Flexgen LLM推理计算环节的量化分析 |
您所在的位置:网站首页 › 怎么计算kv值 › Flexgen LLM推理计算环节的量化分析 |
Flexgen LLM推理计算环节的量化分析
|
LLM推理计算量化分析(Background: LLM Inference) 原文章节叫 Background: LLM Inference,但是个人在读到几乎所有LLMs推理系统设计时,包括DeepSpeed Inference: Enabling Efficient Inference of Transformer Models at Unprecedented Scale感觉都缺少详细的量化分析(多定性分析为主),多以定性的观察以及实验效果提升介绍全文,但是始终觉得看完文章后觉得很有道理、效果也很好,但是多问几个“为什么”就比较难解答了。 基于基于计算机体系结构的优化分析,量化分析是非常有必要的,是非常有助于做系统优化的说服力、逻辑严谨性。多篇文章看下来,感觉Flexgen专门设计了这个章节对读者是非常友好的,这个章节提供了一些关于LLM推理参数量、激活量、KVcache存储量和更新行为,还有generative token时序依赖等基本计算行为做了量化分析,也对LLM推理计算的KVcache原理做了形式化描述。值得一提的是,Deepspeed-inference全文关键4类优化分别是Kernel优化、LLMs dense模型架构的多GPU并行、LLMs MoE稀疏优化、以及CPU Offload设计,都未见详细的量化分析。 例如,LLMs dense多GPU并行的insight中对KV cache行为和时序依赖性仅仅定性描述:  Deepspeed inference中对LLMs推理计算的KV cache以及autogressive时序依赖性能的描述,偏定性描述 Deepspeed inference中对LLMs推理计算的KV cache以及autogressive时序依赖性能的描述,偏定性描述例如,CPU offload设计中,也是定性分析为主:  Deepspeed-inference CPU offload的insight描述 Deepspeed-inference CPU offload的insight描述Flexgen量化分析相对细致不少:  Flexgen对LLM推理计算的量化分析 Flexgen对LLM推理计算的量化分析下面详细对LLMs推理计算的行为进行量化分析(为了阅读通畅,下面补充的知识,对于只有基本transformer网络结构概念的同学也适合,比较适合计算机系统结构同学在没有深度实践LLMs的情况下也能看懂本文技术分析): 下面2张图需要熟记、甚至默写或者推导公式,对每个计算过程的存储、tensor行为最好都能清楚,个人实践,对揣摩KVcache的原理、模型参数量、激活数据量、还有微观向量结构都非常重要,对理解LLM模型的大规模训练也是非常重要的。李沐老师在B站的视频,Transformer论文逐段精读【论文精读】_哔哩哔哩_bilibili中有一节对Transformer架构也做了量化分析,推荐去观摩原视频。这个对理解很多训练和推理计算优化都蛮重要。  