机器学习 |
您所在的位置:网站首页 › 怎么评价书法字的好坏视频 › 机器学习 |
机器学习
|
文章目录
EvaluationLikelihoodLikelihoodKernel Density EstimationLikelihood v.s. Quality
Objective EvaluationObjective EvaluationInception Score
We don’t want memory GAN.其他补充内容Mode DroppingMini-batch Discrimination
Concluding Remarks from A to Z(GAN大集合)
Evaluation
本文是GAN的最后一块内容,就是如何Evaluation一个GAN模型。 说人话:如何评价GAN生成的图片好还不好。 另外一个方面是:是否客观,因为虽然人评价结果比较准确,但是人容易受主观影响,尤其发在论文上的图片,作者肯定不会把很烂的结果摆出来。 Ref: 👉 Lucas Theis, Aäron van den Oord, Matthias Bethge, “A note on the evaluation of generative models”, arXiv preprint, 2015 Likelihood Likelihood相关的内容也可以参考这里 👉 机器学习-35-Theory behind GAN(GAN背后的数学理论) 传统方法就是衡量Generator生成数据的Likelihood.假如我们已经训练好一个Generator: P G P_G PG,然后我们拿几个真实的数据 x i x^i xi (这里是图片,当然是不在训练集的),然后计算生 P G P_G PG成这几个真实数据的概率(这个概率就是Likelihood)。 蓝色星星:real data (not observed during training). 黄色星星:generated data. 
Log Likelihood的计算公式为: L = 1 N ∑ i l o g P G ( x i ) L = \frac{1}{N}\sum_ilogP_G(x^i) L=N1i∑logPG(xi) 如果 P G P_G PG 生成这几个真实数据的概率较大,我们就认为这个Generator还不错。 但是问题在于: P G P_G PG生成这几个真实数据 x i x^i xi 的概率 P G ( x i ) P_G(x^i) PG(xi) 是没有办法计算的。因为: P G P_G PG 是根据一个先验分布来生成数据(橙色星星),但是没有办法指定生成某一个 P G P_G PG特定的图片。通俗的来讲,通过一个NN来生成数据,都是没有办法算Likelihood,这里不知道因为是从先验分布中sample的原因还是NN的原因。 如果 P G P_G PG 是GMM(Gaussian Mixture Model)之类的,给定x,是可以计算概率 P G ( x i ) P_G(x^i) PG(xi) 的,但是GMM太简单了,我们希望Generator是比较复杂的NN。 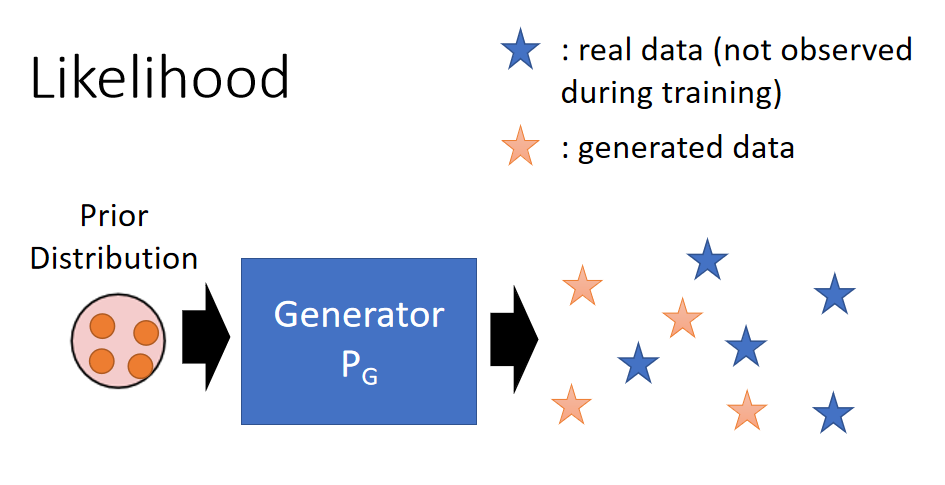 Kernel Density Estimation
