CRF该怎么理解?(从HMM到CRF,图解标注偏差问题) |
您所在的位置:网站首页 › 怎么理解传递函数 › CRF该怎么理解?(从HMM到CRF,图解标注偏差问题) |
CRF该怎么理解?(从HMM到CRF,图解标注偏差问题)
|
原文链接:CRF并不难,面试你就这样答 CRF最初为统计机器学习时代的经典算法,因为计算成本低、效果好、兼容性强的特点,使它在深度学习时代也被广泛使用。 如果你是NLP算法工程师,面试时CRF一定是绕不开的话题。CRF算法原理涉及复杂的公式推导和概率图的基本定理,看起来比较费劲。 但其实只要搞清楚它的来源,知道CRF如何应用,掌握核心思路,公式中涉及的难点也就不攻自破。我会从以下两点进行叙述: 从HMM到CRF的发展历程CRF怎么与深度学习结合若对HMM不理解的同学,建议先阅读漫画图解:小孩都看得懂的HMM 一、从HMM到CRF的发展历程1.1 全景图 1.2 HMM到MEMM 1.2 HMM到MEMM我们知道,HMM有两个假设,分别是齐次一阶马尔科夫假设和观测独立假设。  所以HMM就完全基于统计概率,就可以计算出初始状态矩阵、发射矩阵和转移矩阵。显然两个假设并和合理,所以最大熵马尔可夫模型(MEMM)打破了观测独立假设:  很多同学不理解标注偏差问题,我来举例说明这个问题:有观测和状态的概率分布图如下:  我们可以看到状态1偏向于转移到状态2,而状态2总倾向于停留在状态2,不是全局最优解,这就是所谓的标注偏置问题。可以理解为贪心,总是找当前概率最大的进行选择。  0.6*0.3*0.3 = 0.054 \\ 造成它的原因就是由于分支数不同,概率的分布不均衡,导致状态的转移存在不公平的情况,就是所谓的局部归一化,标注偏置问题。而如果考虑到前后,我们选一条综合概率最大的路径,则应该是:  0.4*0.45*0.5 = 0.09 \\ CRF的提出就是为了解决标注偏差问题,把有向图变为无向图后,进行全局归一化,就可以选出一条综合概率最大的路径了。 1.3 MEMM到CRF所以CRF打破齐次一阶马尔科夫假设,将有向图变为无向图,进行全局归一化。  二、CRF怎么与深度学习结合2.1 CRF公式与损失函数 二、CRF怎么与深度学习结合2.1 CRF公式与损失函数 2.2 CRF在深度学习中的应用 2.2 CRF在深度学习中的应用大家一定很好奇,那么转移矩阵和状态矩阵是怎么算出来的呢? 在深度学习的实际应用中,我们通常会用BiLSTM+CRF来进行序列标注。 BiLSTM的输入是词向量,输出的结果是每个单词对应各类别的分数(每个字是每种状态的概率)。CRF层,我们需要初始化一个i×i(假设共有i种状态)的转移矩阵。它的输入是BiLSTM的输出。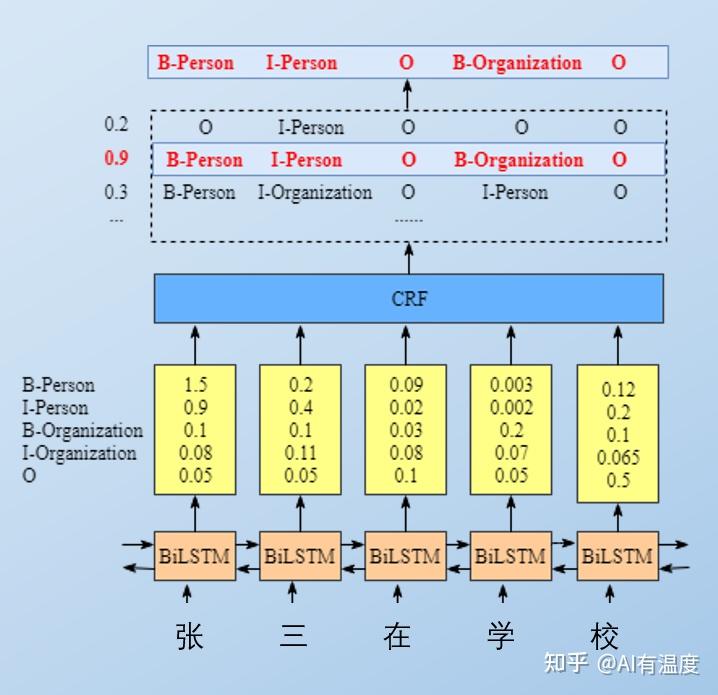 在有了状态矩阵和转移矩阵后,我们就可以进行全局归一化计算综合概率最大的路径了。 2.3 总结BiLSTM可以联系上下文进行计算,最后得出每个字对应各个标签的概率,然后通过转移矩阵计算每种路径的概率,最后概率最大路径的就是标注结果。转移矩阵和状态矩阵的参数都是通过深度学习反向传播计算的出来的,而不是基于统计。 2.4 不用CRF可不可以?其实我们可以看到BiLSTM输出了每个单词对应各类别的分数,那么我们直接在每个单元的输出后接一个softmax层,然后取最大值不就可以了吗?  其实理论是可以的。细细想想,虽然BiLSTM学习到了上下文的信息,但是输出的标签相互之间并没有影响,它只是在每一步挑选一个最大概率值的label输出。 这样的结果就可能产生I-person后再接一个I-organization,显然这种结果是不合理的。而CRF中有转移特征,即它会考虑输出label之间的顺序性,所以考虑用CRF去做BiLSTM的输出层会使结果更为合理。 原文链接: |
【本文地址】
今日新闻 |
推荐新闻 |