encoder-decoder LLM模型架构中Transformer构成(现在主要流行的全部是去掉encoder部分的decoder-only架构) encoder-decoder LLM模型架构中Transformer构成(现在主要流行的全部是去掉encoder部分的decoder-only架构)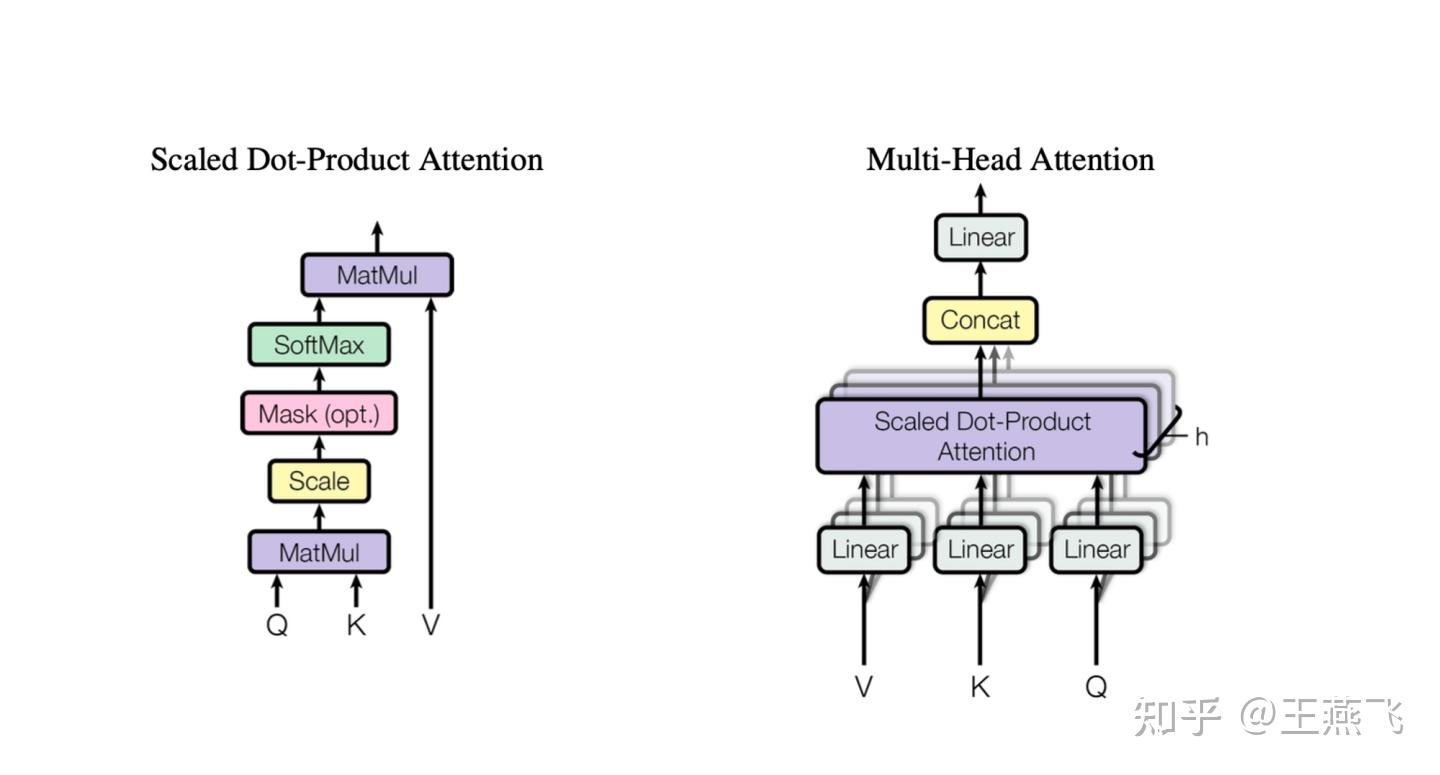 Transformer理的Multi-head attention基本构成 Transformer理的Multi-head attention基本构成 Flexgen对prefill phase量化分析 Flexgen对prefill phase量化分析Flexgen文中描述了上面几个部分的可学习参数内存占用,分别是Q、K、V、O四个矩阵参数是h1*h1的大小,其中Scaled Dot-product Attention全是计算Kernel,无可学习参数。另外,还有FF层h1*h2+h2*h1两个矩阵,分别是从h1升纬到h2然后再降纬到h1的全连接矩阵。flexgen这里说的不是很准确,因为实际上,参数量上,还有Bias部分,但是bias占比太小所以此处简化了。另外,一般QKV都是多头设计,此处多头(multi-head)的小矩阵拼接起来也是h1*h1的矩阵,也不是本文的计算优化insight关注的地方,所以此章节量化分析没有重点讲多头(multi-head)的设计。 可以参考论文原文,此处Prefill phase阶段,强调有几个重要的信息:(推荐medium上一个博主对Transformer量化分析讲的非常细,且逻辑严谨的文章: How to Estimate the Number of Parameters in Transformer models Transformer基础参数的量化分析,仔细读完上面的疑惑都能得到解读。) 1) QKV都会从h1(flexgen里标识,指token的隐层大小)降纬到h1/nhead数,但是实际每个Q\K\V的参数矩阵大小均为,h1*h1/nhead*head=h1*h1大小,共3个h1*h1矩阵(开始可能误以为多个QKV降纬矩阵式小矩阵,但是实际上QKV分别都有nhead个降维小矩阵,拼接起来还是h1*h1大矩阵,可以对照Transformer的Multi-head attention基本构成图进行理解。)。这个可以有助于评估参数量、优化器存储容量。 理解QKV三个h1*h1的矩阵,是一个线性变换,对于同一个seq样本,每个token可以并行计算无时序依赖,这个在训练阶段、推理的prefill阶段(prompt输入的计算)是高度并行的(对于generative阶段,一个token一个token的生成,就没有这种并行性了); 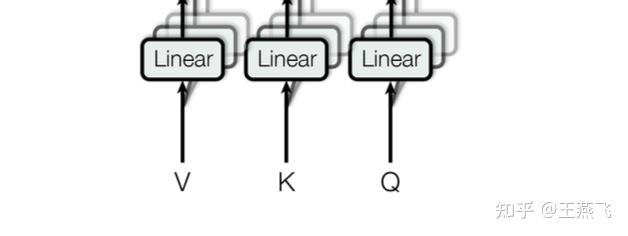 QKV 线性变换 - 降维、多头映射 QKV 线性变换 - 降维、多头映射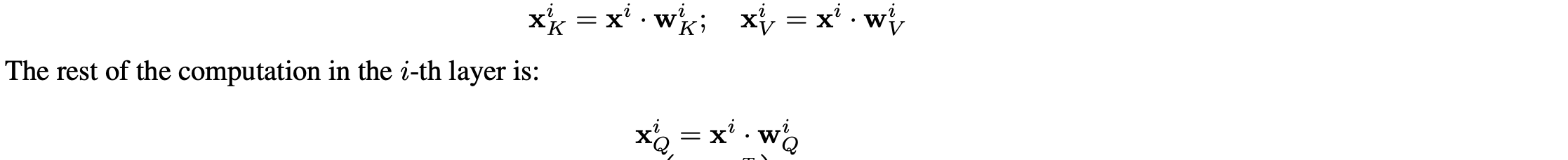 上面线性变换对应的形式化语言,Flexgen里描述的形式化语言 上面线性变换对应的形式化语言,Flexgen里描述的形式化语言2) 