Kernel Density Estimation
既然直接算 P G P_G PG 生成这几个真实数据 x i x^i xi 的概率不好计算,那我们就像办法进行估计。步骤如下: 先让生成 P G P_G PG一大把的图片,然后用一大把有相同covariance的高斯分布来拟合那一大把图片。 再说一遍,先让 P G P_G PG生成一大把的图片,每一个图片就是一个High-dimensional的向量,对于每一个向量都相当于一个高斯分布的mean,这些高斯分布的covariance都一样,注意观察下面的图:星星在红色圈圈中间,红色圈圈都是一样大。然后把这些红色圈圈用GMM的思想合起来。 刚才说了GMM是算Likelihood概率的,现在有一个GMM可以拟合Generator,问题就解决了。 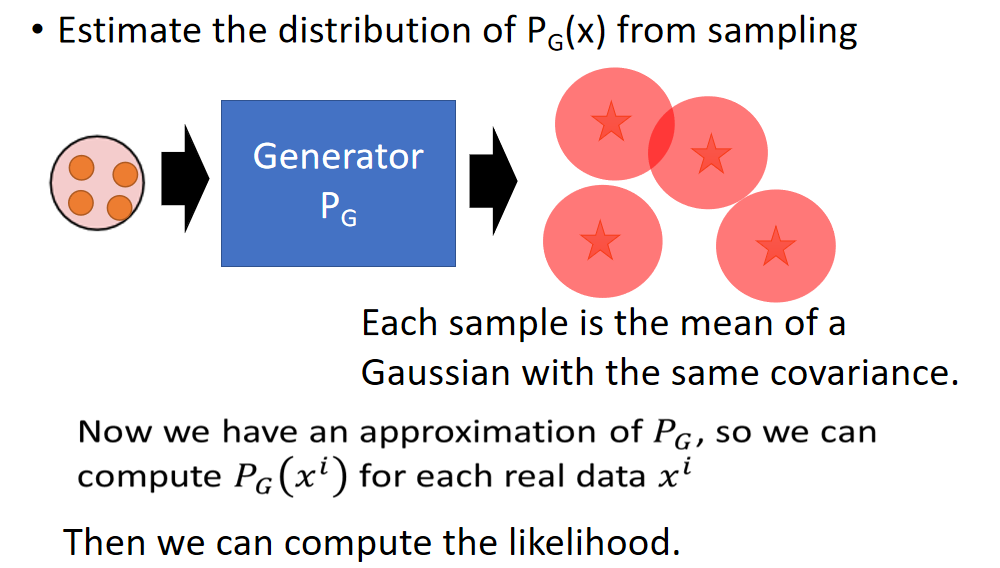
这个方法有很多问题: 要生成多少个图片才能保证GMM拟合的结果比较精确; 高斯分布做拟合的时候上面是1个图片拟合一个,是不是可以几个图片拟合一个高斯分布? 有论文进行研究,结果并不理想。 除了这两个问题之外,还有一个根本问题就是我们费尽心思算的Likelihood并不能表示质量好坏: Likelihood v.s. Quality
Low likelihood, high quality? Considering a model generating good images (small variance) 上图中有一个Generator: P G P_G PG ,生成的图片质量非常棒,但是它只能生成【凉宫春日】的高清图片,但是我们用来评估的图片(testing set)都是其他人物的头像: 右边的其他人物头像的Likelihood P G ( x i ) P_G(x^i) PG(xi) 算出来是0。 这明显不合理呀,也就是likelihood很低,并不代表生成数据质量不好。 High likelihood, low quality? 假设我们有一个很强的Generator:G1,它生成图片的likelihood很高,计算公式: L = 1 N ∑ i l o g P G ( x i ) L = \frac{1}{N}\sum_ilogP_G(x^i) L=N1i∑logPG(xi) 还有一个很烂的Generator:G2,它有99%的几率会生成random noise,只有1%的几率和G1一样生成likelihood很高的图片。