【架构】软件代码的耦合性和内聚性,以几个简单小例子说明 |
您所在的位置:网站首页 › 怎样把音频剪成几段播放 › 【架构】软件代码的耦合性和内聚性,以几个简单小例子说明 |
【架构】软件代码的耦合性和内聚性,以几个简单小例子说明
|
1. 起因
这篇文章应该算作前两篇文章的后续思考。 在前两篇文章中,考虑到了分层的方法,参考了别人的代码架构。 【架构】工程代码结构(附带NXP、ST官方demo)【架构】嵌入式软件架构设计 模块化 & 分层设计其实我们说到最后,好的代码,我们分层,做模块,无非就是实现一个高内聚和低耦合。 举个简单的例子,将某个模块代码直接删除之后,将上层调用处注释,重新编译,是否还能编过?(不考虑功能的运行) 如果还能,说明这个模块和同层的其他模块没有耦合性,即同级的模块不依赖这个模块的实现,不依赖这个模块的结构体,这个模块就有高内聚和低耦合。 内聚,耦合。 这两个词说了很多遍,究竟具体在说什么? 2. 内聚(Cohesion)什么是内聚性。 内聚性由由Larry_Constantine提出,WIKI 是这么介绍的: 内聚性(Cohesion)也称为内聚力,是一软件度量,是指机能相关的程序组合成一模块的程度[1],或是各机能凝聚的状态或程度[2]。是结构化分析的重要概念之一。量测内聚性的方式很多,有些方法是由分析源代码,得到非量化的结果,有些方法则是检查源代码的文本特征,以得到内聚性的量化分数。内聚性是属于顺序式的量测量,一般会以“高内聚性”或“低内聚性”来表示。一般会希望程序的模块有高内聚性,因为高内聚性一般和许多理想的软件特性有关,包括鲁棒性、可靠度、可复用性及易懂性(understandability)等特性,而低内聚性一般也代表不易维护、不易测试、不易复用以及难以理解。 耦合性是一个和内聚性相对的概念。一般而言高内聚性代表低耦合性,反之亦然。内聚性是由赖瑞·康斯坦丁所提出,是以实务上可减少维护及修改的“好”软件的特性为基础[3]。 2.1 分类 偶然内聚性(Coincidental cohesion,最低) 偶然内聚性是指模块中的机能只是刚好放在一起,模块中各机能之间唯一的关系是其位在同一个模块中(例如:“工具”模块)。逻辑内聚性(Logical cohesion) 逻辑内聚性是只要机能只要在逻辑上分为同一类,不论各机能的本质是否有很大差异,就将这些机能放在同一模块中(例如将所有的鼠标和键盘都放在输入处理副程序中)。模块内执行几个逻辑上相似的功能,通过参数确定该模块完成哪一个功能。时间性内聚性(Temporal cohesion) 时间性内聚性是指将相近时间点运行的程序,放在同一个模块中(例如在捕捉到一个异常后调用一函数,在函数中关闭已打开的文件、产生错误日志、并告知用户)。程序内聚性(Procedural cohesion) 程序内聚性是指依一组会依照固定顺序运行的程序放在同一个模块中(例如一个函数检查文件的权限,之后打开文件)。联系内聚性/信息内聚/通信内聚(Communicational cohesion) 联系内聚性是指模块中的机能因为处理相同的数据或者指各处理使用相同的输入数据或者产生相同的输出数据,因此放在同一个模块中(例如一个模块中的许多机能都访问同一个记录)。依序内聚性/顺序内聚(Sequential cohesion) 依序内聚性是指模块中的各机能彼此的输入及输出数据相关,一模块的输出数据是另一个模块的输入,类似工厂的生产线(例如一个模块先读取文件中的数据,之后再处理数据)。功能内聚性(Functional cohesion,最高) 功能内聚性是指模块中的各机能是因为它们都对模块中单一明确定义的任务有贡献(例如XML字符串的词法分析)。 3. 耦合(coupling)什么是耦合性。 耦合性由由Larry_Constantine提出,WIKI 是这么介绍的: 耦合性(英语:Coupling,dependency,或称耦合力或耦合度)是一种软件度量,是指一程序中,模块及模块之间信息或参数依赖的程度。 内聚性是一个和耦合性相对的概念,一般而言低耦合性代表高内聚性,反之亦然。耦合性和内聚性都是由提出结构化设计概念的赖瑞·康斯坦丁所提出[1]。低耦合性是结构良好程序的特性,低耦合性程序的可读性及可维护性会比较好。 3.1 耦合类型耦合主要分为以下几类,耦合度从低到高,分别是: 非直接耦合 < 数据耦合 < 标记耦合 < 控制耦合 < 外部耦合 < 公共耦合 < 内容耦合 非直接耦合(Nondirect coupling) A/B两个模块之间没有任何关系,不会调用对方的API,不依赖对方的结构体、宏……不用包含头文件,删除一个模块对另一个模块没有任何影响,它们之间的联系完全是通过主模块的控制和调用来实现的,这种耦合关系称之为 非直接耦合。 