图中Scaled dot-pruduct Attention计算没有可学习参数(极少,比如Layer Normalization有几个参数,感兴趣也可以看How to Estimate the Number of Parameters in Transformer models细致的分析),多头经过attention计算之后会重新concat拼接并再经过一次线性变换,这个线性变换矩阵记为O,一个h1*h1 O输出矩阵。 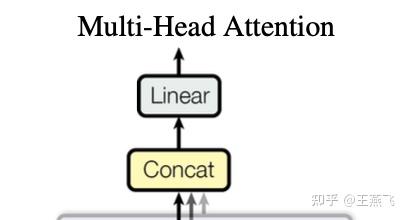 Scaled dot-pruduct Attention 输出重新拼接过程,这里Linear矩阵局势flexgen文章里的O矩阵 Scaled dot-pruduct Attention 输出重新拼接过程,这里Linear矩阵局势flexgen文章里的O矩阵围绕上面3组Linear 多头矩阵以及最后输出的Linear矩阵,不是Transformer参数内存重头,后面FFN层才是,这三个矩阵总共4h1*h1大小,但是FFN一般是4*h1*h1+4h1*h1=8h1*h1。在后面会量化分析,也可以看这个How to Estimate the Number of Parameters in Transformer models这个文章。 3) 每个token并行的进行线性变换映射成低纬度的向量后,过一个Scaled Dot-Product Attention计算(这个计算是比较有名的flashattention: fast and memory-efficient exact attention with io-awareness计算重点优化的对象,通过tiling提高这个sublayer计算的memory hierarchy性能,它在pytorch 社区PyTorch MULTIHEADATTENTION以及第三方框架社区,例如,Huggingface的diffusers框架、fair的xformer框架、meta AItemplate、等等都渗透比较明显),可以把它理解为一个op,也可以是多个可以fusion op。  Scaled Dot-Product Attention 计算示意图 Scaled Dot-Product Attention 计算示意图 Scaled Dot-Product Attention外加resnet和norm计算示意图 Scaled Dot-Product Attention外加resnet和norm计算示意图 Scaled Dot-Product Attention、O矩阵计算、resnet、norm计算形式化计算公式 Scaled Dot-Product Attention、O矩阵计算、resnet、norm计算形式化计算公式这个attention是计算是Transformer计算的复杂度最高的部分,占比Transformer计算算力消耗重头,也是flashattention能提高算力性能的关键量化分析背景。 4) FFN层以及Norm。