那么它生成图片的likelihood的公式为: L = 1 N ∑ i l o g P G ( x i ) 100 = − l o g 100 + 1 N ∑ i l o g P G ( x i ) = 4.6 + 1 N ∑ i l o g P G ( x i ) L = \frac{1}{N}\sum_i\frac{logP_G(x^i)}{100} = -log100+\frac{1}{N}\sum_ilogP_G(x^i) = 4.6+\frac{1}{N}\sum_ilogP_G(x^i) L=N1i∑100logPG(xi)=−log100+N1i∑logPG(xi)=4.6+N1i∑logPG(xi) 我们发现G1和G2的两个Generator的likelihood其实差别没有很大,但是我们知道G1要比G2好100倍才对。因此likelihood并不能代表很好的quality。 Objective Evaluation Objective Evaluation比较客观的做法就是训练一个图片分类器来评估生成图片的好坏。 [Tim Salimans, et al., NIPS, 2016] 假设: 𝑥: image(Generator产生的图片)𝑦: class (output of CNN)从衡量图片质量的角度来看: 
如果很容易分辨出图片属于某个类别,就说明质量还不错,除了这个角度外,还需要从另外一个角度来看,就是多样性上考虑,上面也有例子,就是Generator生成单个类别质量好的图片还不够,还要能生成各种类别的图片最好。 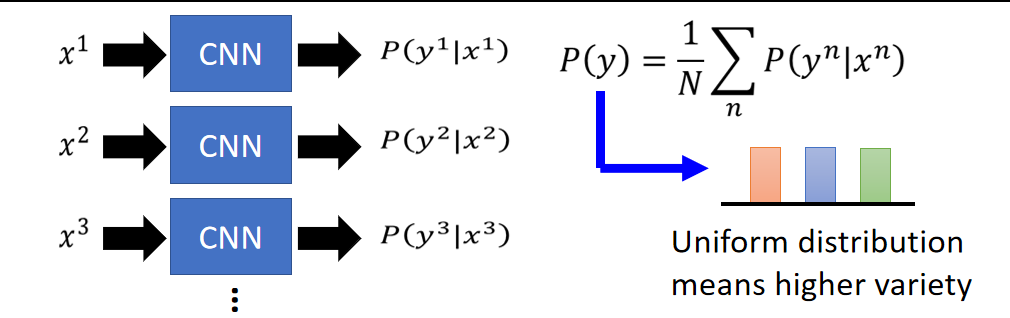
例如上图中有三张图片,把它们分别丢到CNN中,产生三个Distribution,然后把这三个分布进行平均,看得到的结果是否是均匀分布的(右图所示)。 如果是均匀分布,表示Generator生成三个类别的概率差不多; 如果某个类别比例高,表示Generator生成该类别的概率较高,多样性较差。 有了这两个标准,那么我们就可以设定评价分数了:Inception Score Inception Score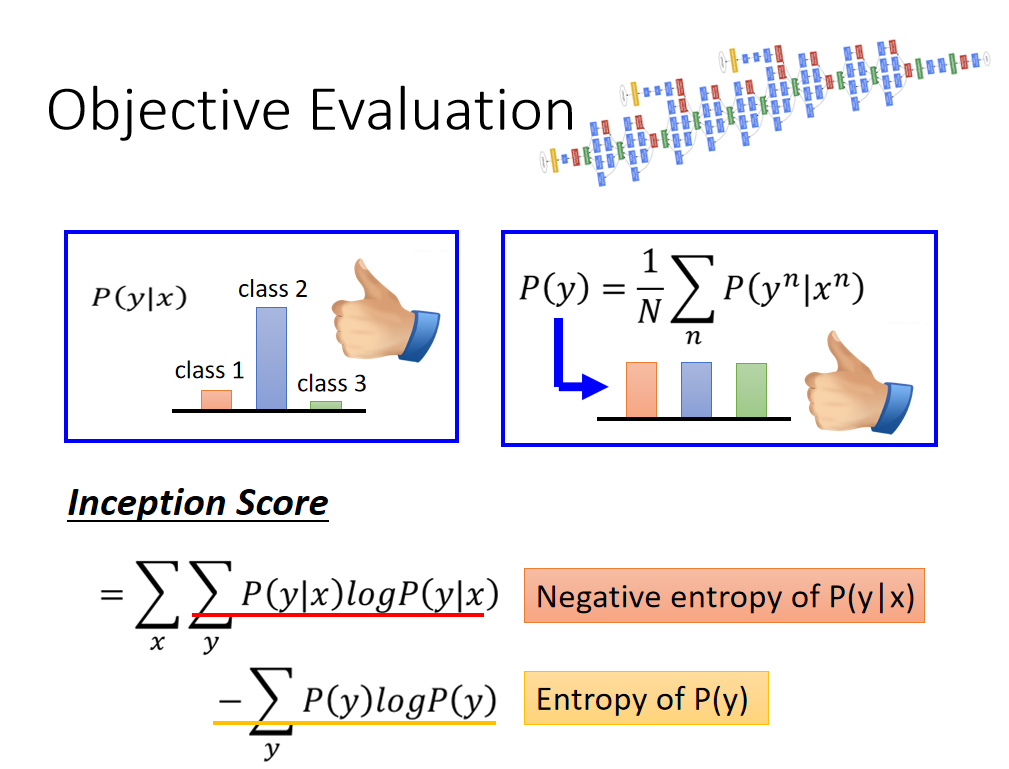
I n c e p t i o n S c o r e = ∑ x ∑ y P ( y ∣ x ) l o g P ( y ∣ x ) − ∑ y P ( y ) l o g P ( y ) Inception\ Score = \sum_x\sum_yP(y|x)logP(y|x)-\sum_yP(y)logP(y) Inception Score=x∑y∑P(y∣x)logP(y∣x)−y∑P(y)logP(y) 上式中 第一项是:Negative entropy of P(y|x)(分布越sharp越好) 第二项是:Entropy of P(y)(分布越平滑越好) 更多的可以参考: 👉 [GAN量化评估方法——IS(Inception Score)和FID(Frechet Inception Distance score)](https://www.cnblogs.com/qizhou/p/13504586.html)👉 【深度理解】如何评价GAN网络的好坏?IS(inception score)和FID(Fréchet Inception Distance) We don’t want memory GAN.