例子: //A模块 int Add(int num1,int num2) { return (num1+num2); } //B模块 typedef struct _SUB_PARA_ { int num1; int num2; }SubPara; int Sub(SubPara* pNum) { return (pNum->num1-pNum->num2); } 数据耦合(Data Coupling) 数据耦合指的是,两个模块调用时,传递的是简单的数据值,不是数据结构或者其他复杂变量。 如果一个模块访问另一个模块时,彼此之间是通过数据参数(不是控制参数、公共数据结构或外部变量)来交换输入、输出信息的,则称这种耦合为数据耦合。。在软件程序结构中至少必须有这类耦合。 在上例子中,A/B之间没有相互的依赖,但是可能A、B的API都会被C模块调用,(个人意见:我们应该把C模块划分到高一层去)。 C调用A,用的是参数传入,传递的都是int型的入参,即为C和A为数据耦合。 例子: //C模块 int Sum(int num1 , int num2 ,int num3,int 4) { int res1 = Add(num1,num2); int res2 = Add(num3,num4); return Add(res1,res2); } 标记耦合(Stamp Coupling) 如果在调用过程中,传递的不是普通参数,而是一个结构体,这个结构体是属于某个模块的,而不是简单变量。 如果一组模块通过参数表传递记录信息,就是标记耦合。事实上,这组模块共享了这个记录,它是某一数据结构的子结构,而不是简单变量。这要求这些模块都必须清楚该记录的结构,并按结构要求对此记录进行操作。在设计中应尽量避免这种耦合,它使在数据结构上的操作复杂化了。 原则上,应该尽量把使用同一结构体的操作尽量集中在一个模块中,消除这种耦合。 还是这个例子。 C调用B,用的是结构体传入,即为标记耦合 //C模块第二部分 int Sub2(int num1, int num2) { SubPara Temp; Temp.num1 = num1; Temp.num2 = num2; return Sub(&Temp); }控制耦合 如果一个模块通过传送开关、标志、名字等控制信息,明显地控制选择另一模块的功能,就是控制耦合。 偷一张别人的图,看的很明白: 外部耦合(External Coupling) 一组模块都访问同一全局简单变量而不是同一全局数据结构,而且不是通过参数表传递该全局变量的信息,则称之为外部耦合。 举个例子,DE模块都直访问了一个全局变量,而不是通过入参传入。 //D模块 int g_Para = 1; int Func1() { return (g_Para+1); } //E模块 extern int g_Para; int Func2() { return (g_Para+2); }公共耦合 若一组模块都访问同一个公共数据环境,则他们之间的耦合就称为公共耦合。公共的数据环境可以是全局数据结构、共享的通信区、内存的公共覆盖区等。 类似外部耦合,只不过依赖不再是简单变量。 内容耦合 又称病态耦合。如果发生下列情形,两个模块之间就发生了内容耦合。 一个模块直接访问另一个模块的内部数据;一个模块不通过正常入口转到另一模块内部;两个模块有一部分程序代码重叠(只可能出现在汇编语言中);一个模块有多个入口。在内容耦合的情形,所访问模块的任何变更,或者用不同的编译器对它再编译,都会造成程序出错。好在大多数高级程序设计语言已经设计成不允许出现内容耦合。它一般出现在汇编语言程序中。这种耦合是模块独立性最弱的耦合。 3.2 如何解耦依赖注入、命名查找 4. 总结我的观点是: 高内聚,低耦合肯定是我们的追求,但并不是内聚越高,耦合越低就一定好,并非要是使用很多兜圈子的代码来降低耦合,我们应该允许单向调用。 项目设计应该先做分层设计。同层级的模块间,尽量保持相互独立,不相互调用。如果无法避免,尽量把被高度依赖的部分封装到同一个模块中,这个模块作为必选功能模块,不可移除上层可以调用下层模块的API和结构体。调用多使用传参,传参多用普通类型每个模块维护自己的内部变量和状态,如果变量少就用基本数据类型,多就用结构体,与外界任何交互都有标准的输入输出接口。 5.参考链接 耦合的本质 - 翟志军耦合-例子《浮现式设计》 |
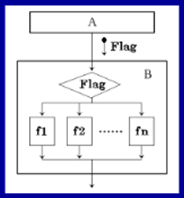 不论这个Flag是怎么传过来的,在功能逻辑上,B模块是依赖于A模块的。
不论这个Flag是怎么传过来的,在功能逻辑上,B模块是依赖于A模块的。【本文地址】
今日新闻 |
推荐新闻 |