【20210803】【数据分析】评价两个向量之间的相关性指标 |
您所在的位置:网站首页 › 怎么算两组数据的相关性 › 【20210803】【数据分析】评价两个向量之间的相关性指标 |
【20210803】【数据分析】评价两个向量之间的相关性指标
|
(参考:向量的相似性度量) 一、问题求下面两个向量的相似性: a = (x11, x12, x13, ..., x1n) b = (x21, x22, x23, ..., x2n) 二、方法 1. 欧氏距离(Eculidean Distance)欧氏距离是最简单的距离计算公式,源于两点间距离。
向量表示方式为:
曼哈顿距离也就是实际驾驶距离,又称为 ”城市街区距离(City Block Distance)“。
国王走象棋,从 (x1, y1) 到 (x2, y2) 最少需要的步数总是 max(|x2-x1|, |y2-y1|),类似这种的距离度量方法叫做切比雪夫距离。
这个公式的等价形式是:
闵氏距离不是一种距离,而是一组距离的定义,也就是不同的 p 参数,对应不同的距离定义。
其中,p 是一个可变参数。 当 p = 1 时,就是曼哈顿距离; 当 p = 2 时,就是欧氏距离; 当 p → ∞ 时,就是切比雪夫距离。 闵氏距离的缺点: 1. 将各个分量的量纲(scale),即 ”单位“ 当作相同看待; 2. 没有考虑各个分量的分布,期望、方差可能是不同的。 例如: 有三个二维样本(身高,体重):a(180, 50)、b(190, 50)、c(180, 60),a 和 b 的闵氏距离 等于 a 和 c 的闵氏距离,但显然身高的 10cm 和体重的 10kg 并不等价。这就是闵氏距离处理不同量纲、不同分布样本数据的不便之处。 5. 标准化欧氏距离(Standardized Eculidean Distance)标准化欧氏距离就是用来解决闵氏距离中的欧氏距离的缺点,思路是:先对各个向量进行标准化:
其中,m 是 X 向量的均值,s 是 X 向量的标准差。标准化之后的数据无量纲,可比性增强,但可解释性减弱。 标准化欧氏距离定义:
从形式上看,标准化欧氏距离像是一种加权欧氏距离。 6. 余弦相似度(Cosine)两个向量的夹角的余弦值取值范围为 [-1, 1],两个向量的夹角越小表示余弦越大,即余弦相似度越大;夹角越大表示余弦越小,即余弦相似度越小。
即:
应用场景:信息编码(为增强容错性,应使得编码间的最小汉明距离尽可能大)。 两个等长字符串 s1 和 s2 之间的汉明距离定义为:将其中一个变为另外一个所需要做的最小替换次数。例如字符串 “1111” 与 “1001” 之间的汉明距离为 2。 Matlab 中的两个向量之间的汉明距离定义为两个向量不同的分量所占的百分比。 例如: X = [0, 0; 1, 0; 0, 2],汉明距离为 D = [0.5, 0.5, 1]。 8. 相关系数 & 相关距离(Correlation Coefficient & Correlation Distance)(1) 相关系数:是衡量随机变量 X 和 Y 相关程度的一种方法,取值范围是 [-1, 1],相关系数的绝对值越大,表示相关性越高,为正表示正相关,为负表示负相关。
(2)相关距离
信息熵并不是一种相似性度量,是衡量某个样本集分布的混乱程度的一种度量。分布越分散/平均,信息熵越大。
其中,n 是样本集 X 的分类数,pi 表示 X 中第 i 类元素出现的概率。 三、Matlab 函数实现方式 X = [a; b]; % 一行一个向量,放两行 d1 = pdist(X, 'euclidean'); % 欧氏距离 d2 = pdist(X, 'cityblock'); % 曼哈顿距离 d3 = pdist(X, 'chebychev'); % 切比雪夫距离 d4 = pdist(X, 'minkowski', 2); % 闵氏距离(以变参数为2的欧氏距离为例) d5 = pdist(X, 'seuclidean', [0.5, 1]); % 假设两个分量的标准差为0.5和1 d6 = 1 - pdist(X, 'cosine'); % Matlab中的pdist(X, 'cosine')得到的是1减夹角余弦的值 d7 = pdist(X, 'hamming'); % 汉明距离 corr = corrcoef('X'); % 相关系数矩阵(方阵) d8 = pdist(X, 'correlation'); % 相关距离 |
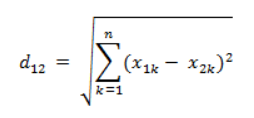
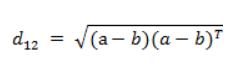
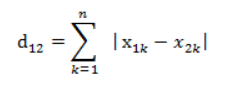
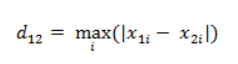
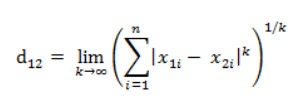
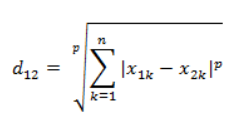
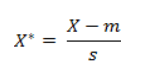

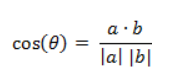
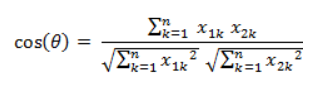
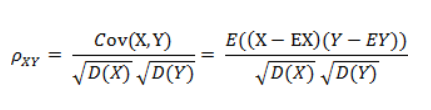
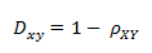
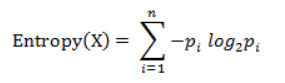
【本文地址】
今日新闻 |
推荐新闻 |