👉 A NOTE ON THE EVALUATION OF GENERATIVE MODELS 除了上面的内容外,还需要注意的是:虽然Generator生成了清晰的图片,也不说明什么,也有可能是GAN把数据库中的真实图片memory下来了。 但是数据库中的图片太多,我们也不知道GAN生成的图片是不是数据库里面的。有人提出来说很简单,把Generator生成的图片拿出来与数据库中的图片做L1或者L2的相似度计算,但是这种pixel级别的计算是不够的,论文中举例如下: 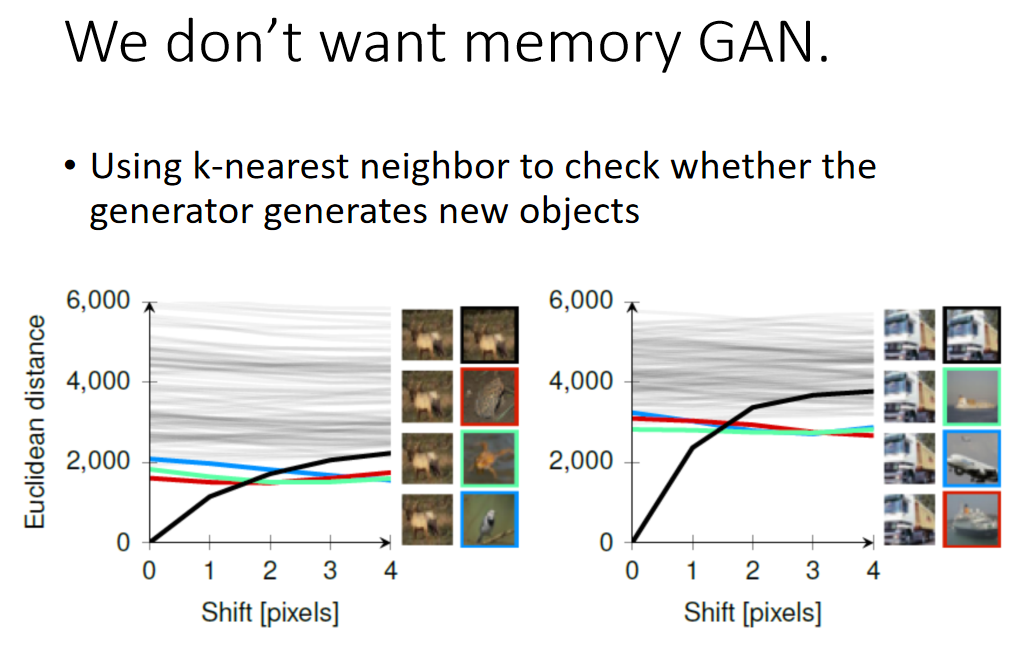
图中很多条线,这些线代表与上面羊的图片的pixel级别的相似度,可以看到,当把图片进行shift一个pixel与其最相似的是黑框那张图片(还是羊),如果shift两个pixel,最相似的图片变成红框那张,以此类推。 也就是说如果GAN生成的图片是shift过两个pixel的,那么用相似度取数据库中找,找到的完全不一样的图片,但是实际上还是一个羊的图片。 右边是另外一个卡车的例子。 其他补充内容 Mode Dropping其实Mode Dropping的概念我们前面也介绍过了👉 机器学习-38-General Framework of GAN(fGAN,GAN的一般框架) 那么有没有方法可以来估计GAN生成样本的分布?或者说找出生成不同图片数量的上限?具体不展开,给例子: DCGAN( Deep Convolutional GAN) If you sample 400 images, with probability>50%, You would sampie"identical"images. There are approximately 0.16M different faces. 意思是这个模型sample 400张图片,有50%的几率会拿到两种相似的图片,那么可以估计出DCGAN生成人脸模型的生成数量为16w左右。 另外一个ALI 模型大约可以生成100w张 👉 Sanjeev Arora,AndrejRisteski,Yi Zhang,“Do GANs learnthe distribution?Some Theory and Empirics”,ICLR,2018 Mini-batch Discrimination👉 Improved Techniques for Training GANs 
原始的GAN的Discriminator进行判别的时候参考的是单个样本,这样的判别结果有可能会有失偏颇; Mini-batch Discrimination对一个Mini-batch中所有的样本同时进行判别,这样除了判断单张样本之外,还会判别同一个batch中类似或者重复的图片,从而给出更加客观的判别结果。 Concluding Remarks from A to Z(GAN大集合)最后的部分,整理出我们介绍过或者稍微提及过的GAN。 不知道你还记不记得我们前面埋了一些坑,一些GAN没具体讲,其实就是为了这了好凑数😸 
|
【本文地址】