylegan出现的历史原因,一篇好的论文出现,一般有两种形式,创新(大格局)和优化。其创新是前人没有想到的方法,后人通过灵感,创建出了新的架构或者方法,优化就是再前人已经有的基础上,进行创新或者提升。其stylegan属于后者。那么他再那些方面有了创新了?
首先说说stylegan出现的历史原因,一篇好的论文出现,一般有两种形式,创新(大格局)和优化。其创新是前人没有想到的方法,后人通过灵感,创建出了新的架构或者方法,优化就是再前人已经有的基础上,进行创新或者提升。其stylegan属于后者。那么他再那些方面有了创新了? 16x16
16x16  32x32
32x32  后面的分辨率我就不贴出来了,没有多大的意义。 注意,网络的输出都是1024的,其就是把1024按比例进行分配,或者填充,变成虚假的8x8,32x32等等。
后面的分辨率我就不贴出来了,没有多大的意义。 注意,网络的输出都是1024的,其就是把1024按比例进行分配,或者填充,变成虚假的8x8,32x32等等。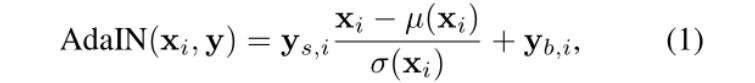 其中的
y
s
,
i
y_s,_i
ys,i与
y
b
,
i
y_b,_i
yb,i来自于A的反射变换:
其中的
y
s
,
i
y_s,_i
ys,i与
y
b
,
i
y_b,_i
yb,i来自于A的反射变换:  为什么通过反射变换会得到
y
s
,
i
y_s,_i
ys,i与
y
b
,
i
y_b,_i
yb,i,本人也比较奇怪,不过不用着急,后续在源码中应该能够找到答案的。
为什么通过反射变换会得到
y
s
,
i
y_s,_i
ys,i与
y
b
,
i
y_b,_i
yb,i,本人也比较奇怪,不过不用着急,后续在源码中应该能够找到答案的。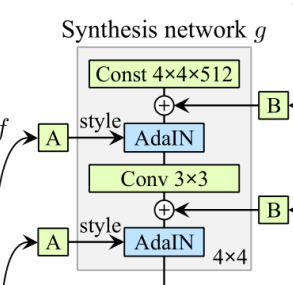
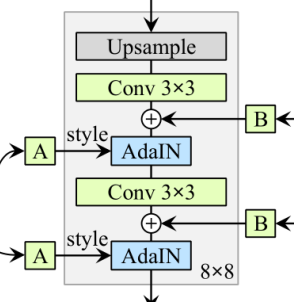 那就是为什么这里的每个分辨率中,都对应着两个反射变化A以及两个AdaIN。难道一个不行吗?下面是一个总体的框图:
那就是为什么这里的每个分辨率中,都对应着两个反射变化A以及两个AdaIN。难道一个不行吗?下面是一个总体的框图:  我们可以看到,生成网络会生成多个尺寸的图片,原图像进行下多次下采样,与生成的图片计算损失。我们可以注意大,参与网络的是两张图片,那么他有什么作用。我们知道stylegan是可以进行图片融合的,那么如下:
我们可以看到,生成网络会生成多个尺寸的图片,原图像进行下多次下采样,与生成的图片计算损失。我们可以注意大,参与网络的是两张图片,那么他有什么作用。我们知道stylegan是可以进行图片融合的,那么如下:  那么,我们既然要融合,起码需要两张图片把。前面提到过,不同分辨率对应的不同的反射变换A,图片生成的风格直接搜反射变化之后的A影响。其中18个反射变化的A或许并不是都来自于同一个latent space W,可能来自于两个W。但是这里只是猜测,没证明,需要后续到源码中去寻找具体的答案。
那么,我们既然要融合,起码需要两张图片把。前面提到过,不同分辨率对应的不同的反射变换A,图片生成的风格直接搜反射变化之后的A影响。其中18个反射变化的A或许并不是都来自于同一个latent space W,可能来自于两个W。但是这里只是猜测,没证明,需要后续到源码中去寻找具体的答案。 可以知道其与反射变换A十分的相似,其也需要进行反向传播学习,即为图中的B。其是一个随机的过程,就是因为有噪声的存在,让图片更加的逼真。下面就是添加了噪声和没有添加噪声的对比:
可以知道其与反射变换A十分的相似,其也需要进行反向传播学习,即为图中的B。其是一个随机的过程,就是因为有噪声的存在,让图片更加的逼真。下面就是添加了噪声和没有添加噪声的对比: 
【本文地址】