FFN是一个升纬再降维的两个矩阵,从h1升纬到h2,共h1*h2+h2*h1+bias的参数内存占比(一般h2=4*h1,这里的4稀疏决定了FFN比attention子层参数内存占用比,当是4的时候,FFN内存占比attention内存大约多出1倍)。理解这些内存占比情况以及量化分析方法,对理解训练系统参数sharding并行方法也非常重要,可以用于评估在特定并行计算硬件架构下利于理论带宽评估通信延迟,从而可以帮助优化latency隐藏条件。  Flexgen中对FFN层的形式化公式 Flexgen中对FFN层的形式化公式5) Multi-Head attention计算行为全局特点、推理计算prompt计算特点以及generative计算特点: 对于推理阶段prompt计算或者训练计算,对于一个input sequence,它所有tokens是并行进行线性转换的,并行降维到一个h1/nhead的大小后,进行QKV attention无状态计算,这个计算过程完成了对QKV三组token序列的信息交叉融合,再经过concat和linear转换输出的矩阵跟原input sequence的shape是一样的。这个计算特性对理解KV cache的更新策略可能有较大的好处。推理计算阶段prompt计算方式等价于训练的input sequence,计算行为是一样的。 LLM是generative model,它在生成时会将生成的当前token作为input再回送给input,对于每个生成的新token都要跟prompt以及之前生成的token拼接起来,然后再输入到attention计算和FFN里去,直觉上,每次拼接的新input 序列和上一次拼接的序列之间存在重复部分,而直觉上这种重叠计算(严格上算是一种激活值,activation)能否通过cache设计来避免重复运算呢,严格上只要prompt+generative tokens长度长到一个阈值size,计算代价一定是很高的,cache设计就非常有意义了。思考这个阈值特点就需要量化分析了,去分析cache的存储代价是什么、计算的代价是什么?  Multi-Head attention计算行为全局特点示意图 Multi-Head attention计算行为全局特点示意图prompt计算过程 ,文章定义的 prefill phase ,类同训练,可以直接用QKV矩阵连乘并行获得每层Transformer的input sequence tokens向量,如下:Xi 代表第i层的prompt tokens序列, 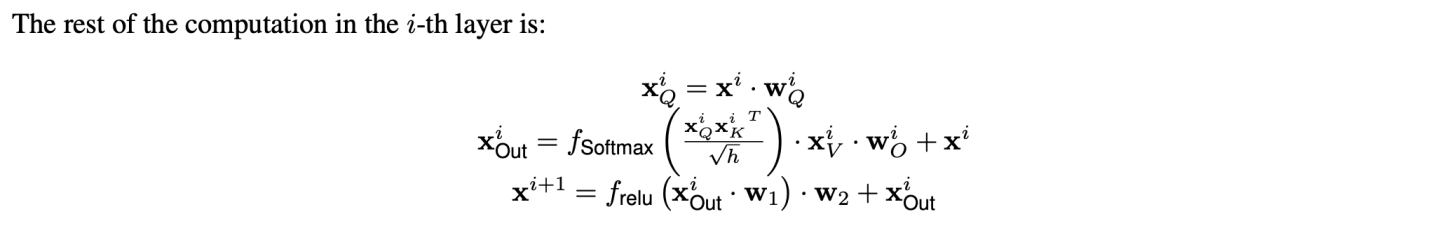 Flexgen 第i层序列Xi映射到第i+1层序列Xi+1的计算方式,类同训练的计算pattern Flexgen 第i层序列Xi映射到第i+1层序列Xi+1的计算方式,类同训练的计算pattern作者定义的第二阶段 decoding phase:  flexgen decoding phase 阶段形式化过程 flexgen decoding phase 阶段形式化过程decoding phase阶段里,可以看出每层的input tokens只是做了一个拼接,这个拼接是在sequence size纬度,不是把h1扩大到h1+h1了,就等于序列的tokens size +1,且历史的token序列Xk、Xv是没有更新的(这个可能要从算法角度解释了,为什么不用结合新的token拼出的new sequence对所有的历史tokens对应的Xk、Xv进行更新?个人有点疑惑),只有新token作为Q,这个Q对应的输出会每次都更新。这儿可以看到每个token生成都面临内存分配,AI加速器上的这种内存动态的分配管理可能也是系统优化的关键吧(不清楚有没有这方面的研究工作) 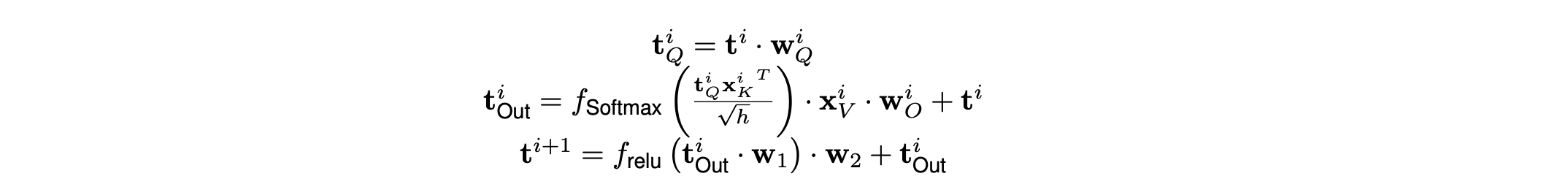 新token作为Q,这个Q对应的输出会每次都更新 新token作为Q,这个Q对应的输出会每次都更新上面decoding phase形式化,可以看出prompt和历史生成的tokens的cache更新主要是tensor拼接操作,然后当前新token作为Q过一遍attention和FFN, 如果cache进行cpu offload,主要就是CPU端内存拼接管理。 LLM decoding phase阶段的cache行为以及tokens时序性是LLM推理计算系统设计的关键,CPU offload的cache的内容和对应的参数都一一对应,但是面临一个是cache内存量大,一般都大于参数量,复杂度是4*blh1(s+n),相比模型参数多了b(batchsize)、s+n(序列长度)两个复杂度系统成线性关系(而且,LLM都逐渐将seq长度扩大,越大越好),因此可以想象量化数据反映出cache的存储和访存带宽压力面临的设计越来越重要(未来,是否可以考虑将cache系统拆开进行更加极致的优化呢?),成为系统设计的关键的关键。 另外,token时序依赖,限制了在同一个sample内做token level的数据并行,flexgen的意图换个角度讲,就是用超级大batch、外加pipeline技术,跳出token level并行,换用跨sample的token level并行,牺牲latency提高计算密度并行度,文章。从这个视角,flexgen跟Orca的insight是类似的,只是系统设计背景不同,orca设计的是一个相对更加通用的计算系统,flexgen就是目标做极高的吞吐throughout。  LLM decoding phase阶段的cache 量化数据 LLM decoding phase阶段的cache 量化数据6)文中在Offload strategy阶段为寻找优化的系统参数,也对简化后的block调度系统进行了深入的量化分析,这种量化分析也是非常值得揣摩的,这种思路也是系统优化必备的(虽然感觉有些假设比较理想),此处不赘述,在下一个章节必要时解读相应的量化分析。下图是Offload strategy阶段,目标要进行量化分析的并行计算子系统(对计算机系统结构同学,建议仔细品一下,体会下怎么进行量化分析,是做性能优化的必备技能,比如作者量化分析后,才有用线性规划的方法去找最优的参数组合,否则就是凭直觉,大概率是次优解)。  Offload strategy阶段,目标要进行量化分析的并行计算子系统 Offload strategy阶段,目标要进行量化分析的并行计算子系统
|
【本文地址】